
rmlint — это специализированная утилита для поиска дубликатов файлов, дубликатов директорий и другого файлового мусора в Unix-подобных системах. В отличие от простых duplicate file finder-инструментов, rmlint работает шире: он находит одинаковые файлы, пустые файлы, пустые каталоги, рекурсивно пустые директории, битые символические ссылки, файлы с некорректным UID/GID и nonstripped-бинарники, то есть исполняемые файлы с отладочными символами. Главный фокус программы — точный и быстрый поиск того, что занимает место, ломает структуру файловой системы или мешает аккуратному хранению данных.
rmlint особенно хорошо подходит для Linux-пользователей, системных администраторов, владельцев NAS, разработчиков, пользователей с большими фотоархивами, резервными копиями, медиаколлекциями и домашними каталогами, где со временем накапливаются повторяющиеся файлы. Программа не является чистильщиком в один клик в стиле массовых Windows-оптимизаторов. Ее логика другая: сначала найти, классифицировать и показать результат, затем сформировать управляемый сценарий действий. Это делает rmlint удобным инструментом для аккуратной очистки, аудита и дедупликации.
Важная особенность rmlint — он сам по себе не удаляет файлы при обычном сканировании. Программа формирует вывод: например, shell-скрипт rmlint.sh, JSON-отчет rmlint.json, CSV или другие форматы. Пользователь может открыть результат, проверить команды, изменить их и только затем выполнить. Такой подход снижает риск случайного удаления нужных данных и хорошо вписывается в Unix-философию: rmlint делает поиск, а дальнейшую обработку можно встроить в скрипты, пайплайны и автоматизацию.
Скачать rmlint
- Оптимизация системы
- Очистка мусора
- Ускорение ПК
- Нет интерфейса
- Сложно новичкам
- Только поиск дублей
Для каких задач используется rmlint
rmlint решает не одну, а несколько практических задач, связанных с порядком в файловой системе. В обычном сценарии пользователь запускает проверку папки Downloads, домашнего каталога, внешнего диска или архива, а программа показывает, какие файлы можно рассматривать как дубликаты и какие объекты являются файловым lint.
Основные задачи, которые можно выполнять в rmlint:
-
искать одинаковые файлы по содержимому, даже если у них разные имена;
-
находить duplicate directories, то есть директории с совпадающими наборами данных;
-
выявлять пустые файлы;
-
находить пустые и рекурсивно пустые папки;
-
искать broken symbolic links, указывающие в никуда;
-
выявлять файлы с некорректным владельцем или группой;
-
искать nonstripped binaries;
-
создавать
rmlint.shдля последующей очистки; -
создавать
rmlint.jsonдля анализа, повторного вывода и автоматизации; -
повторно обрабатывать результаты через
--replay; -
управлять тем, какие пути считать приоритетными и где сохранять оригиналы.
Для пользователя это означает, что rmlint можно применять не только как поиск дубликатов Linux, но и как инструмент ревизии файловой системы. Например, после миграции данных с одного диска на другой можно проверить, все ли файлы со старого носителя уже есть в новом архиве. После нескольких резервных копий можно найти повторяющиеся каталоги. После разработки и сборки программ можно найти nonstripped-бинарники. После перемещения каталогов можно обнаружить битые symlink-ссылки.
Консольная программа и графический интерфейс Shredder
rmlint состоит из консольной утилиты и графического интерфейса Shredder. Основной инструмент — команда rmlint, которую запускают в терминале. Shredder — это GUI-оболочка, запускаемая командой:
rmlint --guiВ графическом интерфейсе пользователь работает не с длинными командными параметрами, а с окнами, списками директорий, деревом результатов, диаграммой, кнопками запуска и редактором скрипта. Shredder использует rmlint как движок: он запускает сканирование в фоне, читает JSON-вывод и показывает найденные объекты в визуальном виде. Генерация скрипта в Shredder также опирается на механизм replay, чтобы корректно пересобрать выбранный вывод после фильтрации результатов.
CLI и GUI не заменяют друг друга полностью. Консольный rmlint удобнее для серверов, cron-задач, SSH-сессий, больших архивов и автоматизации. Shredder удобнее, когда нужно визуально выбрать папки, посмотреть дерево найденных объектов, отметить, какие файлы оставить, а какие удалить, и затем сформировать скрипт через интерфейс.
Интерфейс Shredder: выбор папок и первый экран
Первый важный экран Shredder — Location view. Здесь выбираются директории, которые rmlint будет сканировать. Интерфейс показывает список возможных расположений: домашний каталог, кэш, загрузки, пользовательские папки, смонтированные тома и другие доступные пути. Пользователь может добавить собственную директорию через кнопку Add Location, убрать ненужный путь через Remove from list и запустить проверку кнопкой Scan folders.
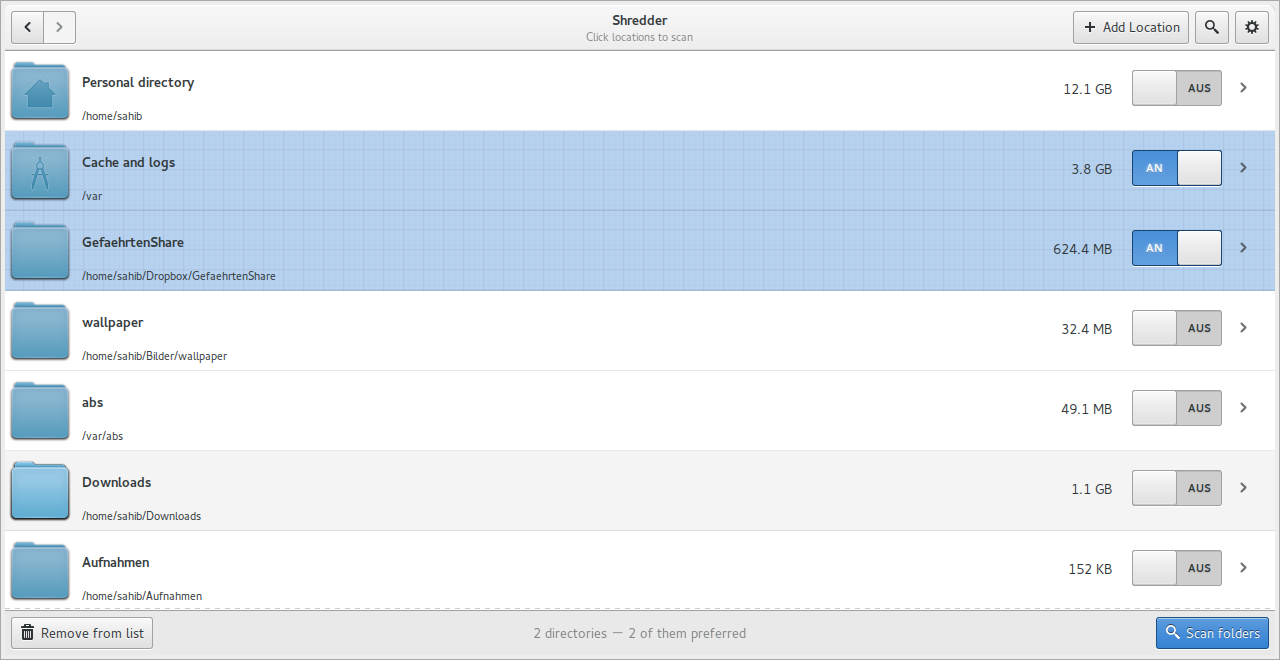
На этом экране особенно важны переключатели рядом с путями. Они позволяют отмечать выбранные директории и задавать предпочтение: какие папки rmlint должен считать более важными при выборе оригинала. Это полезно, когда пользователь сравнивает, например, старую папку с резервной копией и основной каталог. В таком случае можно сделать основной каталог приоритетным, чтобы найденные дубликаты в резервной копии предлагались к удалению, а оригиналы оставались на месте.
В верхней части окна Shredder расположены:
-
кнопка Add Location для добавления новой папки;
-
иконка поиска для фильтрации;
-
иконка шестеренки для перехода к настройкам;
-
навигационные кнопки назад/вперед;
-
заголовок Shredder и подсказка текущего шага.
Внизу находятся:
-
Remove from list — удаление выбранного расположения из списка;
-
статус выбранных директорий;
-
Scan folders — запуск сканирования.
Такой интерфейс делает rmlint доступнее для тех, кто не хочет сразу разбираться с -T, -S, --keep-all-tagged, --must-match-tagged, --algorithm и другими параметрами командной строки.
Как rmlint ищет дубликаты и файловый lint
rmlint получает один или несколько путей и проходит по ним, анализируя файлы и директории. Если пользователь не указывает путь, программа проверяет текущую рабочую директорию. По умолчанию rmlint игнорирует скрытые файлы и не следует по символическим ссылкам как по обычным директориям, что снижает риск неожиданного обхода служебных каталогов и циклов файловой системы. Сначала программа находит другой lint, а затем обрабатывает оставшиеся файлы для поиска дубликатов.
Поиск дубликатов строится вокруг содержимого. rmlint не считает файлы одинаковыми только потому, что у них совпадают имена. Это важное отличие от примитивных способов очистки, где пользователь сортирует файлы по имени и вручную удаляет копии. rmlint смотрит на данные: размер, хеши, а при необходимости byte-by-byte comparison. Для режима максимальной осторожности есть paranoid mode, в котором сравнение идет без доверия к хеш-суммам.
Проверяемые категории задаются через параметр -T или --types. У rmlint есть группы типов и отдельные типы lint. Например:
rmlint -T "df,dd" ~/archiveЭта команда ограничивает проверку дубликатами файлов и дубликатами директорий. Тип df означает duplicate files, а dd — duplicate directories. Если нужно искать не только дубликаты, а все поддерживаемые категории, применяется более широкий набор типов. В обычной работе достаточно стандартного поведения, потому что rmlint уже включает основные проверки, кроме некоторых специализированных категорий вроде nonstripped binaries.
Первый запуск в терминале
Базовый запуск rmlint выглядит очень просто:
rmlint ~/DownloadsКоманда проверяет папку Downloads, выводит результаты в терминал и создает стандартные файлы вывода. В типичном сценарии появляются rmlint.sh и rmlint.json: первый содержит shell-команды для обработки найденных объектов, второй хранит структурированный отчет. Поведение вывода управляется параметрами -o и -O; стандартная схема включает pretty-вывод в терминал, summary-вывод, shell-скрипт и JSON-файл.
Пример минимального запуска в текущей директории:
rmlintТакой вариант удобен, когда пользователь уже находится в нужной папке. Например, если открыть терминал в каталоге с архивом фотографий, командой rmlint можно сразу получить список найденных дубликатов, пустых объектов и итоговую статистику.
Для проверки нескольких путей команда выглядит так:
rmlint ~/Documents ~/Pictures /media/archiveВ этом случае rmlint рассматривает все указанные директории в одном проходе и может найти дубликаты между ними. Это полезно при сравнении рабочего каталога, старого бэкапа и внешнего диска.
Что создают rmlint.sh и rmlint.json
После сканирования rmlint обычно формирует два ключевых файла:
| Файл | Назначение | Как используется |
|---|---|---|
rmlint.sh |
Shell-скрипт с подготовленными действиями | Открывается в редакторе, проверяется и запускается вручную |
rmlint.json |
Структурированный отчет о найденных объектах | Используется для анализа, повторной обработки, replay и автоматизации |
rmlint.replay.json |
JSON-файл повторного вывода при replay | Создается, чтобы не перезаписать исходный результат |
| CSV-вывод | Табличное представление результатов | Удобен для импорта в таблицы и внешние инструменты |
rmlint.sh — это не просто список файлов. Внутри находятся подготовленные команды, функции обработки разных типов lint и логика подтверждения. Его основная ценность в том, что пользователь видит план действий до удаления. Можно открыть скрипт через любой редактор, найти подозрительные пути, удалить из скрипта нежелательные команды и только затем выполнить.
Типичный безопасный порядок такой:
rmlint ~/Downloadsless ./rmlint.sh./rmlint.shПервой командой выполняется сканирование. Второй пользователь просматривает скрипт. Третьей запускает очистку, когда уверен в результате. Именно поэтому rmlint хорошо подходит для рабочих каталогов, резервных копий и больших архивов: программа не требует доверять кнопке удалить все, а позволяет проверить будущие действия.
rmlint.json важен для повторной обработки. Через --replay rmlint может прочитать уже существующий JSON и пересобрать вывод с другими форматами, фильтрами или критериями ранжирования. В replay-режиме программа не выполняет новый полный обход файловой системы; она использует данные предыдущего сканирования и игнорирует файлы, у которых изменилось время модификации относительно JSON-отчета.
Пример повторной обработки:
rmlint --replay rmlint.json ~/archive -S MaDТакой подход полезен, если первое сканирование заняло много времени, а затем нужно пересортировать результаты, изменить формат вывода или сформировать другой скрипт без нового полного анализа диска.
Как rmlint выбирает оригинал и дубликаты
Один из самых важных моментов в rmlint — выбор оригинала. Когда программа находит группу одинаковых файлов, один файл получает статус оригинала, а остальные считаются дубликатами. Это не означает, что оригинал лучше по содержимому: содержимое одинаковое. Оригинал — это файл, который rmlint предлагает оставить.
По умолчанию rmlint ориентируется на порядок указанных путей и дополнительные критерии. Логикой выбора можно управлять через -S или --rank-by. Критерии задаются буквами, где каждая буква отвечает за конкретное правило: время изменения, алфавитный порядок, глубина пути, длина имени, hardlink-count и другие параметры. Если первый критерий не может выбрать оригинал, применяется следующий.
Примеры критериев:
| Критерий | Значение |
|---|---|
m |
оставить файл с самым старым mtime |
M |
оставить файл с самым новым mtime |
a |
оставить первый файл по алфавиту |
A |
оставить последний файл по алфавиту |
p |
оставить файл из первого указанного пути |
P |
оставить файл из последнего указанного пути |
d |
оставить файл на меньшей глубине каталога |
D |
оставить файл на большей глубине каталога |
l |
оставить путь с более коротким basename |
L |
оставить путь с более длинным basename |
r |
оставить путь, совпадающий с regex |
R |
оставить путь, не совпадающий с regex |
h |
оставить файл с меньшим числом hardlinks |
H |
оставить файл с большим числом hardlinks |
Например:
rmlint -S m ~/archiveЭта команда предпочитает более старые файлы как оригиналы. Такой вариант может быть уместен в архиве, где ранняя дата изменения считается признаком исходного файла.
Другой пример:
rmlint -S Ma ~/workЗдесь rmlint сначала предпочитает более новые файлы, а при равенстве применяет алфавитный порядок. Такой сценарий может быть удобен для рабочих документов, где новые версии обычно важнее старых копий.
Tagged paths: как защитить основной каталог
Сильная сторона rmlint — механизм tagged paths. В командной строке используется разделитель //. Все пути после // считаются tagged, то есть предпочтительными. Если дубликат есть и в обычном пути, и в tagged-пути, файл из tagged-пути получает приоритет оригинала.
Пример:
rmlint /media/old-backup // ~/DocumentsЗдесь /media/old-backup — проверяемый старый архив, а ~/Documents — предпочтительный каталог. Если одинаковый файл есть и в старом архиве, и в ~/Documents, rmlint будет считать файл в ~/Documents оригиналом, а копию на старом диске — дубликатом.
Для более жесткой защиты tagged-путей используется параметр -k или полная форма:
rmlint --keep-all-tagged /media/old-backup // ~/DocumentsЭтот режим не предлагает удалять файлы из tagged-путей. Для проверки только тех дубликатов, которые присутствуют в tagged-пути, применяется -m или --must-match-tagged:
rmlint --keep-all-tagged --must-match-tagged /media/old-backup // ~/DocumentsТакой сценарий особенно полезен перед очисткой старого внешнего диска. rmlint найдет только те файлы на старом диске, копии которых уже есть в основном каталоге, и при этом не будет предлагать удалять данные из основного каталога.
Runner view: просмотр результатов в Shredder
После нажатия Scan folders графический интерфейс Shredder переходит к экрану результатов — Runner view. В левой части отображается дерево найденных объектов, в правой — визуальная диаграмма распределения дубликатов по проверяемым директориям. Во время анализа rmlint работает в фоне, а интерфейс постепенно наполняется результатами.
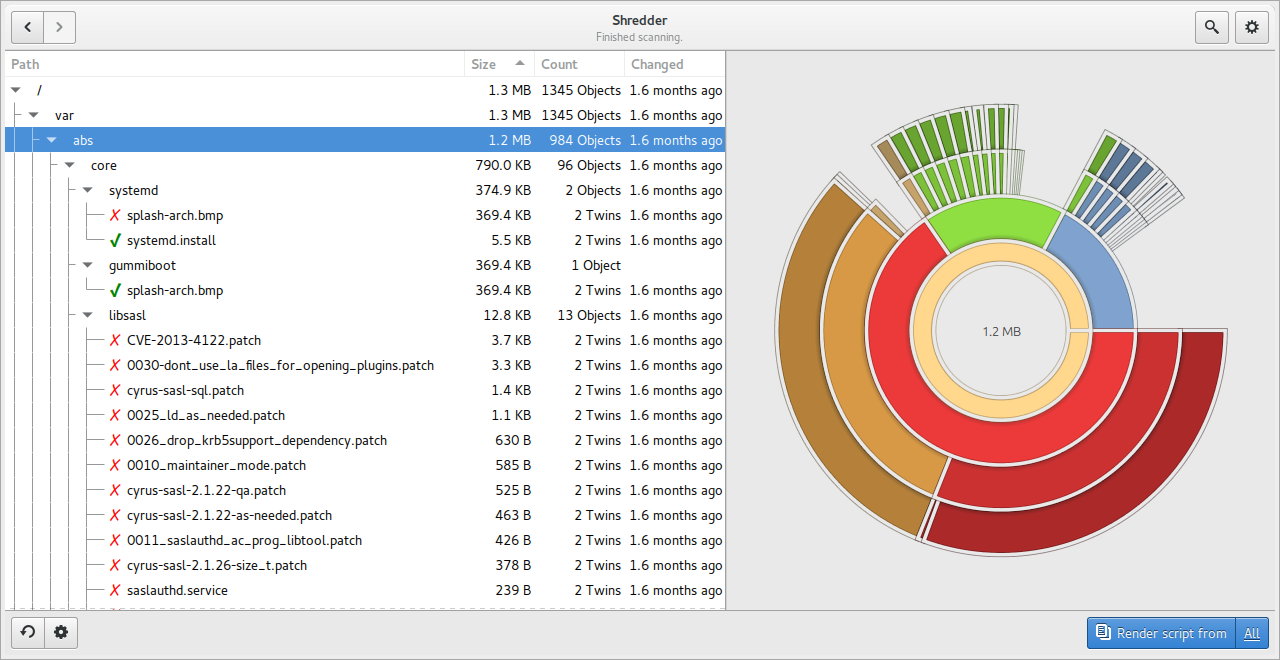
В дереве результатов видны колонки:
-
Path — путь к найденному объекту;
-
Size — размер;
-
Count — количество объектов или twins;
-
Changed — время изменения;
-
значки с красным крестом и зеленой галочкой.
Красный крест означает, что Shredder предлагает удалить этот объект при выполнении скрипта. Зеленая галочка означает, что объект должен остаться. Пользователь может изменить решение вручную, если rmlint выбрал оригинал не так, как нужно. Это особенно важно при работе с фотографиями, рабочими документами, копиями проектов и смешанными архивами, где контекст пути может быть важнее даты или имени.
В правой части Runner view отображается круговая диаграмма. Она помогает понять, где сосредоточены дубликаты. Если большая часть цветного сектора приходится на одну директорию, именно она может быть основным источником повторов. Для больших архивов такая визуализация удобна: пользователь быстрее видит, какая папка создает основной объем мусора.
Внизу справа находится кнопка Render script from. Она формирует скрипт на основе результатов. Рядом может быть выбор области: например, сформировать скрипт по всем найденным объектам или только по видимым после фильтрации. Это позволяет сначала отфильтровать результаты по пути, размеру, времени изменения или количеству twins, а затем создать скрипт только для нужной части.
Фильтрация результатов в Shredder
Shredder поддерживает поиск и фильтрацию в Runner view. Простейший вариант — ввести часть пути или имени файла. Например, если нужно посмотреть только найденные объекты в каталоге Downloads, достаточно ввести соответствующий фрагмент пути.
Более точная фильтрация использует условия:
size:10Ksize:1M-2M,3M-4MМожно фильтровать по размеру, времени изменения и количеству twins. Это полезно, если нужно сначала убрать крупные повторы, а мелкие файлы оставить для отдельной проверки. Например, в фотоархиве можно сосредоточиться на файлах больше 5 MB, а в каталоге исходного кода — наоборот, проверить множество мелких повторяющихся файлов.
Фильтрация делает Shredder не просто визуальной оболочкой, а удобным инструментом ручной ревизии. Пользователь может быстро сузить результат, посмотреть только важные группы и сформировать скрипт не по всему сканированию, а по выбранной видимой части.
Editor view: проверка и запуск скрипта
После формирования скрипта Shredder открывает Editor view. Это встроенный редактор, где показан shell-скрипт, созданный по результатам сканирования. Здесь можно найти нужную строку, просмотреть команды, сохранить файл, выполнить dry run или запустить реальное удаление через Run Script.
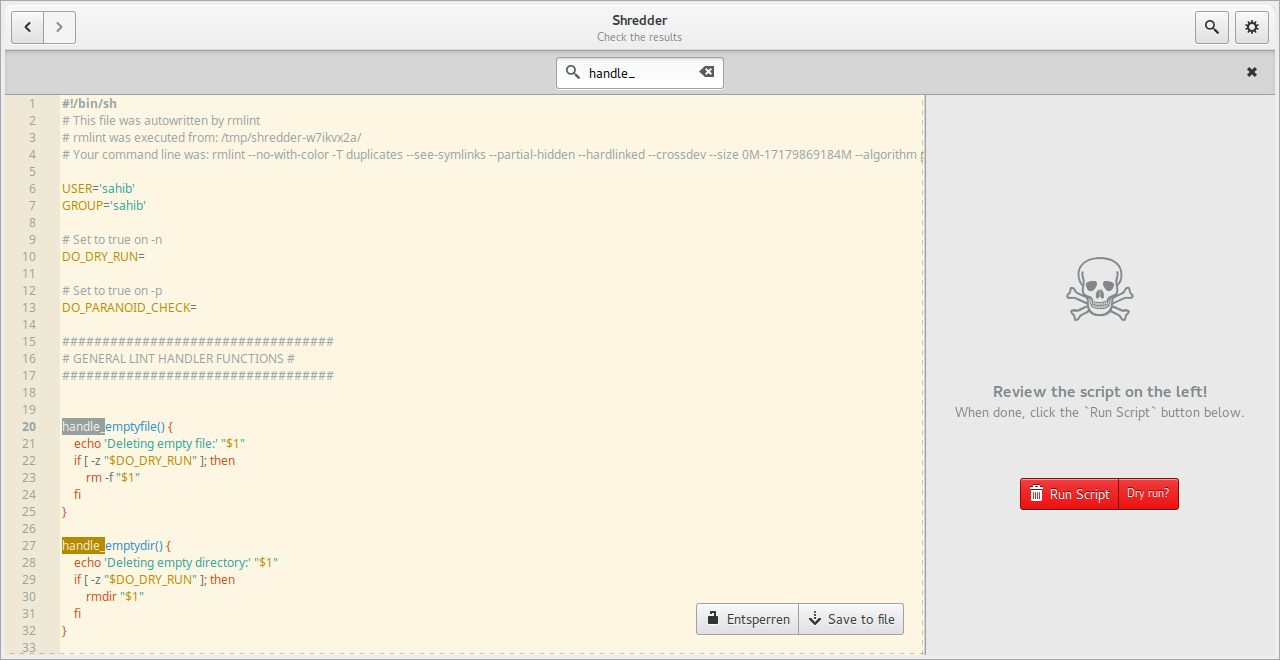
В Editor view видны ключевые элементы:
-
поле поиска по тексту скрипта;
-
основной редактор с подсветкой;
-
кнопка Save to file;
-
кнопка Run Script;
-
переключатель Dry run?;
-
предупреждающая зона с иконкой черепа;
-
счетчик удаляемых или обработанных данных при запуске.
Особенно важен переключатель Dry run?. Когда включен dry run, скрипт выполняется в проверочном режиме и не удаляет файлы. Это лучший способ убедиться, что команды относятся к ожидаемым объектам. После проверки пользователь может отключить dry run и выполнить реальную очистку.
Shredder позволяет сохранять результат не только как .sh, но и как .csv или .json. Это удобно, если нужно передать отчет, открыть данные в таблице, импортировать в другую программу или сохранить доказательство того, какие дубликаты были найдены до очистки.
Settings view: настройки Shredder
Экран Settings view предназначен для настройки логики поиска и обработки результатов. Он доступен через иконку шестеренки в Runner view, пункт Settings или переход к левому экрану интерфейса. Настройки Shredder соответствуют параметрам командной строки rmlint, но представлены в виде переключателей и полей.
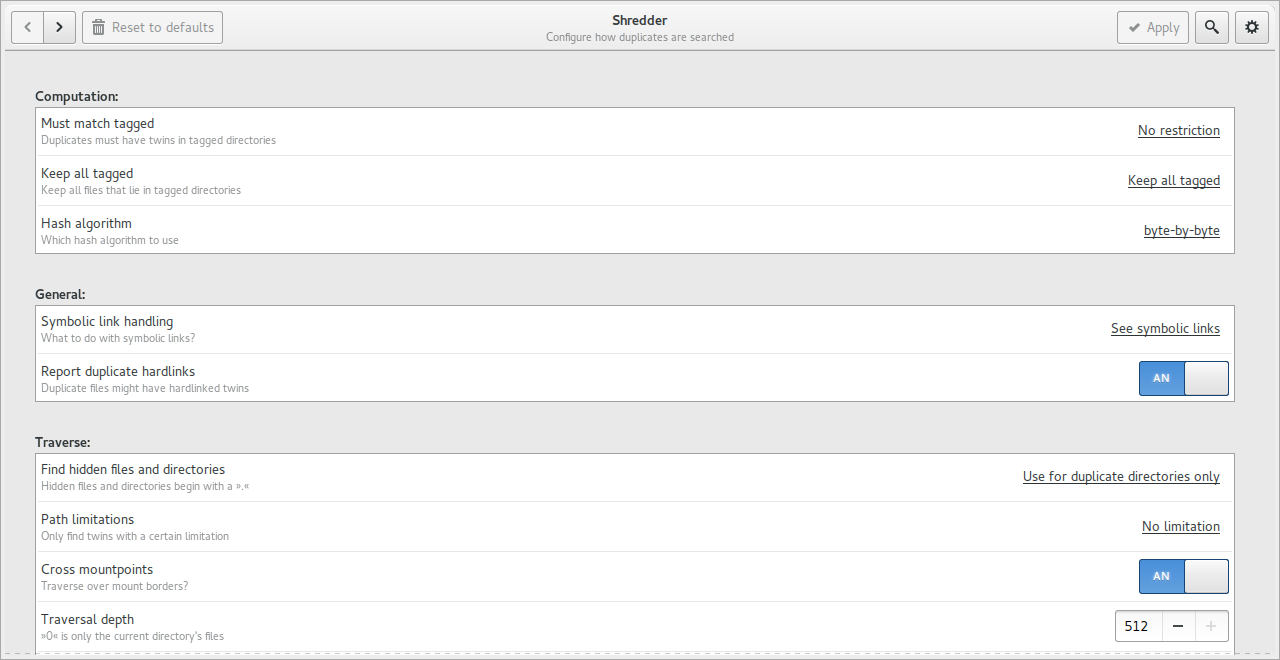
На экране настроек есть несколько групп.
Computation
В блоке Computation находятся параметры, влияющие на выбор и сравнение дубликатов:
-
Must match tagged — ограничивает поиск дубликатами, которые имеют пару в tagged-директориях;
-
Keep all tagged — сохраняет все файлы в tagged-директориях;
-
Hash algorithm — задает алгоритм сравнения, включая byte-by-byte-подход.
Эти параметры особенно важны при сравнении старый диск против основного архива. Включение Keep all tagged защищает основной каталог от удаления, а Must match tagged ограничивает результаты только теми файлами, которые действительно уже есть в защищенной области.
General
В блоке General находятся параметры ссылок и hardlinks:
-
Symbolic link handling — управление тем, что делать с символическими ссылками;
-
Report duplicate hardlinks — показывать ли hardlinked twins как дубликаты.
Для Unix-файловых систем это важная часть. Hardlink может выглядеть как отдельный файл, но фактически ссылаться на тот же inode. Удаление hardlink не всегда освобождает место, поэтому rmlint отдельно обрабатывает этот случай и позволяет управлять поведением.
Traverse
В блоке Traverse задается обход файловой системы:
-
Find hidden files and directories — искать скрытые файлы и папки;
-
Path limitations — ограничение по путям;
-
Cross mountpoints — пересекать ли границы mountpoints;
-
Traversal depth — глубина обхода.
Параметр скрытых файлов требует осторожности. В Linux скрытые директории вроде .git, .cache, .config могут содержать служебные данные. Массовая очистка таких каталогов без проверки способна повредить рабочую среду, репозиторий или кэш приложения. Поэтому для первого запуска лучше проверять обычные пользовательские каталоги и только потом переходить к скрытым областям.
Вверху Settings view находятся кнопки Apply и Reset to defaults. Первая применяет изменения, вторая возвращает настройки по умолчанию.
Поиск только нужных типов lint
rmlint удобен тем, что не заставляет всегда искать все подряд. Через -T можно выбрать конкретные категории.
Только дубликаты файлов
rmlint -T "df" ~/archiveЭтот режим нужен, когда пользователя интересуют именно одинаковые файлы, а пустые каталоги, битые ссылки и другие типы lint пока не важны.
Дубликаты файлов и директорий
rmlint -T "df,dd" ~/archiveХороший вариант для больших архивов и резервных копий. rmlint найдет как отдельные duplicate files, так и duplicate directories.
Все, кроме дубликатов файлов и директорий
rmlint -T "all -df -dd" ~/projectТак можно проверить файловую систему на пустые файлы, пустые директории, битые ссылки и другие проблемы, не смешивая результат с большим количеством повторяющихся файлов.
Пустые файлы
rmlint -T "ef" ~/workПустые файлы часто остаются после неудачных операций, генерации временных данных, тестов или неполных экспортов.
Пустые директории
rmlint -T "ed" ~/workЭтот режим полезен после ручной сортировки архива, когда файлы перемещены, а пустые папки остались.
Битые символические ссылки
rmlint -T "bl" ~/projectsБитые symlink особенно часто появляются после переноса проектов, удаления старых каталогов, изменения путей сборки или перестройки окружения.
Поиск дубликатов директорий
Обычный поиск дубликатов файлов показывает группы одинаковых файлов. Но rmlint умеет работать и с директориями. Для этого используется режим -D или --merge-directories.
rmlint -D ~/archiveВ этом режиме rmlint собирает найденные дубликаты, затем пытается объединить их в полноценные duplicate directories. То есть программа ищет не только отдельные одинаковые файлы, а совпадающие наборы данных внутри каталогов. При этом rmlint ориентируется на содержимое, а не обязательно на имена файлов и точную структуру папок. Если нужно учитывать именно одинаковую иерархию, используется --honour-dir-layout или -j.
Пример с учетом структуры директорий:
rmlint -D -j ~/archiveТакой режим полезен, если пользователь хочет найти именно полностью повторяющиеся деревья каталогов, а не просто папки с совпадающим набором данных.
Для демонстрационного случая:
rmlint fake -D -S aЗдесь rmlint ищет дубликаты директорий в каталоге fake, а -S a задает алфавитный критерий выбора оригинала. В результате программа сначала выводит duplicate directories, затем оставшиеся отдельные duplicate files.
С дубликатами директорий нужно работать внимательнее, чем с одиночными файлами. Во время такого анализа не стоит параллельно перемещать, переименовывать или удалять файлы в проверяемом каталоге. Результат строится на целостном снимке данных, и изменение дерева во время анализа может сделать вывод менее предсказуемым.
Ограничение по размеру
Параметр -s или --size позволяет ограничить поиск дубликатов по размеру. Это особенно полезно, когда нужно быстро найти крупные повторы и не тратить внимание на тысячи мелких файлов.
Найти дубликаты размером от 100 KB до 2 MB:
rmlint --size 100KB-2M ~/archiveНайти только файлы размером от 1 GB:
rmlint --size 1GB ~/videosНайти файлы до 1 MB:
rmlint --size -1M ~/workПо умолчанию пустые файлы не входят в обычный поиск duplicate files, потому что rmlint обрабатывает их как отдельный тип lint. Если нужно включить пустые файлы именно в поиск дубликатов, размерный порог можно опустить до нуля:
rmlint -T df --size 0 ~/archiveОграничение по размеру помогает разделить работу на этапы. Сначала можно найти крупные видеофайлы и архивы, затем отдельно проверить документы, затем — мелкие служебные файлы.
Глубина обхода и скрытые файлы
Параметр -d или --max-depth ограничивает глубину рекурсивного обхода.
Проверить только файлы в текущей папке без глубокого обхода:
rmlint --max-depth 1 ~/DownloadsПроверить текущую папку и один уровень вложенности:
rmlint --max-depth 2 ~/DownloadsТакой подход удобен, если нужно быстро проверить верхний уровень каталога, не заходя в большие вложенные архивы.
Скрытые файлы и папки включаются параметром:
rmlint --hidden ~/home-checkНо использовать его нужно осознанно. Скрытые директории часто содержат конфигурации, историю, индексы, служебные базы, кэши и файлы приложений. Для .git-репозиториев это особенно критично: ручное или автоматическое удаление внутренних объектов может повредить репозиторий. Поэтому --hidden лучше применять к заранее выбранным каталогам, где понятно, что находится внутри.
Символические ссылки и hardlinks
rmlint отдельно учитывает symbolic links и hardlinks. Это принципиально важно в Linux/Unix-среде, где один и тот же набор данных может быть доступен через разные имена, ссылки и mountpoints.
Для symbolic links есть несколько режимов:
rmlint --followlinks ~/archivermlint --no-followlinks ~/archivermlint --see-symlinks ~/archive--followlinks заставляет rmlint следовать по символическим ссылкам. --no-followlinks игнорирует их. --see-symlinks рассматривает symlink как небольшой объект, содержащий путь к цели. Для поиска broken symbolic links применяется тип badlinks или bl.
Hardlinks обрабатываются иначе, потому что несколько имен могут указывать на один и тот же физический набор данных. Удаление одного hardlink не освобождает место, если остались другие ссылки на тот же inode. Поэтому rmlint умеет показывать или скрывать такие случаи и выбирать поведение через параметры --hardlinked, --keep-hardlinked, --no-hardlinked.
Алгоритмы сравнения и paranoid mode
rmlint поддерживает разные алгоритмы для определения duplicate files. В обычном режиме применяется хеширование, а для максимальной осторожности можно включить paranoid mode, то есть byte-by-byte comparison без доверия к хеш-суммам.
Пример byte-by-byte сравнения:
rmlint --algorithm paranoid ~/archiveИли короткий вариант:
rmlint -p ~/archiveParanoid mode нужен там, где пользователь хочет полностью исключить риск коллизии хеша. На практике для обычных пользовательских архивов стандартные алгоритмы работают быстро и надежно, но в критичных задачах режим побайтового сравнения дает дополнительную уверенность.
Снижение уровня паранойи задается вариантами -P, -PP, -PPP, которые переключают rmlint на более быстрые алгоритмы. Это может быть уместно на огромных наборах данных, когда важна скорость и пользователь понимает компромисс.
Вывод в разные форматы
rmlint силен не только поиском, но и форматами вывода. Через -o можно переопределить стандартный вывод, а через -O — добавить новый формат к стандартным.
Вывести JSON в stdout:
rmlint -o json ~/archiveДобавить CSV-файл к стандартному выводу:
rmlint -O csv:/tmp/rmlint.csv ~/archiveСформировать только shell-скрипт:
rmlint -o sh:rmlint.sh ~/archiveСохранить JSON в отдельный путь:
rmlint -o json:/tmp/archive-rmlint.json ~/archiveJSON-вывод особенно ценен для автоматизации. Его можно обрабатывать скриптами, использовать для отчетов, импортировать в собственные инструменты, хранить историю проверок и пересобирать результаты через replay.
CSV удобен для ручного анализа. Его можно открыть в табличном редакторе, отсортировать по размеру, пути, типу lint или времени изменения. Такой подход хорошо подходит для аудита перед большой очисткой.
Caching и повторные проверки
Для больших файловых коллекций повторное сканирование может занимать много времени. rmlint поддерживает кэширование через extended attributes: можно записывать и читать контрольные суммы из xattr, чтобы ускорять последующие проверки. Для этого используются параметры --xattr-read, --xattr-write, --xattr-clear и сокращение --xattr.
Пример первого запуска с записью контрольных сумм:
rmlint large_file_cluster/ --xattr-writeПовторный запуск с чтением кэша:
rmlint large_file_cluster/ --xattr-readКомбинированный режим:
rmlint large_file_cluster/ --xattrКэширование особенно полезно для больших архивов, которые редко меняются: фотоархивы, видеоколлекции, резервные копии, наборы ISO-образов, архивы проектов. Но оно зависит от поддержки extended attributes файловой системой и требует внимательного отношения к копированию данных: не все инструменты корректно сохраняют xattr при переносе файлов.
Типовые сценарии использования rmlint
Очистка папки Downloads
Папка загрузок часто содержит повторные скачивания, старые архивы, копии документов, установочные файлы и временные изображения. Для первичной проверки достаточно:
rmlint ~/DownloadsПосле завершения стоит открыть rmlint.sh, проверить пути и только затем выполнить скрипт. Для начинающего пользователя это лучший стартовый сценарий: папка ограниченная, понятная, а результат легко проверить вручную.
Проверка домашнего каталога
rmlint ~Такой запуск может дать очень большой результат. Для домашнего каталога лучше начинать с отдельных папок:
rmlint ~/Documents ~/Pictures ~/DownloadsПроверка всего ~ удобна для аудита, но требует осторожности из-за скрытых конфигураций, кэшей и программных данных.
Сравнение старого и нового диска
rmlint --keep-all-tagged --must-match-tagged /media/old-drive // /media/new-driveЭта команда проверяет, какие файлы на старом диске уже есть на новом. Путь после // защищается как tagged. Такой сценарий помогает перед освобождением внешнего диска, но перед реальным удалением все равно нужно просмотреть rmlint.sh.
Проверка фотоархива
rmlint -T "df,dd" ~/Picturesrmlint ищет точные дубликаты фотографий и дублирующиеся директории. Это не инструмент поиска визуально похожих изображений: он не ищет почти одинаковые кадры, снимки с другим разрешением или отредактированные версии. Его задача — exact duplicates по содержимому. Для фотоархива это полезно, когда есть копии одних и тех же файлов после импорта с телефона, камеры, облака и резервных дисков.
Проверка проектов разработки
rmlint -T "df,ed,ef,bl" ~/projectsКоманда ищет duplicate files, empty directories, empty files и broken links. Для проектов это полезно после реорганизации структуры, удаления зависимостей, переноса workspace или сборки.
Поиск nonstripped binaries
rmlint -T "ns" ~/buildТак можно найти бинарники с отладочными символами. Для разработчика это способ понять, какие файлы занимают больше места из-за символов отладки.
Формирование отчета без стандартного скрипта
rmlint -o json:/tmp/report.json ~/archiveКоманда удобна, когда нужно получить только JSON-отчет для анализа или внешней системы.
Добавление progressbar
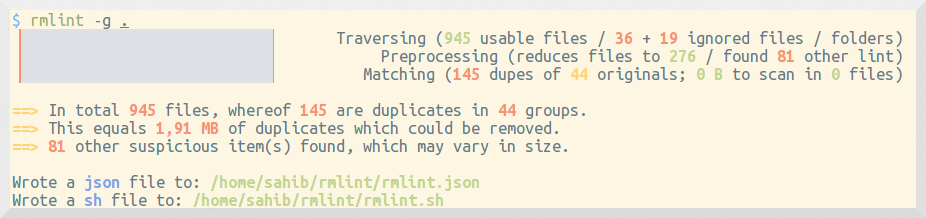
rmlint -g ~/archiveПараметр -g включает progressbar и удобный набор выводов: summary, shell-скрипт и JSON.
Безопасная работа с rmlint
rmlint рассчитан на контролируемую очистку, но безопасность зависит от того, как пользователь применяет результат. Программа формирует скрипт, а скрипт уже может удалять файлы. Поэтому правильный порядок работы важнее скорости.
Рекомендуемый алгоритм:
-
Запустить rmlint на ограниченной папке.
-
Дождаться завершения сканирования.
-
Открыть
rmlint.shв редакторе или просмотрщике. -
Проверить, какие пути предлагаются к удалению.
-
Убедиться, что tagged paths заданы правильно.
-
При работе через Shredder сначала включить Dry run?.
-
Выполнить скрипт только после проверки.
Команда просмотра:
less ./rmlint.shКоманда запуска:
./rmlint.shДля важных архивов лучше сначала сохранять JSON:
rmlint -O json:/tmp/archive-before-cleanup.json ~/archiveТак остается отчет о найденных объектах. Если используется GUI, аналогичную роль выполняет Save to file в Editor view.
Не стоит запускать rmlint.sh от root без необходимости. Проверка системных директорий с повышенными правами может дать результаты, которые пользователь не ожидал увидеть, а удаление системных или служебных файлов может привести к поломке окружения.
Что rmlint делает хорошо
rmlint выделяется среди duplicate file finder-инструментов несколькими особенностями.
Высокая скорость
rmlint рассчитан на большие наборы файлов. Он не тратит время на лишние действия, умеет использовать быстрые алгоритмы, фильтровать кандидатов, работать с кэшем и выводить результат в подходящем формате. На больших деревьях это важнее красивого интерфейса.
Широкий поиск lint, а не только дубликатов
Многие аналоги ограничиваются одинаковыми файлами. rmlint дополнительно ищет пустые файлы, пустые директории, broken symbolic links, bad UID/GID, nonstripped binaries и duplicate directories. Поэтому его можно применять как инструмент технической ревизии.
Генерация скрипта вместо мгновенного удаления
Это одна из главных причин использовать rmlint для серьезных данных. Пользователь получает проверяемый rmlint.sh, а не необратимое действие после кнопки Delete.
JSON и replay
rmlint.json делает программу удобной для автоматизации. Можно один раз просканировать большой архив, а затем повторно формировать вывод с разными критериями.
Tagged paths
Механизм //, --keep-all-tagged и --must-match-tagged позволяет явно сказать программе, где находятся оригиналы. Это удобно при сравнении старого и нового архива, рабочего каталога и резервной копии, NAS и внешнего диска.
Shredder GUI
Наличие графической оболочки делает rmlint доступнее. Пользователь может добавить папки через Add Location, запустить Scan folders, посмотреть дерево результатов, изменить красные кресты и зеленые галочки, сформировать скрипт через Render script from, проверить его в Editor view и выполнить через Run Script.
Ограничения rmlint
rmlint — мощная программа, но не универсальный чистильщик для всех пользователей.
CLI требует понимания
Команды вроде rmlint --keep-all-tagged --must-match-tagged /media/old // ~ очень эффективны, но пользователь должен понимать, что означает //, какие пути являются preferred, что делает -k и почему rmlint.sh нужно читать перед запуском.
Shredder функционален, но не похож на современный массовый GUI
Графический интерфейс решает задачу, но это не визуально насыщенное приложение с предпросмотром фотографий, карточками, мастером очистки и умными рекомендациями. Shredder ближе к техническому интерфейсу для управления результатами rmlint.
Нет поиска похожих изображений
rmlint ищет точные дубликаты по содержимому. Если фотография была сжата, обрезана, переименована с изменением метаданных или сохранена в другом формате, rmlint не должен рассматривать ее как тот же файл. Для similar images лучше подходят другие инструменты.
Дубликаты директорий требуют осторожности
--merge-directories мощный, но сложный режим. Он анализирует наборы данных внутри каталогов, может не учитывать layout без --honour-dir-layout, а вывод откладывается до завершения поиска. Для больших деревьев нужно внимательно проверять результат.
Скрытые каталоги лучше не трогать без необходимости
Параметр --hidden может привести к анализу .git, .cache, .config и других служебных областей. Это полезно для аудита, но опасно для автоматической очистки без проверки.
Сравнение с аналогами
rmlint находится в одной нише с fdupes, jdupes, rdfind, fclones, dupeGuru и Czkawka, но отличается акцентом на Unix-подход, скрипты, JSON, replay, tagged paths и широкий набор lint-категорий.
| Программа | Формат работы | Сильные стороны | Чем отличается rmlint |
|---|---|---|---|
| fdupes | CLI | Простой поиск duplicate files в указанных директориях; сравнение по размеру, MD5 и byte-by-byte verification | rmlint шире: ищет не только duplicate files, но и duplicate directories, empty files, broken links, bad IDs; лучше подходит для скриптового аудита и JSON-вывода |
| jdupes | CLI | Расширенный duplicate file finder с действиями вроде delete, hardlink, symlink, dedupe и JSON | rmlint сильнее в концепции filesystem lint, tagged paths, replay и GUI Shredder; jdupes ближе к мощному наследнику fdupes |
| rdfind | CLI | Поиск duplicate files по содержимому, полезен для бэкапов; умеет заменять дубликаты hardlinks или symlinks | rmlint дает более богатую классификацию lint, больше форматов вывода и гибкую логику выбора оригиналов через -S и // |
| fclones | CLI | Быстрый современный duplicate file finder, JSON, фильтрация, разные способы удаления, linking и reflinking | rmlint отличается поиском не только дубликатов, но и другого файлового мусора; Shredder добавляет GUI, а rmlint.sh делает сценарий очистки прозрачным |
| dupeGuru | GUI | Удобный графический поиск дубликатов, fuzzy matching по именам, режимы для музыки и изображений | rmlint лучше для терминала, серверов, автоматизации, точных duplicate files и Unix-сценариев; dupeGuru удобнее для обычного пользователя и похожих медиафайлов |
| Czkawka | GUI/CLI | Многофункциональная очистка: duplicates, empty folders, big files, temporary files, similar images, similar videos, same music, invalid symlinks | rmlint компактнее и техничнее: сильнее в shell/JSON/replay, tagged paths и контролируемой генерации скрипта; Czkawka шире как визуальный cleaner для разных категорий |
fdupes
fdupes хорош там, где нужен простой и понятный поиск одинаковых файлов. Он исторически популярен, легко запускается и решает базовую задачу duplicate file finder. Но rmlint делает больше. Он ищет не только duplicate files, а целый набор filesystem lint. Кроме того, rmlint создает rmlint.sh и rmlint.json, поддерживает replay, умеет работать с tagged paths и предлагает Shredder GUI. Для разовой проверки маленькой папки fdupes может быть достаточно, но для сложного архива rmlint практичнее.
jdupes
jdupes ближе к rmlint по технической аудитории, потому что это мощный CLI-инструмент для дубликатов с действиями над файлами. Он ориентирован на duplicate files и операции вроде hardlink/symlink/dedupe. rmlint выигрывает там, где нужно искать не только дубликаты, но и пустые директории, bad links, bad IDs и duplicate directories. Еще одно отличие — rmlint делает сильный акцент на сгенерированный скрипт и повторное использование JSON-результата.
rdfind
rdfind удобен для поиска повторяющихся файлов, особенно в резервных копиях. Он сравнивает содержимое, а не имена, и умеет создавать hardlinks или symlinks. Но rmlint гибче в отчетах, выборе оригиналов и типах проверок. Если задача — найти и заменить дубликаты в бэкапе hardlinks, rdfind может быть простым решением. Если нужен более детальный аудит файловой системы, rmlint дает больше контроля.
fclones
fclones — современный и производительный CLI-инструмент, который хорошо подходит для больших наборов duplicate files. У него сильная фильтрация, JSON и разные способы обработки копий. rmlint конкурирует с ним в скорости и автоматизации, но отличается набором задач: rmlint одновременно работает как lint finder. Он находит больше категорий проблем файловой системы и имеет Shredder для визуального контроля.
dupeGuru
dupeGuru лучше для пользователей, которым нужен привычный GUI и поиск похожих файлов по именам, музыке или изображениям. rmlint лучше для точной дедупликации, терминала, серверов, технических архивов и сценариев, где нужно получить shell-скрипт или JSON. Если пользователь работает с фото и хочет найти похожие кадры, dupeGuru может быть удобнее. Если нужно проверить большой Linux-архив и безопасно сформировать команды удаления, rmlint предпочтительнее.
Czkawka
Czkawka — более универсальный визуальный cleaner: он ищет дубликаты, пустые папки, большие файлы, временные файлы, похожие изображения, похожие видео, одинаковую музыку, invalid symlinks, broken files и bad extensions. rmlint не пытается заменить Czkawka как массовый GUI-cleaner. Его сильная сторона — точный Unix-инструмент, который хорошо встраивается в shell, генерирует проверяемый скрипт, работает с tagged paths и повторно использует JSON-результаты.
Кому rmlint подходит лучше всего
rmlint стоит выбирать тем, кто хочет контролировать очистку, а не просто нажимать кнопку удаления.
Лучшие аудитории для rmlint:
-
пользователи Linux, привыкшие к терминалу;
-
системные администраторы;
-
владельцы NAS и домашних серверов;
-
разработчики;
-
пользователи с большими архивами;
-
люди, которые регулярно сравнивают резервные копии;
-
пользователи, которым нужен JSON-отчет;
-
те, кто хочет видеть будущие команды удаления до выполнения;
-
те, кому нужен поиск не только duplicate files, но и broken symlinks, empty directories и bad IDs.
rmlint особенно хорош, когда задача формулируется так: найти все дубликаты на старом диске, но ничего не удалять из основного архива. Механизм //, --keep-all-tagged и --must-match-tagged как раз решает этот сценарий.
Кому rmlint может быть неудобен
rmlint может не подойти пользователю, который хочет максимально простой визуальный интерфейс и не хочет видеть shell-скрипты. Даже в Shredder программа сохраняет техническую логику: дерево путей, скрипт, dry run, параметры поиска. Это плюс для контроля, но минус для тех, кому нужен максимально бытовой cleaner.
rmlint также не лучший выбор для поиска похожих фотографий, похожих видео или музыкальных дублей по тегам. Он ищет точные совпадения данных, а не визуальную похожесть. Если пользователь хочет найти два почти одинаковых JPEG-файла, один из которых был пересжат, rmlint не предназначен для такой задачи.
Для Windows-ориентированного пользователя rmlint тоже может быть менее удобен, чем графические кроссплатформенные аналоги. Основная среда rmlint — Unix-подобные системы, а основная сила раскрывается в терминале и скриптах.
Практический пример: очистка старого резервного диска
Представим, что есть старый диск /media/old-backup, а актуальные данные лежат в домашнем каталоге. Нужно понять, какие файлы на старом диске уже есть в актуальном каталоге, и подготовить удаление только этих повторов.
Команда:
rmlint --keep-all-tagged --must-match-tagged /media/old-backup // ~Что здесь происходит:
-
/media/old-backup— область, где можно искать лишние копии; -
//отделяет обычные пути от tagged-путей; -
~— защищенный preferred path; -
--keep-all-taggedзапрещает удалять файлы из домашнего каталога; -
--must-match-taggedограничивает результат дубликатами, которые имеют пару в домашнем каталоге.
После проверки:
less ./rmlint.shЗатем, если результат правильный:
./rmlint.shПосле удаления файлов можно повторно запустить rmlint для поиска пустых директорий:
rmlint -T "ed" /media/old-backupТакой порядок позволяет не просто почистить диск, а убедиться, что удаляются только данные, уже существующие в защищенном каталоге.
Практический пример: проверка фотоархива
Фотоархивы часто содержат дубликаты после импорта с разных устройств. Один и тот же файл может оказаться в папках Camera, Phone, Backup, Cloud Export, Telegram, Downloads.
Базовая команда:
rmlint -T "df" ~/PicturesЕсли нужно найти также дублирующиеся директории:
rmlint -T "df,dd" ~/PicturesЕсли есть главный каталог с разобранными фотографиями и папка с неразобранным импортом:
rmlint --keep-all-tagged --must-match-tagged ~/Pictures/Unsorted // ~/Pictures/ArchiveЗдесь Archive защищен как tagged-путь. rmlint будет предлагать удалить только то, что в Unsorted уже есть в Archive.
Для крупных фотоархивов удобно ограничить размер:
rmlint --size 1M ~/PicturesТак программа сосредоточится на файлах от 1 MB, то есть преимущественно на реальных фотографиях и видео, а не на миниатюрах и служебных мелких файлах.
Практический пример: проверка каталога разработки
В рабочих проектах накапливаются временные файлы, пустые директории, битые ссылки и повторяющиеся артефакты сборки.
Команда для комплексной проверки:
rmlint -T "df,ed,ef,bl" ~/projectsЧто она ищет:
-
df— duplicate files; -
ed— empty directories; -
ef— empty files; -
bl— bad links.
Если нужно проверить только результаты сборки:
rmlint -T "df,ns" ~/projects/buildЗдесь ns включает поиск nonstripped binaries. Это полезно, если нужно понять, какие бинарники можно дополнительно обработать или исключить из распространяемого набора.
Практический пример: отчет для анализа
Иногда удаление не нужно вообще. Нужно только получить отчет о состоянии архива.
JSON-отчет:
rmlint -o json:/tmp/rmlint-report.json ~/archiveCSV-отчет:
rmlint -o csv:/tmp/rmlint-report.csv ~/archiveСтандартный вывод плюс дополнительный CSV:
rmlint -O csv:/tmp/rmlint-report.csv ~/archiveТакой сценарий полезен для инвентаризации данных. Например, администратор может сформировать отчет, передать его владельцу данных и дождаться подтверждения, прежде чем выполнять rmlint.sh.
Практический пример: быстрый повторный вывод через replay
Предположим, первое сканирование большого архива уже выполнено и создан rmlint.json. Теперь нужно изменить сортировку оригиналов и сформировать новый вывод без полного пересканирования.
rmlint --replay rmlint.json ~/archive -S MaDМожно также объединить несколько JSON-результатов:
rmlint --replay first.json second.json ~/archiveReplay полезен, когда физический обход диска дорогой: сетевое хранилище, внешний HDD, большой NAS, массив с миллионами файлов. Вместо повторного чтения всего дерева rmlint переиспользует уже собранный результат.
Работа с Shredder пошагово
Шаг 1. Запустить GUI
rmlint --guiОткроется Shredder. На первом экране появится список директорий и кнопка Add Location.
Шаг 2. Добавить папки
Нужно нажать Add Location и выбрать папку через файловый диалог. Если проверяются несколько путей, их добавляют по очереди.
Шаг 3. Отметить нужные расположения
В списке директорий включаются переключатели рядом с путями. Если какая-то папка должна быть предпочтительной, ее нужно отметить соответствующим образом. Это влияет на выбор оригинала.
Шаг 4. Запустить проверку
Нажимается Scan folders. Shredder запускает rmlint в фоне и переходит к Runner view.
Шаг 5. Проверить дерево результатов
В Runner view нужно посмотреть группы, красные кресты и зеленые галочки. Красный крест — кандидат на удаление. Зеленая галочка — файл, который останется.
Шаг 6. Отфильтровать лишнее
Через поиск можно оставить видимыми только нужные объекты. Например, отфильтровать по части пути или размеру.
Шаг 7. Сформировать скрипт
Нажимается Render script from. Можно создать скрипт по всем результатам или только по видимой отфильтрованной части.
Шаг 8. Проверить скрипт
В Editor view нужно просмотреть текст, при необходимости найти нужный путь через поиск, сохранить файл через Save to file или оставить скрипт в интерфейсе.
Шаг 9. Выполнить dry run
Перед реальным удалением включается Dry run? и нажимается Run Script. Это проверочный запуск.
Шаг 10. Выполнить реальное действие
Если dry run показывает ожидаемое поведение, dry run отключается, и Run Script выполняет реальную обработку.
Плюсы rmlint
| Плюс | Почему это важно |
|---|---|
| Быстрый поиск | Подходит для больших каталогов, внешних дисков и архивов |
| Поиск разных типов lint | Программа не ограничивается duplicate files |
| Безопасная модель через скрипт | Пользователь проверяет rmlint.sh до удаления |
| JSON-вывод | Удобно для автоматизации и отчетов |
| Replay | Позволяет пересобрать результат без полного нового сканирования |
| Tagged paths | Можно явно защитить основной каталог |
| Shredder GUI | Есть визуальная работа с папками, деревом результатов и скриптом |
| Гибкая сортировка оригиналов | -S позволяет настроить, какие файлы оставлять |
| Поддержка byte-by-byte comparison | Есть режим максимальной осторожности |
| Работа с duplicate directories | Можно искать повторяющиеся деревья каталогов |
Минусы rmlint
| Минус | Что это означает на практике |
|---|---|
| Не самый простой инструмент для новичка | CLI-параметры требуют понимания |
| GUI технический | Shredder удобен, но не выглядит как массовый consumer-cleaner |
| Нет поиска похожих фото | Только точные дубликаты по данным |
| Опасность неправильных предположений | Неверно выбранные tagged paths могут привести к нежелательному скрипту |
| Скрытые директории требуют осторожности | .git, .cache, .config лучше проверять отдельно |
| Duplicate directories — сложный режим | Нужно внимательно читать вывод и понимать --honour-dir-layout |
| Реальное удаление выполняет скрипт | Пользователь должен проверять rmlint.sh |
Лучшие настройки для разных задач
| Задача | Рекомендуемый подход |
|---|---|
| Быстро проверить Downloads | rmlint ~/Downloads |
| Найти только duplicate files | rmlint -T "df" путь |
| Найти duplicate files и duplicate directories | rmlint -T "df,dd" путь |
| Проверить старый диск относительно основного архива | rmlint --keep-all-tagged --must-match-tagged старый_диск // основной_архив |
| Найти пустые папки | rmlint -T "ed" путь |
| Найти битые symlink | rmlint -T "bl" путь |
| Сравнивать byte-by-byte | rmlint -p путь |
| Ограничить крупными файлами | rmlint --size 1GB путь |
| Получить JSON-отчет | rmlint -o json:report.json путь |
| Повторно обработать результат | rmlint --replay rmlint.json путь |
Итоговая оценка rmlint
rmlint — это один из самых сильных инструментов для поиска дубликатов и файлового lint в Linux/Unix-среде. Его главное преимущество — сочетание скорости, точности, контролируемого вывода и технической гибкости. Программа не ограничивается банальным поиском одинаковых файлов: она находит duplicate directories, empty files, empty directories, broken symbolic links, bad UID/GID и nonstripped binaries. Это делает rmlint полезным не только для очистки места, но и для полноценного аудита файловой системы.
Для обычного пользователя rmlint может показаться более строгим и техническим, чем графические cleaner-приложения. Но именно эта строгость делает его надежным в серьезных задачах. Он не удаляет найденное сразу, а формирует rmlint.sh и rmlint.json; он позволяет проверить будущие команды; он поддерживает dry run в Shredder; он умеет защищать приоритетные директории через tagged paths; он дает replay для повторной обработки больших результатов.
rmlint лучше всего раскрывается там, где важны контроль, воспроизводимость и уверенность: резервные копии, домашние серверы, NAS, архивы фотографий, каталоги разработки, внешние диски и большие хранилища. Это не просто программа для удаления дубликатов файлов Linux, а полноценный Unix-инструмент для поиска лишних, повторяющихся и проблемных объектов в файловой системе.