
Duplicate File Detective — это не просто duplicate file finder в духе запустил, посмотрел список, удалил лишнее. У программы другой характер. Она рассчитана на аккуратную дедупликацию файлов, на повторяемые сценарии работы и на случаи, когда важно не только найти одинаковые файлы, но и понять, откуда они взялись, как именно их обрабатывать и как не сломать структуру хранилища после очистки. Именно поэтому у нее есть проектная логика, мастер настройки поиска, гибкие comparison options, SmartMark, Duplicate File Manager, отчеты по типам и владельцам файлов, встроенный scheduler и возможность заменять удаленные копии ссылками на оригинал.
Если нужен обзор программы для поиска дубликатов файлов в Windows, то Duplicate File Detective интересна тем, что работает не только в формате почистить папку Загрузки, но и в сценариях с несколькими локальными путями, сетевыми папками, NAS, повторными проверками и отчетами для последующего анализа. Программа умеет искать дубли на нескольких local и network paths за один проход, поддерживает master search paths, экспортирует результаты в HTML, CSV, PDF, XML и Excel, а XML-отчеты можно потом импортировать обратно и продолжать анализ без повторного сканирования.
В результате Duplicate File Detective хорошо подходит не только для освобождения места на диске, но и для наведения порядка в файловых архивах, общих хранилищах отделов, фото- и медиа-библиотеках, резервных копиях, рабочих папках и старых сетевых шарах, где годами копились одинаковые документы, изображения, архивы и мультимедиа. При этом сильная сторона программы не в агрессивном удалении, а в контролируемой дедупликации: сначала точный поиск, потом анализ групп, затем маркировка, и только после этого — move, zip или delete.
Скачать Duplicate File Detective
- Оптимизация системы
- Очистка мусора
- Ускорение ПК
- Только дубликаты
- Платная лицензия
- Сложно новичкам
Что представляет собой Duplicate File Detective на практике
Если говорить по сути, Duplicate File Detective — это программа для удаления дублей файлов с акцентом на точность поиска и управляемость результата. Она умеет искать одинаковые файлы по имени, расширению, размеру, содержимому, дате и времени, музыкальным тегам и даже по именам родительских папок до заданной глубины. При сравнении содержимого можно выбрать алгоритм хеширования, а при необходимости включить byte-for-byte content match confirmation, то есть побайтное подтверждение совпадения.
У программы явно выраженная проектная модель. Поиск здесь строится не как одноразовый запуск, а как настраиваемый проект: выбираются search paths, exclusions, маски имен файлов, правила сравнения, набор колонок для итогового duplicate file report, а затем все это можно сохранить и использовать повторно. Именно поэтому Duplicate File Detective особенно удобна там, где поиск дублей на жестком диске или поиск дубликатов на сетевых папках нужно выполнять регулярно и по одним и тем же правилам.
Отдельно стоит отметить подход к безопасности. Duplicate File Detective умеет защищать целые search paths, переводить их в protected mode, показывать защищенные элементы с lock icon в отчете и не допускать их к обработке. Кроме этого, можно исключать чувствительные системные пути из сканирования, а при удалении или перемещении программа проводит protective checks уже на этапе Duplicate File Manager. За счет этого программа ощущается как инструмент для осознанной дедупликации, а не как файловая мясорубка.
Интерфейс: как устроено главное окно и почему оно рассчитано на серьезную работу
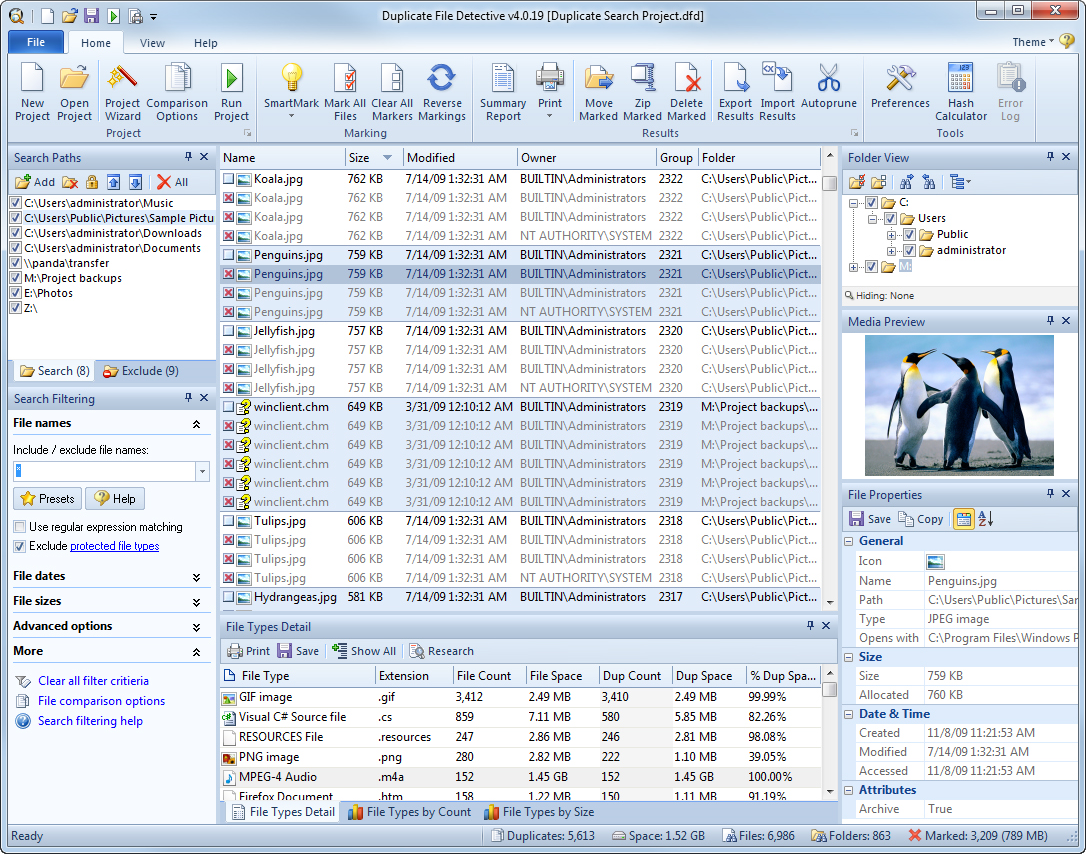
Интерфейс Duplicate File Detective построен вокруг ribbon bar и набора док-панелей. На верхней ленте, на вкладке Home, собраны ключевые команды: Project Wizard, Project Comparison Wizard, Run Project, SmartMark, Mark All Files, Clear All Markers, Reverse Markings, Summary Report, Move Marked, Zip Marked, Delete Marked, Export Results, Import Results, Autorun, Preferences, Hash Calculator и Error Log. Это сразу показывает логику программы: сначала готовится и запускается проект, потом анализируется отчет, затем маркируются файлы и только после этого выполняется обработка.
Слева обычно находятся панели Search Paths и Search Filtering. В Search Paths можно добавлять каталоги, менять их порядок, включать и отключать их по чекбоксам, защищать, переводить в non-inclusive mode, делать master search paths и редактировать двойным щелчком. В Search Filtering есть отдельные секции для File names, File dates, File sizes, Advanced options и других фильтров, так что Duplicate File Detective подходит не только для грубого поиска одинаковых файлов, но и для очень точной фильтрации результата.
Справа и в нижней части окна размещаются вспомогательные панели анализа: Folder View, Media Preview, File Properties, а также аналитические блоки вроде File Types Detail, File Types by Count и File Types by Size. За счет этого отчет о дублях — это не просто список файлов. Можно сразу видеть превью, свойства, владельца, папку, размер группы, статистику по типам и общую картину по месту, которое съедают копии. Именно здесь Duplicate File Detective ощущается как обзорная и аналитическая программа, а не просто очередной duplicate file finder.
Первый запуск и Project Wizard
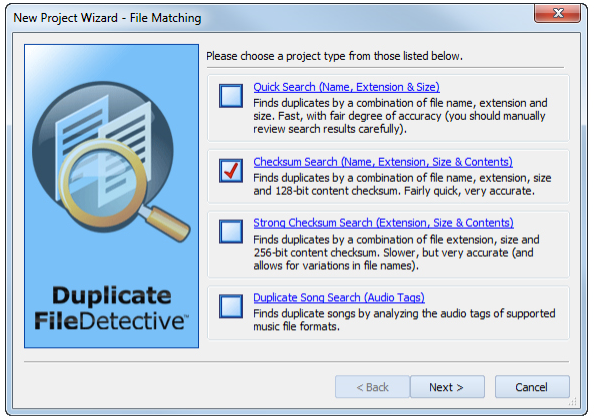
Самый правильный способ начать работу в Duplicate File Detective — через Project Wizard. Программа сама подталкивает к этому сценарию: на вкладке Home нажимается Project Wizard, дальше открывается мастер New Project Wizard - File Matching, после чего пользователь проходит по шагам от выбора метода сравнения до запуска реального поиска. Это удобно и для новичка, и для человека, который хочет быстро собрать рабочий проект без ручной настройки всех панелей.
Логика мастера очень понятная. Сначала выбирается тип проекта и метод сопоставления файлов, затем указываются папки и диски для сканирования, потом задаются типы файлов, после этого определяются колонки будущего отчета, и в финале остается нажать Finish, чтобы стартовал duplicate search process. Кнопки Next и Finish здесь не просто формальность: мастер действительно последовательно проводит пользователя через все основные настройки, из которых потом строится результативный duplicate file report.
На практике это важнее, чем кажется. Во многих утилитах поиск дублей сводится к двум полям и одной кнопке, после чего пользователь получает гору групп без контекста. Duplicate File Detective делает иначе: сначала формирует структуру проекта и только потом запускает анализ. За счет этого уменьшается число хаотичных запусков, а сам обзор результата становится чище и понятнее, особенно если нужно делать повторные проверки по одним и тем же каталогам.
Режимы поиска: Quick Search, Checksum Search, Strong Checksum Search и Duplicate Song Search
Одно из главных отличий Duplicate File Detective от простых программ для поиска одинаковых файлов — наличие нескольких режимов сопоставления уже на этапе Project Wizard. Они различаются не косметически, а по смыслу: одни быстрее, другие точнее, третьи ориентированы на музыкальные файлы.
| Режим | Как работает | Когда использовать |
|---|---|---|
| Quick Search (Name, Extension & Size) | Сопоставляет по имени, расширению и размеру. Быстрый режим с приемлемой точностью, но требует более внимательной ручной проверки результата. | Когда нужен быстрый поиск дублей в понятной файловой структуре. |
| Checksum Search (Name, Extension, Size & Contents) | Добавляет к имени, расширению и размеру 128-bit content checksum, за счет чего дает хороший баланс скорости и точности. | Базовый рабочий режим для большинства сценариев поиска дубликатов файлов в Windows. |
| Strong Checksum Search (Extension, Size & Contents) | Использует 256-bit checksum и ориентирован на более точный поиск, в том числе когда имена файлов уже менялись. | Когда важнее точность дедупликации, чем скорость. |
| Duplicate Song Search (Audio Tags) | Ищет дубли музыкальных файлов на основе аудиотегов. | Когда нужно искать дубликаты треков, а не просто файлов с одинаковыми именами. |
Для обычной файловой дедупликации наиболее универсален Checksum Search. Это именно тот режим, который Duplicate File Detective предлагает по умолчанию в quick start, и это логично: он достаточно точен, чтобы не превращать поиск в лотерею, но при этом не такой тяжелый, как максимально строгая проверка во всех сценариях. Для рабочих папок, документов, архивов, экспортов и резервных копий это почти всегда лучший старт.
Strong Checksum Search — режим уже для более жесткой дедупликации. Он полезен там, где пользователи любят переименовывать файлы, таскать их между папками и плодить одинаковое содержимое под разными названиями. В таком сценарии поиск по одному только имени теряет смысл, и программа фактически опирается на содержимое файла и размер, а не на его название. Именно поэтому Strong Checksum Search хорош для архивов документов, медиабаз, сетевых папок отделов и исторических хранилищ, где наименование давно перестало быть надежным ориентиром.
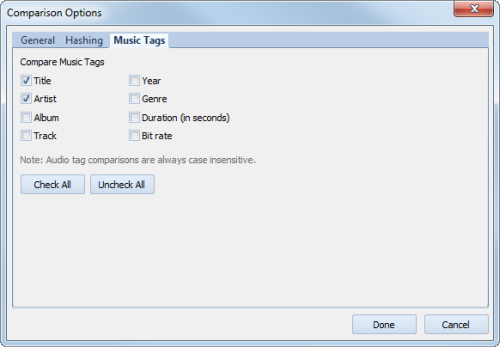
Duplicate Song Search — не случайный довесок, а отдельный полезный режим. Duplicate File Detective умеет сравнивать музыкальные файлы по тегам Title, Artist, Album, Track, Year, Genre, Duration и Bit rate. Это важно, потому что музыкальные дубликаты часто оказываются не буквальными копиями одного и того же файла, а разными экземплярами одного трека с разными именами, папками, битрейтом или тегами. В таком сценарии обычный режим content-based поиска не всегда решает задачу так удобно, как специализированный audio tag search.
Search Paths, exclusions и логика сканирования
В Duplicate File Detective поиск начинается не с нажатия кнопки Scan, а с грамотной настройки Search Paths. Эта панель находится в верхней левой части интерфейса и позволяет добавлять несколько папок и дисков в один проект. В списке у каждого пути есть чекбокс: снял галочку — путь временно отключен из текущего анализа без удаления из проекта. Это очень удобная мелочь для повторных запусков, когда нужно периодически включать и выключать отдельные сегменты хранилища.
Добавление путей сделано гибко. Каталог можно внести через кнопку Add, выбрать его в дереве, указать UNC-путь вручную в формате \\server\share, либо просто перетащить папку из Windows Explorer в Search Paths panel. Для поиска дублей на сетевых папках это особенно удобно: Duplicate File Detective изначально ориентирована на local и network paths, а не только на локальные пользовательские каталоги.
Очень полезная функция — Toggle Non-Inclusive Mode. В обычном inclusive-режиме файлы внутри пути сравниваются и между собой, и с файлами из других путей. В non-inclusive mode файлы внутри одного и того же пути не сравниваются друг с другом, а сопоставляются только с файлами из других путей. Это отличный инструмент, когда нужно, например, сравнить рабочую папку с архивной или проверить одну папку на наличие копий в другой, не получая лишний шум от внутренних совпадений.
Еще сильнее эту логику развивает режим Master Search Paths. Если путь переведен в master status, Duplicate File Detective будет показывать только те группы дублей, в которых есть хотя бы один файл из мастер-пути. Причем при переводе в master mode программа автоматически защищает такой путь и делает его non-inclusive, потому что в типичном сценарии мастер-папка выступает как эталонный источник, который не нужно обрабатывать. Для дедупликации рабочих данных против золотого архива или эталонного набора документов это одна из самых полезных функций всей программы.
Защита путей реализована не номинально. Если search path защищен, любые найденные в нем дубликаты отмечаются как protected и получают значок замка вместо стандартного чекбокса в duplicate report. То есть их нельзя случайно отправить в move, zip или delete наравне с обычными файлами. Эта модель очень хорошо подходит для осторожной дедупликации, когда один сегмент структуры — это источник истины, а остальные лишь кандидаты на очистку.
Панель Exclusions работает в похожем стиле и дает возможность исключать целые пути из анализа. Duplicate File Detective рекомендует отсекать чувствительные системные и программные каталоги — не только из соображений безопасности, но и ради скорости, потому что это уменьшает рабочий набор файлов. Для пользователя это означает простую вещь: если программа используется по уму, то она не тащит в отчет весь шум системы, а концентрируется именно на тех областях, где действительно имеет смысл искать дубли.
Search Filtering: как программа отсекает лишнее еще до отчета
Отдельная причина, почему Duplicate File Detective хорошо подходит для крупных хранилищ, — это мощная секция Search Filtering. Здесь можно не просто сказать сканируй все подряд, а задать точные правила отбора до генерации отчета. Для крупных файловых структур это принципиально: чем меньше мусора попадает в анализ, тем чище группы дублей и тем быстрее поиск.
В секции File names поддерживаются как обычные wildcard-маски, так и регулярные выражения. Маски могут быть как включающими, так и исключающими. Можно использовать шаблоны вроде *.jpg, комбинировать несколько значений через ;, указывать исключающие элементы через ~, переключаться на Use regular expression matching и даже сравнивать не только имя файла, но и полный путь через compare full path. Встроенные Presets и File Groups помогают быстро ограничить сканирование типами данных вроде изображений, документов или архивов.
Кроме имен, программа умеет фильтровать по датам, размерам и дополнительным параметрам. В advanced options можно выделять диапазоны размеров, управлять дополнительными условиями и сокращать выборку до действительно интересных данных. Такой подход особенно полезен, если нужно искать, например, только большие архивы, только старые документы, только медиафайлы или только подозрительные копии внутри определенного диапазона размеров.
По сути, Search Filtering в Duplicate File Detective работает как предохранительный слой между файловой системой и конечным duplicate report. За счет этого отчет перестает быть свалкой всех возможных совпадений и превращается в инструмент анализа конкретной задачи. Для домашнего пользователя это просто удобство. Для администратора или человека, который чистит корпоративное хранилище, — экономия часов ручной работы.
Comparison Options: основа точности Duplicate File Detective
Главная глубина программы раскрывается в окне Comparison Options. Именно здесь Duplicate File Detective перестает быть очередной программой для удаления дублей файлов и превращается в детально настраиваемый инструмент. В Comparison Options можно комбинировать сравнение по имени, расширению, размеру, содержимому, дате и времени, музыкальным тегам, а также по именам родительских папок до заданной глубины. Причем файл считается дубликатом только тогда, когда совпадают все выбранные критерии.
Сравнение имен файлов
В части сравнения имен Duplicate File Detective умеет гораздо больше, чем просто проверка полного совпадения. Можно игнорировать пробелы и специальные символы, игнорировать цифровые символы, выбирать режим matching mode — сравнение по всему имени, только по первым символам, по последним символам или с игнорированием части окончания. Это крайне полезно для поиска копий вроде report.docx, report (1).docx, report_2024.docx и других типичных вариаций пользовательских дублей.
Сравнение содержимого и хеширование
Если активировано Compare file contents, Duplicate File Detective вычисляет content checksums и может использовать разные hash types: CRC32, ADLER32, MD5, SHA1, SHA256 и SHA512. Логика простая: чем сильнее алгоритм, тем выше уверенность в уникальности хеша, но тем дольше вычисление. Для большинства рабочих задач этого более чем достаточно, а если нужна предельная уверенность, можно включить Byte-for-byte content match confirmation, то есть дополнительное побайтное подтверждение совпадения.
Это один из тех моментов, где Duplicate File Detective заметно сильнее многих упрощенных решений. Программа не навязывает один единственный способ поиска, а позволяет выбирать уровень строгости. Если нужна скорость, можно облегчить проверку. Если нужна аккуратная дедупликация файлов перед массовой очисткой архива, можно усилить контроль вплоть до byte-for-byte match. Именно поэтому Duplicate File Detective хорошо подходит для ситуаций, где цена ошибки выше, чем выигрыш от быстрого, но небрежного сканирования.
Работа с ZIP-архивами
Интересная функция — хеширование содержимого ZIP-файлов. Duplicate File Detective умеет enumerate and hash the files they contain, то есть анализировать архивы не только как цельный контейнер, но и по их внутреннему содержимому. Это решает старую проблему: два ZIP-файла могут содержать одинаковые файлы, но из-за различий в метаданных не совпадать как бинарные объекты. В таких случаях программа получает больше шансов выявить дубли там, где поверхностное сравнение бессильно.
Даты, время и родительские папки
Для сценариев, где важно учитывать происхождение файла, Duplicate File Detective умеет сравнивать last modified date and time, при необходимости игнорировать время или секунды, а также включать сравнение parent folders up to this depth. Последнее особенно полезно в структурах, где смысл данных частично хранится в иерархии папок. Например, можно потребовать совпадение имени родительской папки, чтобы отделить настоящие дубли от файлов с одинаковым именем, но разным контекстом хранения.
File Hash Calculator и hash caching
У Duplicate File Detective есть встроенный File Hash Calculator. Это не декоративный инструмент, а вполне практичная часть программы: можно вычислять контрольные суммы для конкретных файлов, использовать разные hash algorithms и быстро проверять подозрительные экземпляры отдельно от основного проекта. Через контекстное меню duplicate report также доступна команда Compute file hash, которая запускает этот инструмент для выбранного файла.
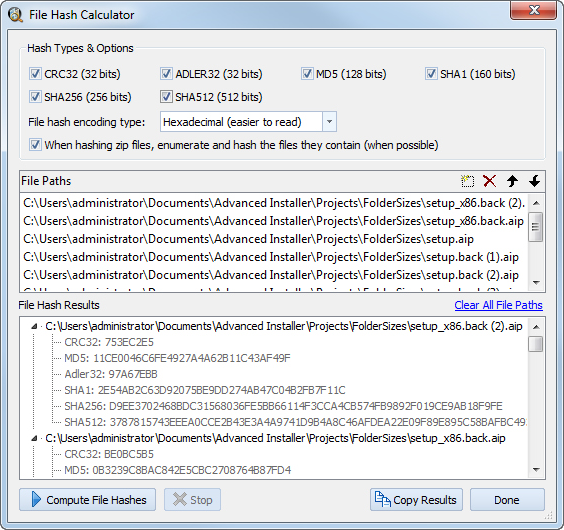
Не менее важна поддержка file hash caching. Duplicate File Detective умеет кэшировать уже вычисленные hash values и повторно использовать их в следующих запусках проекта, если у файла не изменились размер, дата создания и дата модификации. Поскольку вычисление хеша — самая дорогая часть content-based анализа, hash caching может резко ускорить повторные проверки, особенно на больших и редко меняющихся наборах данных. Это особенно заметно на крупных медиаархивах и сетевых хранилищах, где одни и те же search paths сканируются регулярно.
По сути, hash caching превращает Duplicate File Detective из инструмента разовой чистки в инструмент постоянного контроля за хранилищем. Чем более стабилен набор файлов и чем чаще вы проверяете одну и ту же структуру, тем ощутимее выгода. Для бизнеса, архивов и крупных рабочих папок это очень сильная практическая возможность, потому что она сокращает стоимость повторного анализа без потери точности.
Duplicate File Report: что видно после сканирования
После завершения поиска Duplicate File Detective показывает Summary Report, а затем основной duplicate file report. Результаты сгруппированы, и внутри каждой группы видно, какие файлы программа считает дублями. В самом отчете доступны колонки с именем, размером, датой изменения, владельцем, номером группы, папкой и другими полями, набор которых можно заранее выбрать еще на этапе Project Wizard. Для анализа результата это очень удобно: отчет не навязан жестко, а собирается под задачу.
Одна из сильных сторон Duplicate File Detective — сочетание списка дублей с аналитическими панелями. Внизу и по бокам можно видеть File Types Detail, распределение по типам, счетчики по количеству и объему дублей, превью мультимедиа и панель свойств конкретного файла. Поэтому обзор результата здесь получается двухуровневым: с одной стороны, есть точечная работа с отдельной группой, с другой — понимание общей структуры дублирования по всему проекту.
У программы богатое контекстное меню в duplicate report. Из него можно открыть файл, переименовать его, показать родительскую папку через Explore Folder, исключить эту папку из будущих поисков через Exclude parent folder from future searches, переместить, заархивировать или удалить marked items, убрать элементы только из отчета, открыть командную строку в текущем каталоге, скопировать пути в буфер и вычислить file hash. Это делает сам отчет не пассивным списком, а рабочей площадкой для принятия решений.
Важный плюс — возможность экспортировать результаты в CSV, PDF, Excel, HTML и XML. XML хорош тем, что содержит не только список файлов, но и summary data вроде времени выполнения и количества просканированных файлов, поэтому импорт такого отчета возвращает не только группы дублей, но и контекст исходного запуска. Для согласования с коллегами или для этапной дедупликации это очень удобно: сначала можно прогнать анализ, потом сохранить XML и вернуться к нему без повторного сканирования.
SmartMark: одна из лучших функций программы
В реальной работе самая трудная часть начинается не на этапе поиска, а на этапе отбора того, что действительно нужно удалить или переместить. Именно здесь у Duplicate File Detective включается SmartMark — встроенная система assisted selection technology для автоматической маркировки дублей. Программа позволяет массово помечать файлы по Position, Path, Age, Size, Name Length и Music Tag. Дополнительно поддерживается маркировка по пути через wildcard или regular expression pattern matching.
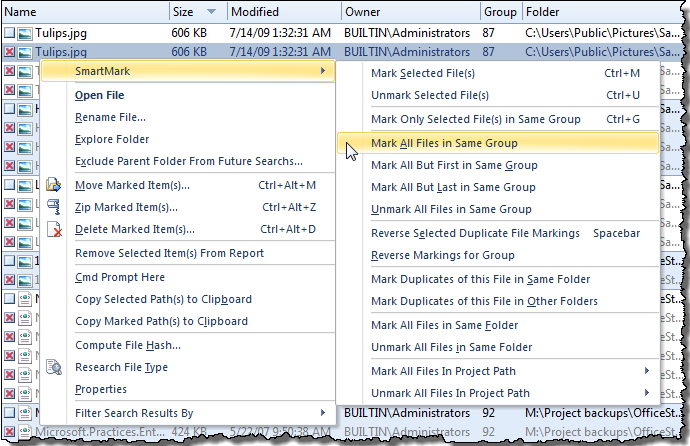
На практике SmartMark экономит огромное количество времени. Вместо того чтобы вручную тыкать каждую группу, можно быстро сказать программе: отмечай более старые файлы, отмечай копии вне мастер-пути, отмечай все, кроме первого или последнего файла в группе, ориентируйся на размер, на длину имени или на аудиопараметры. При этом есть важная страховка: режим Ensure One Unmarked File per Duplicate Group гарантирует, что SmartMark оставит хотя бы один немаркированный файл в каждой группе. Это очень важная защита от ситуации, когда пользователь случайно подготовит к удалению все экземпляры сразу.
SmartMark в Duplicate File Detective сделан не как одна кнопка Auto Select, а как набор логик под разные сценарии. Это и есть зрелый подход к дедупликации файлов: программа не притворяется, будто может волшебно угадать за пользователя, какой файл правильный, но дает мощный набор правил, чтобы эту задачу максимально автоматизировать без потери контроля. В хранилищах с тысячами групп дублей это одна из функций, ради которых Duplicate File Detective вообще стоит ставить.
Move, Zip, Delete: что программа делает с найденными дублями
Когда файлы отмечены, Duplicate File Detective позволяет обработать их через команды Move, Zip и Delete. Каждая из этих операций открывает окно Duplicate File Manager, где можно еще раз проверить список затрагиваемых файлов и только потом запускать обработку кнопкой Go. Это очень правильная модель: перед удалением пользователь видит не абстрактное обещание, а конкретный список того, что будет затронуто.
Move
Режим Move удобен, когда цель — не сразу удалить дубликаты, а сначала вынести их в отдельную карантинную папку. Duplicate File Detective позволяет задать путь назначения и, что особенно полезно, сохранить структуру каталогов через опцию When moving duplicates, retain folder structure. Это снижает риск конфликтов имен и помогает потом проверить результат в более безопасном режиме, уже вне основной рабочей структуры.
Zip
Режим Zip полезен для мягкой дедупликации, когда файлы формально убираются из исходной структуры, но не теряются бесследно. Через Duplicate File Manager можно архивировать помеченные файлы, а при желании включить опцию When zipping duplicates, delete original files after adding them to zip file. Такой режим особенно удобен для архивных документов, когда нужно освободить место, но не хочется сразу расставаться с копиями окончательно.
Delete
Режим Delete — самый прямой и потенциально самый рискованный. Поэтому Duplicate File Detective сопровождает его защитными проверками, позволяет удалять с учетом глобальных правил Protection tab и поддерживает опцию Always delete to Windows Recycle Bin, если нужно сделать удаление обратимым. Также программа умеет удалять родительские папки, если после обработки они становятся пустыми, что полезно для реального наведения порядка, а не только для расчистки отдельных файлов.
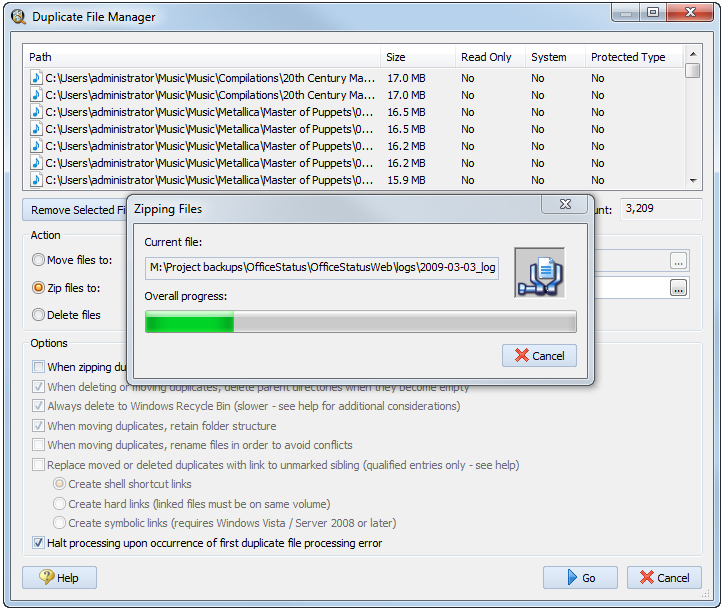
Самое важное в этом блоке — Duplicate File Detective отделяет поиск, маркировку и обработку. В результате удаление дубликатов файлов не превращается в слепой one-click cleanup. Сначала формируется проект, затем группы дублей, затем SmartMark или ручной отбор, после чего уже открывается Duplicate File Manager. Это чуть медленнее, чем бездумный автоклин, но намного безопаснее и качественнее.
Ссылки вместо копий: shell shortcuts, hard links, symbolic links
Одна из самых интересных возможностей Duplicate File Detective — не просто удалять копии, а заменять moved или deleted duplicates ссылками на оригинал. В Duplicate File Manager для этого есть отдельная группа опций, и программа поддерживает три типа ссылок: shell shortcuts, hard links и symbolic links.
Shell shortcut — это обычный .lnk-ярлык. Он подходит почти везде, поддерживается любой версией Windows и любыми файловыми системами, но это все-таки ссылка на уровне оболочки. В Windows Explorer она работает привычно, а вот сторонние приложения могут не всегда интерпретировать такой ярлык как полноценную замену файла. Это хороший вариант для мягкого перехода пользователей после очистки общих папок, когда важно дать им понятный след к оригиналу.
Hard link — вариант более прозрачный. Для пользователя и большинства программ hard link ведет себя как сам файл, без необходимости в поддержке со стороны Windows shell. Но есть ограничения: hard links не могут пересекать разные тома и не подходят для сетевых шар, а также требуют NTFS. Поэтому это отличный выбор для локальной дедупликации внутри одного тома, но не универсальное решение для всех инфраструктур.
Symbolic link — промежуточный вариант между двумя предыдущими, но с важным преимуществом: symbolic links могут работать между томами и даже указывать на сетевые пути. Для Shared Storage и NAS это особенно ценно. Но здесь уже есть системные условия: нужны поддерживаемые версии Windows и, при необходимости, запуск Duplicate File Detective от администратора. Если эти ограничения вас не пугают, symbolic links — очень мощный способ сохранить логику доступа к данным после удаления копий.
Практический смысл этой функции огромен. Во многих организациях боятся дедупликации не потому, что не хотят сэкономить место, а потому что пользователи потеряют свои привычные файлы. Duplicate File Detective решает эту проблему элегантно: можно убрать реальные дубликаты, но оставить на их месте ссылочную дорожку к оригиналу. Для коллективных сетевых папок это один из самых сильных аргументов в пользу программы.
Duplicate File Types и Duplicate File Owners
Большинство программ на этом этапе заканчиваются. Duplicate File Detective — нет. У нее есть отдельные аналитические представления Duplicate File Types и Duplicate File Owners. В первом случае программа показывает распределение дублей по типам файлов, включая detail view и графики по count и aggregate file size. Во втором — распределение дублей по владельцам файлов, опять же с быстрым обзором и графическим представлением.
Практическая польза от этого очень большая. Duplicate File Types позволяет быстро понять, что именно забивает хранилище: документы, изображения, архивы, аудио, видео или какие-то специфические расширения. То есть вы видите не просто отдельные дубли, а структуру проблемы. Если, например, 80% дублируемого объема приходится на ZIP, PSD, ISO или какие-то промежуточные экспортные форматы, решение может быть не только в разовой очистке, но и в изменении рабочих процессов.
Duplicate File Owners особенно полезен в общих сетевых хранилищах и файловых серверах. Он показывает, какие пользователи или сервисные аккаунты ответственны за наибольшую долю дублей. Для администратора это уже не просто технический отчет, а почти управленческий инструмент: можно понять, где лежит основная причина разрастания копий и кому имеет смысл пересмотреть подход к хранению файлов.
Планировщик, autorun и автоматизация
Duplicate File Detective умеет работать не только интерактивно, но и по расписанию. У нее есть встроенный scheduler, который позволяет запускать duplicate searches на deferred или recurring basis, сохранять результаты в файловую систему или отправлять отчеты по email одному или нескольким адресатам. Для регулярного контроля сетевых папок и NAS это очень удобно: можно, например, еженедельно формировать PDF или Excel-отчет по дублям без ручного запуска.
Кроме встроенного scheduler, программа поддерживает command line execution проектов. Через dfd.exe можно запускать заранее сохраненный project-файл, экспортировать отчет в HTML, CSV, XML, PDF или XLSX, добавлять дату к имени результата и встраивать Duplicate File Detective в существующие batch-процессы. Это уже уровень не просто домашней уборки, а интеграции в рабочую файловую рутину.
Сочетание scheduler, command line options и project-based architecture делает Duplicate File Detective очень удобной там, где поиск дублей — не разовая акция, а постоянная гигиена хранилища. Один раз собирается корректный проект, дальше он исполняется вручную, по расписанию или через командную строку, а результаты уходят в нужный формат. Такой подход серьезно отличает программу от типичных бытовых cleaner-решений.
Пошаговый сценарий: как использовать Duplicate File Detective для большой очистки
Шаг 1. Создать проект
Откройте вкладку Home и нажмите Project Wizard. Для обычной рабочей дедупликации разумно начать с Checksum Search, а если структура особенно грязная и файлы часто переименовывались — со Strong Checksum Search. В этом же шаге хорошо сразу решить, будет ли проект разовым или его нужно сохранить для регулярных запусков.
Шаг 2. Добавить search paths
На следующем шаге мастера или через панель Search Paths внесите все папки, которые должны участвовать в анализе. Если вы сравниваете, например, рабочий архив с эталонной папкой, имеет смысл сразу назначить эталонный путь master path. Если какой-то каталог нельзя трогать ни при каких условиях, защитите его через Protect toolbar icon.
Шаг 3. Настроить file groups и фильтры
Не стоит сканировать весь диск без разбора, если задача касается только документов, только фото или только медиа. Ограничьте анализ нужными file groups, настройте File names через wildcard masks или regular expressions, при необходимости сузьте диапазон по размеру и дате. Чем грамотнее собран search filtering, тем чище получится duplicate report.
Шаг 4. Проверить comparison options
Если задача стандартная, проверьте, что заданы нужные match criteria: имя, расширение, размер, содержимое. Если ищете максимально точные дубликаты, включите content comparison и при необходимости byte-for-byte confirmation. Если задача музыкальная, проверьте вкладку Music Tags и нужные поля вроде Title, Artist, Album, Duration и Bit rate.
Шаг 5. Запустить поиск и прочитать Summary Report
После Finish программа запускает duplicate search process и показывает Summary Report. Не пропускайте этот момент: он дает быстрое понимание масштаба проблемы и позволяет решить, нужно ли сразу углубляться в результат или лучше еще донастроить проект и сузить выборку.
Шаг 6. Разобрать duplicate file report
В отчете смотрите не только на группы, но и на правые панели Media Preview и File Properties, а также на нижние статистические блоки. Если видно, что шумят не те типы файлов, которые вас интересуют, вернитесь к Search Filtering. Если дубли выглядят релевантно, переходите к отбору.
Шаг 7. Использовать SmartMark
Дальше самое удобное — SmartMark. Для больших массивов лучше не выделять файлы вручную, а выбрать логичное правило маркировки: по возрасту, пути, размеру, позиции или имени. Если нужно сохранить по одному экземпляру в каждой группе, убедитесь, что активна логика Ensure One Unmarked File per Duplicate Group.
Шаг 8. Проверить спорные группы вручную
После SmartMark стоит пройтись по сомнительным группам глазами. Это особенно важно для документов с похожими именами, для музыкальных файлов и для случаев, где задействованы сложные правила сравнения имен или тегов. Duplicate File Detective здесь хороша тем, что дает и автоматизацию, и детальный ручной контроль в одном окне.
Шаг 9. Выбрать способ обработки
Если нужна осторожность — сначала Move в отдельную папку. Если нужно освободить место, но оставить копии в архиве — Zip. Если решение окончательное — Delete, желательно с Recycle Bin. Если в структуре важна непрерывность доступа, активируйте замену дублей ссылками на оригинал через shell shortcut, hard link или symbolic link.
Шаг 10. Сохранить результат
После обработки стоит экспортировать duplicate report в PDF, Excel или XML. PDF хорош для согласования и просмотра, Excel — для ручного анализа, XML — для повторного импорта и продолжения работы позже. Если эта задача регулярная, сохраните проект и вынесите его в scheduler или командную строку.
Сравнение с аналогами
Duplicate File Detective стоит сравнивать не с абстрактными аналогами, а с конкретными реальными программами, потому что у каждой из них свой профиль.
Duplicate Cleaner
Duplicate Cleaner очень сильна как универсальная пользовательская программа. У нее есть отдельные режимы Regular, Image, Audio и Video, поиск внутри ZIP и других архивов, Selection Assistant, master folder/drive, filters, hard links и symbolic links. Для домашней мультимедийной библиотеки, похожих изображений и видео Duplicate Cleaner часто выглядит более широкой по специализированным медиа-режимам.
Но Duplicate File Detective заметно интереснее там, где нужна именно управляемая дедупликация файловой инфраструктуры: здесь лучше выражены project-oriented workflow, SmartMark-логика, protected search paths, master search paths, duplicate file owners, duplicate file types, встроенный scheduler, re-import XML reports и продуманная работа с сетевыми путями. Duplicate Cleaner хороша как мощный пользовательский комбайн, а Duplicate File Detective — как более строгий и отчетно-ориентированный инструмент для Windows-хранилищ.
dupeGuru
dupeGuru — отличный open-source инструмент с fuzzy matching, content scan, special Music mode, Picture mode и reference directory system. Он работает на Windows, macOS и Linux, умеет искать похожие имена и похожие изображения, а также безопасно обрабатывать результаты через grouping system и reference folders. Для пользователя, которому нужен бесплатный и кроссплатформенный поиск дублей с хорошей логикой fuzzy matching, dupeGuru по-прежнему очень хорош.
Но Duplicate File Detective берет другим. У нее гораздо сильнее инфраструктурная сторона: search paths с protected и master logic, owner/type reports, integrated scheduler, command-line project execution, XML re-import, Duplicate File Manager и замена удаленных копий ссылками на оригинал как часть общего управляемого процесса. dupeGuru ощущается как гибкий и умный инструмент для персональной чистки и мультимедиа, а Duplicate File Detective — как более тяжелый, но и более системный инструмент для повторяемой дедупликации в Windows-среде.
Easy Duplicate Finder
Easy Duplicate Finder делает ставку на простоту, Wizard, 10+ scan modes и работу не только с локальными файлами, но и с Google Drive, OneDrive, Dropbox, а также с email-сценариями. Для пользователя, который хочет максимально простой интерфейс, cloud-first подход и минимальное количество ручной настройки, Easy Duplicate Finder действительно выглядит доступнее.
На стороне Duplicate File Detective — другой тип силы. Она меньше про три клика и готово и больше про точную дедупликацию файлов, сетевые папки, project-based scans, detailed comparison options, SmartMark, owner/type analytics и controlled cleanup через Duplicate File Manager. То есть Easy Duplicate Finder удобнее как легкая универсальная уборка для ПК, Mac и облаков, а Duplicate File Detective лучше вписывается в Windows-ориентированные рабочие хранилища, где важны контроль, повторяемость и безопасность процесса.
DupScout
Вот здесь сравнение особенно интересное, потому что DupScout тоже очень силен в инфраструктурных сценариях. Он умеет искать дубли в disks, directories, network shares, NAS, автоматически находить серверы и сетевые шары, работать через командную строку, сохранять отчеты в HTML/PDF/Excel/CSV/XML, экспортировать данные в SQL database и в серверных редакциях запускать полностью автоматические periodic jobs. Для очень крупных корпоративных сред DupScout часто выглядит даже более сетевым и серверным инструментом.
Но Duplicate File Detective выигрывает в удобстве именно интерактивной дедупликации. Project Wizard, очень наглядный duplicate file report, SmartMark, Duplicate File Manager, search path protection, master search paths и linking duplicates to originals делают процесс чище именно для человека, который не только автоматизирует, но и вручную принимает решения по группам. Иначе говоря, DupScout сильнее как корпоративная платформа и масштабный сетевой сканер, а Duplicate File Detective — как точный и удобный инструмент для контролируемой дедупликации с хорошим интерфейсом и безопасной ручной доработкой результата.
Сильные стороны Duplicate File Detective
У программы действительно много сильных сторон, и они не сводятся к одному только поиску дублей.
-
Очень гибкие file comparison options: имя, расширение, размер, содержимое, даты, музыкальные теги, родительские папки, zip contents, byte-for-byte confirmation.
-
Продуманная работа с search paths: multiple paths, network shares, UNC, protected paths, non-inclusive mode, master search paths.
-
Удачная логика SmartMark, которая реально экономит время на больших отчетах.
-
Сильный Duplicate File Manager: move, zip, delete, сохранение структуры папок, удаление пустых каталогов, работа со ссылками вместо копий.
-
Аналитика по duplicate file types и duplicate file owners, которая почти всегда отсутствует в более простых утилитах.
-
Хорошая отчетность и автоматизация: export/import, scheduler, email delivery, command line, reusable projects.
-
Поддержка hash caching, которая ускоряет повторные content-based проверки.
Что может не понравиться
При всех достоинствах Duplicate File Detective нельзя назвать программой, которая понравится всем без исключения.
Во-первых, она довольно насыщена настройками. Для человека, который просто хочет удалить пару десятков дублей с домашнего диска, интерфейс может показаться перегруженным: панели, режимы, comparison options, search paths, exclusions, analytics. Программа рассчитана не на импульсивное удаление, а на осмысленную работу. Это плюс для серьезных сценариев, но минус для тех, кто ищет только одну большую кнопку очистить все.
Во-вторых, многие сильные стороны Duplicate File Detective раскрываются именно на повторяемых или больших задачах. Если у пользователя нет сетевых папок, нет необходимости сохранять проекты, нет нужды в owner/type reports и планировщике, часть возможностей останется невостребованной. То есть программа не слишком легкомысленная — она любит системный подход и лучше всего работает там, где этот подход действительно нужен.
Кому Duplicate File Detective подходит лучше всего
Duplicate File Detective особенно хороша для нескольких категорий пользователей.
Для power users и аккуратной домашней дедупликации
Если на компьютере большие архивы фото, видео, документов, резервных копий и скачанных материалов, Duplicate File Detective дает намного больше контроля, чем типичная автоочистка. Можно отдельно настроить search paths, фильтры, comparison options и потом безопасно разбирать группы дублей.
Для системных администраторов и IT-специалистов
Здесь программа раскрывается особенно хорошо: network paths, UNC, protected folders, owner reports, type reports, scheduler, command line execution и ссылки вместо копий делают ее удобной для обслуживания сетевых файловых областей.
Для отделов с общими папками и файловыми свалками
Если в организации есть старые общие каталоги, где сотрудники годами сохраняли копии договоров, презентаций, PDF, выгрузок и архивов, Duplicate File Detective дает нужный баланс между автоматизацией и ручным контролем. SmartMark помогает быстро выделять кандидатов на обработку, а Duplicate File Manager и linking options позволяют не ломать пользовательский сценарий после консолидации.
Для тех, кому нужен именно Windows-ориентированный бизнес-класс duplicate file finder
Если задача — найти duplicate file finder не ради разовой уборки, а ради стабильного рабочего процесса по дедупликации, Duplicate File Detective выглядит очень убедительно. Она не универсальна для всех платформ и не притворяется облачным все-в-одном, зато именно в Windows-сценариях с локальными и сетевыми путями дает очень сильный набор инструментов.
Итог
Duplicate File Detective — это одна из тех программ, которые лучше всего понимаешь не по рекламному описанию, а по логике работы. Она не пытается упростить задачу до опасной примитивности. Наоборот, программа строит аккуратный процесс: Project Wizard, выбор режима поиска, точная настройка comparison options, добавление search paths, фильтрация, построение duplicate file report, SmartMark, проверка спорных групп, затем Duplicate File Manager с move/zip/delete и при необходимости с заменой копий ссылками на оригинал.
Именно поэтому Duplicate File Detective хорошо воспринимается как программа для поиска дубликатов файлов, когда нужна не только скорость, но и дисциплина процесса. Для домашнего пользователя, который хочет максимально простой интерфейс, могут найтись варианты попроще. Но если нужен действительно сильный инструмент для поиска дублей на жестком диске, дедупликации файлов в рабочих архивах, поиска дубликатов на сетевых папках и безопасного удаления дубликатов файлов без хаоса, Duplicate File Detective выглядит очень убедительно.
В сухом остатке у программы сильная точность, зрелая архитектура, полезная аналитика, хорошая автоматизация и редкая для этого класса связка из SmartMark, protected/master paths, detailed reporting и link-based cleanup. Для серьезной дедупликации в Windows это действительно один из самых интересных и продуманных инструментов.