
Capture2Text — это узкоспециализированная OCR-программа для Windows, заточенная под одну задачу: быстрое извлечение текста из любой области экрана без ручного перепечатывания. Она работает как portable-утилита, запускается без установки, живёт в системном трее и практически всё делает через горячие клавиши. В типичном сценарии пользователь наводит курсор на нужный фрагмент интерфейса, скриншота, PDF, презентации, видео или изображения, выделяет область и сразу получает распознанный текст в буфере обмена. В этом и заключается суть Capture2Text: это не тяжёлый OCR-пакет для сканов и не редактор документов, а быстрый инструмент для распознавания текста с экрана Windows здесь и сейчас.
Главная ценность программы — скорость. Capture2Text избавляет от промежуточных действий: не нужно сперва сохранять картинку, потом открывать её в отдельном OCR-софте и только после этого копировать результат. Программа ориентирована именно на копирование невыделяемого текста: надписей в окнах программ, элементов интерфейса, фрагментов image-based PDF, субтитров, текста на скриншотах, вставок в комиксах и манге. При этом Capture2Text не ограничивается одним базовым режимом: в ней есть стандартный OCR-захват области, захват ближайшей строки, захват строки от конкретного символа вперёд, распознавание текста внутри speech bubble, перевод, text-to-speech и CLI для автоматизации.
Скачать Capture2Text
- Редактирование PDF
- Русский интерфейс
- Просто для новичков
- Средний интерфейс
- Ограниченные функции
- Нет поддержки форматов
Что представляет собой Capture2Text
По своей логике Capture2Text устроена предельно просто. После запуска она сворачивается в область уведомлений и открывается через иконку в трее. Оттуда доступны ключевые команды: Settings..., Save to Clipboard, Show Popup Window, OCR Language, Text Orientation, Help, Exit. Это меню показывает философию программы лучше любого описания: Capture2Text не перегружает пользователя отдельным главным окном, а держит управление рядом с системными часами, чтобы OCR с экрана был всегда под рукой и запускался в одно действие.
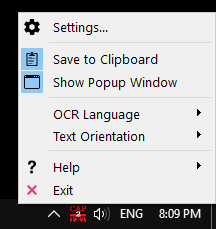
Программа запускается без установки. После распаковки достаточно открыть Capture2Text.exe, и значок появится в трее. При обычном режиме настройки сохраняются в профиле пользователя, а при запуске с параметром --portable — рядом с исполняемым файлом. Это делает Capture2Text удобной не только для постоянной работы на одном ПК, но и для флешки, тестовой среды, временного рабочего профиля и любых ситуаций, где нужна portable OCR для Windows без следов в системе за пределами папки программы.
Поддержка языков в Capture2Text — сильная сторона программы. По умолчанию доступны English, French, German, Japanese, Korean, Russian и Spanish, а через tessdata можно подключать множество дополнительных языков, включая китайский, украинский, арабский, польский, турецкий, вьетнамский и другие. Для повседневной работы это означает простую схему: для английских интерфейсов можно держать один язык, для русскоязычных документов — другой, для манги и вертикального текста — японский или китайский с корректной ориентацией.
Где Capture2Text действительно полезна
Capture2Text особенно хороша там, где текст визуально есть, а выделить его стандартным способом нельзя. Классический пример — старая программа с нестандартным интерфейсом, диалоговое окно без нормального копирования, PDF-скан, кадр видео, субтитры, защищённый просмотрщик, изображение с текстом в браузере, всплывающая ошибка, строка меню, подпись на кнопке или всплывающий блок с данными. В таких сценариях программа не пытается заменить полноценную систему документооборота — она решает конкретную задачу за секунды: сделать OCR по скриншоту и положить результат в буфер обмена.
На практике Capture2Text полезна офисным сотрудникам, редакторам, тестировщикам, техподдержке, переводчикам, студентам, тем, кто работает с иностранными интерфейсами, а также пользователям, которые регулярно вытаскивают текст из манги, комиксов, субтитров и старых приложений. Важный момент здесь в том, что программа не навязывает сложный процесс. Она даёт несколько быстрых режимов OCR-захвата и позволяет выбрать тот, который подходит под конкретный тип текста: обычный прямоугольник, одна строка, строка от символа вперёд или bubble OCR.
Интерфейс Capture2Text
Интерфейс у программы минималистичный и полностью подчинён задаче быстрого распознавания. Основной центр управления — иконка в системном трее. Именно оттуда выбирается текущий язык через OCR Language, ориентация текста через Text Orientation, открываются Settings... и включается Show Popup Window. Такой подход удачен в том смысле, что программа не занимает место на рабочем столе и не требует отдельного окна в фоне. Она активируется только тогда, когда пользователь действительно хочет снять текст с экрана.
Popup-окно результата тоже устроено прагматично. В нём отображается распознанный текст, есть флажок Topmost, ссылка font и кнопка OK. Когда включён text-to-speech и для языка выбрана голосовая модель, в этом же окне появляется кнопка Say. Popup нужен не ради красоты, а ради контроля: можно сразу увидеть, насколько удачно сработало распознавание текста с изображения, нужно ли повторить захват, исправить язык OCR или скорректировать выделение.
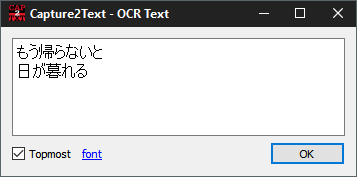
Если text-to-speech активирован, popup меняется не косметически, а функционально: кнопка Say позволяет сразу озвучить распознанный фрагмент. Для языкового обучения и проверки коротких отрывков это полезная деталь, потому что Capture2Text в таком режиме работает не только как OCR с экрана, но и как маленький инструмент проверки произношения или слухового восприятия.
Первый запуск и базовый сценарий работы
Логика первого использования Capture2Text очень прямая. Пользователь запускает программу, находит её значок в трее, выбирает нужный язык OCR, затем нажимает горячую клавишу захвата и выделяет нужный участок экрана. После подтверждения захвата распознанный текст отправляется в clipboard, а при включённом popup сразу показывается в отдельном окне. Это ровно тот сценарий, ради которого программу и используют чаще всего.
Сильная сторона Capture2Text в том, что первый сценарий не ломается от излишней усложнённости. Никаких обязательных профилей, проектов, задач, библиотек документов или мастеров импорта здесь нет. Для OCR с экрана Windows это правильное решение: софт должен срабатывать мгновенно, а не разворачивать отдельную экосистему вокруг простой операции копирования текста.
Ниже — базовые горячие клавиши, с которыми чаще всего работают в Capture2Text.
| Действие | Горячая клавиша по умолчанию |
|---|---|
| Start OCR Capture | Win + Q |
| Re-Capture Last | Win + R |
| Text Line Capture | Win + E |
| Forward Text Line Capture | Win + W |
| Bubble Capture | Win + S |
| Quick-Access Language 1 | Win + 1 |
| Quick-Access Language 2 | Win + 2 |
| Quick-Access Language 3 | Win + 3 |
| Text Orientation | Win + O |
Точные названия этих действий видны во вкладке Hotkeys, где можно переназначить сочетания клавиш или отключить их через значение <Unmapped>. Там же присутствуют пункты Toggle Whitelist и Toggle Blacklist, которые по умолчанию не привязаны к сочетаниям.
Основные режимы OCR в Capture2Text
Standard OCR Capture
Базовый режим — это Start OCR Capture, который запускается по Win + Q. Пользователь ставит курсор в верхний левый угол нужного фрагмента, нажимает hotkey, растягивает синюю рамку на интересующую область и подтверждает захват повторным нажатием горячей клавиши, левым кликом или ENTER. Во время выделения рамку можно целиком перетаскивать, удерживая правую кнопку мыши. На выходе Capture2Text распознаёт выделенный фрагмент и сразу отправляет текст в буфер обмена.
Этот режим — основной для всего, что не укладывается в более узкие сценарии. Он подходит для текста в PDF-сканах, на веб-страницах в виде изображений, в презентациях, диалоговых окнах, на баннерах, в видеороликах, на скриншотах, в старом программном интерфейсе. Если нужно извлечение текста из изображения с произвольной геометрией, но без сложных ограничений, стандартный захват остаётся самым надёжным вариантом. Его преимущество — полный контроль над областью OCR.

Для русского и английского текста этот режим удобен почти всегда. Для японского и китайского он особенно важен ещё и потому, что в программе есть отдельное управление направлением текста. При выборе Chinese или Japanese можно переключать Text Orientation и задавать Auto, Horizontal или Vertical. Если активирован Auto, программа использует горизонтальный режим, когда ширина захвата больше чем в два раза превышает высоту, а в остальных случаях — вертикальный. Эта деталь критична для восточноазиатского текста: без корректной ориентации OCR резко ухудшается.
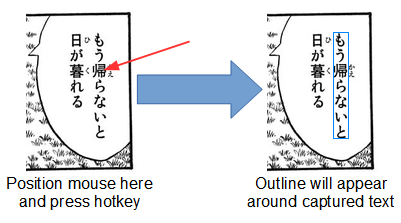
Text Line OCR Capture
Text Line OCR Capture запускается по Win + E и работает иначе: вместо ручного прямоугольного выделения Capture2Text автоматически ищет ближайшую к курсору строку текста, выделяет её контуром и распознаёт результат. Это очень удачный режим для подписей, названий пунктов меню, строк статуса, небольших текстовых элементов интерфейса, одиночных субтитров и коротких подписей в документах.
С практической точки зрения text line OCR capture полезен там, где ручная рамка — лишнее действие. Если на экране ровная одиночная строка, пользователю не нужно растягивать прямоугольник и подгонять его по высоте. Достаточно подвести курсор близко к строке и нажать Win + E. Это ускоряет OCR с экрана в сценариях, где нужно быстро копировать множество коротких элементов подряд: названия вкладок, строк в таблице, подписи столбцов, отдельные реплики в субтитрах.
Forward Text Line OCR Capture
Forward Text Line OCR Capture по Win + W — ещё более специальный режим. Он не просто ищет ближайшую строку, а начинает захват с символа, который находится ближе всего к курсору, и идёт вперёд по строке. В обычной работе это полезно тогда, когда нужен не весь ряд текста, а только его хвостовая часть: например, значение после метки, адрес после подписи, код после двоеточия, цена после названия или часть строки, начинающаяся не с самого первого символа.
Этот режим нельзя назвать универсальным, но именно за счёт своей специальности он и ценен. В обычных OCR-программах пользователь часто вынужден брать всю строку, затем вручную удалять ненужное начало. Capture2Text даёт более точный сценарий: подвести курсор к нужному месту в строке и получить распознавание оттуда вперёд. Для UI-элементов и структурированных строк это заметно ускоряет работу.
Bubble OCR Capture
Bubble OCR Capture по Win + S — одна из самых характерных функций Capture2Text. Программа умеет автоматически распознавать текст внутри speech/thought bubble, если пузырь полностью замкнут. Пользователь ставит курсор в пустую часть bubble, не на сами символы, запускает режим, и программа выделяет содержимое внутри контура.
Это узкая функция, но именно она показывает, что Capture2Text — обзор конкретной программы, а не абстрактной OCR-категории. Bubble OCR нужен не каждому, но тем, кто читает мангу, комиксы или работает с визуальными новеллами и графическими материалами, он экономит массу времени. Вместо ручной подгонки захвата под облачко программа сама пытается извлечь нужный текстовый блок. В обычных офисных OCR-утилитах такой режим либо отсутствует, либо не выделен в отдельную функцию.
Выбор языка и ориентации текста
У Capture2Text очень важен правильный выбор языка. Программа прямо завязана на активный OCR Language, и если попытаться распознавать русский интерфейс на английском профиле или японский вертикальный текст на горизонтальной настройке, результат быстро превращается в мусорные символы. Если Capture2Text выдаёт garbage characters, нужно указать корректный язык OCR. Это не мелочь, а фундаментальный принцип всей работы программы.
Для переключения языков предусмотрены два уровня управления. Первый — обычный выбор через меню OCR Language в трее. Второй — Quick-Access Languages, то есть три быстрых слота, между которыми можно прыгать с помощью Win + 1, Win + 2 и Win + 3. Такой подход хорош для реальной работы: например, в первом слоте держать English, во втором Russian, в третьем Japanese. Тогда OCR по скриншоту не превращается в постоянное хождение по меню и смену профиля перед каждым захватом.
Во вкладке настроек для OCR видны точные элементы, через которые всё это настраивается: Current OCR Language, блок Quick-Access Languages, параметры Whitelist, Blacklist, Text Orientation, Tesseract Config File, а также опции Deskew capture и Trim capture. Это один из самых важных экранов программы, потому что именно здесь Capture2Text из базовой утилиты превращается в настраиваемый рабочий инструмент.
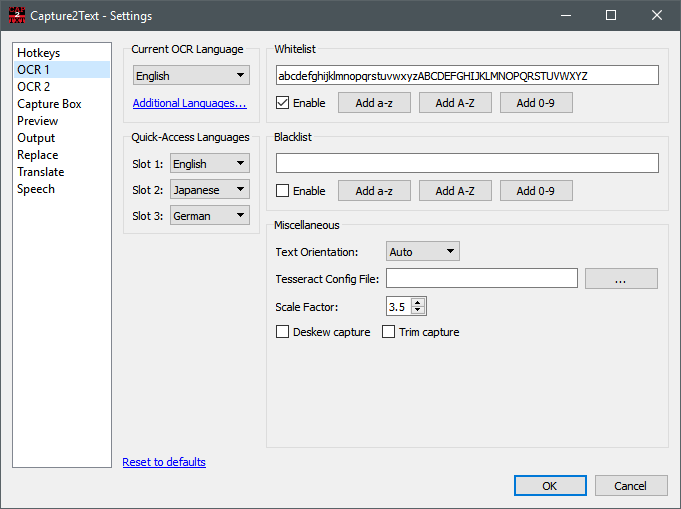
Whitelist и Blacklist
Whitelist и Blacklist в Capture2Text — не декоративные настройки, а реально полезные инструменты точной подстройки OCR. Whitelist сообщает движку, что в захваченной области допустимы только указанные символы. Blacklist, наоборот, запрещает распознавать определённые знаки. Это особенно полезно для цифр, артикулов, кодов, сумм, серийных номеров, коротких служебных строк и любых данных, где набор допустимых символов заранее известен.
Например, если нужно вынимать из интерфейса только числовые значения, whitelist из 0123456789 заметно снижает вероятность того, что буква O превратится в ноль или наоборот. Если в исходнике мешают лишние символы определённого типа, blacklist помогает убрать часть шума. Для бытового OCR это уже полу-профессиональный уровень настройки, и именно такие детали отличают Capture2Text от совсем простых экранных OCR-инструментов.
Trim Capture и Deskew Capture
Trim Capture и Deskew Capture — два параметра, которые напрямую влияют на качество результата. Trim Capture во время предобработки обрезает захваченное изображение по пикселям переднего плана и добавляет тонкую рамку. Это делает точность OCR более стабильной и в ряде случаев повышает её. Deskew Capture пытается компенсировать наклонённый текст. Для фото, косо снятых фрагментов, неровных скриншотов и неидеальных захватов это может быть разницей между нормальным распознаванием и хаосом.
В повседневной работе эти опции особенно полезны на нестандартных исходниках: фото экрана, косо вставленные блоки в PDF, мелкий текст, вырезанные фрагменты интерфейса, изображения с лишними полями. В простых условиях — ровный экранный текст, хороший контраст, крупный шрифт — Capture2Text справляется и без них. Но когда OCR с экрана начинает ошибаться, именно Trim capture и Deskew capture — одни из первых настроек, на которые стоит смотреть.
Настройки Capture2Text
Окно Capture2Text - Settings структурировано по вкладкам. В левой панели видны Hotkeys, OCR 1, OCR 2, Capture Box, Preview, Output, Replace, Translate, Speech. Такой набор разделов хорошо показывает характер программы: она маленькая по интерфейсу, но довольно глубокая по настройке. Здесь нет ощущения перегруженного корпоративного ПО, однако для пользователя, который хочет подстроить OCR под свои сценарии, параметров достаточно.
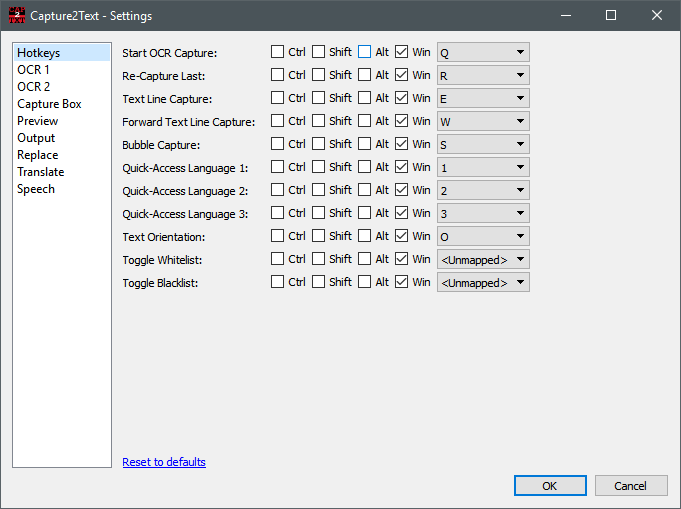
Hotkeys
Во вкладке Hotkeys переназначаются все основные сочетания. Здесь задаются клавиша и модификаторы для захвата, повторного захвата, line capture, forward line capture, bubble capture, трёх быстрых языков и ориентации текста. Если сочетание не нужно, его можно отключить через <Unmapped>. Это важно, потому что у многих пользователей комбинации Win + Q, Win + E, Win + W и Win + S могут пересекаться с личными привычками, скриптами или другими программами. Capture2Text не заставляет жить с заводским набором и позволяет привести управление к собственному рабочему стандарту.
Capture Box
Capture Box отвечает за внешний вид рамки OCR-захвата. Можно менять её цвета, а прозрачность регулируется через Alpha channel в диалоге выбора цвета. На первый взгляд это косметика, но для интенсивной работы цвет рамки имеет практическое значение. Слишком бледная рамка теряется на светлом фоне, слишком агрессивная перекрывает мелкий текст и мешает точному позиционированию. Удобно, что Capture2Text позволяет подобрать вариант под свой экран и тему оформления.
Preview
Во вкладке Preview задаются позиция, цвет и шрифт предпросмотра. Там же можно полностью отключить его через Show Preview Box. Для одних пользователей preview удобен, потому что помогает визуально понимать, что именно сейчас будет распознано. Для других он лишний, если OCR идёт серийно и всё равно проверяется уже по popup или clipboard. Программа не навязывает единый сценарий и позволяет оставить только те элементы, которые не тормозят работу.
Output
Output — один из ключевых разделов Capture2Text. Здесь включается Save to clipboard, активируется Show popup window, задаётся Keep line breaks, настраивается Logging и доступна функция Call Executable. Сильная сторона этого раздела в том, что он переводит программу из режима снял текст и вставил в режим управляемого потока данных. OCR может просто копироваться в буфер, может показываться во всплывающем окне, может сохраняться в лог, а может уходить во внешний обработчик.
Keep line breaks полезен в тех случаях, когда важно сохранить структуру абзаца или списка. Если опция выключена, переносы могут быть убраны; если включена, распознанный текст остаётся ближе к исходной структуре. Для извлечения текста из PDF-скана, субтитров, статейных фрагментов и обучающих материалов это важно: иначе копия быстро превращается в сплошную строку, которую потом приходится вручную чинить.
Logging позволяет записывать все захваты в файл в заданном формате с использованием токенов ${capture}, ${translation}, ${timestamp}, ${linebreak}, ${tab}. Это уже не бытовая функция, а элемент системной работы. Например, можно собирать журнал OCR-операций, вести накопление терминов, сохранять распознанные подписи или автоматизировать сбор коротких фрагментов из разных окон в один текстовый файл.
Call Executable — ещё один серьёзный инструмент. После завершения OCR программа может вызвать внешнее приложение и передать ему ${capture}, ${translation} и ${timestamp}. За счёт этого Capture2Text можно встроить в собственный рабочий процесс: передавать распознанный текст в словарь, скрипт обработки, пользовательскую утилиту или любой другой внешний модуль. Для маленькой экранной OCR-программы это очень сильная возможность.
Replace
Во вкладке Replace реализована постобработка результата. Здесь можно задавать замены текста, в том числе с поддержкой регулярных выражений. Левая часть правила — что искать, правая — на что заменять. Причём разные наборы замен можно хранить для разных OCR-языков. Эта функция особенно полезна там, где OCR систематически ошибается на одних и тех же символах или сочетаниях.
Практическая ценность Replace в том, что программа умеет исправлять повторяющиеся ошибки без ручной рутины. Если определённый шрифт всё время даёт одну и ту же подмену знаков, это можно починить на уровне правила. Если после OCR нужно стандартизировать кавычки, тире, пробелы, суффиксы, сокращения или шаблонно очищать мусорные артефакты, Capture2Text позволяет сделать это сразу после распознавания. Для поточного OCR по скриншоту это серьёзно экономит время.
Перевод текста в Capture2Text
Перевод в Capture2Text настраивается во вкладке Translate. Здесь есть точные флажки Append translation to clipboard и Show translation in popup window, выпадающий список Separator, параметр Server Timeout и таблица соответствий OCR Language → Translate To (using Google Translate). То есть перевод встроен не как отдельный одноразовый сервис, а как надстройка над OCR: программа сперва распознаёт текст, затем может тут же перевести его и либо дописать перевод в clipboard, либо показать его рядом с исходником во всплывающем окне.
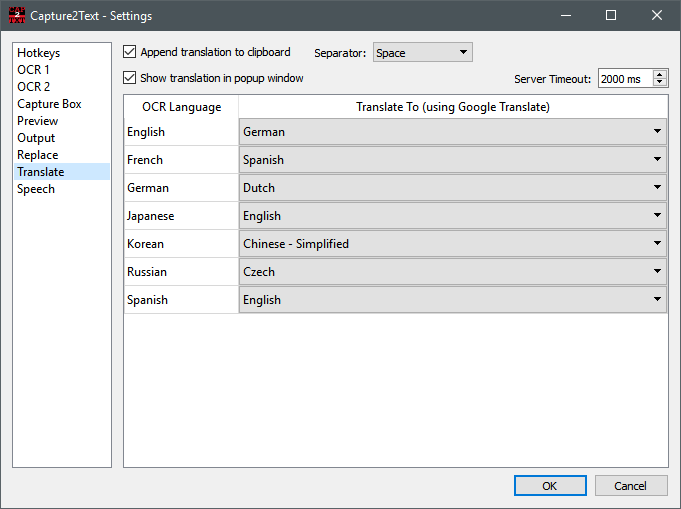
Для коротких фраз, интерфейсных строк, отдельных реплик, подписей и небольших текстовых фрагментов этот режим удобен. Не нужно отдельно копировать результат OCR и нести его в другой сервис. Достаточно настроить пары языков и включить отображение перевода. В popup можно сразу видеть исходный текст и его перевод, что особенно удобно для быстрого понимания интерфейсов, субтитров и коротких японских или английских фрагментов.
Нужно понимать границы этой функции. Capture2Text умеет переводить установленные OCR-языки в выбранные целевые языки, но не все языки поддерживаются в переводе, а сама функция требует интернет-подключения. Поэтому перевод здесь следует воспринимать как быстрое продолжение OCR-сценария, а не как полноценную переводческую систему с глубокой терминологической проработкой. Для коротких экранных фрагментов функция очень практична; для больших массивов текста или ответственной локализации она уже не является главным достоинством программы.
Text-to-speech
Во вкладке Speech Capture2Text умеет озвучивать распознанный текст. Здесь доступны Enable Text-to-speech, общий Volume, выбор OCR Language, отдельные параметры Rate, Pitch, Voice и кнопка Preview. Если для текущего языка голос не отключён, в popup-окне результата появляется кнопка Say. Сценарий работы простой: программа снимает текст с экрана, показывает его и может сразу произнести.
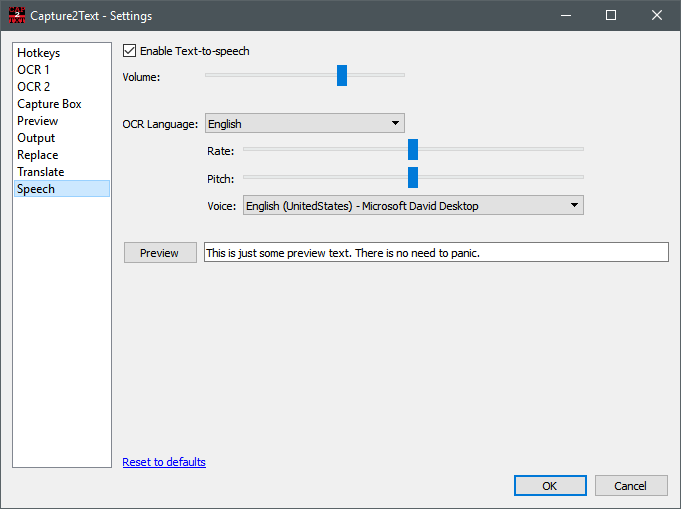
Эта функция полезна в трёх типах задач. Во-первых, при изучении языка, когда нужно не только сделать OCR с экрана, но и сразу прослушать слово или фразу. Во-вторых, при быстрой проверке того, как движок интерпретировал короткий фрагмент. В-третьих, в случаях, когда пользователю удобнее получать часть информации на слух. Capture2Text здесь не пытается конкурировать с полноценными TTS-системами, но как дополнение к OCR работает уместно и без лишних телодвижений.
Командная строка: Capture2Text_CLI.exe
Наличие Capture2Text_CLI.exe делает программу заметно сильнее обычных GUI-утилит. CLI умеет распознавать как image files, так и часть экрана. Среди параметров доступны --image, --images-file, --screen-rect, --language, --output-file, --output-file-append, --output-format, --clipboard, --trim-capture, --deskew, --whitelist, --blacklist, --scale-factor, --tess-config-file, --show-languages, а также --line-breaks. Для обычного пользователя это может быть избыточно, но для автоматизации OCR по изображениям или пакетной обработки фрагментов экрана CLI — серьёзный плюс.
Ниже типовые примеры того, как Capture2Text использует CLI:
Capture2Text_CLI.exe --screen-rect "400 200 600 300"Capture2Text_CLI.exe --vertical -l "Chinese - Simplified" -i img1.pngCapture2Text_CLI.exe -i img1.png -i img2.jpg -o result.txtCapture2Text_CLI.exe -l Japanese -f "C:\Temp\image_files.txt"Capture2Text_CLI.exe --show-languagesТакие сценарии полезны, когда OCR нужно не только снять руками, но и встроить в повторяющийся процесс. Например, обрабатывать список изображений, распознавать заданный прямоугольник экрана, сохранять результаты в файл, передавать выход в буфер обмена или ограничивать набор допустимых символов через whitelist. Для программы класса screen OCR это редкая глубина.
Практические сценарии использования
1. Копирование текста из окна, где нельзя выделить мышью
Это самый очевидный сценарий. Обычный путь — открыть диалог, увидеть текст, понять, что выделение не работает, и начать перепечатывать вручную. С Capture2Text достаточно Win + Q, выделения области и вставки результата из clipboard. Для всплывающих сообщений, предупреждений, устаревших программ, нестандартных контролов и внутренних интерфейсов это работает особенно хорошо.
2. OCR по скриншоту и изображениям
Если в браузере, презентации, PDF или мессенджере есть картинка с текстом, Capture2Text снимает нужный фрагмент без промежуточного сохранения файла. Это один из сильнейших бытовых сценариев программы: пользователь видит картинку, но работает с ней как с текстом. Для статейных вставок, графиков с подписями, сканов документов и кусочных изображений это экономит время и убирает рутину.
3. Работа с субтитрами и текстом в видео
Поскольку Capture2Text делает OCR с экрана Windows, ей неважно, откуда именно пришёл текст — из браузера, проигрывателя или локального видеофайла. Если субтитры на экране читаемы, их можно снять стандартным захватом или Text Line OCR Capture. Для коротких однотипных строк line-capture особенно удобен: меньше движений, быстрее цикл увидел — распознал — скопировал.
4. Манга, комиксы и визуальные материалы
Здесь Capture2Text выделяется на фоне многих аналогов. Программа умеет Bubble OCR Capture, знает о Text Orientation, пытается автоматически убирать furigana в японском тексте и позволяет быстро переключаться между языками через quick-access slots. Это делает её очень практичной для распознавания текста из манги и комиксов, где обычный прямоугольный захват часто неудобен, а текст может быть вертикальным.
5. Извлечение коротких структурированных значений
Для чисел, артикулов, сумм, кодов и однострочных значений Capture2Text удобна сочетанием Text Line OCR Capture, whitelist/blacklist и логирования. Пользователь может сузить алфавит до цифр, быстро снять нужную строку и сохранить всё в файл. Это уже не просто OCR для того чтобы скопировать текст, а инструмент для ускоренного извлечения однотипных данных из интерфейса.
Качество распознавания: сильные стороны и ограничения
Capture2Text хорошо работает на типичном экранном тексте: чёткие буквы, нормальный контраст, достаточный размер шрифта, ровный фон и правильно выбранный язык. В таких условиях программа быстро справляется с интерфейсными надписями, текстом на изображениях, ровными строками и стандартными экранными элементами. Особенно хорошо она показывает себя на коротких фрагментах, где важнее скорость, чем сложная постобработка.
Проблемы начинаются там же, где они начинаются у многих OCR-инструментов: мелкий шрифт, сильный шум, низкое разрешение, плохой контраст, курсив, наклон, наложения, сложный фон, неверный язык, неудачная ориентация текста. Но в Capture2Text часть этих ограничений компенсируется настройками. Можно переключать язык, менять Text Orientation, включать Trim Capture, активировать Deskew Capture, задавать whitelist и blacklist, а при серийной работе — править типовые ошибки через Replace. Программа не делает магию, но даёт инструменты, чтобы вытянуть качество там, где простой OCR уже сдаётся.
Нужно честно сказать и другое: Capture2Text не выглядит как современный визуальный AI-сервис, который пытается понять документ целиком, таблицы, смысловые блоки и сложную вёрстку. Это экранный OCR-инструмент с быстрым и функциональным подходом. Поэтому он лучше всего проявляет себя на конкретных, коротких и управляемых захватах. Чем ближе задача к быстро вытащить текст из видимой области, тем сильнее Capture2Text. Чем ближе задача к распознать сложный документ со структурой и экспортом, тем меньше программа оказывается в своей стихии. Этот баланс нужно понимать заранее.
Плюсы Capture2Text
-
Быстрое распознавание текста с экрана без установки и без лишних окон.
-
Несколько специализированных режимов захвата: стандартный,
Text Line OCR Capture,Forward Text Line OCR Capture,Bubble OCR Capture. -
Гибкое управление языками через
OCR LanguageиQuick-Access Languages. -
Поддержка вертикального текста через
Text Orientation. -
Полезные OCR-настройки: whitelist, blacklist, trim capture, deskew capture, Tesseract config.
-
Встроенный перевод с показом в popup или добавлением в clipboard.
-
Text-to-speech с выбором voice, rate и pitch.
-
Логирование, регулярные замены и вызов внешнего исполняемого файла после OCR.
-
Capture2Text_CLI.exeдля командной строки и автоматизации.
Минусы Capture2Text
-
Интерфейс у программы утилитарный и визуально довольно старый; он сделан ради функции, а не ради удобной визуальной среды. Это видно и по трею, и по popup, и по окну настроек.
-
Программа лучше всего чувствует себя на коротких экранных фрагментах, а не на сложных документах с богатой структурой.
-
Для качественного результата пользователю приходится следить за языком, ориентацией и в ряде случаев подстраивать OCR-параметры вручную.
-
Некоторые функции, например перевод и text-to-speech, полезны, но всё же вторичны относительно основной сильной стороны программы — быстрого OCR с экрана.
Сравнение с аналогами
Capture2Text уместно сравнивать не с OCR вообще, а с несколькими реальными инструментами, которые решают близкие задачи на Windows: Microsoft PowerToys Text Extractor, Text Grab, ABBYY Screenshot Reader и ShareX.
| Программа | Что делает | Где сильнее | Где слабее относительно Capture2Text |
|---|---|---|---|
| Microsoft PowerToys Text Extractor | Быстро копирует текст из любой области экрана по Win + Shift + T, сохраняет результат в clipboard, опирается на языковые пакеты Windows. |
Очень простой и нативный сценарий для мгновенного экранного OCR. | Меньше специализированных режимов, нет bubble OCR, нет такого объёма настроек OCR и встроенных функций вроде Replace, Speech или Call Executable. |
| Text Grab | Имеет Full-Screen Mode, Grab Frame Mode, Edit Text Window, Quick Simple Lookup и CLI. После OCR предлагает развитую текстовую обработку. | Сильнее как среда для дальнейшей работы с текстом после распознавания. | Capture2Text быстрее и прямолинейнее в сценарии нажал hotkey — снял текст — вставил. Для чистого screen OCR она проще и легче. |
| ABBYY Screenshot Reader | Захватывает изображения и текст, умеет извлекать текст и таблицы, сохраняет текстовые результаты в .RTF, .TXT, .DOC, .XLS, поддерживает более 180 языков. |
Сильнее как коммерческий инструмент для извлечения текста и таблиц в офисные форматы. | Capture2Text компактнее, быстрее по ощущению и лучше заточена под горячие клавиши, tray-workflow и специализированные режимы экранного OCR. |
| ShareX | Огромный набор методов захвата, after capture tasks, OCR как одна из задач, аннотации, загрузка, редактор, скроллинг-захват и другие инструменты. | Мощнее как универсальный центр скриншотов и автоматизированных workflows. | OCR в ShareX — часть большого набора функций. Capture2Text проще именно как специализированная программа для распознавания текста с экрана. |
Microsoft PowerToys Text Extractor
Text Extractor в составе PowerToys делает ставку на нативность и минимальный сценарий: Win + Shift + T, выделение области, копирование текста в буфер. Это хороший вариант для пользователя, которому нужна одна функция без дальнейшей настройки.
Capture2Text на этом фоне интереснее именно как специализированный рабочий инструмент. В ней больше режимов захвата, есть quick-access languages, Text Orientation, translation, speech, logging, replace-правила, CLI и вызов внешнего executable. Если PowerToys Text Extractor — это быстрый встроенный нож, то Capture2Text — уже точный мультитул именно для OCR с экрана. В сценариях с разными языками, мангой, line capture и постобработкой она заметно функциональнее.
Text Grab
Text Grab — очень близкий по духу продукт. Но по характеру это другой софт. В Text Grab есть четыре режима: Full-Screen Mode, Grab Frame Mode, Edit Text Window, Quick Simple Lookup. Особенно выделяется Edit Text Window, где уже после OCR доступны инструменты вроде Find and replace, Remove duplicate lines, Convert stacked data to table format, Copy text from every image in a folder и другие.
На этом фоне Capture2Text выглядит более жёстко сфокусированной. Она меньше про последующую редактуру текста и больше про моментальное извлечение невыделяемого текста из интерфейса. У неё нет такого развитого текстового окна для ручной обработки, зато есть line capture, forward line capture, bubble OCR, системный tray-workflow, whitelist/blacklist и более специализированная подстройка именно OCR-части. Если нужен инструмент взял текст с экрана и пошёл дальше, Capture2Text действует быстрее и прямее. Если нужен гибрид OCR и мини-редактора, Text Grab шире.
ABBYY Screenshot Reader
ABBYY Screenshot Reader позиционируется иначе. Это продукт для захвата изображений и текста с экрана с акцентом на конвертацию в редактируемые форматы и извлечение таблиц. Среди форматов сохранения — JPEG, Bitmap, PNG для картинок и .RTF, .TXT, .DOC, .XLS для текстовых результатов.
Capture2Text здесь выигрывает в другом. Она легче, быстрее в запуске, проще по интерфейсу и гораздо лучше ощущается как утилита повседневного OCR с экрана Windows по горячим клавишам. ABBYY Screenshot Reader сильнее тогда, когда нужно вытаскивать текст и таблицы в офисный документооборот. Capture2Text сильнее тогда, когда нужно за долю секунды снять строку, подпись, кусок интерфейса, субтитр или bubble из комикса. Это не конкуренты в лоб по всем фронтам; это программы с разным центром тяжести.
ShareX
ShareX — совершенно другой масштаб продукта. Это бесплатный open-source инструмент для screen capture, file sharing и productivity, где OCR — только одна из функций в составе большого комплекса. В ShareX есть многочисленные capture methods, after capture tasks, региональные инструменты, аннотации, image editor, scrolling capture, upload-сценарии и прочие возможности.
Поэтому ShareX сильнее как универсальная платформа скриншотов и автоматизированных workflows. Но именно из-за широты она не так сфокусирована на чистом OCR. Capture2Text в этом смысле проще и точнее: запустил, выбрал OCR Language, нажал hotkey, снял текст. Если пользователю нужен прежде всего экранный OCR и не нужен целый центр захвата, Capture2Text оказывается более рациональным выбором. Если нужен тяжёлый швейцарский нож для скриншотов, аннотаций, OCR и загрузки — тогда уже разумнее смотреть на ShareX.
Кому подойдёт Capture2Text
Capture2Text подходит тем, кому нужен быстрый OCR с экрана Windows без лишнего интерфейсного шума. Это хороший выбор для пользователей, которые постоянно копируют невыделяемый текст из окон программ, PDF-сканов, изображений, видеосубтитров, всплывающих сообщений и различных UI-элементов. Особенно программа уместна там, где важны горячие клавиши, быстрые языковые слоты и мгновенное попадание результата в буфер обмена.
Отдельная аудитория Capture2Text — те, кто работает с японским и китайским текстом на экране. Поддержка Text Orientation, автоматическая попытка удаления furigana, bubble OCR и быстрый языковой переключатель делают программу заметно более пригодной для манги, комиксов и учебных материалов, чем многие минималистичные аналоги, которые умеют только прямоугольный захват.
Программа также подойдёт тем, кто любит тонкую настройку. Если пользователю нужны whitelist, blacklist, replace-правила, логирование OCR, вызов внешнего executable и CLI, Capture2Text даёт эти возможности без перехода в тяжёлое профессиональное ПО. В этом её редкое достоинство: она остаётся небольшой утилитой, но не обрезает себе функциональность до примитивного минимума.
Итог
Capture2Text — это точный, прикладной инструмент для распознавания текста с экрана, а не универсальный центр работы с документами. Она сильна не эффектным интерфейсом и не попыткой охватить весь мир OCR, а скоростью, логикой управления и количеством действительно полезных функций вокруг экранного захвата: line capture, forward line capture, bubble OCR, quick-access languages, orientation, translation, speech, logging, replace и CLI. Всё это делает программу очень практичной в повседневной работе.
Если оценивать Capture2Text именно как программу своего типа, вывод получается простой. Для задачи быстро извлечь текст из того, что видно на экране, это сильное решение. Для задачи обрабатывать сложные документы как в офисном OCR-пакете — уже не тот класс продукта. Но в своей нише Capture2Text остаётся удобной, цепкой и хорошо продуманной утилитой, которая умеет больше, чем кажется по её внешнему виду.