
Rdfind — это консольная программа для поиска файлов-дубликатов в одной или нескольких директориях. Полное название утилиты раскрывается как Redundant Data Find, то есть поиск избыточных данных. Главное отличие Rdfind от обычного поиска по имени файла в том, что программа сравнивает содержимое, а не названия. Для нее photo.jpg, copy_001.dat и backup/file.bin могут оказаться одним и тем же файлом, если совпадает содержимое. И наоборот: два файла с одинаковым именем не будут считаться дублями, если внутри у них разные данные.
Rdfind особенно хорошо подходит для Linux, Unix-подобных систем, серверов, NAS-хранилищ, резервных копий, архивов документов, ISO-образов, наборов фотографий, рабочих каталогов разработчика и больших папок, где накопились одинаковые файлы. Это не графический чистильщик с кнопкой Scan и красивой плиткой результатов, а точный CLI-инструмент: пользователь запускает команду, получает вывод в терминале, затем анализирует файл results.txt или сразу применяет действие вроде удаления дубликатов, замены на hard links или symbolic links.
Программа работает предсказуемо: без дополнительных флагов она не удаляет найденные дубликаты и не заменяет их ссылками. Стандартный запуск создает отчет results.txt, показывает возможную экономию места и оставляет решение пользователю. Это делает rdfind удобным вариантом для осторожной дедупликации файлов Linux, когда сначала нужно увидеть группы совпадений, а уже затем выбирать действие.
Скачать rdfind
- Оптимизация системы
- Очистка мусора
- Ускорение ПК
- Только дубликаты
- Нет интерфейса
- Сложно новичкам
Назначение программы
Основная задача Rdfind — найти одинаковые файлы внутри одной директории, между несколькими директориями или среди набора конкретных файлов. Утилита рекурсивно обходит переданные пути, проверяет размер, сравнивает части содержимого, считает контрольные суммы только тогда, когда это действительно требуется, и группирует совпадения. Директории обрабатываются рекурсивно, поэтому команда вида rdfind ~/Documents проверяет не только саму папку Documents, но и ее вложенные каталоги.
Практический смысл программы простой: найти избыточные копии, которые занимают место, мешают ориентироваться в данных и усложняют резервное копирование. В типичном домашнем сценарии rdfind помогает проверить ~/Downloads, ~/Pictures, ~/Documents или внешний диск с архивом. В рабочем сценарии программа полезна для директорий с экспортами, логами, копиями проектов, архивами сборок, снапшотами, резервными копиями и повторяющимися файлами конфигурации.
Rdfind не пытается быть универсальным файловым менеджером. Она не показывает миниатюры, не умеет находить похожие фотографии, не сравнивает документы по смыслу и не предлагает интерактивную сортировку мышью. Ее специализация уже: поиск настоящих дубликатов файлов по содержимому. Именно за счет этой узкой специализации программа остается простой, быстрой и удобной для автоматизации.
Как выглядит интерфейс Rdfind
У Rdfind нет графического окна, меню, вкладок и кнопок. Интерфейс программы состоит из четырех основных элементов:
-
команды
rdfind; -
путей к файлам или папкам;
-
флагов, которые управляют поиском и действиями;
-
текстового вывода в терминале и файла
results.txt.
Стандартная форма запуска выглядит так:
rdfind [options] directory_or_file_1 [directory_or_file_2] [directory_or_file_3] ...Вместо привычных кнопок здесь используются параметры. Например, роль кнопки найти дубликаты выполняет сама команда:
rdfind ~/DownloadsРоль переключателя удалить дубликаты выполняет параметр:
-deleteduplicates trueРоль безопасного предпросмотра выполняет:
-dryrun trueА роль сохранения отчета под другим именем выполняет:
-outputname duplicates-report.txtТакой интерфейс кажется сухим только на первый взгляд. Для системного администратора, разработчика или пользователя, который работает через SSH, это преимущество: команду можно вставить в shell-скрипт, cron-задачу, Makefile, инструкцию для сервера или одноразовый сценарий очистки архива.
Во время работы Rdfind выводит этапы обработки в терминал. Пользователь видит строки вроде:
Now scanningNow sorting on sizeNow eliminating candidates based on first bytesNow eliminating candidates based on last bytesNow eliminating candidates based on sha1 checksumNow making results file results.txtЭти сообщения не декоративные. По ним понятно, на какой стадии находится поиск дубликатов файлов: программа уже обошла директорию, отсекла уникальные размеры, проверяет первые байты, проверяет последние байты, считает checksum или записывает отчет. Такой вывод особенно полезен при обработке больших папок на HDD, внешнем диске или сетевом хранилище.
Чем Rdfind отличается от поиска одинаковых имен
Обычный поиск одинаковых имен отвечает на вопрос: есть ли в системе файлы с одинаковым названием. Rdfind отвечает на другой вопрос: есть ли в системе файлы с одинаковым содержимым. Это принципиально разные задачи.
Например, в папке могут лежать такие файлы:
report-final.pdfreport-final-copy.pdfold/report.pdfbackup/2024/report_from_mail.pdfПо имени они разные. Обычный поиск дублей по названию может их не связать. Rdfind проверяет содержимое и, если файлы идентичны, помещает их в одну группу.
Обратная ситуация тоже распространена:
project/readme.txtarchive/readme.txtИмена одинаковые, но содержимое может быть разным. Один readme.txt относится к проекту, другой — к архиву с инструкциями. Rdfind не станет считать такие файлы дубликатами только из-за совпавшего имени. Для него важны размер и содержимое.
Такой подход особенно важен при работе с фотоархивами, резервными копиями, скачанными документами, ISO-образами и экспортами из облачных сервисов. Файлы часто переименовываются, копируются в разные папки, получают суффиксы вроде (1), (2), copy, old, backup, но внутри остаются полностью одинаковыми. Rdfind находит именно эти случаи.
Как Rdfind ищет дубликаты
Rdfind использует многоступенчатый алгоритм. Его смысл в том, чтобы не читать каждый файл полностью без необходимости. Полное чтение больших файлов дорого по времени, особенно если речь о терабайтном архиве, медленном HDD, внешнем USB-диске или NAS. Поэтому программа постепенно отсекает файлы, которые точно не могут быть дубликатами.
Схема работы выглядит так:
| Этап | Что делает Rdfind | Зачем это нужно |
|---|---|---|
| Обход путей | Рекурсивно собирает список файлов из переданных директорий | Получает исходный набор для анализа |
| Размер файла | Считывает размеры всех файлов | Файлы разного размера не могут быть идентичными |
| Inode и device | Убирает уже идентичные записи одного inode/device при включенном поведении по умолчанию | Не считает уже связанные hardlink-записи отдельными дублями |
| Сортировка по размеру | Группирует кандидатов одинакового размера | Сужает список потенциальных совпадений |
| Первые байты | Сравнивает начало файлов | Быстро отсекает разные файлы одинакового размера |
| Последние байты | Сравнивает конец файлов | Еще сильнее сокращает набор кандидатов |
| Контрольная сумма | Считает checksum для оставшихся файлов | Подтверждает совпадение содержимого |
| Ранжирование | Выбирает оригинал и дубликаты | Формирует группы для отчета и действий |
| Отчет или действие | Пишет results.txt, удаляет дубли или заменяет их ссылками |
Завершает сценарий пользователя |
В худшем случае алгоритм имеет сложность O(Nlog(N)), где N — число проверяемых файлов. На практике важнее другое: rdfind старается читать данные с диска только тогда, когда это нужно. Если у файла уникальный размер, его содержимое можно вообще не открывать. Если первые байты отличаются, нет смысла считать полную контрольную сумму. Если последние байты отличаются, файл тоже выбрасывается из списка кандидатов.
Для больших архивов это критично. Допустим, в папке 200 000 файлов. Большая часть из них имеет уникальный размер. Rdfind быстро отсечет их на этапе сортировки по размеру и не будет тратить время на чтение содержимого. Полный checksum понадобится только тем файлам, которые прошли ранние фильтры и действительно похожи на дубликаты.
Первый запуск и базовое сканирование
Базовый запуск Rdfind выглядит так:
rdfind ~/DownloadsКоманда проверяет папку Downloads и все вложенные директории. После завершения в текущей рабочей директории появляется файл results.txt. Важно понимать именно формулировку в текущей рабочей директории: если команда запущена из ~/, отчет появится там, даже если сканируемая папка находится в ~/Downloads.
Для проверки папки с документами используется такой вариант:
rdfind ~/DocumentsДля фотоархива:
rdfind ~/PicturesДля внешнего диска:
rdfind /media/user/BackupДля двух директорий сразу:
rdfind ~/Documents /mnt/backup/DocumentsПоследний пример особенно полезен для сравнения рабочей папки и резервной копии. Rdfind может найти одинаковые файлы между двумя деревьями каталогов и определить, какой экземпляр будет считаться оригиналом, а какой — дубликатом. Здесь уже важен порядок аргументов: файлы, найденные при обработке более раннего аргумента командной строки, получают более высокий ранг.
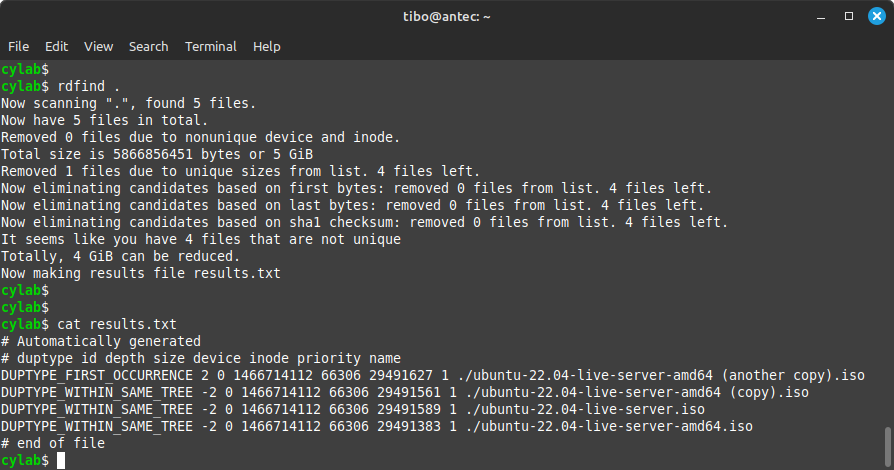
Типичный вывод после запуска выглядит примерно так:
Now scanning "/home/user/Downloads", found 1804 files.Now have 1804 files in total.Removed 0 files due to nonunique device and inode.Now removing files with zero size...removed 8 filesTotal size is 12573890244 bytes or 12 GibNow sorting on size:removed 1640 files due to unique sizes.156 files left.Now eliminating candidates based on first bytes:removed 35 files.121 files left.Now eliminating candidates based on last bytes:removed 18 files.103 files left.Now eliminating candidates based on sha1 checksum:removed 7 files.96 files left.It seems like you have 96 files that are not uniqueTotally, 2 Gib can be reduced.Now making results file results.txtЭти строки показывают не просто прогресс, а логику дедупликации. Сначала в набор попали все найденные файлы, затем часть была исключена как пустые, затем программа отбросила уникальные размеры, потом проверила начало и конец файлов, после чего рассчитала checksum для оставшихся кандидатов.
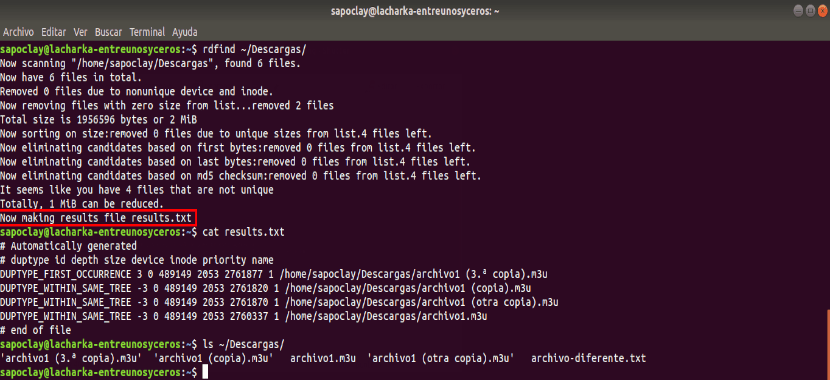
Файл results.txt: главный результат работы
results.txt — центральный элемент Rdfind. Это не вспомогательный лог, а полноценный отчет, по которому можно понять, какие файлы программа считает оригиналами, а какие — дубликатами. По умолчанию файл создается в текущей директории, а имя можно изменить параметром -outputname.
Открыть отчет можно обычной командой:
cat results.txtВнутри находится заголовок и строки с найденными группами:
# Automatically generated# duptype id depth size device inode priority nameDUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/user/Downloads/test5.regexDUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/user/Downloads/test6.regex# end of file
Строка заголовка показывает структуру отчета:
| Колонка | Значение |
|---|---|
duptype |
Тип записи: оригинал, дубль в том же дереве, дубль вне дерева или внутренняя ошибка |
id |
Идентификатор группы совпадений |
depth |
Глубина файла относительно переданного аргумента |
size |
Размер файла в байтах |
device |
Идентификатор устройства |
inode |
Номер inode |
priority |
Приоритет, связанный с порядком аргументов |
name |
Полный или относительный путь к файлу |
Самые важные значения находятся в колонке duptype.
DUPTYPE_FIRST_OCCURRENCE
DUPTYPE_FIRST_OCCURRENCE означает, что этот файл выбран оригиналом внутри группы. Rdfind оставляет его как главный экземпляр. Если затем включить удаление дубликатов или замену на ссылки, именно этот файл будет точкой отсчета.
DUPTYPE_WITHIN_SAME_TREE
DUPTYPE_WITHIN_SAME_TREE означает, что файл найден как дубликат внутри того же дерева каталогов, что и оригинал. Например, оба файла лежат внутри ~/Pictures, но в разных вложенных папках.
DUPTYPE_OUTSIDE_TREE
DUPTYPE_OUTSIDE_TREE используется, когда дубликат найден при обработке другого входного аргумента. Это важно при сравнении нескольких директорий:
rdfind ~/Work /mnt/backup/WorkЕсли оригинал найден в ~/Work, а копия — в /mnt/backup/Work, отчет может показать, что дубль находится вне дерева первого аргумента.
DUPTYPE_UNKNOWN
DUPTYPE_UNKNOWN означает внутреннюю ошибку. В нормальном сценарии пользователь обычно работает с DUPTYPE_FIRST_OCCURRENCE, DUPTYPE_WITHIN_SAME_TREE и DUPTYPE_OUTSIDE_TREE.
Как Rdfind выбирает оригинал
В любой группе одинаковых файлов программе нужно решить, какой экземпляр считать оригиналом. Rdfind делает это через ранжирование. Это не случайный выбор и не визуальное предпочтение пользователя, а набор правил.
Главные правила такие:
-
Файл из более раннего аргумента командной строки получает более высокий ранг.
-
Файл, расположенный ближе к корню переданной директории, получает более высокий ранг.
-
Если файлы найдены в одном входном аргументе и на одинаковой глубине, при включенном детерминированном режиме выбор остается стабильным и не зависит от порядка, в котором файловая система вернула элементы.
Пример:
rdfind ~/Documents /mnt/backup/DocumentsВ этом случае ~/Documents важнее, чем /mnt/backup/Documents, потому что указан первым. Если одинаковый файл найден в обеих папках, экземпляр из ~/Documents будет иметь преимущество при выборе оригинала.
Если нужно сохранить в качестве оригиналов файлы из архива, порядок следует изменить:
rdfind /mnt/backup/Documents ~/DocumentsТеперь выше по рангу будет резервная копия.
Это одна из самых важных особенностей Rdfind. Программа не спрашивает каждый раз, какой файл оставить. Она применяет правила ранжирования. Поэтому перед запуском с -deleteduplicates true, -makehardlinks true или -makesymlinks true нужно правильно расставить аргументы и проверить results.txt.
Основные сценарии работы
Только найти дубликаты и ничего не менять
Это стандартный и самый безопасный сценарий:
rdfind ~/DocumentsРезультат:
-
программа рекурсивно проверяет папку;
-
найденные совпадения записываются в
results.txt; -
файлы остаются на месте;
-
пользователь видит возможную экономию места.
Такой запуск подходит для первой проверки любой новой папки. Он не меняет содержимое каталога, поэтому его удобно использовать перед ручной очисткой.
Найти дубликаты в нескольких папках
rdfind ~/Pictures /mnt/photo-backupКоманда сравнивает файлы внутри обеих директорий и между ними. Это полезно, когда нужно понять, какие фотографии уже есть в резервной копии, какие копии появились в рабочем архиве и где хранятся повторяющиеся файлы.
Сохранить отчет под другим именем
rdfind -outputname duplicates-pictures.txt ~/PicturesТакой вариант удобен, когда нужно оставить несколько отчетов:
rdfind -outputname duplicates-documents.txt ~/Documentsrdfind -outputname duplicates-downloads.txt ~/Downloadsrdfind -outputname duplicates-backup.txt /mnt/backupПараметр -outputname меняет имя файла отчета вместо стандартного results.txt.
Отключить создание отчета
rdfind -makeresultsfile false ~/DownloadsОбычно отчет нужен, поэтому отключать его стоит редко. Этот вариант логичен в сценариях, где программа используется только для вывода или действия, а файл отчета не нужен.
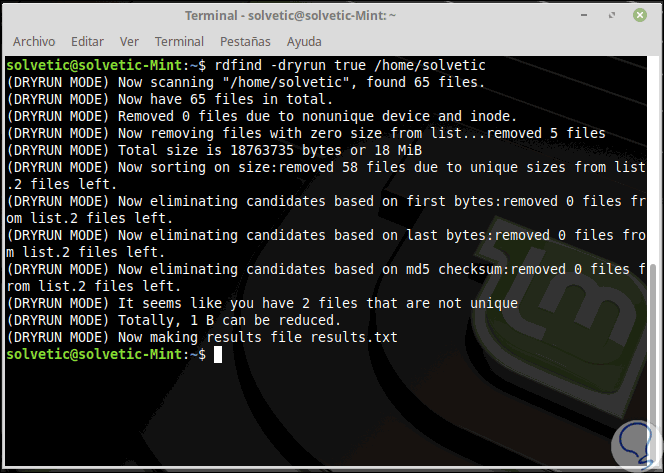
Проверить действие без реального изменения файлов
rdfind -deleteduplicates true -dryrun true ~/Downloads-dryrun true показывает, что программа сделала бы при включенном действии, но не выполняет изменение. Вариант полезен перед удалением, заменой на hard links или заменой на symlinks. В некоторых записях также используется короткая форма -n.
Удаление дубликатов
Rdfind умеет не только находить дубли, но и удалять их. Для этого используется параметр:
rdfind -deleteduplicates true /path/to/folderПример для папки загрузок:
rdfind -deleteduplicates true ~/DownloadsПример для резервной копии:
rdfind -deleteduplicates true /mnt/backup-deleteduplicates true удаляет дубликаты, которые программа выбрала неоригинальными. Оригиналы остаются. Поскольку выбор оригинала зависит от порядка аргументов и глубины файла, этот режим нельзя использовать вслепую.
Правильная последовательность такая:
rdfind ~/Downloadscat results.txtrdfind -deleteduplicates true -dryrun true ~/Downloadsrdfind -deleteduplicates true ~/DownloadsПервый запуск формирует отчет. Второй шаг позволяет его прочитать. Третий показывает, что будет удалено. Четвертый выполняет удаление.
Важная деталь: удаление в контексте Rdfind означает unlink-файла. Программа убирает дубликат из файловой системы, а не переносит его в графическую корзину. Поэтому перед использованием -deleteduplicates true лучше иметь резервную копию или хотя бы отчет с результатами.
Замена дубликатов hard links
Один из сильных сценариев Rdfind — замена одинаковых файлов жесткими ссылками. Для этого используется:
rdfind -makehardlinks true /path/to/folderПример:
rdfind -makehardlinks true ~/ArchiveHard link позволяет нескольким именам файлов указывать на один и тот же inode. Визуально файлы остаются на своих местах: путь folder1/file.iso и путь folder2/copy.iso продолжают существовать. Но данные на диске хранятся один раз. Именно поэтому hard links особенно полезны для архивов, резервных копий и неизменяемых коллекций файлов.
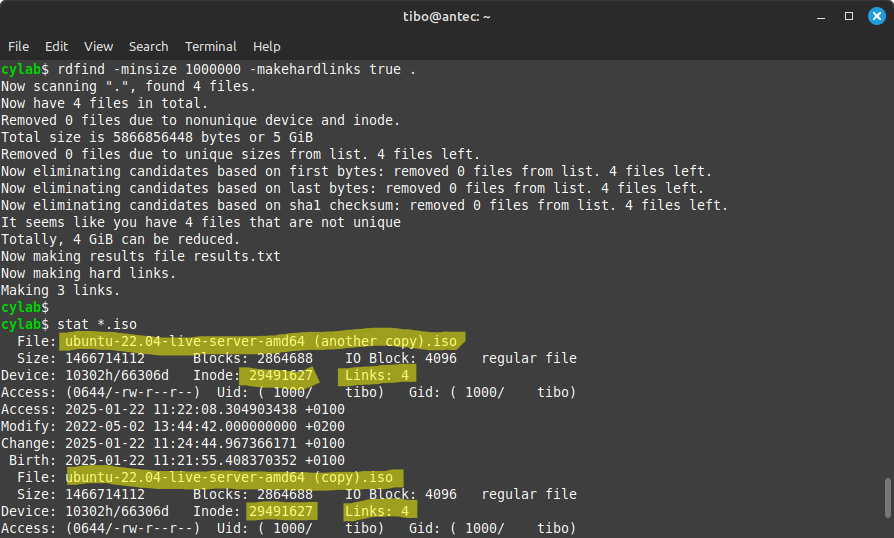
Этот режим хорош, когда нужно сохранить структуру директорий, но уменьшить занимаемое место. Например, есть несколько резервных копий одной рабочей папки:
backup-2024-01/backup-2024-02/backup-2024-03/В каждой копии могут повторяться большие файлы: документы, изображения, архивы, бинарные файлы, ISO-образы. Если заменить идентичные копии hard links, дерево каталогов внешне почти не изменится, но одинаковые данные будут храниться экономнее.
Однако hard links требуют аккуратности. Если пользователь изменит один из таких файлов, он фактически изменит содержимое, на которое указывают все жесткие ссылки. Поэтому сценарий лучше подходит для архивов, которые не редактируются, а не для активных рабочих документов.
Замена дубликатов symbolic links
Другой вариант — заменить дубликаты символическими ссылками:
rdfind -makesymlinks true /path/to/folderПример:
rdfind -makesymlinks true ~/ArchiveSymbolic link отличается от hard link тем, что является отдельной ссылкой на путь к оригиналу. Такой подход понятнее визуально: файл-дубликат превращается в ссылку, и пользователь видит, куда она указывает. В некоторых сценариях это удобнее, чем hard links, особенно когда нужно явно понимать, какие элементы стали ссылками.
У Rdfind есть важная особенность: создаваемые symbolic links являются абсолютными. Это значит, что ссылка указывает на полный путь к оригиналу. Если затем перенести весь архив в другое место, абсолютная ссылка может стать нерабочей.
Поэтому для переносимых архивов чаще практичнее hard links, а для локальных неизменяемых структур — symlinks могут быть удобны, если нужен прозрачный указатель на оригинальный файл.
Поиск с ограничением размера
В больших каталогах часто нет смысла проверять совсем маленькие файлы. Например, в папке проекта могут быть тысячи мелких текстовых файлов, кешей, служебных файлов, фрагментов конфигурации. Даже если среди них есть дубликаты, экономия места будет минимальной. Для таких случаев используется -minsize.
Команда:
rdfind -minsize 1048576 ~/DownloadsОна игнорирует файлы меньше 1 048 576 байт, то есть меньше 1 МиБ. Параметр -minsize N исключает из проверки файлы, размер которых меньше N байт.
Для больших архивов можно задать более высокий порог:
rdfind -minsize 10485760 /mnt/mediaТакой запуск проверяет только файлы от 10 МиБ. Это удобно для каталогов с видео, ISO, архивами, образами дисков и большими наборами изображений.
Есть и обратный параметр:
rdfind -maxsize 104857600 ~/Documents-maxsize N игнорирует файлы размером N байт или больше. По умолчанию эта проверка отключена. Такой фильтр полезен, если нужно проверить только мелкие и средние файлы, но не трогать крупные образы, виртуальные диски или видео.
Работа с пустыми файлами
По умолчанию Rdfind игнорирует пустые файлы. Это поведение соответствует -ignoreempty true, а также эквивалентно -minsize 1. То есть файлы размером 0 байт не участвуют в проверке.
Команда с явным указанием:
rdfind -ignoreempty true ~/ProjectsЕсли нужно включить пустые файлы в анализ, используется:
rdfind -ignoreempty false ~/ProjectsТакой режим нужен редко. Пустые файлы часто являются маркерами, служебными заглушками или частью структуры проекта. Их массовое удаление может нарушить логику некоторых приложений, сборочных систем или скриптов. Поэтому стандартное поведение Rdfind выглядит разумно: пустые файлы лучше не считать обычными дубликатами.
Работа с символическими ссылками
По умолчанию Rdfind не следует по symbolic links. Это значит, что если в сканируемой директории есть символическая ссылка на другую папку, программа не будет автоматически уходить по ней и анализировать целевое дерево. Такое поведение защищает от неожиданного расширения области проверки.
Чтобы включить переход по символическим ссылкам, используется:
rdfind -followsymlinks true ~/DataЭтот режим нужен, когда структура данных намеренно собрана через symlinks и пользователь хочет анализировать не только сами ссылки, но и то, куда они ведут. Однако в обычной очистке домашней папки лучше не включать этот параметр без необходимости: символические ссылки могут вести в системные каталоги, сетевые монтирования, внешние диски или обратно в уже проверяемое дерево.
Контрольные суммы: md5, sha1, sha256, sha512, xxh128 и none
Rdfind поддерживает несколько вариантов checksum:
-checksum md5-checksum sha1-checksum sha256-checksum sha512-checksum xxh128-checksum noneКонтрольная сумма используется на финальной стадии, когда программа уже отсеяла файлы по размеру, первым байтам и последним байтам. По умолчанию применяется sha1. Также доступны md5, sha256, sha512 и xxh128, если сборка поддерживает xxhash.
Пример с sha256:
rdfind -checksum sha256 ~/DocumentsПример с sha512:
rdfind -checksum sha512 /mnt/archivesha256 и sha512 выглядят логичным выбором для сценариев, где важна максимальная осторожность при проверке. На обычных домашних архивах стандартного поведения достаточно, но для критичных данных можно явно указать более сильный алгоритм.
xxh128 ориентирован на скорость, но не является криптографическим алгоритмом. Его можно рассматривать как вариант для больших некритичных наборов данных, если соответствующая поддержка присутствует в сборке.
Особого внимания требует:
rdfind -checksum none ~/DownloadsЭтот режим отключает подсчет контрольной суммы. Использовать его опасно, особенно вместе с удалением или заменой ссылками. Файлы одинакового размера могут иметь разное содержимое, и без checksum возрастает риск ошибочно принять разные файлы за дубликаты. Для безопасной дедупликации файлов лучше не отключать контрольные суммы.
Параметры производительности
Rdfind обычно не требует ручной настройки производительности, но у программы есть несколько параметров для специальных случаев.
-buffersize N
rdfind -buffersize 4194304 /mnt/archive-buffersize задает размер блока при вычислении checksum. По умолчанию используется 1 МиБ, максимальное значение ограничено 128 МиБ. Изменение буфера может влиять на скорость в зависимости от файловой системы, диска и выбранного алгоритма checksum.
На практике этот параметр имеет смысл трогать, когда пользователь уже понимает характер нагрузки: крупные последовательные файлы, медленный сетевой диск, HDD с большим seek time, быстрый SSD, специфическая файловая система.
-firstbytessize N
rdfind -firstbytessize 8192 ~/DownloadsПараметр управляет тем, сколько байт читать в начале файла перед полным checksum. Если указать 0, этап проверки первых байтов отключается.
Отключать этот этап обычно не стоит. Он помогает быстро отсечь разные файлы одинакового размера без полного чтения.
-lastbytessize N
rdfind -lastbytessize 8192 ~/DownloadsЭтот параметр аналогичен предыдущему, но относится к концу файла. Если указать 0, проверка последних байтов отключается.
Проверка последних байтов полезна для архивов, изображений, документов и бинарных файлов, где начало может быть похожим, а различия находятся ближе к концу.
-sleep Xms
rdfind -sleep 10 /mnt/nas/archive-sleep добавляет паузу между чтениями файлов. Поддерживаются не произвольные, а определенные значения: 0, 1-5, 10, 25, 50, 100 миллисекунд. Такой параметр помогает снизить нагрузку на диск или сетевое хранилище.
Это полезно, если rdfind запускается на сервере, где параллельно работают другие задачи: резервное копирование, медиасервер, база данных, синхронизация или индексатор.
-progress true
rdfind -progress true /mnt/archive-progress true включает отображение прогресса во время этапа elimination. Для небольших папок это неважно, но при больших наборах файлов прогресс помогает понимать, что программа продолжает работать, а не зависла.
Практический workflow для безопасной дедупликации
Rdfind можно использовать агрессивно, но лучше применять последовательный workflow. Он снижает риск удаления нужных файлов и помогает понять, что именно происходит.
Шаг 1. Проверить папку без действий
rdfind ~/DownloadsНа этом этапе программа только анализирует файлы и создает results.txt.
Шаг 2. Открыть отчет
less results.txtИли:
cat results.txtНужно просмотреть группы DUPTYPE_FIRST_OCCURRENCE и DUPTYPE_WITHIN_SAME_TREE, обратить внимание на пути и убедиться, что выбранные оригиналы действительно выглядят правильными.
Шаг 3. Проверить действие через dry run
rdfind -deleteduplicates true -dryrun true ~/DownloadsЕсли планируется hardlink-дедупликация:
rdfind -makehardlinks true -dryrun true ~/DownloadsЕсли планируется symbolic links:
rdfind -makesymlinks true -dryrun true ~/DownloadsШаг 4. Выполнить действие
Удаление:
rdfind -deleteduplicates true ~/DownloadsЗамена hard links:
rdfind -makehardlinks true ~/DownloadsЗамена symbolic links:
rdfind -makesymlinks true ~/DownloadsШаг 5. Сохранить отчет
Если работа проводится с важным архивом, удобно сразу задавать имя отчета:
rdfind -outputname rdfind-downloads-before-cleanup.txt ~/DownloadsТакой файл можно оставить рядом с заметками по очистке, чтобы потом восстановить контекст: какие дубликаты были найдены, где лежали оригиналы, сколько места можно было освободить.
Примеры команд для типовых задач
| Задача | Команда | Что делает |
|---|---|---|
| Найти дубликаты в папке загрузок | rdfind ~/Downloads |
Создает results.txt, файлы не меняет |
| Найти дубликаты в документах | rdfind ~/Documents |
Проверяет документы рекурсивно |
| Проверить фотоархив | rdfind ~/Pictures |
Ищет одинаковые изображения и другие файлы |
| Сравнить рабочую папку и бэкап | rdfind ~/Work /mnt/backup/Work |
Считает рабочую папку более приоритетной |
| Сохранить отчет с другим именем | rdfind -outputname report.txt ~/Pictures |
Записывает результат в report.txt |
| Исключить файлы меньше 1 МиБ | rdfind -minsize 1048576 ~/Downloads |
Не тратит время на мелкие файлы |
| Проверить только файлы меньше 100 МиБ | rdfind -maxsize 104857600 ~/Documents |
Не анализирует слишком крупные файлы |
| Включить пустые файлы | rdfind -ignoreempty false ~/Projects |
Учитывает файлы размером 0 байт |
| Следовать по symlinks | rdfind -followsymlinks true ~/Data |
Анализирует цели символических ссылок |
| Использовать SHA-256 | rdfind -checksum sha256 ~/Archive |
Считает контрольные суммы SHA-256 |
| Предпросмотр удаления | rdfind -deleteduplicates true -dryrun true ~/Downloads |
Показывает действие без удаления |
| Удалить дубликаты | rdfind -deleteduplicates true ~/Downloads |
Удаляет неоригинальные файлы |
| Заменить дубли hard links | rdfind -makehardlinks true ~/Archive |
Экономит место, сохраняя пути |
| Заменить дубли symbolic links | rdfind -makesymlinks true ~/Archive |
Заменяет копии ссылками на оригинал |
| Показать прогресс | rdfind -progress true /mnt/archive |
Выводит прогресс обработки |
| Снизить нагрузку на диск | rdfind -sleep 25 /mnt/nas |
Делает паузы между чтениями |
Сценарий: очистка папки загрузок
~/Downloads — одна из лучших папок для первого знакомства с Rdfind. В ней часто появляются повторяющиеся PDF-файлы, установочные архивы, изображения, документы, экспортированные таблицы и файлы с суффиксами (1), (2), copy.
Безопасная команда:
rdfind ~/DownloadsПосле проверки нужно открыть отчет:
less results.txtЕсли в отчете видно, что дубли очевидные, можно выполнить dry run:
rdfind -deleteduplicates true -dryrun true ~/DownloadsИ только затем удаление:
rdfind -deleteduplicates true ~/DownloadsДля папки загрузок лучше не применять слишком сложные параметры. Обычно достаточно стандартного поиска и ручной проверки отчета. Если папка огромная, можно исключить мелкие файлы:
rdfind -minsize 1048576 ~/DownloadsТакой запуск сосредоточится на файлах, где экономия места действительно заметна.
Сценарий: проверка фотоархива
В фотоархиве часто встречаются одинаковые файлы под разными именами. Например, изображение могло попасть в архив из телефона, мессенджера, облака и резервной копии. Rdfind не ищет похожие фотографии, но отлично находит полностью одинаковые файлы.
Базовый запуск:
rdfind ~/PicturesЕсли фотоархив лежит на внешнем диске:
rdfind /media/user/PhotosЕсли нужно сравнить локальную папку и резервную копию:
rdfind ~/Pictures /mnt/backup/PicturesПорядок аргументов здесь имеет смысл. Если локальный архив считается главным, он должен быть первым. Если главным считается внешний архив, первым нужно указать его.
Для больших фотоархивов можно исключить миниатюры и мелкие служебные файлы:
rdfind -minsize 102400 ~/PicturesЭта команда игнорирует файлы меньше 100 КиБ. Она не найдет дубли маленьких превью, зато ускорит проверку и сосредоточится на реальных фотографиях.
Важно не путать Rdfind с программами поиска похожих изображений. Если одна фотография была сжата, обрезана, пересохранена или получила другой размер, Rdfind не будет считать ее дубликатом. Это не недостаток, а четкая специализация: программа ищет идентичное содержимое.
Сценарий: дедупликация резервных копий
Резервные копии — один из самых подходящих сценариев для Rdfind. В них часто повторяются одни и те же файлы: документы, исходники, изображения, архивы, бинарные файлы. Если копии хранятся на одной файловой системе, замена дублей hard links может заметно сократить занимаемое место.
Сначала выполняется отчет:
rdfind /mnt/backupЗатем dry run:
rdfind -makehardlinks true -dryrun true /mnt/backupЗатем реальное действие:
rdfind -makehardlinks true /mnt/backupДля резервных копий hard links часто лучше удаления. Удаление меняет структуру архива: часть файлов исчезает. Hard links сохраняют имена и расположение, но позволяют одинаковым файлам использовать один набор данных на диске.
При этом важно понимать ограничение: hard links подходят для данных, которые не будут редактироваться. Если резервная копия используется как неизменяемый архив, это хороший вариант. Если пользователь открывает файлы из старых бэкапов и редактирует их прямо на месте, жесткие ссылки могут привести к неожиданному изменению всех связанных имен.
Сценарий: сравнение рабочей папки и архива
Допустим, есть рабочая папка:
~/WorkИ архивная копия:
/mnt/archive/WorkЧтобы считать рабочую папку приоритетной, используется:
rdfind ~/Work /mnt/archive/WorkЕсли одинаковый файл есть в обеих папках, Rdfind выберет оригиналом экземпляр из ~/Work, потому что этот путь указан раньше. Если нужно наоборот сохранить архив как главный источник, команда меняется:
rdfind /mnt/archive/Work ~/WorkТакой подход удобен для проверки миграций, переносов данных, ручных резервных копий и старых рабочих каталогов. Программа показывает, какие файлы уже повторяются, и помогает принять решение: удалить лишнее, заменить ссылками или просто сохранить отчет.
Сценарий: поиск дублей только среди крупных файлов
Иногда задача состоит не в идеальной очистке, а в быстрой экономии места. В таком случае не стоит тратить время на мелкие файлы. Для каталога с видео, архивами и ISO-образами можно задать порог:
rdfind -minsize 104857600 /mnt/mediaКоманда проверит только файлы от 100 МиБ. Это хороший вариант для медиатеки, папки виртуальных машин, архива дистрибутивов, каталога с резервными ZIP/TAR-архивами и папки с экспортами.
Для ISO-образов пример может выглядеть так:
rdfind -minsize 100000000 -makehardlinks true /mnt/iso-archiveСначала лучше выполнить без -makehardlinks true, затем с -dryrun true, и только потом запускать реальную замену. Но сама идея понятна: крупные идентичные файлы дают максимальную экономию.
Сценарий: подготовка отчета для ручного удаления
Rdfind не обязательно должен сам удалять файлы. Иногда лучше использовать его только как анализатор:
rdfind -outputname duplicates.txt ~/DocumentsПосле этого отчет можно открыть в редакторе, просмотреть строки, найти группы по id, скопировать пути и удалить лишние файлы вручную.
Для удобного чтения можно отфильтровать только дубликаты:
grep "DUPTYPE_WITHIN_SAME_TREE" duplicates.txtИли посмотреть только оригиналы:
grep "DUPTYPE_FIRST_OCCURRENCE" duplicates.txtМожно также искать конкретные расширения:
grep ".pdf" duplicates.txtgrep ".jpg" duplicates.txtgrep ".zip" duplicates.txtТакой режим особенно удобен, если в архиве много ценных документов, и автоматическое удаление нежелательно.
Помощь и параметры командной строки
Rdfind показывает справку через:
rdfind --helpИли:
rdfind -helpТакже используется:
man rdfindВ справке перечислены основные режимы: -makesymlinks, -makehardlinks, -deleteduplicates, -ignoreempty, -minsize, -maxsize, -outputname, -followsymlinks, -checksum, -dryrun, -sleep и другие параметры.
Для повседневной работы обычно достаточно небольшого набора:
rdfind ~/folderrdfind -outputname report.txt ~/folderrdfind -minsize 1048576 ~/folderrdfind -deleteduplicates true -dryrun true ~/folderrdfind -deleteduplicates true ~/folderrdfind -makehardlinks true ~/folderОстальные параметры нужны для тонкой настройки, больших наборов данных и специальных сценариев.
Сильные стороны Rdfind
Безопасное поведение по умолчанию
Главный плюс Rdfind — программа не удаляет файлы при обычном запуске. Она создает results.txt и показывает потенциальную экономию места. Для утилиты, работающей с удалением и дедупликацией, это правильное поведение.
Поиск по содержимому
Rdfind сравнивает файлы по содержимому, а не по названию. Это делает ее полезной в реальных архивах, где одинаковые файлы часто называются по-разному.
Экономный алгоритм чтения
Программа не читает все файлы полностью без необходимости. Она постепенно отсеивает кандидатов по размеру, первым байтам, последним байтам и checksum. Это делает поиск дубликатов рациональным на больших наборах данных.
Поддержка удаления, hard links и symbolic links
Rdfind умеет не только находить дубли, но и выполнять практические действия:
-
удалить дубликаты;
-
заменить их hard links;
-
заменить их symbolic links;
-
сделать dry run перед изменениями.
Такой набор закрывает основные сценарии дедупликации.
Хорошая автоматизация
CLI-формат удобен для скриптов. Команды можно запускать через shell, cron, SSH, системные задачи, Ansible-плейбуки или собственные backup-скрипты. В отличие от GUI-программ, Rdfind не требует рабочего стола и может работать на сервере.
Понятный отчет
results.txt легко читать, фильтровать через grep, обрабатывать через awk, сохранять в историю очистки и использовать как основу для ручной проверки.
Ограничения и недостатки
Нет графического интерфейса
Rdfind не подойдет пользователю, которому нужен визуальный список с чекбоксами, предпросмотром изображений, сортировкой колонок и кнопкой удаления. Все управление идет через командную строку.
Нет поиска похожих файлов
Программа ищет идентичные файлы, а не похожие. Она не найдет две фотографии одной сцены, если одна была пересжата. Она не найдет похожие документы, если в одном изменена строка. Она не ищет похожую музыку по тегам или акустическому отпечатку.
Порядок аргументов имеет значение
При сравнении нескольких директорий первый путь получает более высокий приоритет. Это мощная возможность, но ошибка в порядке аргументов может привести к тому, что оригиналом будет считаться не тот экземпляр.
Удаление требует осторожности
-deleteduplicates true удаляет файлы. Это действие нужно использовать только после проверки отчета и dry run. Особенно осторожно нужно работать с системными каталогами, чужими домашними папками, правами разных пользователей и активно изменяемыми директориями. Rdfind рассчитан на дедупликацию директорий одного владельца и не управляет сложными сценариями владения и разрешений.
Symbolic links создаются абсолютными
Если использовать -makesymlinks true, ссылки будут абсолютными. При переносе архива они могут сломаться, если оригинальный путь перестанет существовать.
Безопасность при работе с Rdfind
Rdfind нужно запускать на стабильных данных. Не стоит одновременно копировать, перемещать, переименовывать или изменять файлы в директории, которую программа сейчас анализирует. Особенно это важно при удалении или создании ссылок. При изменении дерева каталогов во время работы повышается риск некорректного поведения.
Практические правила:
-
не запускайте
-deleteduplicates trueпервым действием; -
всегда проверяйте
results.txt; -
используйте
-dryrun trueперед удалением или заменой ссылками; -
не применяйте Rdfind к системным директориям без ясной цели;
-
не запускайте программу по каталогам разных пользователей;
-
не трогайте папку во время сканирования;
-
не используйте
-checksum noneвместе с удалением; -
заранее продумайте порядок аргументов;
-
для важных данных сохраняйте отчет с понятным именем.
Хороший шаблон для осторожной работы:
rdfind -outputname rdfind-report.txt /path/to/folderless rdfind-report.txtrdfind -deleteduplicates true -dryrun true /path/to/folderrdfind -deleteduplicates true /path/to/folderДля hard links:
rdfind -outputname rdfind-report.txt /path/to/archiveless rdfind-report.txtrdfind -makehardlinks true -dryrun true /path/to/archiverdfind -makehardlinks true /path/to/archiveПодробный разбор ключевых параметров
| Параметр | Значение по смыслу | Когда использовать |
|---|---|---|
-ignoreempty true |
Игнорировать пустые файлы | Почти всегда, это стандартное поведение |
-ignoreempty false |
Учитывать пустые файлы | Когда нужно найти все нулевые дубли |
-minsize N |
Пропустить файлы меньше N байт |
Для ускорения и фокуса на крупных дублях |
-maxsize N |
Пропустить файлы размером N байт и больше |
Когда крупные файлы трогать не нужно |
-followsymlinks true |
Следовать по symbolic links | Для специально связанных деревьев каталогов |
-removeidentinode true |
Убирать уже одинаковые inode/device | Обычный режим работы |
-checksum sha256 |
Использовать SHA-256 | Для более строгой проверки |
-checksum none |
Не считать checksum | Нежелательно для удаления |
-buffersize N |
Размер блока для checksum | Для тонкой настройки производительности |
-firstbytessize N |
Сколько байт читать в начале файла | Для настройки раннего отсева |
-lastbytessize N |
Сколько байт читать в конце файла | Для настройки раннего отсева |
-deterministic true |
Стабильный выбор при равном ранге | Обычный предсказуемый режим |
-makeresultsfile true |
Создавать отчет | Почти всегда полезно |
-outputname name |
Имя отчета | Для нескольких проверок |
-deleteduplicates true |
Удалить дубликаты | После проверки отчета |
-makehardlinks true |
Заменить дубли hard links | Для архивов и бэкапов |
-makesymlinks true |
Заменить дубли symbolic links | Когда нужны явные ссылки |
-dryrun true |
Ничего не менять, показать действие | Перед любым опасным режимом |
-progress true |
Показывать прогресс | Для больших каталогов |
-sleep Xms |
Пауза между чтением файлов | Для снижения нагрузки на диск |
Сравнение с аналогами
Rdfind находится в одной нише с другими инструментами поиска дубликатов, но отличается от них философией. Он не самый визуальный, не самый многофункциональный и не самый интерактивный. Его сильная сторона — лаконичная дедупликация по содержимому, понятный отчет и удобная работа в командной строке.
| Программа | Тип | Что умеет | Чем отличается от Rdfind | Когда выбрать |
|---|---|---|---|---|
| Rdfind | CLI | Ищет дубликаты по содержимому, создает results.txt, удаляет дубли, делает hard links и symlinks |
Сфокусирован на одной задаче и хорошо подходит для скриптов | Для серверов, бэкапов, SSH, архивов, автоматизации |
| fdupes | CLI | Ищет и удаляет дубликаты в директориях | Часто используется для интерактивного удаления; ищет через размер, MD5 и byte-by-byte comparison | Когда нужен простой классический инструмент с ручным выбором |
| rmlint | CLI | Ищет дубликаты, пустые файлы, пустые папки, битые ссылки, bad IDs и другой файловый мусор | Шире по возможностям, генерирует исполняемые сценарии очистки и разные форматы вывода | Когда нужна комплексная проверка файловой системы |
| dupeGuru | GUI | Ищет дубликаты через графический интерфейс, поддерживает fuzzy matching, режимы для музыки и изображений | Удобнее для визуального выбора и похожих имен/картинок | Когда нужен GUI, предпросмотр и ручная сортировка |
| Czkawka | GUI/CLI | Ищет дубликаты, пустые папки, большие файлы, похожие изображения, видео, музыку, broken files и другие категории | Более универсальный чистильщик с графическим интерфейсом и CLI | Когда нужен современный многофункциональный инструмент |
| jdupes | CLI | Развитый CLI-поиск дубликатов, близкий по духу к fdupes | Больше ориентирован на расширенные режимы fdupes-подобной работы | Когда нужен CLI с большим количеством режимов выбора и удаления |
fdupes — близкий по назначению инструмент. Он ищет дубликаты в заданных директориях и определяет их через сравнение размеров, MD5-сигнатур и последующее побайтовое сравнение. В сравнении с Rdfind он воспринимается как более классический инструмент для вывода и ручной обработки групп.
rmlint шире: он ищет не только duplicate files, но и duplicate directories, empty files, empty directories, broken symlinks, файлы с проблемными UID/GID и другие типы lint. При этом сам rmlint не удаляет файлы напрямую по умолчанию, а создает исполняемый вывод, например shell script, который помогает выполнить очистку.
dupeGuru ориентирован на пользователей, которым нужен графический интерфейс. Он умеет искать дубликаты по именам и содержимому, использует fuzzy matching для похожих имен, имеет специальные режимы для музыки и изображений, а также позволяет удалять, перемещать или копировать найденные дубликаты.
Czkawka — более широкий инструмент для очистки хранилища. Он включает поиск дубликатов по имени, размеру или hash, поиск пустых папок, больших файлов, временных файлов, похожих изображений, похожих видео, музыкальных совпадений, битых файлов, неверных расширений и других категорий. У него есть GUI и CLI, поэтому он конкурирует не только с Rdfind, но и с целым классом программ для обслуживания файловой системы.
Rdfind выигрывает там, где не нужен универсальный чистильщик. Если задача звучит как найти одинаковые файлы по содержимому и безопасно заменить копии hard links, Rdfind выглядит прямым и понятным решением. Если же нужно просматривать миниатюры, сравнивать похожие фотографии или чистить десятки типов мусора, лучше подходят dupeGuru, Czkawka или rmlint.
Для кого подходит Rdfind
Rdfind хорошо подходит пользователям, которые понимают командную строку и хотят точный инструмент без лишнего интерфейса.
Основные аудитории:
-
администраторы Linux-серверов;
-
пользователи, работающие через SSH;
-
владельцы NAS и домашних файловых серверов;
-
разработчики, у которых копятся сборки, архивы и дубли проектов;
-
пользователи с большими папками
Downloads,Documents,Pictures; -
те, кто хранит много резервных копий;
-
люди, которым нужно заменить копии hard links без ручного перебора;
-
пользователи, которым нужен отчет
results.txtдля проверки и последующей обработки.
Для таких сценариев Rdfind удобен тем, что команда короткая, результат читаемый, поведение по умолчанию безопасное, а действия явно включаются через параметры.
Для кого Rdfind не лучший вариант
Rdfind не лучший выбор, если пользователь ожидает визуальную программу с кнопками и предпросмотром. Если нужно открыть список фотографий, увидеть миниатюры, отметить галочками, сравнить похожие изображения и удалить выбранные копии мышью, лучше использовать GUI-инструмент.
Также Rdfind не подходит для задач вроде:
-
найти похожие, но не идентичные фотографии;
-
найти одинаковые песни по тегам или звучанию;
-
сравнить документы по содержанию текста;
-
найти похожие видео;
-
очистить временные файлы браузеров;
-
удалить кеши приложений;
-
проанализировать размер папок визуальной картой.
Программа решает конкретную задачу: duplicate file finder command line для настоящих идентичных файлов. Чем точнее задача совпадает с этим назначением, тем лучше Rdfind проявляет себя.
Типичные ошибки при работе
Запуск удаления без отчета
Плохой вариант:
rdfind -deleteduplicates true ~/DocumentsТехнически команда корректна, но для первой проверки важной папки это слишком рискованно. Лучше сначала:
rdfind ~/Documentsless results.txtНеправильный порядок аргументов
Плохой вариант для случая, когда рабочая папка должна быть главной:
rdfind /mnt/backup/Documents ~/DocumentsЕсли первым указан бэкап, он получает приоритет. Правильнее:
rdfind ~/Documents /mnt/backup/DocumentsОтключение checksum
Опасный вариант:
rdfind -checksum none -deleteduplicates true ~/DownloadsТакой режим повышает риск ошибочной дедупликации. Для удаления и ссылок лучше оставлять checksum включенным.
Работа по активно меняющейся директории
Не стоит запускать Rdfind на папку, куда в этот момент идет синхронизация, копирование, сборка проекта, загрузка торрента, работа backup-демона или импорт фотографий. Дерево файлов должно быть стабильным.
Непонимание hard links
После -makehardlinks true одинаковые файлы могут остаться видимыми в разных местах, но указывать на один inode. Это экономит место, но требует понимания: изменение содержимого через один путь отражается на остальных hardlink-именах.
Непонимание symlinks
После -makesymlinks true дубликаты превращаются в symbolic links. Rdfind создает абсолютные ссылки, поэтому перенос каталога может сломать такие связи.
Рекомендации по настройке под разные задачи
Для домашней папки
rdfind -outputname home-duplicates.txt ~Лучше не запускать удаление сразу. Домашняя папка содержит конфиги, кеши, проекты, скрытые файлы, данные приложений. Для первого анализа достаточно отчета.
Для папки загрузок
rdfind -minsize 1048576 ~/DownloadsХороший баланс: мелкие файлы игнорируются, крупные дубли находятся быстро.
Для фотоархива
rdfind -minsize 102400 ~/PicturesПорог помогает не отвлекаться на миниатюры и служебные файлы.
Для резервных копий
rdfind -makehardlinks true -dryrun true /mnt/backupПосле проверки:
rdfind -makehardlinks true /mnt/backupДля отчета без файла results.txt
rdfind -makeresultsfile false ~/DownloadsИспользуется редко, потому что отчет — одна из главных сильных сторон программы.
Для больших сетевых хранилищ
rdfind -progress true -sleep 25 /mnt/nas/archiveТакой запуск показывает прогресс и снижает нагрузку за счет пауз между чтениями.
Что можно сделать в Rdfind
Rdfind выполняет конкретный набор задач:
-
найти дубликаты файлов внутри одной директории;
-
найти дубликаты между несколькими директориями;
-
сравнить содержимое файлов независимо от названий;
-
создать отчет
results.txt; -
переименовать отчет через
-outputname; -
исключить пустые файлы;
-
включить пустые файлы;
-
игнорировать файлы меньше заданного размера;
-
игнорировать файлы больше заданного размера;
-
следовать или не следовать по symbolic links;
-
выбрать алгоритм checksum;
-
отключить checksum, если пользователь осознанно принимает риск;
-
показать потенциальную экономию места;
-
удалить дубликаты;
-
заменить дубликаты hard links;
-
заменить дубликаты symbolic links;
-
выполнить dry run;
-
показать progress;
-
снизить нагрузку на диск через
-sleep; -
использовать результаты в скриптах.
Это фактический набор действий, который выполняется именно через параметры Rdfind.
Частые вопросы
Rdfind удаляет файлы сразу?
Нет. При обычном запуске программа создает results.txt и показывает возможную экономию места. Удаление включается только параметром -deleteduplicates true.
Где появляется results.txt?
В текущей рабочей директории, из которой запущена команда. Имя можно изменить через -outputname.
Можно ли искать дубликаты в двух папках?
Да. Нужно указать обе папки:
rdfind ~/Folder1 ~/Folder2Программа проверит дубликаты внутри них и между ними.
Как указать, какую папку считать главной?
Поставить ее первой в команде:
rdfind ~/MainFolder ~/BackupFolderФайлы из более раннего аргумента получают более высокий ранг.
Что лучше: удалить дубликаты или заменить hard links?
Для папки загрузок обычно проще удалить. Для резервных копий и архивов часто лучше hard links, потому что структура каталогов сохраняется, а место экономится.
Можно ли использовать Rdfind для похожих фотографий?
Нет. Rdfind ищет идентичные файлы. Для похожих фотографий нужен инструмент с image similarity или fuzzy picture matching.
Что означает DUPTYPE_FIRST_OCCURRENCE?
Это файл, который программа считает оригиналом в группе совпадений. Остальные строки той же группы являются дубликатами.
Что означает DUPTYPE_WITHIN_SAME_TREE?
Это дубликат, найденный внутри того же дерева каталогов, что и оригинал.
Что означает DUPTYPE_OUTSIDE_TREE?
Это дубликат, найденный при обработке другого входного аргумента, а не того же дерева, где найден оригинал.
Можно ли запускать Rdfind на сервере без графического интерфейса?
Да. Это CLI-программа, поэтому она хорошо подходит для серверов и SSH-сессий.
Можно ли запускать Rdfind по системным папкам?
Технически можно, но практически это плохая идея без четкой необходимости. Системные каталоги содержат файлы с разными владельцами, правами, ссылками и служебной логикой. Rdfind рассчитан на дедупликацию директорий, контролируемых одним пользователем.
Можно ли перемещать файлы во время работы Rdfind?
Не стоит. Директорию лучше не менять во время сканирования, особенно если включены удаление или создание ссылок.
Итоговая оценка
Rdfind — сильная программа для тех случаев, когда нужен точный поиск дубликатов файлов Linux через терминал. Она не отвлекает лишним интерфейсом, не подменяет задачу универсальной очисткой системы и не пытается быть графическим файловым менеджером. Ее задача конкретна: найти одинаковые файлы по содержимому, выбрать оригинал по понятным правилам, записать отчет и при необходимости удалить дубликаты или заменить их hard links/symbolic links.
Главные преимущества Rdfind — безопасное поведение по умолчанию, поиск по содержимому, понятный results.txt, поддержка dry run, возможность hardlink-дедупликации и удобство автоматизации. Главные ограничения — отсутствие GUI, отсутствие поиска похожих файлов и необходимость понимать порядок аргументов.
Для папки загрузок Rdfind работает как аккуратный анализатор дублей. Для фотоархива — как способ найти полностью одинаковые изображения. Для резервных копий — как практичный инструмент экономии места через hard links. Для сервера — как простой command line duplicate file finder, который можно запускать без графического окружения.
Оптимальный подход к работе с программой такой: сначала rdfind /path, затем чтение results.txt, потом -dryrun true, и только после этого удаление или замена ссылками. Такой workflow раскрывает сильные стороны Rdfind и снижает риск ошибок при дедупликации.