
DupDetector — небольшая Windows-программа для поиска одинаковых и визуально похожих изображений. Она не занимается очисткой реестра, не ищет временные файлы, не анализирует музыку, документы или видео как универсальный duplicate file finder. Ее задача уже и понятнее: взять папку с изображениями, построить по ней базу, сравнить картинки по содержимому, показать найденные пары и дать пользователю удалить лишнюю копию после визуальной проверки.
Главная особенность DupDetector в том, что программа ориентируется не только на имя файла. Для фотоархива это принципиально. В папке могут лежать IMG_2027.jpg, K1600_IMG_2027.jpg, photo_copy.jpg и еще один вариант той же фотографии после изменения яркости или добавления даты поверх кадра. По названию такие файлы не всегда выглядят как дубликаты, но DupDetector сравнивает изображения по пиксельным данным и находит одинаковые или близкие картинки даже при разных именах и размере файла.
Скачать DupDetector
- Оптимизация системы
- Очистка мусора
- Ускорение ПК
- Только изображения
- Старый интерфейс
- Нет очистки системы
Программа особенно уместна для старых локальных фотоархивов, папок с импортами с камер, коллекций картинок, рабочих подборок изображений и архивов, где за годы накопились повторные сохранения, уменьшенные копии, обработанные варианты и почти одинаковые файлы.
Что такое DupDetector
DupDetector — это программа для поиска дубликатов изображений и near-duplicate images, то есть почти одинаковых картинок. Она работает не как обычный файловый менеджер, который сравнивает только имя, расширение, дату изменения или размер файла. Основная логика DupDetector построена вокруг визуального сравнения: программа открывает изображения, считывает их пиксельные данные и затем ищет совпадения по выбранному методу.
Такой подход нужен в ситуациях, где классический поиск одинаковых файлов бессилен. Например, одна фотография может быть сохранена в разных папках с разными названиями. Другая может быть уменьшена. Третья — слегка осветлена, переведена в черно-белый вид или дополнена текстовой датой. Формально это уже разные файлы, но для пользователя они часто являются дублями одной и той же фотографии. DupDetector помогает выявить именно такие совпадения.
В обзоре важно воспринимать DupDetector не как современный фотоорганайзер, а как узкий инструмент для конкретной операции: найти похожие изображения и дать возможность решить, какой файл оставить. В программе нет сложной медиатеки, облачной синхронизации, автоматической сортировки по людям, местам или событиям. Ее рабочая модель более прямолинейная:
-
выбрать папку или набор изображений;
-
построить data file;
-
выбрать метод сравнения;
-
запустить поиск дублей;
-
открыть найденные пары;
-
проверить миниатюры;
-
удалить ненужную копию.
Эта простота одновременно является сильной и слабой стороной. DupDetector не пытается заменить Lightroom, Google Photos, ACDSee или современный менеджер фото. Он закрывает отдельную практическую задачу: поиск дубликатов фото на локальном диске.
Для каких задач подходит DupDetector
DupDetector удобен там, где нужно разобраться с папками, в которых изображения копировались, пересохранялись, переносились между дисками или импортировались несколько раз. Чаще всего программа нужна не для красивой каталогизации, а для наведения порядка в хаотичном наборе файлов.
Типичные задачи:
-
найти одинаковые фотографии с разными именами;
-
найти похожие изображения после изменения яркости, цвета или контраста;
-
проверить папку с подпапками;
-
сравнить изображения внутри одного набора;
-
сравнить изображения между двумя наборами;
-
найти копии между двумя папками;
-
проверить одну выбранную картинку на наличие совпадений в большой коллекции;
-
удалить лишнюю копию после визуального сравнения;
-
освободить место, занятое повторяющимися изображениями;
-
подготовить фотоархив перед переносом на внешний диск.
DupDetector особенно полезен, если в архиве много старых JPEG-файлов с повторяющимися сюжетами. Например, после нескольких импортов с фотоаппарата на диске могут появиться папки Camera, Camera old, Photos backup, New folder, For print, Edited, где одна и та же фотография хранится в исходном виде, уменьшенной копией и обработанным вариантом. Обычный поиск по имени не поможет, если файлы переименованы. Поиск по размеру тоже не даст точного результата, если изображение было пересохранено. DupDetector решает задачу через визуальное сравнение.
Программа также подходит для коллекций изображений, которые собирались из разных источников: обои для рабочего стола, клипарты, сканы, иллюстрации, графические заготовки, старые фотоальбомы. В таких наборах часто есть одинаковые картинки в разных папках, разные версии одной фотографии и почти одинаковые изображения с небольшими отличиями.
При этом DupDetector не стоит использовать как бездумный автоматический удалятель. Дубликаты изображений отличаются от дублей документов или архивов: две картинки могут быть похожими, но одна из них может быть важной обработанной версией, уменьшенной копией для сайта, вариантом с подписью или изображением, входящим в рабочий проект. Поэтому лучший сценарий работы — найти совпадения автоматически, а удалять вручную после просмотра.
Общая логика работы программы
DupDetector построен вокруг последовательного рабочего процесса. В интерфейсе есть вкладки Method, Get data, Find dups и View dups. Они соответствуют основным этапам работы: сначала выбирается метод сравнения, затем программа получает данные об изображениях, после этого запускается поиск, а затем пользователь просматривает найденные совпадения.
Верхнее меню содержит разделы File, Data, Find, View, Options, Tools, Help. Это классическая структура старой Windows-утилиты: основные действия доступны через вкладки, а дополнительные настройки — через меню.
Рабочий процесс выглядит так:
-
Пользователь открывает вкладку Get data.
-
В блоке Primary data file нажимает Build.
-
Выбирает папку с изображениями или другой источник.
-
При необходимости включает обработку подпапок.
-
Переходит к Method и выбирает способ сравнения.
-
Открывает Find dups.
-
Настраивает диапазон совпадения.
-
Нажимает кнопку поиска.
-
Переходит в View dups.
-
Смотрит найденные пары.
-
Удаляет ненужное изображение кнопкой Delete под соответствующей миниатюрой.
Главное отличие DupDetector от некоторых более простых программ для удаления дубликатов фото — промежуточный этап с data file. Программа не просто мгновенно сканирует папку и показывает результат. Она сначала создает набор данных по изображениям, а затем использует его для сравнения. Такой подход выглядит менее привычно для пользователей современных приложений, но хорошо вписывается в логику старых специализированных утилит.
Интерфейс DupDetector
Интерфейс DupDetector простой, но не современный. Это типичное Windows-окно с верхним меню, вкладками и отдельными областями для параметров. В нем нет ленточной панели, карточек, темной темы, мастера с крупными шагами или автоматических рекомендаций. Пользователь сам выбирает, что сравнивать, как сравнивать и что удалять.
Основные элементы интерфейса:
| Элемент | Назначение |
|---|---|
| File | Работа с файлами данных и базовыми операциями |
| Data | Действия, связанные с построением и использованием data file |
| Find | Запуск и настройка поиска совпадений |
| View | Просмотр найденных дубликатов |
| Options | Поведение программы, режимы удаления, сортировка, отображение |
| Tools | Дополнительные инструменты, включая запуск Windows Explorer |
| Help | Справочная информация |
| Method | Выбор сценария сравнения |
| Get data | Создание или открытие файла данных по изображениям |
| Find dups | Настройка и запуск поиска дубликатов |
| View dups | Просмотр найденных совпадений и удаление лишних файлов |
Первое впечатление может быть сухим: окно выглядит техническим, а названия вроде Primary data file или Secondary data file требуют понимания логики программы. Но после первого полного прохода становится ясно, что интерфейс построен линейно. Вкладки идут почти как инструкция: метод, данные, поиск, просмотр.
Во вкладке Method пользователь выбирает, как именно сравнивать изображения. Во вкладке Get data задает, откуда брать изображения. Во вкладке Find dups запускает поиск. Во вкладке View dups принимает решение по найденным парам.
Для программы поиска похожих изображений это удачная структура: самые рискованные действия — удаление файлов — вынесены в отдельный этап просмотра. DupDetector не заставляет сразу чистить диск после сканирования. Он показывает пары изображений, процент совпадения, путь к файлам и дает возможность удалить конкретную копию.
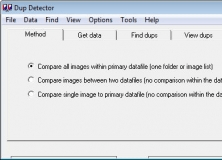
Вкладка Method: выбор метода сравнения
Вкладка Method определяет, что именно будет сравнивать DupDetector. В ней есть три основных сценария:
-
Compare all images within primary datafile (one folder or image list);
-
Compare images between two datafiles (no comparison within the datafiles);
-
Compare single image to primary datafile (no comparison within the datafile).
Первый вариант — самый частый. Он используется, когда нужно проверить одну папку или один список изображений на наличие дублей внутри себя. Например, есть папка Photos, в ней лежат подпапки по годам, событиям и устройствам. Пользователь строит primary data file и выбирает сравнение всех изображений внутри него. DupDetector ищет совпадения между всеми файлами этого набора.
Второй вариант нужен, когда есть две разные коллекции. Например, одна папка находится на внутреннем диске, другая — на внешнем. Или есть основной фотоархив и резервная папка, которую нужно проверить на пересечения. В этом режиме программа сравнивает изображения между двумя data files, но не ищет совпадения внутри каждого набора. Это удобно, если нужно понять, какие фото из одной папки уже есть в другой.
Третий вариант подходит для точечной проверки. Пользователь выбирает одно изображение и сравнивает его с primary data file. Такой сценарий полезен, если есть конкретная картинка и нужно найти ее копии или близкие варианты в большой коллекции.
Эта вкладка важна, потому что от выбранного сценария зависит смысл результатов. Если по ошибке выбрать сравнение между двумя data files, когда нужна проверка внутри одной папки, программа не даст ожидаемого результата. Поэтому перед запуском поиска стоит четко решить, какая задача выполняется: чистка одной коллекции, сравнение двух коллекций или поиск копий одного изображения.
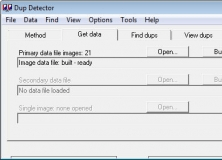
Вкладка Get data: создание базы изображений
Вкладка Get data отвечает за подготовку данных. В DupDetector есть понятие Primary data file — основной файл данных, который создается по выбранной папке, подпапкам или списку изображений. Для начала работы пользователь нажимает Build в блоке Primary data file, после чего выбирает папку с изображениями.
На этом этапе программа проходит по выбранному источнику, открывает изображения и собирает информацию, которая затем используется для поиска совпадений. Это не просто список имен файлов. DupDetector ориентируется на содержимое изображения, поэтому ему нужно прочитать данные картинок, а не только увидеть, что в папке лежат файлы с расширениями .jpg или .gif.
Практически вкладка Get data решает несколько задач:
-
указать основную папку для анализа;
-
создать primary data file;
-
открыть уже созданный primary data file;
-
при необходимости подготовить secondary data file;
-
использовать image list;
-
определить, какие изображения попадут в сравнение;
-
подготовить программу к поиску дубликатов.
Primary data file — центральный элемент. Без него нельзя перейти к нормальному поиску, потому что программе сначала нужно построить базу по изображениям. Если пользователь работает с одной папкой, достаточно primary data file. Если нужно сравнить две разные папки, используется также Secondary data file.
В старом интерфейсе такой подход может казаться лишним: современные программы часто предлагают просто перетащить папку и нажать Start. Но у DupDetector есть своя логика. Построенный data file можно использовать как подготовленный набор для дальнейшего сравнения. Это особенно удобно, когда одна и та же большая папка проверяется не один раз.
Вкладка Find dups: запуск поиска дубликатов
После подготовки данных используется вкладка Find dups. Здесь задается диапазон совпадения и запускается поиск. В интерфейсе есть поле с процентами, где можно указать, какой уровень совпадения считать дубликатом. Например, если поставить поиск в диапазоне от 98% до 100%, программа будет искать изображения, которые почти полностью совпадают.
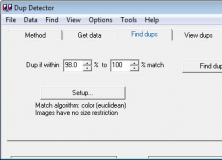
Диапазон совпадения — один из самых важных параметров. Чем выше нижняя граница, тем строже поиск. При значениях около 100% программа будет находить почти точные копии. Если снизить порог, в результаты начнут попадать похожие, но не идентичные изображения. Это полезно для поиска фото после изменения яркости, цвета, размера или конвертации в черно-белый вариант, но одновременно увеличивает риск ложных совпадений.
Условно можно ориентироваться так:
| Задача | Подходящий характер настройки |
|---|---|
| Найти почти точные копии | Высокий процент совпадения |
| Найти пересохраненные JPEG | Высокий или умеренно высокий процент |
| Найти уменьшенные версии фото | Умеренно высокий процент |
| Найти обработанные варианты | Более мягкий диапазон |
| Найти похожие картинки в большой коллекции | Осторожно снижать порог и проверять вручную |
Во вкладке Find dups также отображается информация о выбранном алгоритме. Например, программа может работать с цветовым методом сравнения или с яркостным вариантом. Это важно для коллекций, где есть черно-белые версии цветных изображений или фотографии с измененной цветовой обработкой.
Запуск поиска лучше делать после небольшой подготовки. Если в папке много случайных файлов, временных копий и рабочих изображений, результаты могут быть перегружены. Гораздо удобнее сначала проверить одну тематическую папку, затем другую, а уже после этого переходить к большой коллекции.
Вкладка View dups: просмотр найденных совпадений
Вкладка View dups — наиболее важная часть DupDetector с точки зрения безопасности. Здесь программа показывает найденные пары изображений, пути к файлам, процент совпадения, миниатюры и кнопки Delete под каждым изображением. Пользователь видит две картинки рядом и сам выбирает, какую оставить.
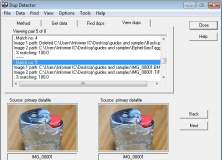
Такой режим лучше автоматической чистки, потому что дубликаты фото не всегда очевидны. Два изображения могут выглядеть одинаково на миниатюрах, но различаться по разрешению, качеству сжатия, наличию даты, обработке, кадрированию или назначению. Одна картинка может быть оригиналом, вторая — уменьшенной копией для отправки по почте. Одна может быть чистой фотографией, вторая — вариантом с подписью. Одна может быть исходником, вторая — финальной обработкой.
В View dups стоит обращать внимание на несколько параметров:
-
визуальное совпадение;
-
процент совпадения;
-
путь к первому изображению;
-
путь ко второму изображению;
-
имя файла;
-
разрешение;
-
размер файла;
-
наличие подписей, дат, рамок или водяных знаков;
-
степень сжатия;
-
принадлежность файла к рабочей папке.
Кнопка Delete находится под каждой миниатюрой. Это удобно, но требует дисциплины: нажимать ее стоит только после проверки. Если программа нашла пару со 100% совпадением, решение обычно простое. Если совпадение 97–99%, нужно смотреть внимательнее. Если совпадение ниже, особенно в коллекции похожих кадров, удалять автоматически опасно.
Навигация по результатам выполняется через кнопки Back и Next. Пользователь последовательно проходит найденные пары и принимает решения. Такой режим подходит для аккуратной чистки: программа делает тяжелую часть поиска, а человек оставляет контроль над удалением.
Настройки поиска и точность совпадений
DupDetector позволяет настроить не только общий процент совпадения, но и метод сравнения. В окне Find dups setup (method and restrictions) доступны варианты Color (euclidean), Color (weighted euclidean), Color (variance) и Luminance (as greyscale). Также есть параметры для зеркальных изображений, использования luminance для серых изображений, коррекции средней цветовой разницы и ограничения сравнения по соотношению сторон или размеру.
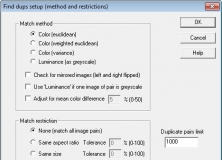
Эти настройки делают DupDetector более гибким, чем простой поиск файлов с одинаковым размером. Пользователь может адаптировать поиск под тип коллекции.
Color (euclidean)
Метод Color (euclidean) подходит для поиска похожих изображений по цветовой информации. Его логично использовать для обычных цветных фотографий, где важны оттенки, насыщенность и общая цветовая структура кадра. Если две фотографии практически одинаковы, но одна слегка пересохранена, такой метод обычно помогает обнаружить совпадение.
Color (weighted euclidean)
Color (weighted euclidean) использует взвешенный цветовой подход. Он полезен, когда важно более аккуратно учитывать цветовые различия. Для пользователя это не требует математического анализа: достаточно понимать, что это еще один вариант цветового сравнения, который может давать другие результаты на сложных коллекциях.
Color (variance)
Color (variance) ориентирован на различия в цветовой структуре. Его можно пробовать, если обычный цветовой метод либо пропускает похожие изображения, либо дает слишком много лишних совпадений. В больших архивах один метод может лучше работать на фотографиях, другой — на сканах, иллюстрациях или обработанных изображениях.
Luminance (as greyscale)
Luminance (as greyscale) полезен, когда цвет не должен быть главным критерием. Например, если в коллекции есть цветная фотография и ее черно-белый вариант, чисто цветовой анализ может считать их более разными, чем они выглядят для человека. Яркостное сравнение помогает искать совпадения по светлоте и структуре изображения.
Check for mirrored images
Параметр Check for mirrored images (left and right flipped) нужен для поиска зеркально отраженных картинок. Это полезно в коллекциях иллюстраций, обоев, сканов или изображений, которые могли быть сохранены после горизонтального отражения. При обычном сравнении зеркальная копия может не совпадать с оригиналом, хотя для пользователя это почти тот же файл.
Match restriction
Блок Match restriction ограничивает пары, которые программа будет сравнивать. Доступны варианты вроде сравнения всех пар, ограничения по одинаковому aspect ratio или одинаковому размеру. Это важная защита от лишнего шума в результатах.
Например, если пользователь ищет точные дубликаты фотографий, логично ограничить сравнение одинаковым соотношением сторон или размером. Если же нужно найти уменьшенные версии, слишком строгие ограничения могут помешать. Поэтому настройки выбираются под задачу.
Options: режимы удаления, отображение и поведение программы
Меню Options в DupDetector содержит параметры, которые влияют на удобство просмотра и удаления. В программе есть ручное удаление, полуавтоматический и автоматический режимы, настройки отображения размеров файлов, напоминания о сохранении data file, сортировка по проценту совпадения, параметры folder preferences и другие рабочие опции.
На практике наиболее важны следующие настройки:
| Настройка | Практический смысл |
|---|---|
| Manual delete | Пользователь сам удаляет выбранный файл |
| Semi-auto delete | Удаление ускоряется, но контроль частично остается у пользователя |
| Automatic delete | Наиболее рискованный режим, требует осторожности |
| Show file sizes | Показывает размер файлов при сравнении |
| Beep on deleting file | Звуковой сигнал при удалении |
| Remind to save datafile | Напоминание о сохранении файла данных |
| No sort on % match | Без сортировки по проценту совпадения |
| Sort high-to-low % match | Сначала самые похожие пары |
| Sort low-to-high % match | Сначала менее похожие пары |
| Folder preferences | Настройки папок, используемых программой |
Для большинства пользователей оптимален Manual delete. Он медленнее, но безопаснее. При поиске дубликатов изображений скорость удаления не должна быть главным критерием. Цена ошибки слишком высока: можно удалить оригинал, оставить сжатую копию или потерять обработанный вариант.
Show file sizes лучше держать включенным. Размер файла не всегда равен качеству, но он помогает принимать решение. Если две картинки выглядят одинаково, а одна весит значительно меньше, это может быть уменьшенная или сильнее сжатая копия. Если одна имеет большее разрешение и больший размер, часто разумнее оставить ее.
Сортировка по проценту совпадения помогает выстроить удобный порядок просмотра. При Sort high-to-low % match сначала идут самые очевидные дубликаты. Это хороший вариант для первой чистки: пользователь быстро удаляет стопроцентные или почти стопроцентные повторы, а спорные пары оставляет на потом.
Folder Preferences и рабочие папки
В DupDetector есть окно Default folder locations, где задаются папки для data files, log files и image list. Это не самая заметная часть программы, но она важна, если утилита используется регулярно.
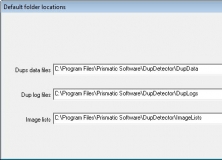
Такие параметры удобны, если пользователь проверяет разные фотоархивы и хочет хранить служебные файлы программы отдельно от самих изображений. Например, data files можно держать в отдельной папке DupData, журналы — в DupLogs, а списки изображений — в ImageLists.
Это снижает путаницу. Если служебные файлы лежат рядом с фотографиями, пользователь может не сразу понять, что относится к архиву, а что создано самой программой. Отдельные рабочие папки делают процесс чище.
Как найти дубликаты фотографий в DupDetector
Ниже — практический сценарий работы с DupDetector. Он подходит для обычной задачи: проверить папку с фотографиями и удалить очевидные дубликаты.
Шаг 1. Подготовить папку
Перед запуском стоит выбрать конкретную папку, а не весь диск. Например, лучше начать с D:\Photos\Camera Imports, а не с корня диска D:\. Это уменьшит количество лишних совпадений и ускорит проверку.
Хороший порядок действий:
-
выбрать одну папку с фотографиями;
-
убедиться, что в ней нет важных рабочих проектов, где копии нужны намеренно;
-
при необходимости создать резервную копию;
-
решить, нужно ли проверять подпапки;
-
заранее определить, какие файлы считаются лишними.
DupDetector помогает найти дубли, но не знает контекст пользователя. Для программы две картинки могут быть совпадением, а для человека одна из них — исходник, другая — подготовленный файл для печати или сайта.
Шаг 2. Открыть вкладку Get data
После запуска нужно перейти во вкладку Get data. Здесь находится блок Primary data file. Для обычной проверки одной папки используется именно он.
Далее пользователь нажимает Build. Эта кнопка запускает создание файла данных по выбранной папке. После выбора источника программа начинает читать изображения и готовить информацию для последующего сравнения.
Шаг 3. Выбрать папку с изображениями
При выборе папки важно понимать, попадут ли в анализ подпапки. Если фотографии разложены по годам, датам или событиям, рекурсивный поиск нужен. Например:
D:\PhotosD:\Photos\2020D:\Photos\2021D:\Photos\2022D:\Photos\EditedD:\Photos\For printЕсли проверить только верхнюю папку без подпапок, DupDetector может не увидеть большую часть архива. Если включить подпапки, программа сравнит изображения глубже по структуре.
Шаг 4. Дождаться построения data file
Построение data file может занять время. Скорость зависит от количества изображений, их размера и носителя. Папка с несколькими сотнями JPEG обычно обрабатывается гораздо быстрее, чем архив с десятками тысяч фотографий на внешнем диске.
На этом этапе не стоит прерывать процесс без необходимости. Программа собирает данные, которые затем будут использоваться во вкладке Find dups.
Шаг 5. Перейти во вкладку Method
Во вкладке Method нужно выбрать сценарий сравнения. Для чистки одной папки подходит:
Compare all images within primary datafile (one folder or image list)Этот режим ищет совпадения внутри выбранной базы. Если задача другая — например, сравнить папку Photos с папкой Backup Photos, используется режим сравнения двух data files.
Шаг 6. Перейти во вкладку Find dups
Во вкладке Find dups задается диапазон совпадения. Для первой проверки лучше начинать со строгого диапазона, например около 98–100%. Такой подход уменьшает количество ложных результатов и позволяет сначала удалить самые очевидные дубликаты.
После первой чистки можно повторить поиск с более мягким порогом, если нужно найти обработанные, уменьшенные или слегка измененные копии.
Шаг 7. Выбрать метод сравнения
Через настройки поиска можно выбрать color или luminance method. Для обычных цветных фотографий обычно логично начинать с цветового сравнения. Если нужно искать черно-белые варианты цветных снимков, полезно попробовать яркостный метод.
Для зеркальных копий включается проверка mirrored images. Но эту опцию не стоит включать без необходимости: чем больше условий сравнения, тем больше потенциальных совпадений придется просматривать.
Шаг 8. Запустить поиск
После настройки диапазона и метода нажимается кнопка поиска во вкладке Find dups. DupDetector анализирует подготовленный data file и формирует список совпадений.
Если коллекция большая, поиск может идти долго. Это нормально для программы, которая работает с пиксельными данными изображений. Особенно медленно могут обрабатываться большие изображения, сканы и папки на внешних дисках.
Шаг 9. Открыть View dups
Когда поиск завершен, результаты просматриваются во вкладке View dups. Здесь программа показывает найденные пары. В верхней области отображается текстовая информация: номер совпадения, пути к файлам, процент совпадения и другие данные. В нижней области находятся две миниатюры.
Шаг 10. Сравнить изображения вручную
Перед удалением нужно посмотреть на обе картинки. Важные вопросы:
-
это действительно один и тот же кадр;
-
есть ли различия в кадрировании;
-
есть ли дата, подпись или рамка;
-
какое изображение больше по разрешению;
-
какой файл находится в более важной папке;
-
не является ли один файл специально подготовленной копией;
-
не относится ли файл к рабочему проекту.
Если обе картинки одинаковые, можно удалить лишнюю. Если есть сомнения, лучше не удалять сразу.
Шаг 11. Удалить ненужную копию кнопкой Delete
Под каждой миниатюрой есть кнопка Delete. Она удаляет именно тот файл, под которым находится. Это удобно, потому что не нужно переходить в проводник и искать файл вручную.
Но здесь легко ошибиться: если удалить не ту копию, программа не сможет понять, что пользователь хотел оставить оригинал. Поэтому перед нажатием Delete нужно проверить путь, имя, размер и визуальное качество.
Шаг 12. Пройти результаты до конца
Кнопки Back и Next позволяют перемещаться по найденным парам. Лучше не пытаться удалить все за один проход. Оптимальная тактика:
-
Сначала удалить только очевидные 100% совпадения.
-
Затем пройти пары с очень высоким процентом.
-
Потом отдельно решить, нужны ли похожие, но не идентичные изображения.
-
Спорные варианты оставить.
Такой подход медленнее автоматической чистки, но значительно безопаснее.
Безопасное удаление дубликатов
Поиск дубликатов фото — операция с риском. Программа может найти похожие изображения правильно, но решение об удалении остается за пользователем. Особенно осторожно нужно работать с папками, где есть исходники, обработанные версии, фотографии для печати, веб-копии и проектные файлы.
Правила безопасной работы:
-
не начинать с полного диска;
-
не запускать автоматическое удаление на незнакомой коллекции;
-
сначала проверить небольшую папку;
-
перед массовой чисткой сделать резервную копию;
-
не удалять файлы только по имени;
-
сравнивать разрешение и размер;
-
смотреть путь к файлу;
-
учитывать назначение папки;
-
не удалять похожие, но не одинаковые кадры без причины;
-
спорные пары пропускать.
Особенно важно не путать дубликаты и версии. Например, в папке могут быть:
IMG_2027.JPGIMG_2027_edit.JPGIMG_2027_web.JPGIMG_2027_print.JPGДля DupDetector эти файлы могут оказаться похожими. Но для пользователя это четыре разных версии с разным назначением. Оригинал нужен для хранения, edit — для обработки, web — для сайта, print — для печати. Удалять их как мусор нельзя.
DupDetector хорошо подходит для поиска, но не должен заменять здравый смысл. Его результат — это список кандидатов на удаление, а не окончательный приговор.
Поддерживаемые изображения и ограничения
DupDetector работает с изображениями и читает несколько типов графических файлов из папки, подпапок или image list. В программе есть поддержка распространенных форматов старых фотоархивов, включая JPEG-варианты, TIFF-варианты и GIF.
При этом DupDetector не стоит воспринимать как современный конвертер или универсальный просмотрщик всех новых графических форматов. Его сильная сторона — поиск дубликатов в классических коллекциях изображений. Если архив состоит в основном из старых JPEG, TIFF, GIF и похожих файлов, программа попадает в свою задачу. Если коллекция построена вокруг современных форматов, RAW-процессинга, облачных медиатек или файлов из смартфонов с нестандартными расширениями, лучше заранее проверять работу на небольшой выборке.
Практический вывод простой: DupDetector лучше использовать для тех папок, где изображения открываются программой и корректно попадают в data file. Если часть файлов не участвует в анализе, программа не сможет найти их дубликаты.
Производительность на больших коллекциях
DupDetector читает пиксельные данные изображений, поэтому скорость работы зависит не только от количества файлов, но и от размера картинок. Большие коллекции и крупные файлы замедляют обработку. Это ожидаемо: программа не просто сравнивает имена, а анализирует содержимое изображений.
На практике на скорость влияют:
-
количество изображений;
-
разрешение фото;
-
размер файлов;
-
тип носителя;
-
глубина подпапок;
-
выбранный метод сравнения;
-
включение проверки зеркальных изображений;
-
диапазон совпадений;
-
состояние самой папки.
Если в архиве несколько тысяч фотографий, лучше не начинать с полного набора. Рациональнее проверять по частям:
D:\Photos\2019D:\Photos\2020D:\Photos\2021D:\Photos\2022D:\Photos\Phone importsD:\Photos\Camera importsТак результаты будут понятнее, а ошибки менее вероятны. Кроме того, пользователь быстрее увидит, какие настройки дают хороший результат именно на его коллекции.
Если запустить DupDetector на огромном архиве с подпапками, программа может долго строить data file и затем долго искать пары. Это не обязательно признак сбоя. Просто визуальное сравнение изображений тяжелее, чем поиск файлов по имени.
Практический пример: очистка папки с импортами камеры
Представим типичную ситуацию. На диске есть папка:
D:\Photos\Camera ImportsВнутри лежат подпапки:
D:\Photos\Camera Imports\Import 1D:\Photos\Camera Imports\Import 2D:\Photos\Camera Imports\OldD:\Photos\Camera Imports\For sortingD:\Photos\Camera Imports\EditedПроблема в том, что фотографии несколько раз копировались с карты памяти. Часть файлов имеет исходные имена вроде IMG_0001.JPG, часть была переименована, часть уменьшена, часть пересохранена после обработки. Нужно найти повторы.
Правильный порядок работы в DupDetector:
-
Открыть программу.
-
Перейти во вкладку Get data.
-
В Primary data file нажать Build.
-
Выбрать папку
D:\Photos\Camera Imports. -
Включить обработку подпапок, если фото лежат внутри них.
-
Дождаться построения data file.
-
Перейти во вкладку Method.
-
Выбрать сравнение всех изображений внутри primary data file.
-
Перейти во вкладку Find dups.
-
Установить строгий диапазон совпадения.
-
Запустить поиск.
-
Открыть View dups.
-
Сначала удалить только очевидные пары.
-
Повторить поиск с более мягким диапазоном, если нужно найти обработанные копии.
В таком сценарии DupDetector работает как инструмент первичной уборки. Сначала он убирает явный мусор: одинаковые фотографии, повторные импорты, копии с другими именами. Затем пользователь может отдельно рассмотреть похожие, но не полностью одинаковые изображения.
Практический пример: сравнение основной папки и резервной копии
Другой сценарий — сравнение двух наборов. Например:
D:\PhotosE:\Backup\PhotosПользователь хочет понять, какие изображения из резервной папки уже есть в основной, но не хочет искать дубликаты внутри каждой папки отдельно. Для этого в DupDetector используется сравнение между двумя data files.
Порядок действий:
-
Построить Primary data file для
D:\Photos. -
Построить Secondary data file для
E:\Backup\Photos. -
Во вкладке Method выбрать сравнение между двумя data files.
-
Во вкладке Find dups задать диапазон совпадения.
-
Запустить поиск.
-
Во вкладке View dups просмотреть пары.
Этот режим удобен, если нужно объединить архивы. Например, есть старая резервная копия и новый основной каталог. DupDetector помогает увидеть пересечения и не переносить одно и то же изображение несколько раз.
Но удалять файлы из резервной копии нужно осторожно. Резервный архив может быть единственным местом, где сохранилась более качественная версия снимка. Поэтому перед удалением стоит смотреть размер, разрешение и путь.
Практический пример: поиск копий одного изображения
Третий сценарий — поиск дублей одной конкретной картинки. Например, есть файл:
D:\Temp\sunset.jpgНужно найти, есть ли он в большом архиве:
D:\PhotosДля этого используется режим:
Compare single image to primary datafileСначала строится primary data file по архиву D:\Photos, затем выбирается одно изображение для сравнения. DupDetector проверяет, есть ли в базе совпадающие или похожие картинки.
Такой сценарий полезен, если пользователь нашел отдельный файл на рабочем столе, во вложениях, в папке загрузок или на флешке и хочет понять, нужен ли он, или такая фотография уже есть в основном архиве.
Как выбирать, какую копию оставить
DupDetector показывает совпадения, но не всегда может решить за пользователя, какой файл лучше. При выборе нужно смотреть не только на миниатюру.
Основные критерии:
| Критерий | Что означает |
|---|---|
| Разрешение | Больше пикселей часто означает более качественный исходник |
| Размер файла | Больший размер может указывать на меньшее сжатие, но не всегда |
| Путь | Файл в основной папке обычно важнее копии из временной папки |
| Имя | Осмысленное имя может быть полезнее случайного |
| Наличие обработки | Иногда обработанный вариант нужно сохранить вместе с оригиналом |
| Дата или подпись на фото | Версия с датой может быть отдельным нужным вариантом |
| Кадрирование | Похожая картинка может быть другой версией кадра |
| Назначение папки | Файл из папки проекта может использоваться в другом месте |
Нельзя механически оставлять самый большой файл. Иногда большая копия может быть не оригиналом, а пересохраненным изображением с меньшим качеством. Нельзя механически оставлять файл с самым коротким именем. Иногда исходник лежит в папке камеры, а коротко названная копия — временный экспорт.
Самый надежный подход — смотреть на путь и контекст. Если один файл находится в D:\Photos\Originals, а второй в D:\Temp, обычно логично оставить первый. Если один в D:\Photos\Edited, а второй в D:\Photos\Originals, возможно, нужны оба.
Типичные ошибки при работе с DupDetector
Слишком широкий первый запуск
Проверять сразу весь диск — плохая идея. В результат попадут системные изображения, кэши, иконки, временные файлы, картинки из программ и документы с графикой. Это создаст шум и увеличит риск удаления нужных файлов.
Лучше начинать с конкретной папки с фотографиями.
Слишком низкий порог совпадения
Если поставить слишком мягкий диапазон, DupDetector начнет находить визуально похожие, но разные изображения. Например, серии кадров, похожие пейзажи, фотографии одного объекта с разных ракурсов. Для коллекции семейных фото это опасно: можно принять разные снимки за дубликаты.
Удаление без просмотра
DupDetector показывает миниатюры не случайно. Просмотр — обязательная часть работы. Даже при высоком проценте совпадения нужно убедиться, что файлы действительно взаимозаменяемы.
Игнорирование путей
Путь к файлу часто важнее имени. Одинаковая картинка в папке Originals и в папке Website может выполнять разные роли. Если удалить файл из рабочей структуры сайта или проекта, можно нарушить связи.
Удаление обработанных вариантов
Черно-белая версия, кадрированный вариант, изображение с подписью или уменьшенная копия для публикации могут быть не мусором, а рабочими версиями. DupDetector может найти их как похожие, но решение остается за человеком.
Работа без резервной копии
Перед большой чисткой фотоархива резервная копия обязательна. Ошибка при удалении изображений часто обнаруживается не сразу. Пользователь может понять, что удалил нужный вариант, только через недели или месяцы.
Сильные стороны DupDetector
Главная сильная сторона DupDetector — узкая специализация. Программа не распыляется на десятки функций. Она ищет дубликаты изображений и похожие картинки. Для пользователя, которому нужно именно это, такая прямолинейность удобна.
Плюсы программы:
-
поиск одинаковых и почти одинаковых изображений;
-
сравнение по содержимому, а не только по имени;
-
работа с папками и подпапками;
-
возможность сравнивать два набора изображений;
-
возможность сравнить одно изображение с базой;
-
выбор color и luminance методов;
-
настройка процента совпадения;
-
проверка mirrored images;
-
просмотр двух миниатюр перед удалением;
-
отображение путей к файлам;
-
ручное удаление конкретной копии;
-
наличие настроек сортировки и отображения.
DupDetector особенно хорош там, где нужно найти старые повторы в локальном архиве. Он не перегружает пользователя каталогизацией, альбомами, облачными функциями или учетными записями. Открыл папку, построил базу, нашел пары, проверил, удалил лишнее — вся логика укладывается в несколько вкладок.
Слабые стороны DupDetector
Слабые стороны DupDetector связаны в первую очередь с возрастом интерфейса и узостью программы. Это не современное приложение с автоматическим выбором лучших кадров, не фотоорганайзер и не универсальный очиститель диска.
Минусы:
-
устаревший интерфейс;
-
непривычная логика data file для новичков;
-
ручная проверка обязательна;
-
автоматическое удаление требует осторожности;
-
большие архивы могут обрабатываться медленно;
-
программа ориентирована именно на изображения;
-
нет современной визуальной организации фотоархива;
-
нет интеллектуального выбора лучшей версии;
-
нет полноценной системы управления альбомами;
-
спорные совпадения приходится анализировать вручную.
Сама по себе простота интерфейса не является проблемой, если пользователь понимает рабочую логику. Но тем, кто привык к современным приложениям с кнопкой найти и удалить все лишнее, DupDetector может показаться сухим и техническим.
Сравнение с аналогами
DupDetector стоит сравнивать не с абстрактными чистильщиками ПК, а с программами, которые реально решают похожую задачу: поиск дубликатов фотографий и похожих изображений.
| Программа | Основной профиль | Сильные стороны | Где DupDetector проще | Где DupDetector уступает |
|---|---|---|---|---|
| DupDetector | Поиск дубликатов и near-duplicate images | Data file workflow, color/luminance методы, ручной просмотр пар | Узкая логика, понятный контроль удаления | Устаревший интерфейс, меньше современных удобств |
| Awesome Duplicate Photo Finder | Поиск одинаковых и похожих фото | Очень простой сценарий с добавлением папок и кнопкой Start, поддержка JPG, BMP, GIF, PNG, TIFF, CR2 | DupDetector дает более технический выбор метода сравнения | Awesome Duplicate Photo Finder проще для новичка |
| AntiDupl.NET | Поиск похожих изображений и дефектов | Много форматов, сравнение по содержимому, поиск похожих изображений и некоторых дефектов | DupDetector визуально проще и старомоднее | AntiDupl.NET функционально шире и лучше подходит для сложных коллекций |
| dupeGuru | Универсальный поиск дубликатов файлов | Работает с файлами шире, поддерживает разные режимы сканирования, кроссплатформенный профиль | DupDetector сфокусирован именно на изображениях | dupeGuru универсальнее, но не такой специализированный как old-school image duplicate finder |
| VisiPics | Поиск дубликатов изображений | Фильтры Strict, Basic, Loose и Auto-Select | DupDetector дает отдельную логику data files и сравнения наборов | VisiPics удобнее для тех, кто хочет быстро менять строгость поиска |
Awesome Duplicate Photo Finder
Awesome Duplicate Photo Finder проще воспринимается новичком. Его типичный сценарий — добавить папки и нажать Start. Он подходит пользователям, которым нужен максимально прямой поиск похожих фотографий без промежуточной логики primary data file.
DupDetector выглядит менее дружелюбно, но дает более явное разделение этапов. Пользователь отдельно готовит данные, отдельно выбирает метод, отдельно запускает поиск, отдельно просматривает результаты. Для тех, кто любит контролируемый процесс, это преимущество.
AntiDupl.NET
AntiDupl.NET — более мощный инструмент для похожих изображений. Он поддерживает много графических форматов и ориентирован на автоматизацию поиска идентичных и похожих картинок по содержимому. Также он может находить изображения с некоторыми типами дефектов.
DupDetector проще и компактнее по восприятию. Он не выглядит как большой комплекс для анализа коллекции. Его удобно использовать, когда нужна старая, понятная, локальная программа для поиска дублей без лишнего окружения.
dupeGuru
dupeGuru — более универсальная программа. Она ищет дубликаты файлов, может работать с именами и содержимым, а не ограничивается только изображениями. Поэтому dupeGuru лучше подходит, если нужно проверить разные типы файлов: документы, музыку, архивы, изображения.
DupDetector выигрывает там, где задача уже: найти дубликаты изображений по визуальному сходству. Он не универсален, зато его интерфейс и настройки сосредоточены именно на картинках.
VisiPics
VisiPics близок по назначению: это программа для поиска похожих изображений. Ее фильтры Strict, Basic и Loose удобны для быстрого изменения строгости поиска. Также у VisiPics есть идея автоматического выбора кандидатов на удаление.
DupDetector отличается тем, что делает акцент на data file workflow и отдельных методах сравнения. Он ощущается более техническим и менее мастеровым, но при этом позволяет аккуратно выстроить проверку одной базы, двух баз или одного изображения против базы.
Кому подойдет DupDetector
DupDetector подойдет пользователям, у которых есть локальные папки с изображениями и желание вручную контролировать удаление.
Хорошие сценарии:
-
старый фотоархив на Windows-компьютере;
-
папки с повторными импортами камеры;
-
коллекции JPEG и TIFF;
-
архивы изображений с разными именами файлов;
-
проверка резервных папок;
-
поиск похожих картинок после обработки;
-
ручная чистка без облачных сервисов;
-
работа с папками и подпапками.
Программа особенно полезна людям, которые не доверяют полностью автоматической очистке. DupDetector показывает пары и дает возможность принять решение вручную. Это правильный подход для фотографий, потому что ценность файла не всегда определяется тем, похож он на другой или нет.
Кому DupDetector не подойдет
DupDetector не лучший выбор для пользователей, которым нужна современная медиатека, автоматическая сортировка фото, распознавание лиц, облачная синхронизация или поддержка всех новых форматов. Он также не подойдет тем, кто хочет нажать одну кнопку и удалить все без просмотра.
Плохие сценарии:
-
полная автоматическая чистка без контроля;
-
работа с огромной современной медиатекой без разделения на папки;
-
поиск дублей среди документов, видео, музыки и архивов;
-
организация фото по людям, датам и геолокации;
-
замена профессионального фотоорганайзера;
-
массовое удаление без резервной копии.
DupDetector — это не умный ассистент, который сам выберет лучшие фотографии. Он находит совпадения. Выбор остается за пользователем.
Рекомендованные настройки для разных задач
| Задача | Метод | Диапазон совпадения | Дополнительные настройки |
|---|---|---|---|
| Найти точные копии фото | Color | Очень высокий | Сортировка high-to-low |
| Найти пересохраненные JPEG | Color | Высокий | Смотреть размер и путь |
| Найти черно-белые версии | Luminance | Высокий или умеренно высокий | Проверять визуально |
| Найти зеркальные копии | Color или Luminance | Высокий | Включить mirrored images |
| Сравнить две папки | Between two datafiles | Высокий | Не удалять без проверки |
| Проверить одно изображение | Single image to primary datafile | Высокий | Смотреть все найденные пары |
| Разобрать старый фотоархив | Color сначала, затем Luminance | Сначала строгий, затем мягче | Работать по папкам |
Для первой проверки лучше не снижать порог слишком сильно. Начинать стоит со строгих совпадений. Это даст меньше результатов, но они будут надежнее. После удаления очевидных дублей можно провести второй проход.
Как DupDetector помогает освободить место
Дубликаты изображений занимают место не так заметно, как видео, но в больших архивах потери становятся существенными. Если одна и та же фотография хранится в нескольких папках, а таких фотографий тысячи, общий объем лишних файлов может быть заметным.
DupDetector помогает освободить место за счет поиска:
-
повторных импортов;
-
одинаковых фотографий с разными именами;
-
копий после пересохранения;
-
уменьшенных вариантов;
-
обработанных дубликатов;
-
изображений в резервных папках;
-
старых копий из временных каталогов.
Но освобождение места не должно быть единственной целью. Иногда копия занимает мало места, но имеет отдельное назначение. Например, уменьшенная версия может использоваться на сайте, а оригинал храниться в архиве. Удаление такой копии освободит немного места, но создаст проблему в рабочем процессе.
Поэтому DupDetector лучше использовать не как выжать максимум мегабайт, а как инструмент наведения порядка.
Работа с подпапками
Одна из важных возможностей DupDetector — поиск по folder structures, то есть по папкам и подпапкам. Это необходимо для реальных фотоархивов, потому что изображения редко лежат в одной плоской папке. Обычно они распределены по годам, устройствам, событиям или этапам обработки.
Пример структуры:
D:\PhotoArchive├── 2018├── 2019├── 2020├── Phone├── Camera├── Edited├── Web└── BackupЕсли программа проверит только верхнюю папку, она почти ничего не найдет. Если включить подпапки, DupDetector сможет сравнить изображения глубже. Это особенно важно, когда одна и та же фотография находится, например, в Camera, Edited и Backup.
Но поиск по подпапкам повышает риск ложных решений. Файл в папке Web может быть нужен именно как веб-версия, а файл в Edited — как результат обработки. Поэтому при работе с подпапками нужно особенно внимательно смотреть путь.
Работа с image list
DupDetector может использовать image list — список изображений. Это полезно, когда нужно проверять не всю папку, а заранее выбранный набор файлов. Например, пользователь может подготовить список изображений из разных мест и сравнить только их.
Такой подход удобен в более аккуратных сценариях:
-
проверить выборку из нескольких папок;
-
исключить системные и служебные изображения;
-
работать только с фотографиями определенного проекта;
-
сравнить файлы, отобранные вручную;
-
не трогать весь архив.
Image list делает работу более контролируемой. Вместо того чтобы запускать поиск по большой папке, пользователь сам определяет, какие изображения участвуют в анализе.
Журналирование и контроль действий
DupDetector умеет сохранять log file. Для обычной небольшой чистки это не всегда нужно, но при работе с большим архивом журнал полезен. Он помогает понимать, какие совпадения были найдены и какие действия выполнялись.
Журнал особенно уместен, если:
-
обрабатывается большой фотоархив;
-
удаление идет в несколько этапов;
-
программа используется на рабочей коллекции;
-
нужно сохранить историю чистки;
-
несколько папок проверяются последовательно.
Журнал не заменяет резервную копию, но добавляет прозрачности. Если после чистки возник вопрос, какие пары находились, log file может помочь восстановить ход работы.
Почему DupDetector не стоит путать с обычным поиском одинаковых файлов
Обычный duplicate file finder часто ищет файлы по хэшу, размеру, имени или бинарному совпадению. Это хорошо работает для полностью одинаковых файлов. Если два JPEG-файла совпадают байт в байт, такой инструмент найдет их точно.
Но изображения часто отличаются технически, оставаясь одинаковыми визуально. Примеры:
-
файл пересохранен с другим качеством JPEG;
-
изображение уменьшено;
-
добавлена дата;
-
изменена яркость;
-
изменена насыщенность;
-
картинка конвертирована в другой формат;
-
файл переименован;
-
изображение зеркально отражено.
Обычный поиск одинаковых файлов может пропустить такие случаи. DupDetector ориентирован именно на изображения, поэтому его смысл — найти визуальные совпадения, а не только бинарные копии.
Почему ручной просмотр важнее автоматического удаления
В DupDetector есть режимы, которые ускоряют удаление, но безопаснее работать вручную. Причина проста: похожесть изображения не всегда означает ненужность одного из файлов.
Фотографии могут быть похожими, если:
-
сняты серией;
-
отличаются фокусом;
-
отличаются выражением лица;
-
имеют разные настройки обработки;
-
одна версия кадрирована;
-
одна версия подготовлена для печати;
-
одна версия содержит текст или дату;
-
одна версия нужна для проекта.
Автоматическое удаление таких файлов может привести к потере нужных вариантов. Особенно опасно это для семейных фото, творческих проектов и рабочих каталогов.
Оптимальный подход:
-
Автоматизировать только поиск.
-
Просматривать найденные пары вручную.
-
Удалять только очевидные копии.
-
Спорные совпадения оставлять.
-
Повторять проверку по папкам.
DupDetector хорошо вписывается именно в такой аккуратный сценарий.
Итоговая оценка
DupDetector — специализированная программа для поиска дубликатов изображений и визуально похожих фотографий. Ее сильная сторона — конкретный рабочий процесс: выбрать метод, построить data file, найти совпадения, просмотреть пары и удалить ненужную копию вручную. Она не пытается быть универсальным менеджером файлов или современной медиатекой, и именно поэтому остается понятной в своей узкой задаче.
Лучше всего DupDetector проявляет себя в старых локальных фотоархивах, папках с повторными импортами, коллекциях JPEG/TIFF/GIF и наборах изображений, где одинаковые картинки годами копировались под разными именами. Программа помогает найти то, что обычный поиск по имени или размеру не видит: похожие фото, пересохраненные варианты, измененные копии и near-duplicate images.
Основной недостаток — необходимость внимательной ручной проверки. Но для фотографий это не минус, а нормальная цена безопасной работы. Любая программа может найти похожие изображения, но только пользователь знает, какая версия является оригиналом, какая нужна для печати, какая используется в проекте, а какая действительно лишняя.
DupDetector стоит использовать как аккуратный инструмент для контролируемой чистки: сначала строгий поиск, затем просмотр пар, затем ручное удаление очевидных дублей. В таком сценарии программа выполняет свою работу точно и предсказуемо.