
DupScout — это не просто программа для поиска одинаковых файлов, а полноценный duplicate file finder с упором на контроль, аналитику и управляемую очистку. Она умеет искать дубликаты на локальных дисках, во внешних накопителях, в сетевых папках и на NAS, показывает, сколько места действительно теряется на дублях, позволяет выбрать оригинал, назначить действие для копий, сохранить отчёты в несколько форматов и, если нужно, встроить эту работу в регулярный сценарий администрирования. В этом и заключается главное отличие DupScout от массы упрощённых утилит: здесь акцент сделан не на кнопке найти и удалить всё, а на точном поиске, фильтрации, проверке и только потом на очистке.
Если смотреть на DupScout как на конкретную программу, а не на класс софта вообще, то у неё очень узнаваемый профиль. Она особенно хороша там, где дубликаты разрастаются постепенно: архивы документов, папки с бэкапами, старые медиатеки, рабочие шары отдела, NAS с копиями проектов, сетевые каталоги, куда пользователи раз за разом складывают одни и те же данные под разными путями. DupScout не пытается выглядеть волшебной кнопкой, зато даёт точные инструменты для разбора таких завалов.
Скачать Dup Scout
- Оптимизация системы
- Очистка мусора
- Ускорение ПК
- Сложно новичкам
- Только дубликаты
- Платная Pro-версия
Что такое DupScout и для каких задач он нужен
DupScout рассчитан на три базовых сценария. Первый — обычная очистка компьютера или внешнего диска, когда нужно убрать одинаковые файлы и освободить место. Второй — аналитика: понять, какие типы данных чаще всего дублируются, где именно теряется место, в каких папках и категориях образуются повторные копии. Третий — полуавтоматизированная или полностью автоматизированная работа с профилями, отчётами, сетевыми шарами и серверными ресурсами. За счёт этого программа одинаково уместна и на домашней машине, и в инфраструктуре, где дубликаты надо отслеживать системно, а не разово.
Важный момент: DupScout работает не только по локальным папкам. Программа умеет обрабатывать network shares, UNC-пути и NAS storage devices, а в старших редакциях — запускать пакетный поиск по множеству серверов и сохранять по ним отдельные отчёты. Для домашнего пользователя это может быть вторично, но именно эта сетевая часть делает DupScout заметно сильнее многих обычных утилит для удаления дубликатов файлов.
С практической точки зрения DupScout хорош тогда, когда нужно не просто обнаружить одинаковые файлы по содержимому, а ещё и решить, что именно с ними делать. Программа поддерживает удаление, перенос, сжатие, замену дублей ярлыками или жёсткими ссылками, ручной выбор оригинала, предварительный просмотр действий и экспорт результатов. Это уже не поиск дублей ради факта, а осмысленная очистка занятого места.
Интерфейс DupScout: как устроено главное окно
Первое знакомство с DupScout обычно производит двойственное впечатление: визуально программа выглядит функционально и даже немного строго, зато почти каждый элемент интерфейса здесь работает на задачу. В верхней части окна находится крупная панель инструментов, где можно увидеть кнопки Duplicates, Pause, Stop, Wizard, Computer, Network, Actions, Execute, Save, Charts, Search, Database, Options и Help. Ниже располагаются панели Profiles, Inputs, Status, центральная таблица наборов дублей и нижний блок с категоризацией и фильтрами. Именно эта структура делает программу удобной не только для одноразового запуска, но и для повторяемых сценариев.
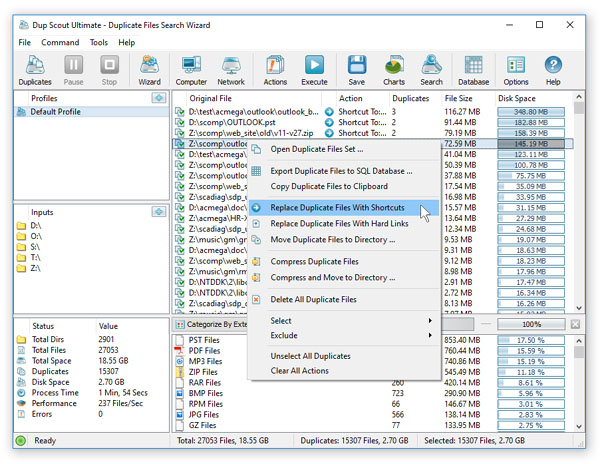
На скриншоте хорошо видно, что DupScout строится вокруг профиля поиска. Слева находится Default Profile, ниже — список Inputs, то есть дисков, папок или сетевых путей, которые будут участвовать в поиске. В центре выводятся найденные наборы дублей, а внизу — категории по типам или расширениям. Такой расклад очень практичен: в одной рабочей области видно, откуда сканируются данные, что уже найдено, какое действие назначено и в какой категории дубликаты занимают больше всего места.
Отдельно стоит отметить гибкость внешнего вида. У DupScout есть три GUI layout-режима: стандартный с крупными кнопками и нижним блоком категорий, более компактный с небольшими кнопками и скрытой правой панелью, а также минималистичный режим без подписей на кнопках и без нижней панели категорий. Переключение выполняется через кнопку Layouts или пункт Tools – Switch GUI Layout. Для программы, которую нередко держат открытой подолгу, это полезнее, чем кажется: можно подстроить интерфейс под размер экрана и плотность работы.
Есть и ещё одна практичная мелочь: DupScout интегрируется в контекстное меню Windows Explorer через пункт DupScout - Find Duplicates. Для сценария выбрал несколько папок в Проводнике и сразу запустил поиск дублей это очень удобно, особенно когда не хочется каждый раз собирать входные каталоги вручную в самой программе. Если такая интеграция не нужна, её можно отключить в общих параметрах.
Как DupScout ищет дубликаты
Базовый сценарий в DupScout устроен очень просто. Пользователь нажимает Duplicates на главной панели, открывает окно профиля поиска, добавляет один или несколько дисков, папок либо сетевых путей и запускает анализ кнопкой Search. Если нужно, прямо из этого окна можно открыть дополнительные параметры через Options, а затем вернуться к старту сканирования. Формально ничего сложного здесь нет, но в отличие от примитивных утилит DupScout уже на этом этапе позволяет точно задать область поиска.
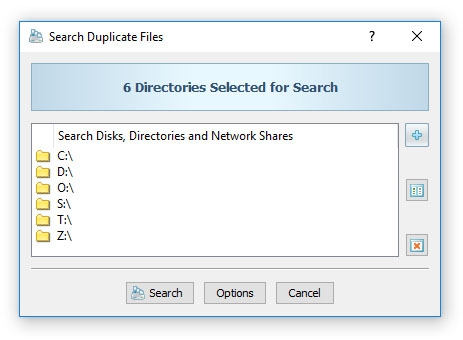
Окно Search Duplicate Files предельно утилитарно. В нём виден список выбранных директорий, область Search Disks, Directories and Network Shares, а справа — кнопки для добавления и удаления входов. Внизу находятся Search, Options и Cancel. Логика понятная: сначала собирается набор локаций, потом при необходимости уточняются правила и опции, после чего запускается поиск. Для пользователя это означает, что DupScout не распыляет внимание на красивую оболочку, а сразу ведёт к рабочему сценарию: задать область, проверить настройки, начать сканирование.
После завершения анализа DupScout показывает не хаотичный список файлов, а именно наборы дубликатов, отсортированные по тому, сколько лишнего пространства они съедают. Это очень сильная особенность программы. Вместо тысячи беспорядочных совпадений пользователь сразу видит самые дорогие группы — те, что занимают наибольший объём wasted disk space. По умолчанию в основном списке программа показывает верхние 10 000 наборов дублей, отсортированных по объёму duplicate disk space, а лимит можно менять через параметр Max Dup File Sets.
Центральная таблица ориентирована не на файловую мелочёвку, а на принятие решений. В ней видны исходный файл, число дублей, размер файла и общий эффект по дисковому пространству. Это удобно: DupScout с самого начала переводит разговор из плоскости сколько одинаковых файлов найдено в плоскость какие именно группы реально мешают и сколько места можно вернуть. Для очистки больших архивов такая подача гораздо полезнее, чем сухой список путей.
Насколько точен поиск: сигнатуры, хэширование и логика совпадений
В основе DupScout лежит поиск одинаковых файлов по содержимому, а не просто по совпадению имён. Программа идентифицирует дубликаты через hash signatures, и по умолчанию использует SHA256. В настройках можно переключиться на MD5 или SHA1: они работают быстрее, но считаются менее надёжными. На практике это означает простую вещь: если вам важнее максимальная точность, разумно оставить SHA256; если задача — быстро прогнать огромный массив файлов и получить предварительную картину, можно смотреть в сторону более быстрых алгоритмов.
Это важное отличие DupScout от программ, которые ищут одинаковые файлы только по имени, размеру или базовому набору атрибутов. Здесь акцент сделан именно на идентичность данных. Поэтому DupScout особенно хорошо подходит для случаев, когда один и тот же файл лежит в разных папках под разными именами: копии архивов, изображения, вложения из почты, документы после многократного копирования и ручного переименования. Для серьёзной очистки это принципиально.
При этом DupScout не сводится к чистому хэшу. Программа умеет накладывать file matching rules, фильтры по типу, расширению, размеру, времени создания, модификации и последнего доступа. То есть пользователь может искать не вообще все одинаковые файлы, а, например, только duplicate images, только документы крупнее заданного порога или только файлы, изменённые в определённый период. Благодаря этому поиск дублей в Windows превращается из грубой операции в аккуратный, управляемый процесс.
Что видно в результатах и как читать найденные наборы
Когда DupScout закончил сканирование, на экране появляется список duplicate file sets. И здесь проявляется одна из лучших сторон программы: результаты устроены так, чтобы человек быстро дошёл до решения. Набор можно открыть двойным щелчком, посмотреть все файлы внутри, проверить, какой из них выбран как оригинал, и сразу понять, какой cleanup action назначен. По умолчанию оригиналом считается самый старый файл в группе, а остальные помечаются как duplicate files.
Такой выбор логики по умолчанию очень практичен для архивных и рабочих сценариев. Старый файл часто оказывается первичной копией, а более новые дублёры — следствием последующих пересохранений, копирований и разбрасывания по папкам. Разумеется, программа не навязывает этот выбор: любой файл из набора можно назначить основным вручную через Set as Original. Но стартовая логика у DupScout вполне разумная и в большинстве случаев помогает сэкономить время.
Отдельно стоит отметить, что DupScout ориентирован именно на работу с набором дублей, а не только с отдельными файлами. Это правильный подход. Когда программа показывает группу, пользователь сразу видит контекст: сколько копий существует, где они лежат, какой объём занимают, какое действие уже выбрано для каждой из них. В итоге риск удалить не тот файл ниже, чем в утилитах, где найденные совпадения показываются плоским списком без группировки.
Работа с оригиналом: как DupScout помогает не удалить нужное
Одна из ключевых задач duplicate file finder — не просто найти одинаковые данные, а корректно определить, какую копию оставить. В DupScout это решено довольно аккуратно. По умолчанию программа берёт самый старый файл в наборе как original file, но в карточке набора пользователь может вручную указать любой другой файл через контекстное меню Set as Original. Это особенно важно в тех случаях, когда правильная копия определяется не возрастом, а расположением, именем папки или рабочим процессом.
Представим типичную ситуацию: один и тот же PDF лежит в папке D:\Archive, в рабочей директории проекта и в резервной копии на другом диске. Самый старый файл может оказаться архивным экземпляром, но в реальной работе логичнее оставить копию внутри актуального проекта, а всё лишнее убрать или заменить ссылками. DupScout не спорит с пользователем и не запирает его в автоматике: логика по умолчанию задаёт старт, а финальное решение остаётся у человека. Это очень правильный баланс между автоматизацией и контролем.
Действия с дублями: удаление, перенос, сжатие, ярлыки и жёсткие ссылки
В DupScout сильна не только часть поиска, но и блок cleanup. Программа позволяет удалить выбранные duplicate files, переместить их в другую папку или на backup disk, заменить дубликаты ссылками на оригинал, сжать их или сжать и перенести в другую директорию. В интерфейсе эти действия видны как отдельные команды, а в контекстном меню можно увидеть, в частности, Replace Duplicate Files With Shortcuts, Replace Duplicate Files With Hard Links, Move Duplicate Files To Directory, Compress Duplicate Files, Compress and Move Duplicates и Delete All Duplicate Files.
Это делает DupScout особенно полезным там, где удаление — не единственный правильный сценарий. Например, если нужно навести порядок в папках с резервными копиями, имеет смысл не стирать всё подряд, а перенести дубликаты в отдельный каталог. Если задача — сократить объём рабочей коллекции, но оставить видимую структуру, подойдут ярлыки или жёсткие ссылки. Если речь идёт о старых архивах, где доступ нужен редко, логично рассмотреть сжатие. У многих конкурентов цепочка поиск → удаление короче, а DupScout закрывает больше реальных вариантов действий.
При этом самое важное — программа не бросает пользователя сразу на исполнение операции. DupScout реализует трёхэтапный cleanup process: сначала выбирается действие, потом используется предпросмотр через Preview, и только после проверки запускается Execute. Такой подход сильно снижает риск случайной очистки. В мире программ для удаления дубликатов именно наличие полноценного preview превращает инструмент из потенциально опасного в рабочий.
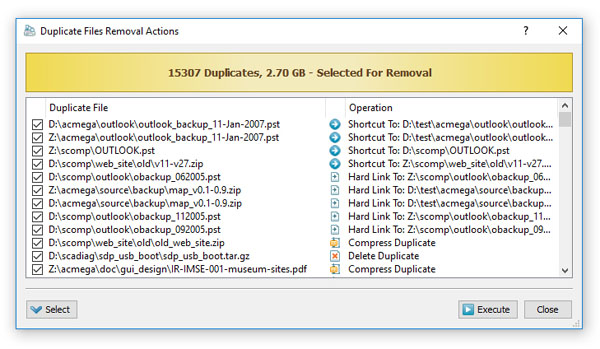
Окно Duplicate Files Removal Actions — одно из самых важных в программе. Здесь DupScout показывает список файлов, выбранных для обработки, и столбец Operation, где видно, что именно будет выполнено: Delete Duplicate, Compress Duplicate, Hard Link To, Shortcut To и так далее. Внизу расположены кнопки Execute и Close, а также раскрывающийся список Select. Такой интерфейс не даёт действовать вслепую: перед фактической очисткой пользователь видит конкретный набор файлов и конкретную операцию для каждого из них.
Очень важный практический вывод: DupScout хорошо подходит для безопасной очистки, если работать через preview, а не сразу через автоматическое исполнение. Особенно это касается дублей в системных каталогах и папках приложений. В таких местах одинаковые файлы могут быть критичны для работы Windows или конкретного ПО, и программа прямо подразумевает осторожный подход: сначала отбор, потом проверка, потом действие.
Категории и фильтры: почему DupScout удобен не только для удаления, но и для анализа
После любого серьёзного сканирования быстро становится ясно: просто список найденных дублей — это ещё не анализ. DupScout решает эту проблему через file categories и filters. Программа умеет категоризировать найденные duplicate files по расширению, типу файла, размеру, имени пользователя, времени последнего доступа, дате модификации и дате создания. По умолчанию используется категоризация по расширению, а список категорий сортируется по объёму занятого пространства. Для каждой категории видно число файлов, объём и долю относительно остальных групп.
Это одна из самых недооценённых возможностей DupScout. Когда вы видите, что основную часть duplicate disk space съедают, к примеру, ZIP-архивы, PST-файлы, PDF-документы или JPEG-изображения, решение становится намного быстрее. Не нужно просматривать сотни групп подряд. Достаточно выбрать нужную категорию в Categories и сразу сосредоточиться на проблемном сегменте. Для больших хранилищ именно такой путь экономит больше всего времени.
В DupScout можно не только посмотреть категории, но и проваливаться в них. Например, программа позволяет отфильтровать файлы, которые были доступны 2–3 месяца назад, а затем работать только с этим срезом. Аналогично можно выделять документы, изображения, файлы по диапазону дат или по определённому типу. В результате DupScout становится не просто cleaner-утилитой, а инструментом навигации по дубликатам. Это особенно ценно, когда задача состоит не в тотальной зачистке, а в точечной оптимизации диска.
Правила поиска: как сузить сканирование до действительно нужных файлов
У DupScout очень сильный блок search rules. Через окно Duplicate Files Search Options и вкладку Rules можно собрать подборку критериев, которые определяют, какие именно файлы должны участвовать в поиске дублей. Программа поддерживает matching rules по имени, расширению, директории, типу файла, размеру, времени создания, дате модификации и последнего доступа. Иными словами, пользователь может не просто искать одинаковые файлы вообще, а задать очень узкий сценарий.
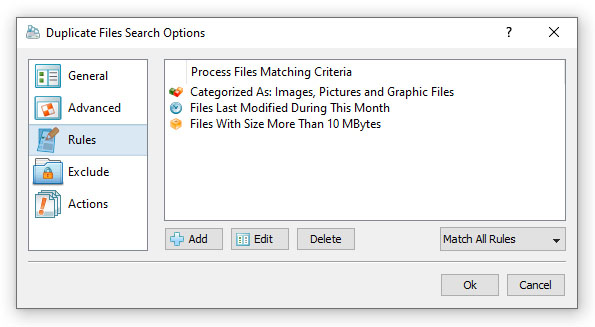
На скриншоте окна Duplicate Files Search Options видно, как это выглядит вживую: в списке Process Files Matching Criteria могут одновременно стоять, например, правила Categorized As: Images, Pictures and Graphic Files, Files Last Modified During This Month и Files With Size More Than 10 MBytes. Ниже расположены кнопки Add, Edit, Delete, а справа — режим сопоставления правил. Такой конструктор особенно удобен для практических задач: искать только большие duplicate images, только документы старше трёх лет, только архивы в определённой ветке папок и так далее.
С точки зрения повседневной пользы rules превращают DupScout в действительно точный инструмент. Если без правил поиск одинаковых файлов на компьютере может вернуть слишком широкий массив результатов, то с правилами программа быстро превращается в прицельный сканер. Это снижает шум, ускоряет просмотр результатов и делает очистку заметно безопаснее, потому что пользователь работает только с тем классом данных, который реально хочет разобрать.
Исключения: как не затронуть служебные и опасные каталоги
Грамотный поиск дублей почти всегда строится не только на включении нужных папок, но и на исключении лишних. В DupScout для этого есть вкладка Exclude. В неё можно добавить каталоги, которые должны быть полностью пропущены во время сканирования. Все файлы и подкаталоги внутри таких директорий не будут участвовать в duplicate files search process. Это простая, но критически важная функция: без неё любая очистка быстро превращается в риск.
Практически это означает, что перед серьёзным запуском в DupScout разумно исключить временные директории, системные каталоги Windows, папки приложений, служебные кэши, рабочие зоны виртуальных машин, каталоги синхронизации, которые вы не готовы трогать автоматически, и все области, где одинаковые файлы могут быть частью нормальной логики работы программ. Такая предварительная настройка занимает минуты, но экономит часы на разборе спорных совпадений.
Для более сложных сценариев DupScout поддерживает макрокоманды исключения: $BEGINS, $CONTAINS, $ENDS, $REGEX и $DIRLIST. С их помощью можно исключать сразу целые группы каталогов по шаблону, регулярному выражению или по списку из текстового файла. Для больших инфраструктур это очень мощная возможность: один набор правил закрывает десятки или сотни путей без ручного перечисления.
Именно поэтому DupScout хорошо подходит не только для разовой очистки домашнего диска, но и для повторяемых администраторских задач. Программа не заставляет каждый раз вручную строить одинаковые исключения. Однажды собранный профиль с корректным Exclude можно использовать снова и снова, поддерживая стабильный и безопасный сценарий поиска одинаковых файлов.
Работа с сетевыми папками, UNC-путями и NAS
Если ограничиться только локальными папками, DupScout уже выглядит сильным инструментом. Но его по-настоящему фирменная сторона — это сеть. Программа умеет работать с UNC path names без необходимости монтировать каждую шару как локальный диск, умеет искать duplicate files в network shares, обнаруживать servers and NAS storage devices, выбирать доступные сетевые папки и запускать анализ по ним. Для тех, кто работает с NAS, общими ресурсами отдела или файловыми серверами, это одна из причин смотреть именно в сторону DupScout.
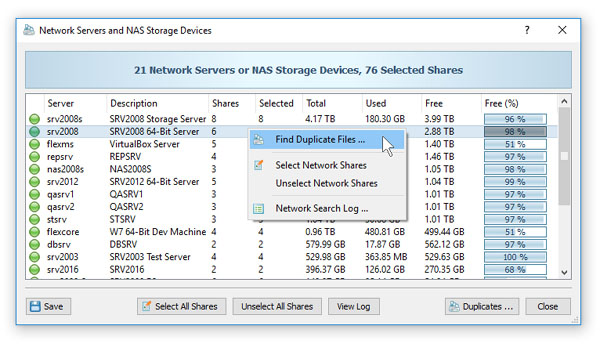
Окно Network Servers and NAS Storage Devices показывает, что DupScout воспринимает сеть не как побочную возможность, а как полноценную рабочую среду. В таблице видны серверы, число шар, объём, занятое и свободное пространство, а через контекстное меню можно выбрать Find Duplicate Files, Select Network Shares, Unselect Network Shares и Network Search Log. Внизу есть кнопка Duplicates. Для администратора это очень удобный формат: сначала быстро обнаружить источники данных, затем точечно отметить нужные шары и только после этого запускать поиск дублей.
Отдельно стоит отметить работу с UNC. DupScout позволяет задавать каталоги через UNC path names without mounting each network share as a local disk. На практике это снимает массу рутины. Не нужно раздавать буквы дисков под каждую шару, особенно если речь идёт о множестве ресурсов. Важно лишь, чтобы у пользователя были нужные права на сетевые папки, потому что и поиск, и дальнейшие действия — перемещение, удаление, замена ссылками — будут выполняться уже по этим путям.
Для больших сетевых сред у DupScout есть ещё одно преимущество: он может добавлять в операцию неограниченное количество network shares от разных servers and NAS devices и обрабатывать их параллельно. А в серверных сценариях возможна работа даже без назначения букв дискам — через снятие флажка Local Disk в конфигурации сетевого подключения. Это очень практично для компаний, где файловых шар больше, чем доступных букв в Windows, и всё должно жить в устойчивом профиле без ручного монтирования.
Отчёты: HTML, PDF, Excel, JSON, CSV, XML и native-формат
Один из самых сильных модулей DupScout — отчётность. Программа умеет сохранять результаты в HTML, PDF, Excel, text, JSON, CSV и XML, а также в собственный native report format, который сохраняет всю структуру конкретной операции и может быть открыт позже в самой программе. Для регулярной работы это очень удобно: не нужно каждый раз пересканировать весь массив данных только ради повторного просмотра результатов.
Если говорить о повседневной практике, у разных форматов тут своя роль. HTML удобно открывать и быстро просматривать как визуальный отчёт. PDF полезен, когда нужно передать результат коллегам, руководителю или заказчику в устойчивом виде. Excel и CSV хороши для сортировки, постобработки и самостоятельного анализа. JSON и XML — уже скорее для интеграций, автоматизации и внешней обработки. Native-отчёт полезен в тех случаях, когда важно вернуться к конкретному состоянию поиска и продолжить работу изнутри DupScout.
Отдельного внимания заслуживает механизм summary/detailed reports. Например, для PDF DupScout предлагает PDF Summary и PDF Report. Summary-вариант показывает верхние 20 duplicate file sets по объёму lost space и снабжает их графиками, а detailed-вариант уже разворачивает полную структуру найденных наборов и списки файлов внутри них. Это очень правильное разделение: быстрый обзор — для управленческого решения, детальный отчёт — для практической разборки.
Программа умеет экспортировать не только общие результаты, но и отчёты по отфильтрованным срезам. Можно, например, работать по пользователям, по верхнеуровневым директориям, по категориям файлов и получать отдельные отчёты под эти сегменты. Для корпоративной эксплуатации это уже почти обязательная функция: одно дело — увидеть, что в хранилище много дублей, и совсем другое — показать, у какого пользователя, на каком хосте и в каком классе файлов эти дубликаты сосредоточены.
Графики и аналитика: DupScout умеет показывать не только что удалить, но и где проблема
DupScout хорош не только как duplicate files cleaner, но и как инструмент аналитики хранилища. Через кнопку Charts программа строит pie charts и timeline charts, показывающие объём duplicate disk space и число duplicate files по расширениям, категориям, датам модификации, датам создания, top-level directories и user names. Это позволяет перейти от механической очистки к пониманию структуры проблемы.
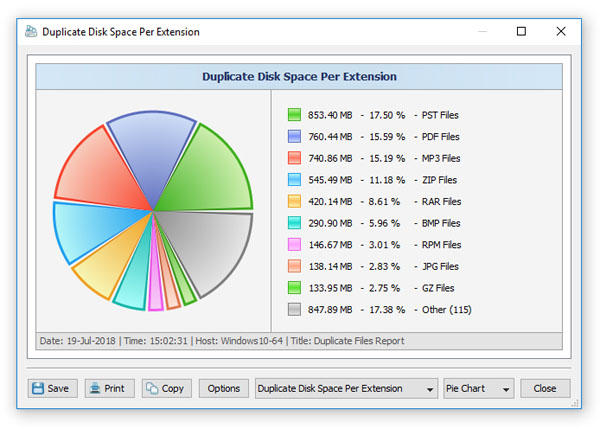
На скриншоте с диаграммой Duplicate Disk Space Per Extension видно, насколько практично устроен этот модуль. Справа сразу показаны расширения и доли, внизу есть кнопки Save, Print, Copy, Options, а также выпадающие списки режима и типа графика. То есть графики в DupScout — это не декоративное дополнение, а отдельный рабочий инструмент, который можно сохранять, копировать в документы и использовать как часть отчёта по очистке диска или аудиту файловой системы.
В реальной работе этот модуль особенно полезен в двух случаях. Первый — когда нужно быстро понять, какой тип данных больше всего плодит дубликаты: архивы, изображения, документы, видео, резервные копии. Второй — когда важно увидеть динамику по времени: в какие годы или периоды накопилось больше всего дублей, где находятся старые слои мусора, к которым можно подойти без риска для актуальной работы. Для системного администратора и аккуратного power user это одна из самых ценных сторон DupScout.
Экспорт в SQL и работа с базой данных
DupScout умеет не только сохранять отчёты в файлы, но и экспортировать duplicate files search results в SQL database через ODBC interface. Настройка выполняется в Options на вкладке Database: задаются ODBC data source name, имя пользователя, пароль и затем используется Verify для проверки соединения. После этого найденные duplicate file sets можно экспортировать через контекстное меню Export To SQL Database с указанием имени таблицы.
Для домашнего использования эта возможность может показаться избыточной. Но в рабочих и серверных сценариях она очень полезна. SQL-экспорт позволяет не просто разово сохранить отчёт, а построить централизованную базу результатов, накапливать историю, анализировать повторяемость дублей, строить внешние сводки и связывать это с другими учётными или аналитическими системами. В экосистеме обычных duplicate finder-утилит такое встречается далеко не всегда.
Именно здесь становится хорошо видно позиционирование DupScout. Программа думает не только как файловый cleaner, но и как инструмент инфраструктуры. Если пользователь хочет разложить duplicate files analysis по файлам — пожалуйста. Если нужна сводка по базе — тоже пожалуйста. Если отчёт должен стать частью регулярного процесса, тут уже есть готовые элементы для этого.
Производительность и настройка скорости
Для программы, которая может работать с большими каталогами, вопрос производительности критичен. DupScout позволяет настраивать тип сигнатуры, лимит отображаемых групп через Max Dup File Sets, число directory scanning threads, количество duplicate files search threads и performance mode. То есть скорость здесь можно адаптировать под конкретную задачу: от аккуратной обработки локального диска до более агрессивного параллельного поиска по большим хранилищам и сети.
Особенно полезно, что программа сама отделяет удобство от нагрузки. Например, обработка и отображение user names выключена по умолчанию из соображений performance, а для сетевых сценариев рекомендуется увеличивать число потоков, если эта функция включена. То есть DupScout не прячет техническую цену за дополнительные аналитические данные: пользователь понимает, что гибкость стоит ресурсов, и может сам выбирать баланс между глубиной анализа и скоростью.
Важна и другая сторона: DupScout не просто быстро сканирует, а позволяет не тонуть в результатах. Тот же Max Dup File Sets — это не косметическая настройка, а способ держать результаты управляемыми. Когда в системе сотни тысяч совпадений, намного полезнее сначала увидеть верхние группы по wasted disk space, а не пытаться пролистывать бесконечный список мелких дублей. В этом смысле программа оптимизирует не только процесс вычисления, но и сам процесс принятия решений.
Командная строка и автоматизация
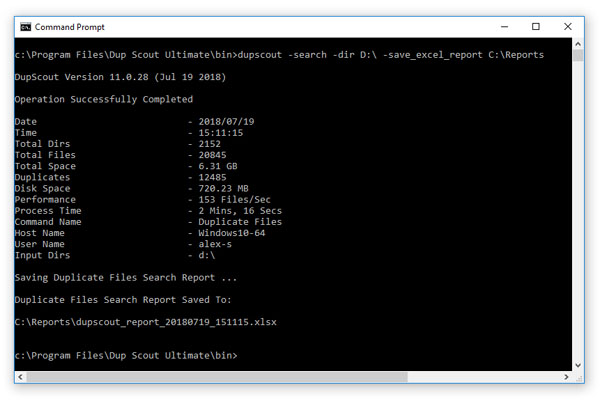
DupScout включает command line utility, которая позволяет запускать поиск и удаление дублей из shell-окна и встраивать операции в batch files и scripts. В числе базовых команд есть dupscout -execute <Profile Name>, запуск поиска по каталогам через -search -dir, работа с серверами и NAS через -search -server, а также поиск по всей сети через -search -network. Отдельными опциями сохраняются HTML, PDF, Excel, text, JSON, CSV и XML отчёты, а также выполняется запись в базу через -save_to_database.
Для обычного пользователя CLI не обязательна, но для администратора это один из самых важных аргументов в пользу DupScout. Программа перестаёт быть ручной утилитой и становится частью автоматизированного обслуживания. Можно собрать профиль, протестировать его в GUI, а затем запускать по расписанию или включать в стандартный технический сценарий. Такой путь особенно ценен в инфраструктуре, где дубликаты появляются не от случая к случаю, а как постоянный фон работы с файлами.
Серверная линия DupScout идёт ещё дальше. Server и Enterprise-варианты ориентированы на фоновые службы, несколько параллельных поисковых операций, периодические jobs, history trend analysis и веб-интерфейс управления. Для обзора именно DupScout это важно не ради перечисления редакций, а ради понимания философии продукта: даже настольная программа построена так, будто однажды может стать частью большого управляемого контура работы с файлами.
Пошаговая инструкция: как безопасно очистить дубликаты в DupScout
Шаг 1. Создайте отдельный профиль под конкретную задачу
Лучше не запускать DupScout по всей системе без подготовки. Практичнее выделить один понятный сценарий: например, дубликаты в архиве документов, дубли фото на внешнем диске, одинаковые файлы в сетевой папке проекта. В левой панели с профилями оставьте отдельный профиль под каждую такую задачу. Это поможет не путать входные папки, правила и исключения, а позже позволит вернуться к тому же сценарию без пересборки параметров.
Шаг 2. Добавьте только нужные входные каталоги
В окне Search Duplicate Files добавьте конкретные директории, которые действительно нужно проверить. Если задача — разобрать медиатеку, не стоит одновременно добавлять системный диск с пользовательскими приложениями. Если нужно обработать сетевую шару, не надо смешивать её с рабочим профилем локального диска. Чем точнее список Inputs, тем чище будет результат и тем ниже риск получить много нерелевантных совпадений.
Шаг 3. Настройте Rules до запуска сканирования
Перед началом поиска имеет смысл зайти в Options и открыть вкладку Rules. Там удобно ограничить поиск по типу данных, размеру и времени. Для практической очистки это один из лучших приёмов. Например, если вам нужно освободить место, ищите только крупные duplicate files. Если вы чистите старый архив, ограничьте анализ файлами старше нужного срока. Если задача касается фото, задайте соответствующую категорию. Такой подход резко снижает шум в результате.
Шаг 4. Заполните Exclude до первого большого запуска
Следующий обязательный шаг — вкладка Exclude. Туда стоит сразу добавить системные каталоги Windows, папки приложений, служебные каталоги кэшей, директории синхронизации, временные области и всё, что не предназначено для ручной очистки дубликатов. Если структура большая, используйте макрокоманды $BEGINS, $CONTAINS, $ENDS, $REGEX или $DIRLIST. Это делает поиск безопасным с первого же прохода.
Шаг 5. Запустите Search и сначала смотрите на верхние группы
После нажатия Search DupScout сформирует список duplicate file sets, отсортированных по объёму duplicate disk space. Именно так и стоит работать: начинайте разбор с верхних строк, потому что они дают максимальный эффект по освобождению места. Мелкие дубликаты тоже важны, но сначала лучше снять крупные пласты — большие архивы, видео, резервные копии, PST-файлы, PDF-комплекты, тяжёлые папки с одинаковым содержимым.
Шаг 6. Проверьте Categories и фильтры
Когда первый список уже на экране, переключитесь на нижний блок категорий. Посмотрите, какие расширения или типы файлов занимают максимум дублируемого пространства. Иногда это мгновенно меняет стратегию. Вместо общего разбора всего результата можно сосредоточиться только на ZIP, ISO, JPEG или PDF. Если нужно, примените фильтр по категории и работайте уже только с этой частью данных.
Шаг 7. Откройте набор и проверьте оригинал
Дальше нужно открыть конкретный duplicate set и убедиться, что DupScout правильно выбрал основной файл. По умолчанию это oldest file, но не всегда именно он должен остаться. Если более логичной является копия из актуального проекта, рабочей папки или правильного архива, выделите её и назначьте через Set as Original. Этот шаг критичен: он определяет, что сохранится после cleanup.
Шаг 8. Назначьте действие не вслепую, а по типу данных
DupScout позволяет не только удалить дубль, но и переместить его, сжать, заменить shortcut или hard link. Выбор действия зависит от типа данных. Для резервных копий и старых архивов разумен Move Duplicate Files To Directory. Для сохранения структуры без физического дублирования — Replace Duplicate Files With Shortcuts или Replace Duplicate Files With Hard Links. Для однозначно лишних копий — удаление. Чем ближе действие к реальной задаче, тем лучше результат.
Шаг 9. Обязательно используйте Preview
Это тот шаг, который нельзя пропускать. Нажмите Preview и посмотрите, какие операции DupScout реально собирается выполнить. В окне preview видно, какие файлы выбраны, какие действия будут применены и нет ли в списке спорных позиций. Именно здесь чаще всего обнаруживаются нюансы: неверно выбранный original file, дубль в служебной папке, несвоевременное удаление нужной копии. Если всё выглядит корректно, тогда уже можно переходить к Execute.
Шаг 10. Сначала сохраните отчёт, потом очищайте большие наборы
Если операция затрагивает большие объёмы данных или сетевые ресурсы, перед исполнением разумно сохранить HTML, PDF или Excel отчёт. Это даёт точку возврата на уровне анализа: всегда можно посмотреть, что было найдено, какие группы считались проблемными и почему принималось то или иное решение. Для крупных чисток это хорошая дисциплина. DupScout как раз рассчитан на такой стиль работы.
В итоге безопасная работа в DupScout выглядит так: точные входные папки, правила, исключения, просмотр категорий, ручная проверка оригинала, предпросмотр действий и только потом исполнение. Если придерживаться этой схемы, программа показывает себя очень надёжно и действительно помогает очистить диск от одинаковых файлов без лишнего риска.
Сильные стороны DupScout
У DupScout много достоинств, но самые важные можно свести к нескольким пунктам.
-
Очень сильная работа с локальными дисками, network shares и NAS, включая UNC-пути и сетевое обнаружение.
-
Продуманная модель работы с duplicate file sets, а не просто со списком совпавших файлов.
-
Мощные actions: удаление, перенос, сжатие, shortcut, hard link, preview перед исполнением.
-
Сильная аналитика: categories, filters, charts, PDF summary, Excel/CSV/JSON/XML, SQL export.
-
Профили, GUI layouts, shell extension и CLI делают программу удобной как для разового запуска, так и для повторяемой рутины.
Если перевести это в обычный язык, DupScout особенно хорош там, где дубликаты — не маленькая бытовая проблема, а заметная часть файлового хаоса. Он даёт не только механизм поиска, но и нормальный управленческий инструментарий: разобрать, понять, показать, зафиксировать, безопасно применить действие. В своей нише это очень весомое преимущество.
Что может не понравиться
Интерфейс DupScout функционален, но не пытается понравиться новичку за счёт визуальной мягкости. Здесь много рабочих панелей, параметров, вкладок и режимов. Для человека, который впервые открывает duplicate finder и ожидает одну большую кнопку очистить, программа может показаться более сложной, чем хочется. Это не недостаток логики, а скорее следствие её взрослого позиционирования.
Вторая особенность — часть действительно мощных сценариев связана с Pro/Server-линией: command line utility, rule-based removal actions, SQL database, batch network operations, history trend analysis. Даже в настольной части DupScout уже полезен, но максимальную силу продукт показывает там, где важны автоматизация, сеть и централизованная аналитика. Это нужно учитывать, если цель сводится только к разовой чистке личной папки Загрузки.
Наконец, DupScout требует дисциплины. Это не та программа, в которой стоит бездумно запускать тотальный поиск по всей системе, а потом так же бездумно исполнять действия над верхними строками. Она даёт достаточно возможностей, чтобы работать очень точно, но предполагает, что пользователь будет пользоваться ими осознанно: правилами, исключениями, preview и ручным выбором оригинала.
Сравнение с аналогами
AllDup
AllDup позиционируется как инструмент для профессионального поиска duplicate files по содержимому, свойствам файла, похожим изображениям и музыкальным трекам; в нём есть встроенный file manager, а также preview, smart marking, перемещение, копирование и отправка в корзину.
На фоне AllDup DupScout выглядит более инфраструктурно. Это мой вывод по набору акцентов в самих продуктах: AllDup сильнее ассоциируется с поиском дублей по разным критериям, похожими изображениями и классическим интерактивным разбором в файловом менеджере, а DupScout — с network shares, NAS, отчётами, графиками, SQL database и автоматизируемыми профилями. Если нужен мощный личный инструмент для ручной разборки, AllDup выглядит очень убедительно. Если нужна программа для поиска дубликатов файлов в Windows и сети с сильной аналитической частью, DupScout выглядит выигрышнее.
dupeGuru
dupeGuru строится на другой философии. Он известен fuzzy matching-алгоритмом, умеет искать совпадения по именам или содержимому, а также имеет специальные режимы для музыки и изображений. Picture mode умеет находить похожие, но не полностью одинаковые картинки, а Music mode работает с тегами и музыко-ориентированной информацией. Это делает dupeGuru очень привлекательным для домашних коллекций фото и музыки, где проблема часто состоит не только в точных дублях, но и в почти одинаковых копиях.
DupScout решает другую задачу. Его сильная сторона — точный поиск одинаковых файлов по сигнатурам, дальнейшее управление duplicate file sets, отчётность, preview, network shares и NAS. Поэтому между этими программами выбор зависит не столько от вкуса, сколько от сценария. Для фотоархива с похожими изображениями dupeGuru может быть интереснее. Для рабочего диска, файлового сервера, NAS или большого архива документов DupScout выглядит более деловым и полезным инструментом. Это уже не вопрос какая программа лучше вообще, а вопрос соответствия конкретной задаче.
Duplicate Cleaner
Duplicate Cleaner — один из самых насыщенных конкурентов. На официальных страницах он делает ставку на Selection Assistant, режимы для музыки, изображений и видео, поиск по video frames, soundtrack, audio tags, похожим изображениям, работу с архивами, фильтры по размеру и датам, а также создание shortcuts, symbolic links и hard links. По набору специализированных режимов для медиа он очень силён.
На фоне Duplicate Cleaner DupScout проигрывает именно в медиа-специализации. Если задача — разбирать похожие фотографии, видео по кадрам, аудио по звучанию и метаданным, Duplicate Cleaner выглядит богаче. Но DupScout выигрывает там, где важнее не медиа-режимы, а структурированный поиск одинаковых файлов на дисках и в сети, отчёты, SQL export, batch-подход и аналитика duplicate disk space. Для пользователя, у которого дубликаты — это прежде всего файловая инфраструктура, а не фото- и видео-библиотека, DupScout часто оказывается логичнее.
Wise Duplicate Finder
Wise Duplicate Finder — более лёгкий и массовый инструмент. Он ориентирован на Windows, ищет совпадения по file names, file sizes или file contents и после сканирования группирует результаты так, чтобы пользователь мог удалить копии вручную или автоматически. Это хороший вариант для человека, которому нужен понятный duplicate file cleaner без углубления в инфраструктурные детали.
Но именно в сравнении с Wise очень хорошо заметно, чем уникален DupScout. Wise Duplicate Finder — это история про простой поиск и удаление дублей. DupScout — это уже поиск, categorization, filters, charts, reports, SQL, network shares, NAS, preview, профили и автоматизация. В бытовом сценарии Wise может показаться проще. В рабочем и масштабируемом сценарии DupScout выглядит заметно взрослее.
Сводный взгляд на фоне конкурентов
| Программа | Сильная сторона | Где DupScout смотрится лучше |
|---|---|---|
| AllDup | Поиск по содержимому, свойствам, похожим изображениям и музыке; встроенный file manager, preview и smart marking. | Когда нужны network shares, NAS, отчёты, графики и более выраженная инфраструктурная логика. |
| dupeGuru | Fuzzy matching, Music mode и Picture mode для похожих, а не только одинаковых файлов. | Когда речь идёт о точных duplicate files в рабочих папках, архивах, сетевых ресурсах и повторяемых профилях. |
| Duplicate Cleaner | Очень сильные режимы для фото, аудио и видео, плюс Selection Assistant и богатые критерии сопоставления. | Когда важнее отчётность, duplicate disk space analytics, SQL export и сетевой контур. |
| Wise Duplicate Finder | Простота и быстрый порог входа для базового поиска дублей на Windows. | Когда нужна не только очистка, а управляемая работа с дубликатами как с предметом анализа. |
Главный вывод здесь такой: DupScout не пытается побеждать каждый аналог на его поле. Он не лучший выбор для тех, кто ищет максимально упрощённую программу или ориентируется прежде всего на похожие фото и медиа-матчинг. Зато среди инструментов, которые должны уверенно работать с точными дублями, сетевыми путями, NAS, отчётами и профилями, DupScout выглядит очень убедительно.
Кому DupScout подойдёт лучше всего
DupScout особенно уместен в нескольких сценариях.
-
Пользователь с большими архивами документов, PDF, ZIP, ISO и резервных копий, которому нужен точный поиск одинаковых файлов по содержимому.
-
Фрилансер или небольшой офис с NAS, где дубли появляются в общих папках, рабочих проектах и резервных копиях.
-
Системный администратор, которому важны profiles, reports, network shares, SQL export и CLI.
-
Power user, который хочет не просто удалить дубль, а видеть categories, filters, charts и грамотно выбирать original file.
А вот если задача сводится к простой домашней чистке без сети, без отчётов и без желания вникать в правила, DupScout может показаться слишком взрослым. В таком случае кто-то действительно комфортнее почувствует себя в более лёгкой утилите. Но если нужен обзор программы именно с позиции реальной полезности, а не только простоты входа, то DupScout оставляет очень сильное впечатление.
Итог
DupScout — это мощная программа для поиска, анализа и удаления дубликатов файлов, которая особенно хорошо раскрывается там, где объём данных уже вышел за пределы обычной домашней папки. Её сильные стороны — точный поиск по сигнатурам, понятная модель duplicate file sets, ручной выбор original file, продуманный Preview → Execute, гибкие rules и exclude-механизмы, уверенная работа с network shares и NAS, а также зрелая система отчётов и графиков.
У программы есть порог входа. Она требует внимательности, не рассчитана на бездумное нажатие одной кнопки и ожидает, что пользователь воспользуется её сильными сторонами: профилями, фильтрами, категориями, preview и точным выбором действия для дублей. Но именно за счёт этого DupScout и выигрывает. Он не обещает магию, он даёт контроль. А в теме duplicate file management контроль почти всегда важнее визуальной простоты.
Если нужен уверенный, детальный и взрослый duplicate file finder для Windows, который умеет работать не только с локальным диском, но и с сетевыми ресурсами, NAS, отчётами и автоматизацией, DupScout заслуживает очень высокой оценки. Это не очередная программа для поиска одинаковых файлов, а действительно сильный рабочий инструмент, способный как освобождать место, так и помогать разбираться в самой природе файлового хаоса.