
fdupes — это узкоспециализированная консольная утилита для поиска идентичных файлов в одной или нескольких директориях. Она не пытается быть оптимизатором системы, не чистит кэш приложений, не ищет похожие изображения по визуальному сходству и не занимается случайным системным мусором. Её задача предельно конкретна: найти файлы с одинаковым содержимым и дать удобные механизмы, чтобы эти дубликаты изучить, отсортировать и удалить. fdupes сравнивает файлы по размеру, затем по MD5-сигнатурам и после этого подтверждает совпадение побайтным сравнением. Именно поэтому утилита хорошо подходит для архивов документов, резервных копий, медиатек, папок Downloads, сборок проектов и каталогов, которые разрастались копированием и синхронизацией.
Для понимания программы важен один принцип: fdupes ищет одинаковые файлы по содержимому, а не похожие файлы по смыслу. Если у вас есть две фотографии одного и того же объекта, но сохранённые с разным качеством, разрешением или после повторного экспорта, fdupes не сочтёт их дублями. Если же содержимое полностью совпадает, утилита объединит их в одну группу совпадений. В этом её сила: результат предсказуем, строг и пригоден для безопасной файловой дедупликации без гаданий.
Ещё одна важная особенность — у fdupes нет привычного оконного интерфейса. Это не программа, в которой пользователь нажимает кнопки мышью в многооконном мастере. Здесь все рабочие элементы — это ключи командной строки, режимы вывода и интерактивные команды внутри режима удаления. Именно поэтому fdupes особенно удобен там, где важны контроль, автоматизация, пакетная обработка и работа через терминал: на Linux-машинах, серверах, NAS, в контейнерах, в удалённых SSH-сеансах и на macOS через Homebrew.
Скачать FDUPES
- Оптимизация системы
- Очистка мусора
- Ускорение ПК
- Командная строка
- Сложно новичкам
- Нет GUI-интерфейса
Как устроена работа fdupes
Базовый синтаксис у программы простой:
fdupes [options] DIRECTORY ...Уже из этого видно главное: в центре работы стоят каталоги, а не отдельные разовые файлы. Обычно fdupes запускают либо на одной конкретной папке, либо сразу на нескольких путях, между которыми нужно найти повторяющееся содержимое. По умолчанию утилита просто выводит найденные группы дублей. Никакого автоматического удаления в стандартном режиме нет. Это правильное поведение: сначала пользователь видит результат, потом решает, что с ним делать.
В обычном выводе fdupes показывает каждую группу дублей отдельно: один файл — одна строка, а группы разделяются пустыми строками. Это очень удобный формат для ручной проверки. Вы сразу видите, какие файлы принадлежат к одной группе совпадений, а какие относятся к другой. Если нужен компактный вывод, есть режим -1 или --sameline, который размещает каждый набор совпадений в одну строку. Для терминальной автоматизации и последующей обработки скриптами это часто полезнее стандартного блочного вывода.
В повседневной работе fdupes закрывает несколько очень конкретных задач:
-
находит полные копии файлов в одной папке;
-
ищет дубликаты рекурсивно во вложенных каталогах;
-
помогает понять, сколько места съедают повторяющиеся копии;
-
позволяет учитывать или игнорировать скрытые файлы, пустые файлы, hard links и symlinked directories;
-
даёт интерактивный и неинтерактивный режим удаления;
-
умеет сортировать файлы в найденных наборах по имени, времени изменения и времени изменения статуса;
-
может журналировать решения об удалении;
-
поддерживает кэш сигнатур, чтобы ускорять повторные прогоны по большим деревьям каталогов.
Установка и первый запуск
В Linux fdupes обычно ставят из репозитория пакетов. На системах семейства Debian и Ubuntu команда выглядит так:
sudo apt install fdupesНа macOS через Homebrew используется команда:
brew install fdupesЭтого достаточно, чтобы получить рабочую утилиту и сразу перейти к поиску дубликатов файлов.
После установки логично начинать не с удаления, а с самого безопасного сценария — обычного сканирования каталога без destructive-действий. Минимальная команда выглядит так:
fdupes ~/DocumentsОна просто выведет найденные группы одинаковых файлов в указанной папке. Ничего удалено не будет. Это лучший первый шаг, потому что пользователь сразу понимает, как именно fdupes группирует совпадения и какие каталоги на его машине дают наибольшее количество дублей.
Если нужно быстро убедиться, что утилита установилась корректно и какие режимы она поддерживает, стоит вызвать справку:
fdupes --helpИменно с --help удобно знакомиться со структурой программы: здесь видны основные ключи для рекурсии, фильтрации, вывода, удаления, сортировки и журналирования. У fdupes нет главного окна и панели кнопок, поэтому справка фактически выполняет роль карты интерфейса.
Интерфейс программы: вместо кнопок — ключи, режимы и команды
Если рассматривать fdupes как полноценный программный интерфейс, то его рабочими элементами являются:
-
ключи запуска вроде
-r,-S,-m,-d; -
режимы вывода вроде
--sameline,--summarize,--quicksummary; -
режимы удаления вроде
--delete,--plain,--noprompt,--immediate; -
команды интерактивной сессии вроде
prune,sel,ks,ds,help,exit; -
клавиши навигации внутри screen-mode интерфейса —
PAGE DOWN,PAGE UP,TAB,BACKSPACE,F2,F3,SHIFT + RIGHT,SHIFT + LEFT,?.
Это важно понимать заранее. Если desktop-программа для поиска дублей обычно ведёт пользователя через панель Scan, список результатов и кнопку Delete, то у fdupes логика другая: сначала правильно сформулировать команду, затем оценить вывод, затем выбрать режим удаления. Зато именно эта логика делает утилиту очень точной. Она не навязывает лишние действия, а позволяет собрать под себя ровно тот сценарий, который нужен.
Как fdupes определяет дубликаты
Поиск дубликатов файлов здесь не сводится к сравнению имён. fdupes не интересует, называется ли файл photo.jpg, photo_copy.jpg или archive-final-final.zip. Программа смотрит на содержимое. Алгоритм практический и последовательный: сначала сравниваются размеры файлов, потом MD5-сигнатуры, а затем проводится побайтная проверка. Такой подход одновременно ускоряет предварительный отсев и сохраняет точность финального подтверждения дубля.
Именно поэтому fdupes полезен в реальных задачах, где имена давно потеряли смысл. Например:
-
один и тот же PDF лежит в папках
Downloads,Work,Archive; -
несколько одинаковых JPEG были скопированы из телефона, мессенджера и облачной синхронизации;
-
один и тот же ISO-образ случайно хранится в двух бэкапах;
-
проектные ассеты размножились копированием между ветками и тестовыми каталогами;
-
музыкальный файл был продублирован переименованием, но содержимое не изменилось.
Здесь и проходит граница между duplicate file finder и инструментами для поиска похожих объектов. fdupes блестяще решает задачу строгой дедупликации, но не занимается fuzzy matching по картинкам, тегам или именам. Для этого класса задач существуют другие программы.
Базовый поиск дубликатов в одной папке
Самый простой режим — сканирование одной директории без рекурсии:
fdupes ~/DocumentsВ таком режиме программа просматривает только содержимое указанной папки. Если в ней есть две одинаковые копии документа, изображения, архива или бинарника, fdupes выведет их в одну группу. Это удобный сценарий для чистки Downloads, Desktop, временных экспортов или любого каталога, где дубликаты образуются буквально на поверхности и не прячутся в десятках вложенных папок.
На практике такой вывод читается очень легко. Если вы видите несколько строк подряд, а затем пустую строку, это означает один набор дублей. Следующий блок после пустой строки — уже другая группа совпадений. Когда задача состоит именно в ручной проверке архивов, такой формат лучше большинства GUI-списков: меньше визуального шума, меньше случайных кликов, выше концентрация на путях и файлах.
Рекурсивный поиск: -r и -R --recurse:
Настоящая сила fdupes раскрывается на больших деревьях каталогов. Для рекурсивного поиска используется ключ:
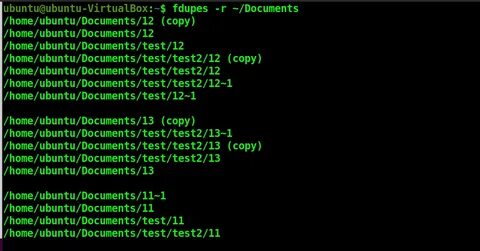
fdupes -r ~/DocumentsС ним программа заходит во все вложенные папки и ищет одинаковые файлы уже по всему дереву. Если дубликаты разбросаны по подкаталогам, именно -r превращает локальный просмотр в полноценный рекурсивный поиск дублей.
Есть и более тонкий вариант — -R --recurse:. Этот ключ отличается от обычного -r тем, что применяет рекурсию только к тем директориям, которые идут после него в командной строке. Пример очень показателен:
fdupes a --recurse: bВ таком случае подкаталоги будут просматриваться только у b, а у a — нет. Это очень удобный режим, когда нужно сравнить, например, плоский эталонный каталог с другим деревом каталогов, не раздувая зону поиска там, где рекурсия не нужна.
Для практики это один из самых полезных приёмов в программе. Представьте ситуацию: у вас есть одна папка с чистым набором мастер-файлов и другая папка с копиями, выгрузками и служебными подкаталогами. -R --recurse: позволяет не строить лишних обходных путей и не смешивать сценарии. Для power user это почти всегда полезнее, чем бездумно запускать -r на всё подряд.
Работа с symlinked directories и hard links
У fdupes есть два режима, которые заметно меняют логику анализа: -s --symlinks и -H --hardlinks. Они нужны не всем, но знать о них необходимо.
-s --symlinks
Ключ -s заставляет программу следовать symlinked directories. Если в вашей файловой структуре есть символьные ссылки на каталоги, fdupes сможет пройти через них и включить их содержимое в поиск. Это полезно в сложных деревьях данных, но требует аккуратности: при удалении вместе с --delete можно случайно сохранить ссылку и удалить файл, на который она указывает. Именно поэтому режим с симлинками — не то, что стоит включать автоматически.
-H --hardlinks
По умолчанию fdupes не считает дублями несколько имён, которые указывают на один и тот же физический участок диска. То есть hard links обрабатываются как особый случай и не попадают в дубликаты автоматически. Ключ -H --hardlinks меняет это поведение и разрешает рассматривать такие файлы как совпадения. На серверах, в хранилищах и при работе с заранее дедуплицированными данными это бывает важно. В домашней повседневной чистке режим нужен реже.
Фильтры, которые реально экономят время
fdupes особенно хорош не тем, что просто умеет искать одинаковые файлы, а тем, что умеет сужать поиск. Когда каталогов много, фильтры спасают и время сканирования, и нервы при анализе результата.
Исключение пустых файлов: -n --noempty
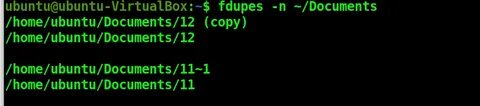
fdupes -n ~/DocumentsЕсли в рабочих папках встречаются нулевые файлы, служебные заглушки, пустые логи и временные артефакты, ключ -n исключает их из рассмотрения. Это делает отчёт чище и сразу убирает шум. Для больших архивов проектов этот флаг очень полезен.
Исключение скрытых файлов: -A --nohidden
fdupes -A ~/DocumentsКлюч -A убирает из поиска скрытые файлы. В Linux и macOS это особенно актуально, потому что в глубоких каталогах часто накапливаются скрытые служебные элементы, которые не стоит смешивать с пользовательскими данными. При быстрой чистке фотоархива, папки документов или экспорта медиа этот фильтр помогает сосредоточиться на видимом содержимом.
Ограничение по размеру: -G --minsize и -L --maxsize
fdupes -G 1048576 ~/Documentsfdupes -L 10485760 ~/Documents-G задаёт минимальный размер файла в байтах, -L — максимальный. Это один из самых недооценённых инструментов программы. Когда нужно найти только тяжёлые повторяющиеся архивы или видео, нижний порог резко сокращает объём лишней мелочи. Когда, наоборот, нужно разгрести кучу мелких дубликатов в рабочей папке, верхний порог позволяет не трогать большие образы, бэкапы и медиафайлы.
Форматы вывода: как читать результаты и извлекать из них максимум
fdupes умеет не только печатать наборы совпадений, но и показывать дополнительную информацию, которая реально помогает в чистке данных. Главное — понимать, какой режим для чего нужен.
-S --size: размер каждой группы дублей
fdupes -S ~/DocumentsЭтот режим добавляет размер повторяющихся файлов. Для быстрой оценки пользы от дедупликации он очень удобен: вы сразу видите, какие группы почти ничего не дают по месту, а какие действительно отъедают пространство на диске. Когда в архиве тысячи совпадений, именно размер помогает расставить приоритеты.
-t --time: время изменения
fdupes -t ~/DocumentsЕсли важен не только факт совпадения, но и хронология, ключ -t показывает время модификации файлов. Это полезно при выборе, что оставить: старую исходную копию, более свежий экспорт или файл из последнего резервного набора. В связке с сортировкой по времени это особенно удобно.
-m --summarize: краткая сводка по количеству и объёму
fdupes -m ~/DocumentsЭто один из лучших режимов для первого анализа каталога. Вместо длинного списка путей вы получаете краткое суммарное сообщение: сколько дублей найдено, в скольких наборах и какой объём они занимают. Для аудита папок этот режим идеален: сначала смотрите суммарную цифру, потом переходите к детальному разбору только там, где это оправдано.
-M --quicksummary: быстрая суммаризация
fdupes -M ~/DocumentsРежим --quicksummary делает суммаризацию быстрее, потому что пропускает более медленное финальное подтверждение побайтного совпадения. Практический смысл здесь понятен: когда нужно очень быстро прикинуть масштаб проблемы на большом дереве каталогов, -M даёт ответ раньше. Но для окончательных решений об удалении надёжнее полноценный режим, где совпадение подтверждено полностью. --quicksummary хорош как быстрый предварительный аудит, а не как последний шаг перед чисткой.
-q --quiet: отключение индикатора прогресса
fdupes -q -r ~/DocumentsЭтот ключ прячет индикатор прогресса. На интерактивной рабочей машине он нужен не всегда, а вот в логах, скриптах и автоматизированных конвейерах тихий режим делает вывод заметно чище.
-f --omitfirst: не показывать первый файл в наборе
fdupes -f ~/DocumentsКлюч -f убирает из вывода первый файл в каждой группе совпадений. Практический смысл простой: иногда пользователя интересуют именно лишние копии, а не весь набор целиком. Это полезно в связке со скриптами и полуавтоматическими сценариями анализа.
-1 --sameline: одна группа — одна строка
fdupes -1 ~/DocumentsЕсли вы строите обработку через shell-инструменты, --sameline делает данные компактнее. При этом нужно помнить, что в таком режиме пробелы и обратные слэши в имени файла экранируются. Для глазами читаемого вывода это не самый приятный вариант, зато для последующей фильтрации, парсинга и быстрой выжимки он очень удобен.
Кэш сигнатур: как ускорить повторные прогоны
Для больших каталогов у fdupes есть режим -c --cache. Он ускоряет повторные проверки, потому что хранит сигнатуры файлов в базе. Если вы регулярно сканируете один и тот же массив данных — например, архив фото, коллекцию образов, набор бэкапов или рабочую файловую свалку — кэш заметно сокращает время на повторные проходы.
У кэша есть дополнительные параметры, которые задаются через -x cache.OPTION:
-
readonly— читать сигнатуры, но не обновлять их; -
prune— почистить из кэша записи-сироты; -
clear— очистить кэш; -
vacuum— сократить размер базы, если это возможно.
Это уже режим для тех, кто работает с fdupes системно, а не от случая к случаю. Если запуск делается один раз в полгода ради чистки папки Downloads, кэш не даёт особой выгоды. Но если дедупликация — регулярная задача, --cache делает утилиту заметно взрослее и практичнее.
Сортировка результатов
Внутри набора совпадений порядок файлов тоже имеет значение. Для этого используются -o --order=WORD и -i --reverse. В качестве значения у --order доступны:
-
time— сортировка по времени изменения; -
ctime— сортировка по времени изменения статуса; -
name— сортировка по имени файла.
Практически это очень полезно. Если вы хотите оставлять самые свежие версии — сортируете по времени. Если хотите оставить аккуратно названный эталон и удалить копии вроде file (copy).txt, логичнее сортировать по имени. Если порядок нужно инвертировать, добавляется -i --reverse. Такие мелочи заметно ускоряют ручной выбор файлов в интерактивной чистке.
Удаление дубликатов: где начинается настоящая работа
Режим удаления запускается через -d --delete:
fdupes -d ~/DocumentsВ этом режиме программа не просто печатает группы совпадений, а предлагает выбрать, какие файлы сохранить, а какие удалить. Это уже не просто duplicate file finder, а полноценный инструмент дедупликации с управляемым сценарием очистки. Именно в таком режиме fdupes чаще всего используют после предварительного анализа через -m, -S или обычный рекурсивный списо
В документации важно две вещи. Во-первых, --delete удаляет все файлы в наборе, кроме тех, которые пользователь явно сохраняет. Во-вторых, в зависимости от окружения fdupes может работать либо в screen-mode интерфейсе, либо в line-based prompt. Принудительно включить старый построчный режим позволяет ключ -P --plain. Если экранный интерфейс не поддерживается, line-based поведение используется автоматически.
-N --noprompt
fdupes -d -N ~/DocumentsЭтот режим говорит программе: в каждом наборе дублей сохранить первый файл, а остальные удалить без дополнительных вопросов. Это очень мощная опция, но использовать её без предварительного анализа не стоит. Она хороша только там, где структура каталога уже изучена и порядок файлов заранее понятен.
-I --immediate
fdupes -I ~/DocumentsРежим --immediate удаляет дубликаты по мере нахождения, не группируя их в полноценные наборы. Он автоматически подразумевает --noprompt. Это уже инструмент для очень уверенных сценариев и автоматизации, а не для спокойной ручной чистки. На личных архивах, где важна вдумчивая проверка, режим избыточно агрессивен.
-D --deferconfirmation
fdupes -d -D ~/DocumentsЭтот ключ откладывает побайтное подтверждение дублей в интерактивном режиме до момента непосредственно перед удалением. Для обычного пользователя это не первая опция, о которой нужно помнить, но в длинных интерактивных сессиях она бывает полезной.
-l --log=LOGFILE
fdupes -d -l cleanup.log ~/DocumentsЕсли нужна трассировка решений, подключается логирование. В большой чистке каталогов это сильный режим: потом можно проверить, что именно было удалено, как принимались решения и в каком порядке обрабатывались группы. Для рабочей среды, общей файловой помойки или тех случаев, когда хочется оставить себе след операций, лог — очень разумная практика.
Подробно про интерактивный screen-mode интерфейс
Когда fdupes --delete работает в экранном режиме, он показывает список дублей и приглашает пользователя к дальнейшим действиям. Это уже не просто одноразовая строка приглашения, а полноценная интерактивная сессия навигации и пометки файлов.
Навигация по списку
Для прокрутки и перемещения курсора используются следующие клавиши:
-
PAGE DOWN— следующая страница; -
PAGE UP— предыдущая страница; -
SHIFT + DOWN— прокрутка на одну строку вниз; -
SHIFT + UP— прокрутка на одну строку вверх; -
DOWN— перейти к следующему файлу; -
UP— вернуться к предыдущему файлу; -
TAB— перейти к следующему набору дублей; -
BACKSPACE— перейти к предыдущему набору; -
F3— перейти к следующему выбранному набору; -
F2— перейти к предыдущему выбранному набору; -
goto <index>— сразу перейти к нужному набору по номеру.
Такой набор навигации показывает, что fdupes рассчитан не только на мини-папку с тремя копиями файлов. Утилита нормально чувствует себя и в больших сессиях, где дублей десятки или сотни групп, и пользователю нужно быстро перескакивать между выбранными наборами.
Пометка файлов через курсор
Текущий файл под курсором можно размечать так:
-
SHIFT + RIGHT— пометить файл к сохранению; -
SHIFT + LEFT— пометить файл к удалению; -
?— снять пометку.
Это очень удобная логика: не нужно сразу удалять, можно сначала пройтись по нескольким группам, аккуратно расставить пометки и только потом запускать фактическое удаление. Такой подход снижает риск ошибки и позволяет работать пакетно, но без потери контроля.
Выбор по номерам внутри текущей группы
Внутри набора дублей можно просто ввести список индексов через запятую. Например:
1, 3После нажатия ENTER fdupes пометит файлы 1 и 3 как сохраняемые, а остальные в текущем наборе — как удаляемые. Команда all помечает все файлы как сохраняемые. Команда rg снимает все пометки в текущем наборе. Это один из самых удобных способов работы, когда вы быстро видите набор из трёх-четырёх файлов и сразу понимаете, какой оставить.
Команды выбора по тексту и шаблону пути
fdupes умеет выделять файлы по содержимому пути. Это один из самых сильных элементов программы. Доступны команды:
-
sel <text>— выбрать все файлы, в пути которых есть заданный текст; -
selb <text>— выбрать файлы, путь которых начинается с текста; -
sele <text>— выбрать файлы, путь которых заканчивается текстом; -
selm <text>— выбрать файлы, чей путь совпадает с текстом полностью; -
selr <expression>— выбрать по регулярному выражению.
Есть и обратные варианты:
-
dsel <text>; -
dselb <text>; -
dsele <text>; -
dselm <text>; -
dselr <expression>.
Дополнительно доступны:
-
csel— очистить все выборы; -
isel— инвертировать выделения внутри выбранных наборов.
Это очень мощно в больших каталогах. Например, если вы хотите удалить всё, что находится внутри Backup/Old/, но сохранить копии из Projects/Master/, вам не нужно вручную размечать каждый файл. Можно работать по частям пути и быстро применять правила к целым группам. Именно здесь fdupes превращается из простого CLI-поисковика дублей в серьёзный инструмент для структурированной файловой чистки.
Команды пометки уже выбранных файлов
После выделения файлов можно применить к ним действия:
-
ks— пометить выбранные файлы к сохранению; -
ds— пометить выбранные файлы к удалению; -
rs— снять пометки с выбранных файлов.
Фактическое удаление
Когда всё размечено, удалить файлы можно двумя способами:
-
клавишей
DELETE; -
командой
prune.
При этом действует важная защита: fdupes не позволит удалить все файлы из набора, если ни один не отмечен к сохранению. Чтобы операция прошла, хотя бы один файл должен остаться. Это очень правильный предохранитель, который защищает от грубых ошибок в массе однотипных решений.
Выход и помощь
Внутри интерактивной сессии доступны команды:
-
help— показать справку; -
exitилиquit— выйти из программы.
Практический сценарий №1: безопасный аудит папки без удаления
Если задача — сначала понять масштаб проблемы, а не сразу чистить каталог, оптимальный порядок действий такой:
fdupes -m ~/Documentsfdupes -S ~/Documentsfdupes -r ~/DocumentsСначала вы видите общую сводку, потом размеры, затем полный список. Такой порядок хорош тем, что мозг не тонет в списках с самого начала. Сначала появляется количественная оценка, потом приоритизация по объёму, затем — детальный просмотр путей. Для домашнего архива это, пожалуй, самый удобный сценарий.
Если архив содержит много технического мусора, его лучше сразу слегка отфильтровать:
fdupes -r -n -A ~/DocumentsТак вы исключите пустые и скрытые файлы, а значит получите более осмысленную картину именно пользовательских данных.
Практический сценарий №2: понять, сколько места съедают дубли
Когда пространство на диске заканчивается, самое полезное — не просто список совпадений, а быстрый ответ на вопрос: сколько места реально можно вернуть. Для этого лучше всего подходят две команды:
fdupes -m -r ~/Archivefdupes -S -r ~/ArchiveПервая показывает общее количество дублей и объём, вторая помогает понять, какие группы особенно тяжелы. Такой тандем очень удобен для папок с видео, образами, архивами и проектными сборками.
Если каталог огромный, а вам нужен только быстрый предварительный замер, пригодится и такой вариант:
fdupes -M -r ~/ArchiveОн быстрее выдаст общую картину и позволит решить, стоит ли уже запускать полноценный углублённый проход.
Практический сценарий №3: чистка нескольких каталогов сразу
Одна из сильных сторон fdupes — работа сразу с несколькими путями:
fdupes ~/Downloads ~/Documents ~/ArchiveЭто полезно, когда один и тот же файл путешествует между несколькими папками: был скачан, потом скопирован в документы, потом снова попал в архив. В таком режиме программа ищет повторы между всеми указанными директориями, а не только внутри каждой по отдельности. Именно это делает fdupes хорошим инструментом для сравнения рабочих папок и бэкап-деревьев.
Если одну папку нужно просматривать без рекурсии, а другую — рекурсивно, как раз пригодится -R --recurse::
fdupes master --recurse: archiveДля сравнения эталонного каталога с глубоким архивом это очень удачная конструкция.
Практический сценарий №4: аккуратное интерактивное удаление
Для ручной дедупликации безопаснее всего идти так:
fdupes -r ~/Archivefdupes -S -r ~/Archivefdupes -d -r ~/ArchiveСначала список, затем размеры, потом удаление. Внутри удаления разумно ориентироваться на три принципа:
-
сохранять файлы в главной рабочей папке, а не во временных подкаталогах;
-
обращать внимание на сортировку и время изменения;
-
использовать выбор по путям через
sel, если структура папок понятна и повторяется.
Если нужен именно старый построчный режим, без screen-mode интерфейса, можно запускать так:
fdupes -d -P -r ~/ArchiveЭто удобно тем, кто привык к классическому line-based prompt и хочет отвечать набором номеров прямо в терминале.
На что программа рассчитана лучше всего
fdupes особенно хорош в следующих сценариях:
-
папка
Downloads, где образуются несколько одинаковых копий одного и того же файла; -
архив PDF, EPUB, ZIP и ISO, накопленный из разных источников;
-
коллекции фото и видео, где много точных копий одного и того же файла;
-
каталоги проектов, куда ассеты копировались между версиями;
-
резервные директории с одинаковыми выгрузками;
-
сравнение рабочего и архивного дерева каталогов.
Там, где нужна строгая проверка одинаковости данных, утилита работает очень уверенно. Она не отвлекает на второстепенные сущности и не выдумывает лишних метрик похожести. Это именно тот случай, когда программа делает немногое, но делает это правильно.
Чего fdupes не делает
Границы программы тоже нужно понимать заранее. fdupes:
-
не ищет похожие картинки по визуальному сходству;
-
не анализирует музыкальные теги;
-
не ищет дубли по похожим именам;
-
не показывает предпросмотр изображений;
-
не даёт графическое окно для мышиного выбора;
-
не является системным cleaner в широком смысле.
Это не недостаток как таковой. Это просто характер инструмента. Если вам нужен консольный duplicate file finder для точного поиска одинаковых файлов по содержимому — fdupes на месте. Если нужен визуальный разбор похожих фотографий, музыкальных дублей или fuzzy-поиск по именам — это уже зона других программ.
Безопасность: реальные риски и как их избежать
Главное правило при работе с fdupes очевидно: не начинать сразу с удаления. Сначала просмотреть список, потом размеры, и только затем включать --delete. Документация отдельно предупреждает, что режим -d требует осторожности из-за риска потери данных.
Есть два особенно важных риска.
Риск с симлинками
Если использовать --delete вместе с -s --symlinks, можно случайно сохранить символьную ссылку и удалить тот файл, на который она указывает. То есть формально что-то осталось, но практический полезный файл может исчезнуть. Для сложных деревьев каталогов это реальная проблема, а не теоретическая.
Риск при повторном указании одной и той же директории
Если один и тот же каталог передан в команду больше одного раза, файлы внутри него будут показаны как дубликаты самих себя. Это уже прямой путь к разрушительной ошибке: пользователь может сохранить один файл и удалить его дубликат, который на самом деле является тем же самым файлом в повторно указанном пути. Для fdupes это один из ключевых caveats, который действительно нужно помнить.
Практические правила безопасной чистки
-
не используйте
-Nи тем более-I, пока не проверили структуру каталога обычным списком; -
не включайте
-s, если не уверены, как устроены симлинки в дереве данных; -
не передавайте один и тот же путь дважды;
-
на больших архивах сначала работайте через
-mи-S; -
если удаление идёт по серьёзному объёму данных, ведите лог через
-l.
Производительность и ощущение от работы
По ощущениям fdupes — это классическая, зрелая CLI-утилита без украшательств. Она не перегружает интерфейс, не пытается угадать за пользователя, не распыляется на десятки типов мусора. В небольших каталогах она работает прямо и быстро. В больших массивах начинает особенно цениться её структурность: фильтры, суммаризация, кэш, сортировка, тихий режим и разные сценарии удаления.
При этом важно понимать: по меркам современных duplicate finder CLI-утилит fdupes — не самый навороченный инструмент на рынке. Но он остаётся очень удобным именно благодаря предсказуемости. Это утилита, которую легко встроить в личный рабочий процесс и так же легко объяснить другому человеку.
Сильные стороны программы
1. Строгая и понятная логика поиска
fdupes не путает одинаковые файлы с похожими. Если программа показывает дубликат, речь идёт именно о совпадении по содержимому. Для многих сценариев это лучший возможный вариант.
2. Отличная пригодность для терминала и автоматизации
Тихий режим, однострочный вывод, сводки, сортировка, фильтры, логирование, кэш — всё это делает fdupes удобным элементом shell-процессов и скриптов.
3. Сильный интерактивный режим
Многие пользователи думают, что CLI-утилита с удалением будет примитивной. У fdupes всё наоборот: screen-mode интерфейс с навигацией, выбором по тексту пути, инверсией селекции и явной пометкой файлов даёт очень приличный уровень контроля.
4. Полезная суммаризация
Режимы -m, -M и -S экономят массу времени. Программа хорошо подходит не только для немедленного удаления, но и для аудита хранилища.
5. Узкая специализация
fdupes делает одну вещь, но делает её последовательно. Это программа не про сто функций сразу, а про точный и контролируемый поиск одинаковых файлов.
Слабые стороны программы
1. Отсутствие GUI
Для новичка это всё же барьер. У программы нет окна предпросмотра, панели действий и мышиного выбора в привычном виде. Если пользователь боится терминала, входной порог будет выше.
2. Нет работы с похожими файлами
Там, где нужен fuzzy matching по именам, музыке или картинкам, одной fdupes уже мало.
3. Режимы удаления требуют дисциплины
-d, -N и особенно -I — это не шутка. Программа даёт мощный контроль, но ответственность тоже полностью на пользователе.
Сравнение с аналогами
Когда речь идёт именно о сравнении реальных программ-аналогов, fdupes почти всегда сопоставляют с jdupes, rmlint, dupeGuru и fclones. Эти инструменты решают похожую задачу, но делают это по-разному.
fdupes и jdupes
jdupes вырос из той же идеи, но пошёл дальше в сторону расширенных действий над найденными копиями. Он умеет не только удаление, но и hard linking, symlinking и block-level deduplication, а также позиционируется как более быстрый инструмент. При этом сам проект подчёркивает повышенное внимание к безопасности данных и даёт более широкий набор продвинутых функций.
На практике разница ощущается так: fdupes проще и прямолинейнее, а jdupes богаче по возможностям и агрессивнее ориентирован на опытного пользователя. Если нужен минималистичный, понятный duplicate file finder для типового поиска и удаления дублей — fdupes очень удобен. Если нужны расширенные действия над совпадениями и более современный CLI-арсенал — jdupes выглядит мощнее.
fdupes и rmlint
rmlint — это уже не просто утилита для duplicate files. Он ищет и дубликаты файлов и директорий, и пустые каталоги, и битые symlink’и, и прочий filesystem lint. Важнейший практический момент: сам rmlint не удаляет файлы напрямую, а создаёт исполняемый вывод, например shell script, через который уже можно проводить очистку. Кроме того, у него есть отдельный GUI-frontend Shredder.
Поэтому rmlint уместнее там, где задача шире, чем обычная дедупликация. Если вам нужен именно точный и относительно простой поиск одинаковых файлов по содержимому, fdupes читается легче и настраивается быстрее. Если же нужно комплексно разбирать файловую свалку как систему — rmlint объективно функциональнее.
fdupes и dupeGuru
dupeGuru — это другой класс удобства. Это GUI-программа, умеющая сканировать не только содержимое, но и имена файлов, причём для имён используется fuzzy matching. У неё есть отдельные режимы Standard, Music и Picture, а Picture mode умеет искать похожие изображения, а не только точные копии. Программа также позволяет перемещать, копировать и удалять найденные файлы через графический интерфейс.
Именно поэтому dupeGuru лучше чувствует себя в домашнем мультимедийном сценарии, где пользователю нужен визуальный разбор похожих фотографий или музыкальных дублей. fdupes в этом сравнении выигрывает там, где нужен терминал, строгая дедупликация и сценарии автоматизации. Проще говоря: dupeGuru — для визуальной и более человеческой работы, fdupes — для строгой CLI-дедупликации.
fdupes и fclones
fclones — современный высокопроизводительный CLI-инструмент с очень серьёзным упором на скорость и масштаб. Он реализован на Rust, умеет параллельно обходить деревья каталогов, фильтровать пути по glob и regex, работать с несколькими корнями, использовать persistent cache, выдавать JSON и удалять либо заменять копии разными способами. Проект отдельно подчёркивает оптимизации под SSD и HDD, работу с миллионами путей и бережное отношение к page cache.
В сравнении с ним fdupes выглядит гораздо проще и классичнее. Но именно это для многих остаётся достоинством. fclones интереснее на огромных массивах и в сложных автоматизированных пайплайнах, а fdupes — в тех случаях, где нужен быстрый, понятный и предсказуемый инструмент без лишней концептуальной тяжести.
Сводное сравнение
| Программа | Главный профиль | GUI | Поиск похожих, а не только идентичных | Подходит для автоматизации | Характер работы |
|---|---|---|---|---|---|
| fdupes | Строгий поиск одинаковых файлов по содержимому | Нет | Нет | Да | Минималистичный и предсказуемый |
| jdupes | Продвинутый CLI с дополнительными действиями над дублями | Нет | Нет акцента на fuzzy-поиск | Да | Более широкий и более мощный CLI |
| rmlint | Дубликаты и прочий filesystem lint | Есть отдельный GUI Shredder | Не про похожие картинки | Да | Комплексный анализ файловой системы |
| dupeGuru | GUI-поиск дублей по именам, содержимому, музыке и изображениям | Да | Да, в том числе по картинкам и именам | Ограниченно | Визуальная работа |
| fclones | Высокопроизводительная дедупликация больших наборов данных | Нет | Нет фокуса на fuzzy matching | Да, очень хорошо | Современный heavy-duty CLI |
Кому fdupes подходит лучше всего
fdupes стоит выбирать в трёх типовых ситуациях.
1. Нужен именно поиск одинаковых файлов по содержимому
Если задача — найти точные копии и больше ничего, программа работает очень чисто и по делу. Без маркетинговой магии, без расплывчатых критериев похожести, без лишних сущностей.
2. Работа идёт через терминал
На Linux, на сервере, по SSH, в shell-процессах, внутри регулярных обслуживающих сценариев fdupes чувствует себя естественно. Он не требует GUI и не упирается в десктопный сценарий использования.
3. Нужен аккуратный, контролируемый cleanup
Интерактивный режим, выбор по путям, логирование и предохранители в удалении делают утилиту удобной для вдумчивой чистки, а не только для грубого массового удаления.
Кому лучше посмотреть на другие решения
Если нужен визуальный интерфейс, предпросмотр и работа с похожими фотографиями, логичнее смотреть на dupeGuru. Если нужна более широкая зачистка файловой системы, а не только duplicate files, лучше подойдёт rmlint. Если важны расширенные действия над дублями и более современный CLI-функционал, есть смысл выбрать jdupes. Если задача — high-performance дедупликация массивов данных с глубокой автоматизацией, интереснее выглядит fclones.
Итоговый вердикт
fdupes — это очень удачная программа для тех, кому нужен не абстрактный очиститель, а конкретный инструмент поиска и удаления дубликатов файлов. Она точна, последовательна, хорошо чувствует себя в терминале, не расползается в лишние функции и при этом даёт всё необходимое для серьёзной работы: рекурсивный поиск, фильтрацию, суммаризацию, сортировку, кэш, интерактивное и неинтерактивное удаление, а также весьма сильный режим экранного выбора.
Её главный плюс в том, что она решает задачу строгой дедупликации без двусмысленности. Главный минус — отсутствие графического комфорта и любого fuzzy-поиска. Но если смотреть именно на класс CLI-утилит для поиска одинаковых файлов, fdupes остаётся очень сильным и практичным выбором. Для Linux-пользователя, администратора, разработчика или просто аккуратного power user это одна из тех программ, которые быстро становятся постоянной частью рабочего набора.