
Распознавание текста нужно в ситуациях, когда документ выглядит как картинка: отсканированный договор, сфотографированный чек, PDF без выделяемого текста, страница книги, акт, счет, архивная справка, конспект, таблица или скриншот интерфейса. OCR-программа анализирует изображение, находит буквы, цифры, знаки препинания, таблицы и блоки верстки, после чего превращает их в редактируемый текст, Word-файл, Excel-таблицу или PDF с поиском.
В хорошем OCR-инструменте важны не только точность распознавания русского текста. На практике решают детали: умеет ли программа сохранять колонки, как работает с таблицами, распознает ли многостраничные PDF, дает ли выбрать язык документа, сохраняет ли текстовый слой поверх исходного скана, выполняет ли пакетную обработку и требует ли загрузки конфиденциальных документов в облако.
Как выбрать программу для распознавания текста
Для обычной домашней задачи достаточно инструмента, который открывает JPG, PNG или PDF, распознает русский и английский, а затем сохраняет результат в DOCX или TXT. Для офиса требования строже: важны обработка десятков страниц, экспорт в Word и Excel, searchable PDF, настройка диапазона страниц, работа с печатями, таблицами, сканами с перекосом и файлами низкого качества.
Главные критерии выбора:
| Критерий | Что проверять |
|---|---|
| Точность OCR | Программа уверенно распознает русский, английский, цифры, даты, номера договоров и спецсимволы |
| Работа с PDF | Поддерживается распознавание сканированного PDF, создание поискового PDF и экспорт в Word |
| Качество обработки скана | Есть исправление перекоса, поворот страниц, повышение контраста, удаление шума |
| Таблицы | OCR сохраняет строки и столбцы, а не превращает таблицу в сплошной текст |
| Пакетный режим | Несколько файлов или страниц обрабатываются за один запуск |
| Приватность | Локальная программа не отправляет договоры, паспорта и счета на сторонний сервер |
| Удобство | Есть понятные кнопки вроде OCR, Распознать текст, Scan & OCR, Copy Text from Picture |
| Экспорт | DOCX, TXT, XLSX, PDF/A, searchable PDF, иногда RTF и HTML |
| Платформа | Windows, macOS, браузер, iPhone, Android |
Для бумажных документов лучше сканировать с разрешением 300 DPI, держать лист ровно, не допускать теней и бликов, заранее выбрать язык распознавания. Google Drive, например, лучше работает с PDF и изображениями JPEG, PNG, GIF, а также рекомендует загружать файлы до 2 МБ, держать документ в правильной ориентации и делать текст не меньше 10 пикселей по высоте.
Краткое сравнение OCR-программ
| Программа | Платформа | Лучший сценарий | Офлайн | Русский язык | Фото | Пакетная обработка | |
|---|---|---|---|---|---|---|---|
| PDF Commander | Windows | PDF, сканы, учебники, договоры | Да | Да | Да | Да | По страницам |
| ABBYY FineReader PDF | Windows, macOS | Максимальная точность и сложная верстка | Да | Да | Да | Да | Да |
| Adobe Acrobat Pro | Windows, macOS | OCR плюс редактирование PDF | Да | Да | Да | Да | Да |
| PDFelement Pro | Windows, macOS | Редактируемый PDF после OCR | Да | Да | Да | Да | Да |
| Readiris Pro | Windows, macOS | Конвертация сканов в офисные форматы | Да | Да | Да | Да | Да |
| NAPS2 | Windows, macOS, Linux | Бесплатное сканирование с OCR | Да | Да | Да | Да | Да |
| Tesseract OCR | Windows, macOS, Linux | Автоматизация и командная строка | Да | Да | Через обвязки | Да | Да |
| OneNote | Windows, macOS, Web | Быстро скопировать текст с картинки | Частично | Да | Через вставку | Да | Нет |
| Capture2Text | Windows | Текст с экрана | Да | Да | Нет | Да | Нет |
| Google Drive + Google Docs | Браузер | Бесплатное распознавание фото и PDF | Нет | Да | Да | Да | Нет |
| OnlineOCR | Браузер | Быстро получить Word, Excel или TXT | Нет | Да | Да | Да | Нет |
| OCR.space | Браузер, API | OCR для файлов и интеграций | Нет | Да | Да | Да | Да |
| Adobe Scan | iPhone, Android | Сканирование документов телефоном | Нет | Да | Да | Камера | Да |
| CamScanner | iPhone, Android, Web | Мобильный сканер с OCR | Нет | Да | Да | Камера | Да |
| Apple Live Text | iPhone, iPad, macOS | Текст прямо из камеры и фото | Да | Зависит от языка | Нет | Да | Нет |
| Google Lens | Android, iPhone | Текст, перевод, быстрые действия | Нет | Да | Нет | Да | Нет |
| Text Fairy | Android | Простое распознавание снимков | Да | Да | Через экспорт | Да | Нет |
Программы для распознавания текста на Windows
PDF Commander
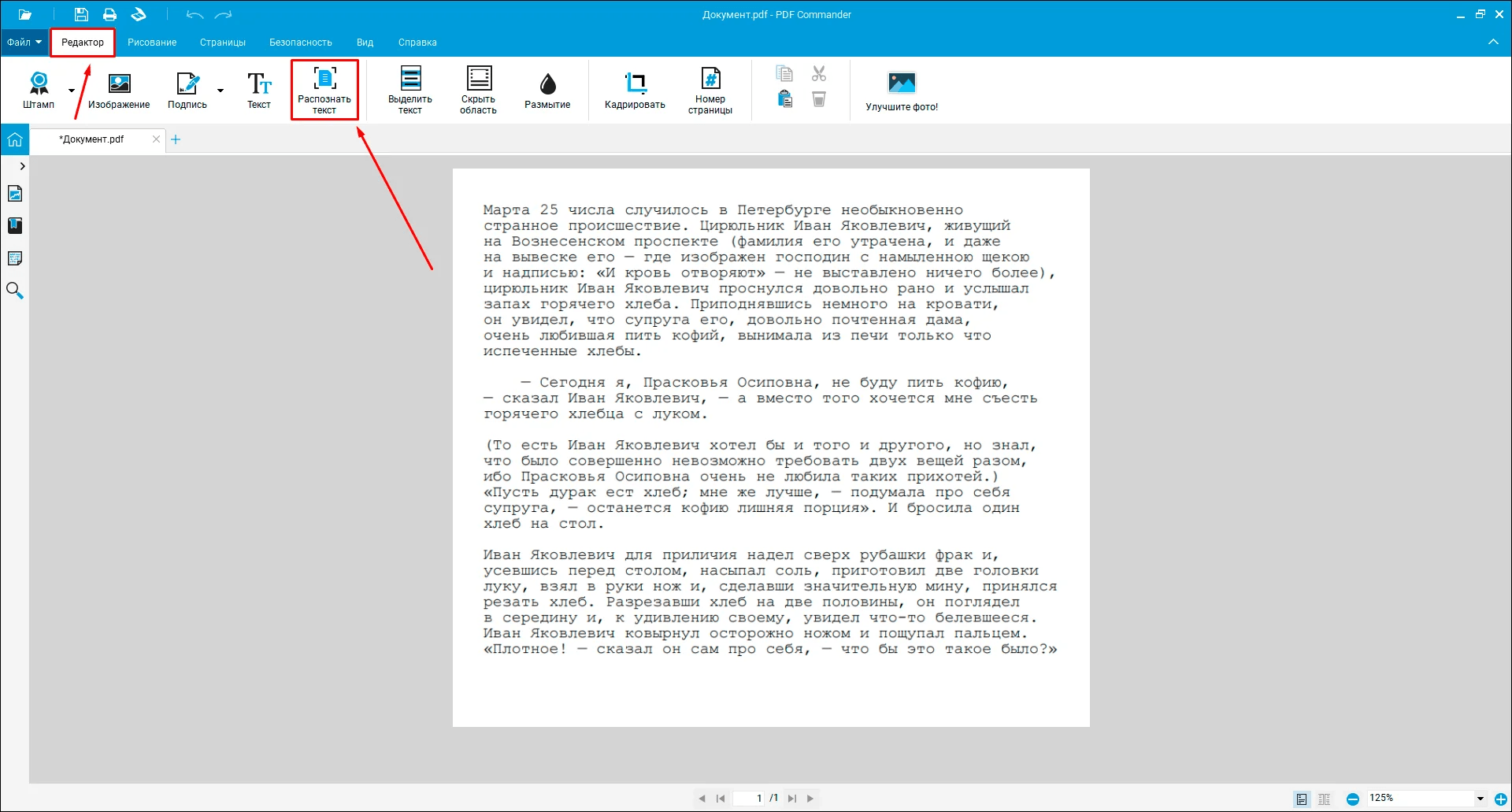
PDF Commander стоит поставить первым, когда нужна понятная программа для распознавания текста на Windows без перегруженного профессионального интерфейса. Она подходит для сканированных учебников, договоров, актов, отчетов, инструкций, заявлений, справок и PDF-файлов, где текст не выделяется мышью. В редакторе есть распознавание текста: открываете отсканированный документ, запускаете одноименную функцию, выбираете русский или английский язык, указываете диапазон страниц и сохраняете результат в удобном формате.
PDF Commander удобен тем, что OCR встроен в общий рабочий процесс с PDF. После распознавания документ не нужно переносить в отдельный редактор: в той же программе доступны редактирование страниц, вставка текста, добавление изображений, объединение файлов, удаление лишних страниц, поворот, защита и экспорт.
Что можно сделать в PDF Commander
-
распознать текст в сканированном PDF;
-
извлечь текст из изображения внутри документа;
-
сделать PDF пригодным для копирования фрагментов;
-
выбрать язык распознавания;
-
обработать только нужный диапазон страниц;
-
отредактировать PDF после распознавания;
-
сохранить результат для учебы, работы или архива;
-
подготовить договор, инструкцию, заявление, счет или акт к дальнейшей правке.
-
Откройте PDF Commander.
-
Нажмите кнопку открытия файла и выберите сканированный PDF.
-
Перейдите к функции распознавания текста.
-
Отметьте язык документа: русский или английский.
-
Укажите все страницы или нужный диапазон.
-
Запустите OCR.
-
Проверьте результат: номера, даты, фамилии, таблицы и спецсимволы.
-
Сохраните файл как PDF с распознанным текстом или экспортируйте содержимое в редактируемый формат.
Плюсы
-
русскоязычный интерфейс;
-
понятный сценарий для новичка;
-
OCR встроен прямо в PDF-редактор;
-
подходит для учебников, отчетов, договоров и сканов;
-
есть выбор языка и диапазона страниц;
-
после распознавания файл сразу редактируется;
-
не требует сложной настройки.
Минусы
-
нет такой глубокой профессиональной разметки зон, как в ABBYY FineReader;
-
для сложных таблиц требуется ручная проверка;
-
рукописные заметки распознаются хуже печатного текста;
-
основной сценарий рассчитан на PDF, а не на потоковую обработку тысяч страниц.
PDF Commander лучше выбирать для Windows, когда нужно быстро распознать текст из PDF, поправить документ, удалить лишние страницы, объединить файлы и получить результат без сложного обучения.
ABBYY FineReader PDF
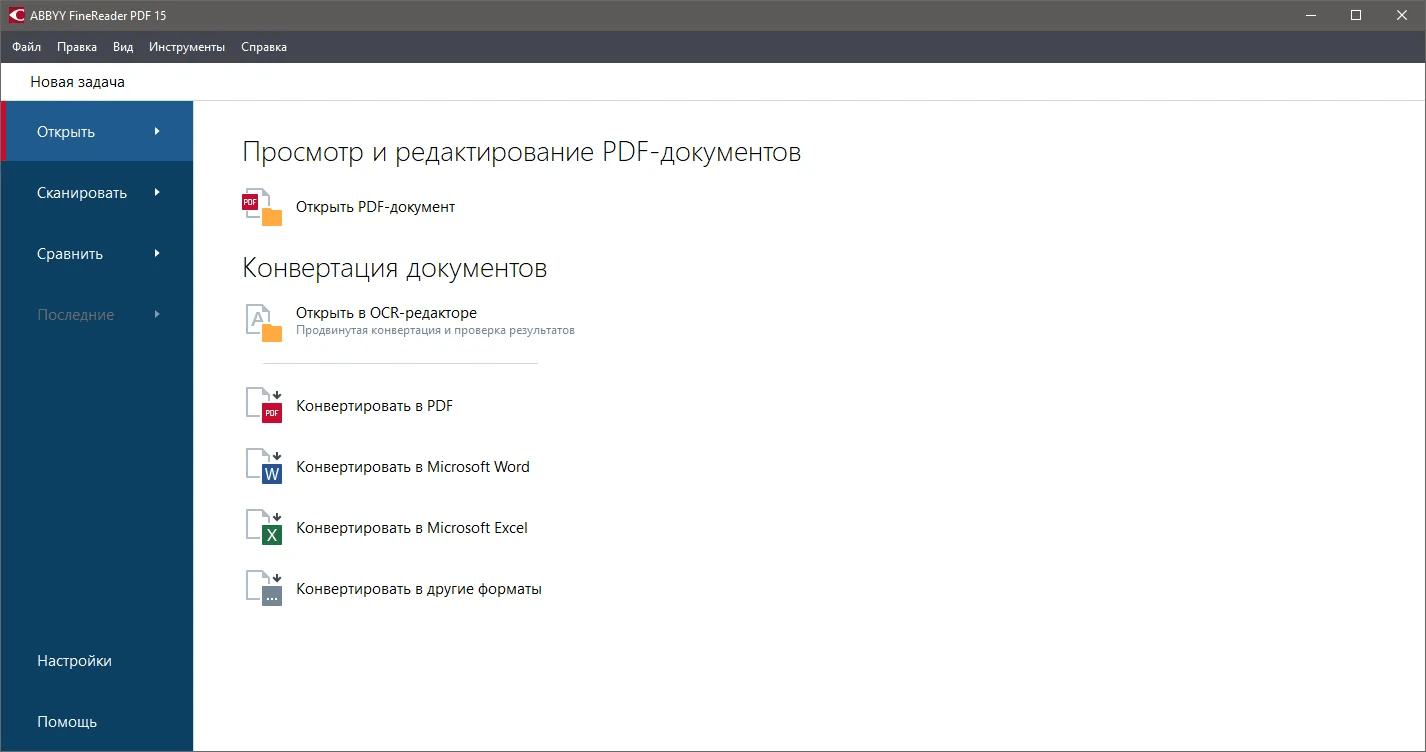
ABBYY FineReader PDF — профессиональный OCR-инструмент для тех, кто часто работает со сканами, архивами, договорами, счетами, таблицами, многостраничными PDF и документами со сложной версткой. Программа использует OCR-технологии ABBYY для оцифровки, поиска, редактирования, защиты, совместной работы и конвертации документов; она переводит бумажные и сканированные документы в Microsoft Word, Excel, OpenOffice Writer и другие форматы с сохранением структуры.
FineReader хорошо подходит для задач, где важно не просто получить текст, а сохранить исходный вид страницы: колонки, заголовки, таблицы, сноски, изображения, нумерацию, подписи и поля. Это важно для юридических документов, учебных материалов, технических инструкций, бухгалтерских таблиц и архивных подборок.
Что можно сделать в ABBYY FineReader PDF
-
распознать сканированный PDF;
-
создать searchable PDF с текстовым слоем;
-
конвертировать PDF и изображения в Word, Excel, RTF и TXT;
-
сравнить две версии документа;
-
распознать таблицы и сохранить их в XLSX;
-
настроить области распознавания вручную;
-
обработать папку с документами;
-
улучшить изображение перед OCR;
-
проверить ошибки в окне распознанного текста.
Инструкция
-
Запустите ABBYY FineReader PDF.
-
Выберите задачу OCR или откройте файл через меню открытия.
-
Укажите PDF, TIFF, JPG, PNG или другой скан.
-
Проверьте язык документа.
-
При сложной верстке откройте редактор областей и проверьте блоки: текст, таблица, изображение.
-
Запустите распознавание.
-
Исправьте подозрительные символы в проверочном окне.
-
Сохраните результат как DOCX, XLSX, TXT или PDF с поиском.
Плюсы
-
высокая точность на печатных документах;
-
хорошая работа с русским языком;
-
сохранение структуры страницы;
-
сильное распознавание таблиц;
-
подходит для больших архивов;
-
есть инструменты проверки ошибок;
-
поддерживает профессиональную конвертацию PDF в Word и Excel.
Минусы
-
интерфейс насыщен функциями и требует привыкания;
-
программа тяжелее простых OCR-утилит;
-
для разовой задачи выглядит избыточно;
-
лучшие функции ориентированы на платный профессиональный сценарий.
FineReader стоит выбирать для документов, где ошибка в цифре, фамилии, дате или строке таблицы приводит к проблемам: договоры, акты, счета, отчеты, архивные дела, научные материалы.
Adobe Acrobat Pro
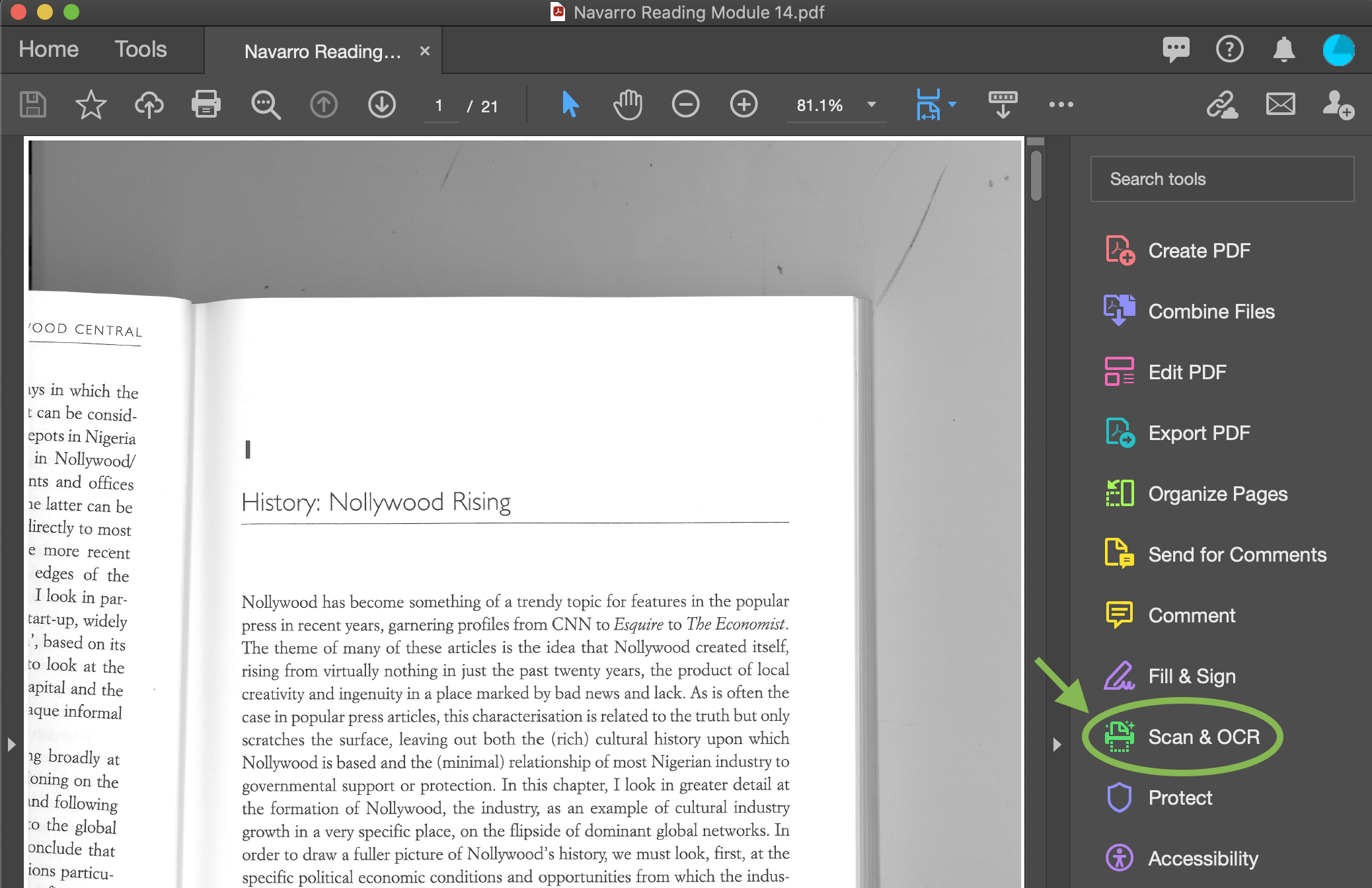
Adobe Acrobat Pro удобен для тех, кто уже редактирует PDF, подписывает документы, добавляет комментарии, защищает файлы и готовит их к отправке. OCR в Acrobat превращает сканы в редактируемые и поисковые PDF: текст извлекается из отсканированных документов и изображений, после чего документ становится доступным для поиска и правки.
Рабочий путь в Acrobat логичный: открыть PDF, перейти в раздел All tools, выбрать Scan & OCR, нажать In this file, настроить язык и запустить Recognize Text. После распознавания в том же файле работает поиск, выделение, копирование и редактирование текста.
Что можно сделать в Adobe Acrobat Pro
-
распознать текст в сканированном PDF;
-
сделать файл searchable PDF;
-
отредактировать распознанный текст;
-
объединить OCR с комментариями, подписями и защитой;
-
улучшить качество скана;
-
экспортировать PDF в Word или Excel;
-
подготовить документ к отправке в офисный документооборот.
Инструкция
-
Откройте сканированный PDF в Adobe Acrobat Pro.
-
Перейдите в All tools.
-
Откройте Scan & OCR.
-
Нажмите Recognize Text.
-
Выберите In this file.
-
Откройте настройки языка и диапазона страниц.
-
Запустите распознавание.
-
Используйте Edit PDF для правки текста или Export PDF для сохранения в Word.
Плюсы
-
сильная связка OCR и PDF-редактирования;
-
удобен для делового документооборота;
-
поддерживает searchable PDF;
-
хорошо работает с комментариями, подписями и защитой;
-
подходит для PDF, которые нужно не только распознать, но и доработать.
Минусы
-
платная подписочная модель;
-
интерфейс перегружен для простой задачи;
-
для разового распознавания проще использовать PDF Commander, NAPS2 или онлайн-сервис;
-
на слабых компьютерах работает тяжелее легких OCR-программ.
Adobe Acrobat Pro лучше подходит офису, где PDF-файл проходит полный цикл: сканирование, распознавание, редактирование, комментарии, подписи, защита и отправка.
PDFelement Pro
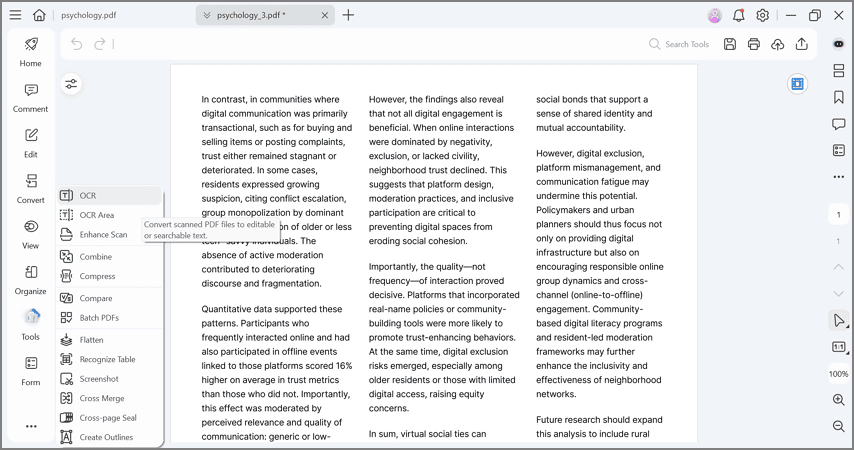
PDFelement Pro — PDF-редактор с OCR, который переводит отсканированные и image-based PDF в редактируемые и поисковые документы. В программе есть распознавание всего документа и отдельной области, поддерживается извлечение, редактирование и поиск текста внутри сканов.
PDFelement удобен для пользователей, которым нужен баланс между Acrobat и более простыми редакторами: открыть PDF, запустить OCR, выбрать режим searchable или editable, затем править текст, картинки и страницы. В актуальной линейке заявлены OCR для сканированных PDF и изображений, работа с несколькими языками и пакетное распознавание.
Что можно сделать в PDFelement Pro
-
распознать весь PDF;
-
распознать выбранную область страницы;
-
сделать PDF редактируемым;
-
создать PDF с поиском;
-
экспортировать результат в Word, Excel или TXT;
-
редактировать текст после OCR;
-
обрабатывать несколько файлов;
-
конвертировать сканы в офисные форматы.
Инструкция
-
Откройте PDFelement Pro.
-
Нажмите Open File и выберите сканированный PDF.
-
Перейдите к инструменту OCR.
-
Выберите режим: редактируемый PDF или searchable PDF.
-
Укажите язык документа.
-
Настройте страницы или область распознавания.
-
Нажмите Apply или OK.
-
После обработки перейдите в режим редактирования текста.
Плюсы
-
современный интерфейс PDF-редактора;
-
есть OCR всего файла и области;
-
подходит для PDF, Word, Excel и текстового экспорта;
-
удобен для редактирования после распознавания;
-
поддерживает пакетные сценарии.
Минусы
-
OCR-функции зависят от редакции и лицензии;
-
сложные таблицы требуют проверки;
-
для полного документооборота Acrobat привычнее в крупных компаниях;
-
бесплатный режим ограничен.
PDFelement Pro стоит брать, когда нужен PDF-редактор с OCR, но интерфейс Acrobat кажется слишком тяжелым.
Readiris Pro
Readiris Pro — OCR-программа для конвертации сканов и PDF в Word, Excel, PowerPoint, изображения и другие форматы. Readiris PDF позиционируется как PDF-конвертер с AI-powered OCR, пакетной конвертацией, извлечением текста, сохранением шрифтов, форматирования и структуры документа.
Readiris удобен для пользователей, которым часто нужно переводить сканы в редактируемые офисные документы. Он закрывает задачи сканирования, распознавания, конвертации и подготовки PDF. Особенно полезен в офисах, где документы приходят из разных источников: сканер, телефон, почта, архивные изображения.
Что можно сделать в Readiris Pro
-
распознать PDF и изображения;
-
конвертировать скан в Word;
-
сохранить таблицу в Excel;
-
создать searchable PDF;
-
обрабатывать несколько документов;
-
сохранять структуру страниц;
-
готовить документы для архива;
-
работать со сканерами.
Инструкция
-
Откройте Readiris Pro.
-
Добавьте PDF, скан или изображение.
-
Укажите язык распознавания.
-
Выберите итоговый формат: Word, Excel, PDF, TXT или изображение.
-
Проверьте разметку страниц.
-
Запустите распознавание.
-
Откройте экспортированный документ и проверьте таблицы, номера и списки.
Плюсы
-
хорошая конвертация в офисные форматы;
-
поддерживает пакетную обработку;
-
подходит для сканов и PDF;
-
сохраняет структуру страниц;
-
удобен для рабочих архивов.
Минусы
-
интерфейс менее привычен, чем у Acrobat и FineReader;
-
сложные документы требуют проверки областей;
-
для простого копирования текста есть более легкие решения;
-
часть возможностей зависит от версии.
Readiris Pro лучше всего подходит для конвертации сканированных документов в редактируемые файлы, особенно когда нужно получить не просто TXT, а Word или Excel.
NAPS2
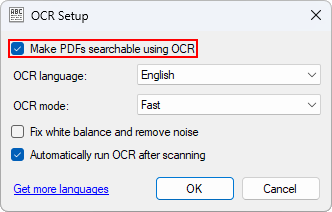
NAPS2 — бесплатная программа для сканирования документов и создания PDF. OCR в NAPS2 делает текст в сканированных документах поисковым, а не просто картинкой. Для запуска распознавания нужно нажать кнопку OCR на панели, скачать языки, затем включить Make PDFs searchable using OCR и выбрать нужный язык.
NAPS2 особенно хорош для пользователей, которым нужен легкий офлайн-сканер: подключить МФУ или сканер, отсканировать пачку страниц, повернуть, переставить, удалить лишние листы и сохранить PDF с текстовым слоем. Программа не заменяет полноценный OCR-редактор, но отлично справляется с созданием поисковых PDF-архивов.
Что можно сделать в NAPS2
-
сканировать документы через WIA и TWAIN;
-
импортировать уже готовые PDF и изображения;
-
включить OCR для сохранения поискового PDF;
-
скачать языковые пакеты;
-
выбрать один или несколько языков;
-
включить автоматический OCR после сканирования;
-
убрать шум и поправить белый баланс;
-
сохранить результат в PDF, TIFF, JPEG, PNG.
Инструкция
-
Откройте NAPS2.
-
Нажмите Profiles и настройте сканер.
-
Нажмите Scan или импортируйте готовый файл.
-
Нажмите OCR.
-
При первом запуске скачайте нужный язык.
-
В окне OCR Setup включите Make PDFs searchable using OCR.
-
Выберите язык и режим: Fast или Best.
-
Сохраните документ через Save PDF.
Плюсы
-
полностью бесплатная программа;
-
работает на Windows, macOS и Linux;
-
подходит для сканеров и МФУ;
-
делает PDF поисковым;
-
есть языковые пакеты;
-
легкий интерфейс;
-
обработка идет локально.
Минусы
-
не сохраняет OCR-результат напрямую в TXT;
-
не предназначен для глубокой правки текста;
-
таблицы после OCR лучше проверять в PDF-редакторе;
-
точность зависит от качества скана и языковых пакетов.
NAPS2 стоит использовать для домашнего и офисного архива: счета, инструкции, заявления, справки, старые документы и любые бумаги, которые нужно потом находить по словам.
Tesseract OCR
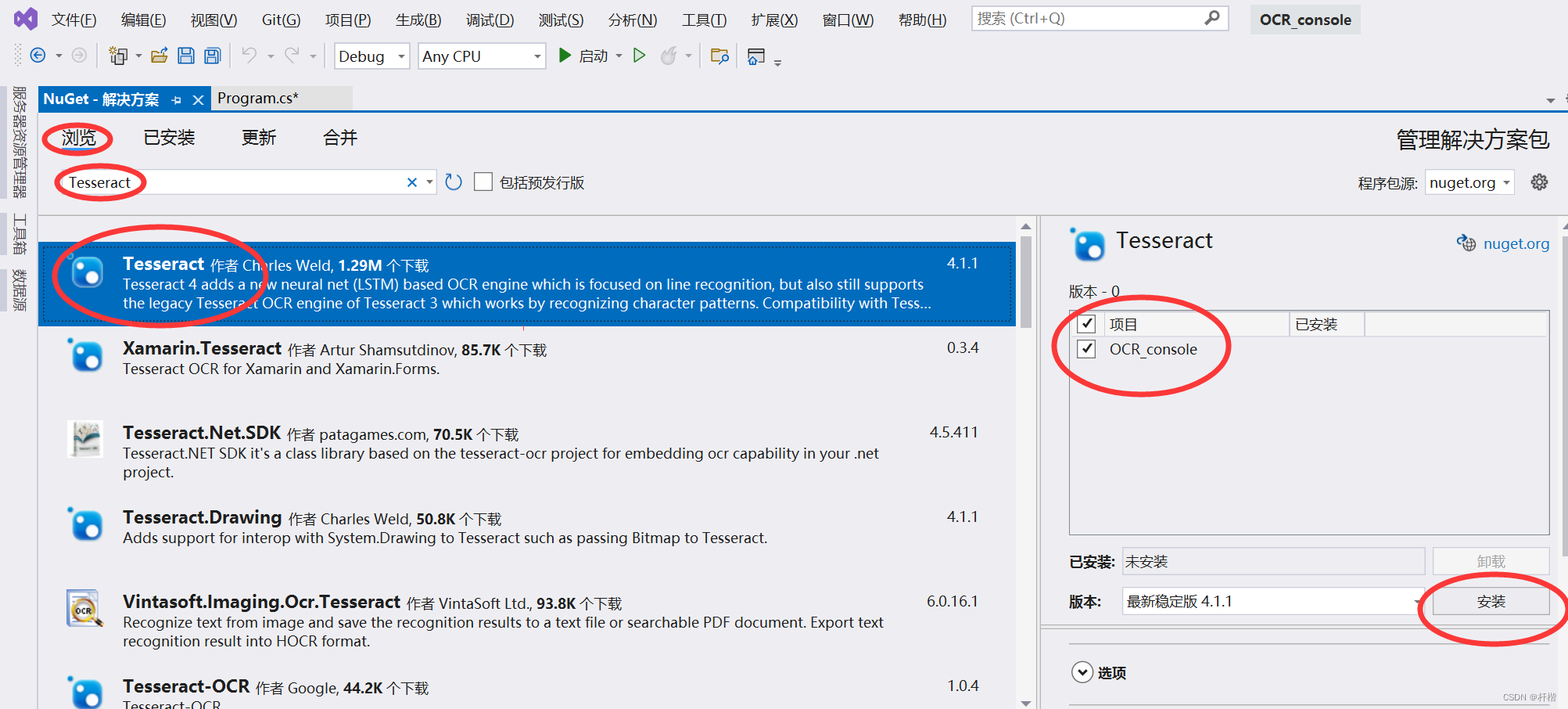
Tesseract OCR — движок распознавания текста для командной строки, автоматизации и интеграции в другие программы. Он не похож на обычный PDF-редактор: пользователь работает через команды, скрипты, обвязки или графические оболочки. Tesseract особенно полезен для разработчиков, администраторов, архивистов и тех, кто обрабатывает много однотипных изображений.
Документация Tesseract содержит список поддерживаемых языков и скриптов, а сам движок используется во многих бесплатных OCR-решениях. В связке с OCRmyPDF, Python, PowerShell или пакетными скриптами он превращается в мощный инструмент для автоматического распознавания папок с изображениями.
Что можно сделать в Tesseract OCR
-
распознать PNG, JPG, TIFF и другие изображения;
-
выбрать язык через параметр
-l; -
объединить несколько языков;
-
вывести результат в TXT;
-
встроить OCR в скрипт;
-
автоматизировать обработку папок;
-
использовать в локальном контуре без облака;
-
подключить предобработку изображений через ImageMagick, OpenCV или другие инструменты.
Инструкция
-
Установите Tesseract OCR.
-
Установите языковые данные для русского и английского.
-
Откройте командную строку.
-
Перейдите в папку с изображением.
-
Выполните команду вида
tesseract scan.png result -l rus+eng. -
Откройте файл
result.txt. -
Для PDF используйте OCRmyPDF или другой инструмент-обвязку.
-
Для папок напишите пакетный скрипт.
Плюсы
-
бесплатный и открытый движок;
-
работает локально;
-
удобен для автоматизации;
-
поддерживает много языков;
-
подходит для серверных сценариев;
-
используется в других OCR-программах.
Минусы
-
нет привычного интерфейса;
-
PDF требует дополнительных инструментов;
-
качество зависит от предобработки изображения;
-
новичку сложнее, чем в PDF Commander или NAPS2;
-
ручная проверка результата обязательна.
Tesseract — выбор для технических пользователей. Для обычного офиса проще NAPS2, PDF Commander или FineReader, а для массового OCR по расписанию Tesseract отлично подходит.
OneNote
OneNote — не классическая OCR-программа, а приложение для заметок, где распознавание текста встроено в работу с изображениями. Сценарий простой: вставляете картинку на страницу, нажимаете правой кнопкой мыши и выбираете Copy Text from Picture. Текст копируется в буфер обмена, после чего его можно вставить ниже, в Word, письмо или таблицу.
OneNote удобен для быстрых учебных и рабочих задач: скриншот из презентации, фото объявления, фрагмент книги, схема с подписью, слайд, изображение из PDF. Для договоров на десятки страниц лучше использовать PDF Commander, FineReader или Acrobat, но для одной картинки OneNote экономит время.
Что можно сделать в OneNote
-
вставить картинку и скопировать из нее текст;
-
хранить исходное изображение и текст рядом;
-
распознавать скриншоты и фотографии;
-
собирать конспекты с картинками;
-
переносить текст в Word или письмо;
-
использовать OCR без отдельного PDF-редактора.
Инструкция
-
Откройте OneNote.
-
Создайте страницу.
-
Вставьте изображение с текстом.
-
Нажмите по изображению правой кнопкой мыши.
-
Выберите Copy Text from Picture.
-
Вставьте текст ниже на страницу или в другой документ.
-
Проверьте переносы строк, знаки и цифры.
Плюсы
-
удобно для заметок и учебы;
-
не нужен отдельный OCR-редактор;
-
быстро копирует текст с картинки;
-
результат сразу хранится рядом с исходником;
-
подходит для скриншотов.
Минусы
-
нет профессиональной разметки страниц;
-
не предназначен для больших PDF;
-
качество хуже у сложных таблиц;
-
нет полноценного экспорта OCR-проекта.
OneNote стоит использовать как быстрый способ распознать один фрагмент, а не как основную программу для документооборота.
Capture2Text
Capture2Text — легкая Windows-утилита для распознавания текста прямо с экрана. Она полезна, когда текст находится не в файле, а в окне программы, на изображении, в видео, в скриншоте, в старом интерфейсе или на странице, где копирование недоступно. Пользователь выделяет прямоугольную область, утилита распознает символы и копирует результат в буфер обмена.
Главная ценность Capture2Text — скорость. Не нужно сохранять скриншот, открывать PDF-редактор и запускать OCR. Достаточно вызвать горячую клавишу, обвести область и вставить результат в заметку.
Что можно сделать в Capture2Text
-
распознать текст с любого участка экрана;
-
скопировать подпись из окна программы;
-
вытащить текст из скриншота;
-
распознать субтитры или надписи в видео;
-
работать через горячие клавиши;
-
отправить результат в буфер обмена.
Инструкция
-
Запустите Capture2Text.
-
Настройте язык распознавания.
-
Откройте изображение, окно или страницу с текстом.
-
Нажмите горячую клавишу захвата.
-
Выделите прямоугольную область.
-
Отпустите кнопку мыши.
-
Вставьте распознанный текст в нужное место.
Плюсы
-
очень быстрый захват текста;
-
работает с любым видимым участком экрана;
-
подходит для скриншотов и интерфейсов;
-
не требует подготовки PDF;
-
удобен для коротких фрагментов.
Минусы
-
не предназначен для многостраничных документов;
-
требует хорошего масштаба текста на экране;
-
таблицы и сложная верстка распознаются хуже;
-
ручная проверка обязательна.
Capture2Text — лучший вариант для задачи распознать текст на компьютере с экрана, когда источник нельзя нормально открыть или скопировать.
CuneiForm
CuneiForm — классическое OCR-решение для Windows, которое часто вспоминают как бесплатную программу для распознавания текста. Оно подходит для простых печатных документов, старых сканов и локальной обработки без облака. По современным меркам интерфейс выглядит устаревшим, зато программа понятна: открыть изображение, выбрать язык, запустить распознавание, сохранить текст.
CuneiForm не стоит ставить вместо FineReader или Acrobat для сложных PDF, но как резервный локальный инструмент для несложных страниц он остается полезным.
Что можно сделать в CuneiForm
-
распознать текст с картинки;
-
обработать сканированную страницу;
-
сохранить текстовый результат;
-
выбрать язык документа;
-
работать без интернет-сервиса;
-
использовать программу на старом компьютере.
Инструкция
-
Запустите CuneiForm.
-
Откройте отсканированное изображение.
-
Выберите язык распознавания.
-
Проверьте ориентацию страницы.
-
Запустите OCR.
-
Сверьте результат с оригиналом.
-
Сохраните текст в нужном формате.
Плюсы
-
бесплатное OCR-решение;
-
локальная работа;
-
подходит для старых ПК;
-
простой сценарий распознавания;
-
работает с печатными сканами.
Минусы
-
устаревший интерфейс;
-
слабее современных OCR-движков на сложной верстке;
-
плохо подходит для рукописного текста;
-
нет удобного современного PDF-цикла.
CuneiForm подходит как запасной вариант для простых сканов, особенно когда нужен локальный инструмент без подписок.
Программы для распознавания текста на macOS
ABBYY FineReader PDF для Mac
На macOS ABBYY FineReader PDF решает те же задачи, что и Windows-версия: распознает сканы, переводит PDF в Word и Excel, создает поисковые PDF, сохраняет структуру страницы и помогает работать с документами, где важна точность. Он подходит для юристов, бухгалтеров, преподавателей, студентов, переводчиков и специалистов, которые часто получают сканы вместо редактируемых файлов.
Особенно полезен сценарий с фотографиями документов: снимок с телефона открывается в FineReader, программа исправляет изображение и превращает его в searchable PDF или DOCX. ABBYY отдельно описывает такой подход для создания поискового PDF из фотографий документов.
Что можно сделать
-
распознать PDF и фото на Mac;
-
экспортировать в Word, Excel и searchable PDF;
-
сохранить структуру страниц;
-
проверить подозрительные символы;
-
обработать многостраничный документ.
Инструкция
-
Откройте FineReader PDF на Mac.
-
Добавьте файл через окно задач.
-
Выберите язык документа.
-
Запустите OCR.
-
Проверьте области: текст, таблицы, изображения.
-
Сохраните результат в нужном формате.
Плюсы
-
высокая точность;
-
удобен для сложной верстки;
-
сильный экспорт в офисные форматы;
-
подходит для профессиональной работы;
-
работает локально.
Минусы
-
платная программа;
-
для простых фото есть более быстрый Live Text;
-
требует времени на освоение;
-
избыточен для одного скриншота.
Adobe Acrobat Pro для Mac
Acrobat Pro на Mac подходит тем, кто работает с PDF как с основным форматом: подписывает, комментирует, защищает, отправляет клиентам, готовит документы к печати и архиву. OCR находится в разделе Scan & OCR, а результат остается в том же PDF-файле.
Что можно сделать
-
распознать сканированный PDF;
-
создать PDF с поисковым текстом;
-
редактировать распознанный текст;
-
экспортировать в Word;
-
объединить OCR с подписями и комментариями.
Инструкция
-
Откройте PDF в Acrobat Pro.
-
Перейдите в All tools.
-
Выберите Scan & OCR.
-
Нажмите Recognize Text.
-
Укажите язык и страницы.
-
Запустите обработку.
-
Проверьте результат поиском по документу.
Плюсы
-
профессиональная работа с PDF;
-
OCR встроен в редактор;
-
подходит для делового документооборота;
-
есть инструменты защиты и подписи;
-
удобен для финальной подготовки PDF.
Минусы
-
подписка;
-
тяжелый интерфейс;
-
для простого копирования текста быстрее Live Text;
-
сложные сканы требуют ручной проверки.
Readiris PDF для Mac
Readiris PDF для Mac удобен для перевода сканов в редактируемые форматы. Он подходит тем, кто часто получает отсканированные документы, но дальше работает в Word, Excel или PDF-редакторе. Программа делает акцент на конвертации и OCR, а не только на чтении PDF.
Что можно сделать
-
распознать PDF и изображения;
-
конвертировать в Word и Excel;
-
создать searchable PDF;
-
обрабатывать несколько документов;
-
сохранить структуру страниц.
Инструкция
-
Откройте Readiris PDF.
-
Добавьте документ.
-
Выберите язык OCR.
-
Укажите выходной формат.
-
Запустите распознавание.
-
Проверьте результат в Word или Excel.
Плюсы
-
удобная конвертация;
-
поддерживает пакетные задачи;
-
подходит для сканов;
-
работает на Mac;
-
полезен для офисных документов.
Минусы
-
требует привыкания;
-
сложные таблицы проверяются вручную;
-
не заменяет полноценный PDF-документооборот Acrobat;
-
для коротких фрагментов есть более простые способы.
TextSniper
TextSniper — macOS-приложение для OCR с экрана. Оно работает по принципу снимка области: пользователь нажимает сочетание клавиш, выделяет участок экрана, а распознанный текст попадает в буфер обмена. Это удобно для презентаций, видео, защищенных PDF, изображений в браузере, интерфейсов программ и скриншотов.
Что можно сделать
-
скопировать текст с любого участка экрана;
-
распознать фрагмент изображения;
-
вытащить надпись из видео или презентации;
-
быстро перенести текст в заметки;
-
работать без полноценного PDF-редактора.
Инструкция
-
Запустите TextSniper.
-
Нажмите заданное сочетание клавиш.
-
Выделите область с текстом.
-
Дождитесь распознавания.
-
Вставьте результат в заметку, письмо или документ.
Плюсы
-
очень быстрый OCR;
-
удобен для macOS;
-
работает с экраном, а не только с файлами;
-
не требует подготовки документа;
-
хорошо подходит для коротких фрагментов.
Минусы
-
не рассчитан на многостраничные PDF;
-
не сохраняет структуру сложных документов;
-
для таблиц нужен другой инструмент;
-
платное приложение.
Live Text в Просмотре на Mac
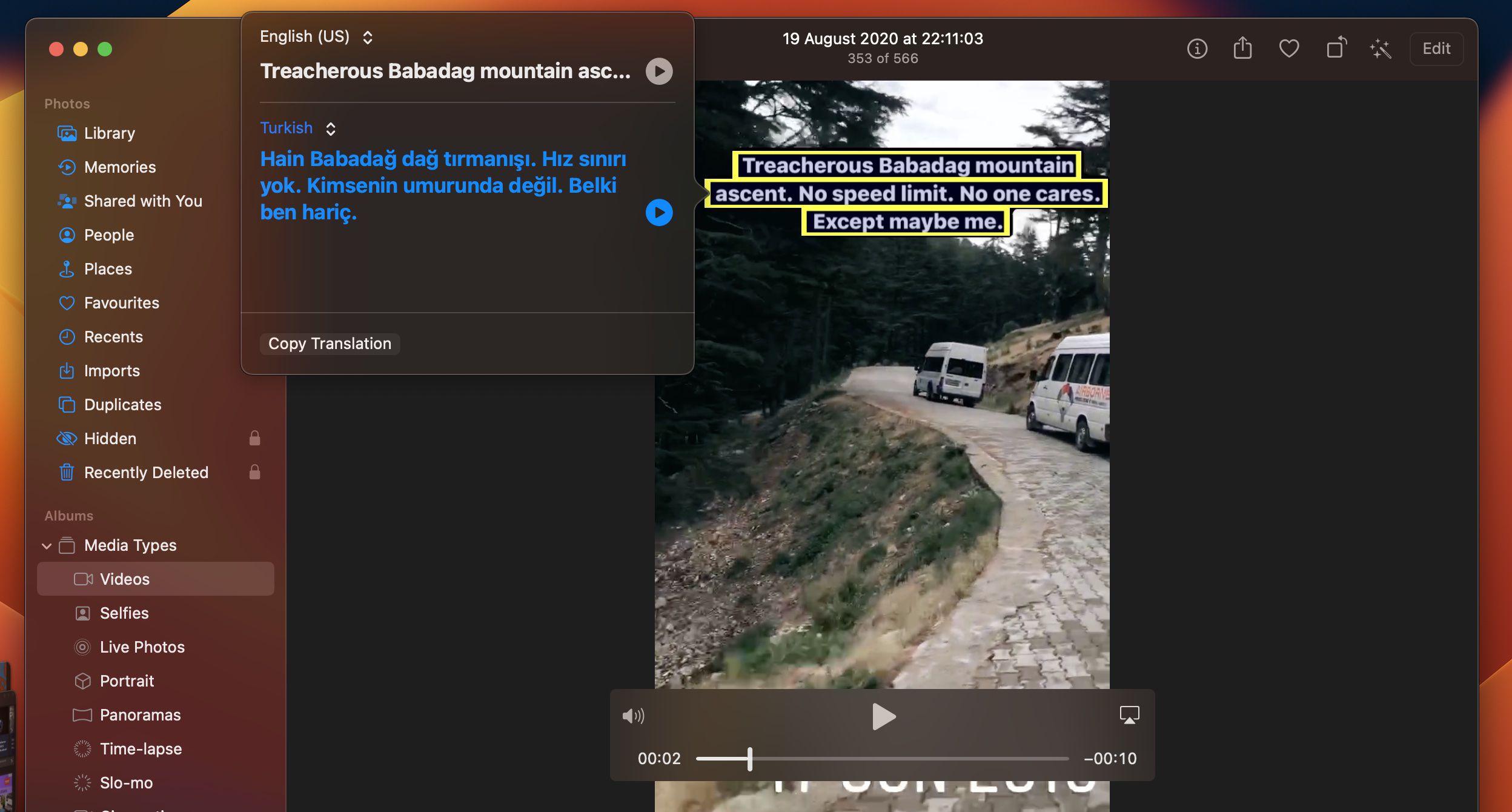
Live Text на Mac встроен в системные приложения Apple. В Просмотре можно открыть фото или изображение, выделить текст мышью, нажать Control-click и выбрать Copy Text. Также доступны поиск, перевод, переход по ссылке, работа с телефонными номерами и email-адресами.
Это не полноценная программа для распознавания PDF-архивов, а быстрый системный способ извлечь текст из картинки. Для фото объявления, номера телефона, фрагмента инструкции или снимка страницы он работает быстрее отдельного OCR-редактора.
Что можно сделать
-
скопировать текст из фотографии;
-
перевести выделенный фрагмент;
-
открыть сайт с изображения;
-
создать письмо по email на фото;
-
скопировать номер телефона;
-
быстро перенести данные в заметки.
Инструкция
-
Откройте изображение в Просмотре.
-
Наведите курсор на текст.
-
Выделите нужный фрагмент.
-
Нажмите Control-click.
-
Выберите Copy Text.
-
Вставьте результат в документ.
Плюсы
-
встроено в macOS;
-
работает без установки OCR-программы;
-
удобно для фото и скриншотов;
-
быстро копирует короткие фрагменты;
-
поддерживает быстрые действия с телефонами, ссылками и адресами.
Минусы
-
не заменяет OCR для больших PDF;
-
не дает тонкой настройки языка;
-
таблицы переносятся плохо;
-
доступность зависит от языка и региона.
Онлайн-сервисы для распознавания текста
Google Drive и Google Docs
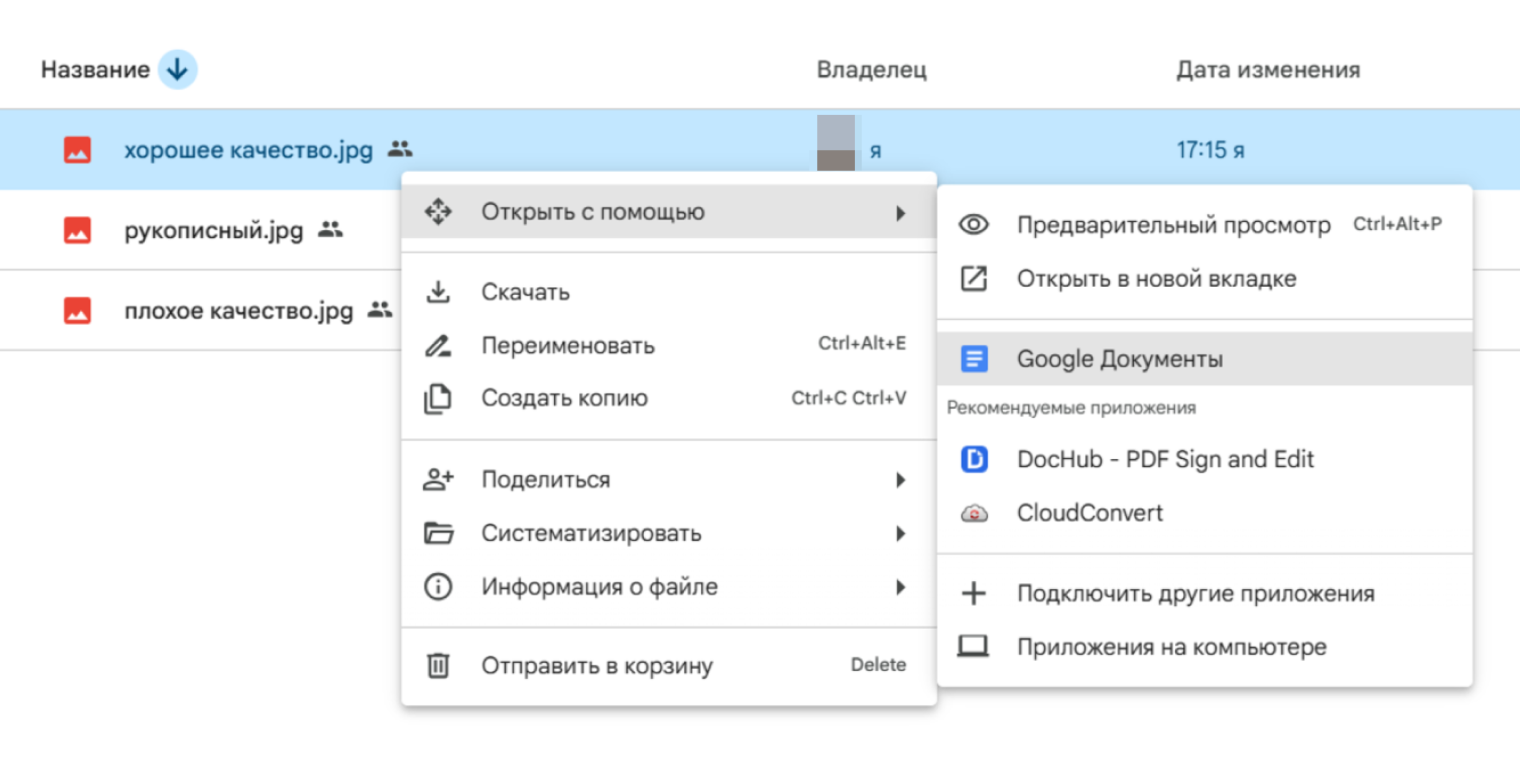
Google Drive и Google Docs — один из самых простых бесплатных способов распознать текст онлайн. Сценарий такой: загрузить PDF или изображение на Google Drive, нажать правой кнопкой мыши, выбрать Открыть с помощью и затем Google Документы. Google создаст документ, где сверху останется изображение, а ниже появится распознанный текст.
Этот способ хорош для быстрых задач, но не для конфиденциальных договоров и паспортных данных: файл загружается в облако. Google рекомендует использовать PDF или фотофайлы JPEG, PNG, GIF, держать документ в правильной ориентации и загружать изображения с достаточно крупным текстом.
Что можно сделать
-
распознать JPG, PNG, GIF и PDF;
-
получить редактируемый Google Docs;
-
скопировать текст в Word;
-
сохранить документ как DOCX;
-
быстро обработать один файл без установки программ.
Инструкция
-
Откройте Google Drive.
-
Нажмите Создать.
-
Выберите Загрузить файл.
-
Дождитесь загрузки PDF или изображения.
-
Нажмите по файлу правой кнопкой мыши.
-
Выберите Открыть с помощью → Google Документы.
-
Скопируйте или сохраните распознанный текст.
Плюсы
-
бесплатно;
-
работает в браузере;
-
не требует установки;
-
удобно для одиночных файлов;
-
результат сразу редактируется в Google Docs.
Минусы
-
файл загружается в облако;
-
есть ограничения по размеру и качеству;
-
сложная верстка теряется;
-
таблицы часто требуют ручной правки;
-
не подходит для конфиденциальных документов.
OnlineOCR
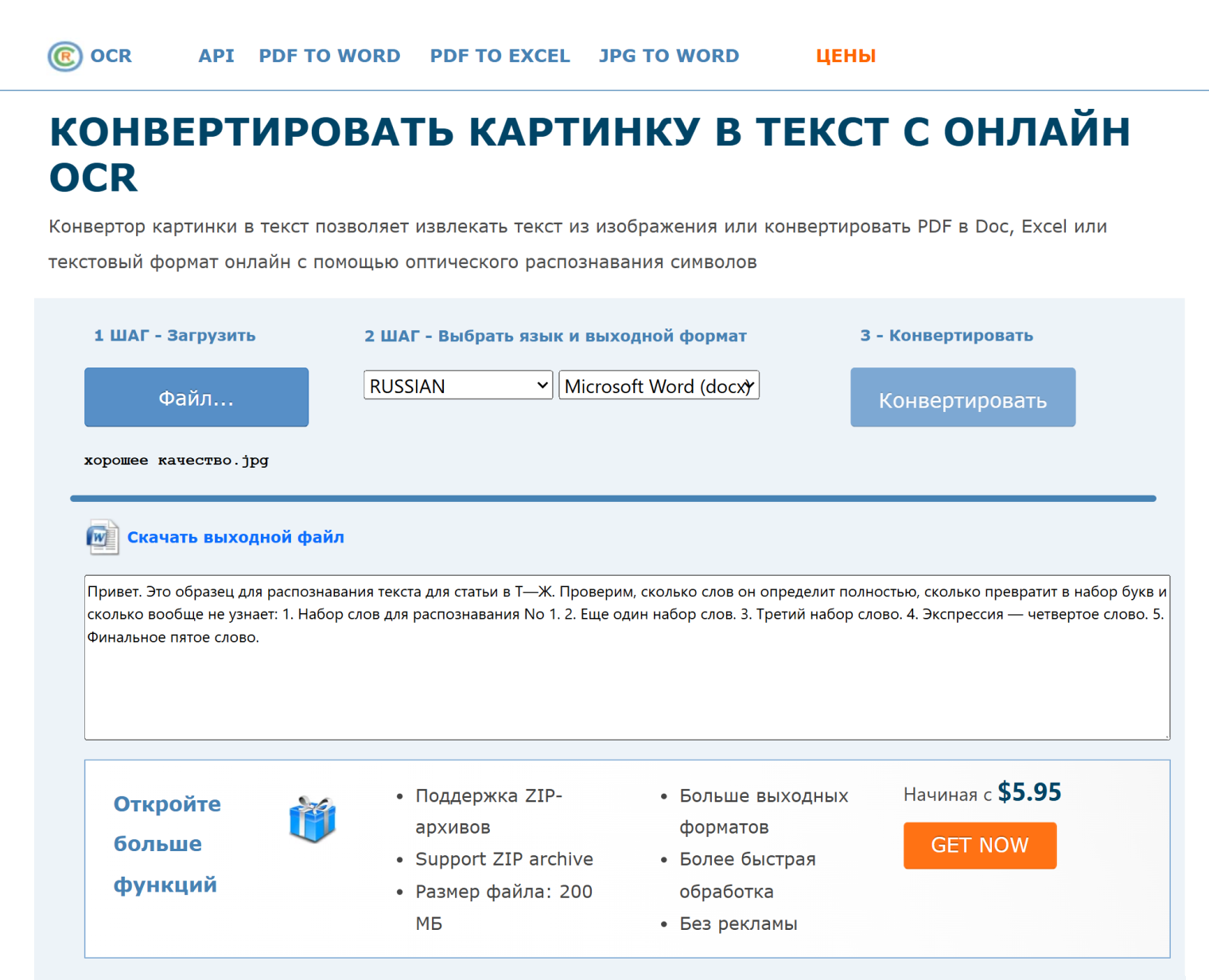
OnlineOCR — простой сервис для распознавания текста из PDF и изображений с экспортом в Word, Excel или TXT. Он удобен, когда нужно быстро распознать один скан без установки программы. Важно сразу выбрать правильный язык: при неверном языке сервис заменяет похожие символы, путает кириллицу и латиницу, ошибается в знаках.
Что можно сделать
-
загрузить PDF, JPG, PNG или другой файл;
-
выбрать язык документа;
-
получить Word, Excel или TXT;
-
скопировать распознанный текст;
-
быстро обработать один документ.
Инструкция
-
Откройте OnlineOCR.
-
Загрузите файл.
-
Выберите язык распознавания.
-
Укажите выходной формат.
-
Запустите конвертацию.
-
Скачайте результат.
-
Проверьте номера, даты и таблицы.
Плюсы
-
понятный интерфейс;
-
есть экспорт в Word и Excel;
-
подходит для быстрых задач;
-
не требует установки;
-
полезен для одиночных файлов.
Минусы
-
документы загружаются на сервер;
-
качество зависит от исходного файла;
-
рукописный текст распознается слабее;
-
сложная верстка переносится неточно.
OCR.space

OCR.space — онлайн-сервис и OCR API для изображений и PDF. Он интересен не только обычным пользователям, но и разработчикам: сервис возвращает распознанный текст, поддерживает параметры обработки и используется в интеграциях. В интерфейсе можно загрузить файл, выбрать язык, включить ориентацию, обработку таблиц, создание searchable PDF и выбрать OCR-движок.
Что можно сделать
-
распознать изображение или PDF;
-
получить текст в браузере;
-
создать searchable PDF;
-
использовать API;
-
включить автоопределение ориентации;
-
распознавать чеки и таблицы;
-
работать с результатом в JSON.
Инструкция
-
Откройте OCR.space.
-
Загрузите файл или вставьте ссылку на изображение.
-
Выберите язык.
-
Включите дополнительные параметры при необходимости.
-
Выберите режим результата.
-
Нажмите Start OCR.
-
Скопируйте текст или скачайте результат.
Плюсы
-
есть веб-интерфейс и API;
-
подходит для интеграций;
-
умеет создавать searchable PDF;
-
есть дополнительные настройки;
-
работает без установки.
Минусы
-
облачная обработка;
-
интерфейс сложнее, чем у OnlineOCR;
-
приватные документы лучше обрабатывать локально;
-
качество таблиц зависит от исходника.
PDF24 OCR
PDF24 OCR — онлайн-инструмент для создания PDF с распознанным текстом. Он удобен для задач, где нужен именно поисковый PDF, а не отдельный Word-файл. Пользователь загружает документ, выбирает язык, запускает OCR и скачивает готовый файл.
PDF24 хорошо дополняет локальные инструменты: для разовых PDF подходит браузер, для конфиденциальных файлов лучше PDF Commander, FineReader, Acrobat или NAPS2.
Что можно сделать
-
распознать PDF онлайн;
-
создать searchable PDF;
-
выбрать язык OCR;
-
обработать сканированный документ;
-
скачать готовый файл.
Инструкция
-
Откройте инструмент PDF24 OCR.
-
Загрузите PDF.
-
Выберите язык.
-
Настройте качество и выходной PDF.
-
Запустите OCR.
-
Скачайте файл.
-
Проверьте поиск по словам внутри PDF.
Плюсы
-
удобно для searchable PDF;
-
не требует установки;
-
интерфейс простой;
-
подходит для разовых задач;
-
работает в браузере.
Минусы
-
обработка идет онлайн;
-
не подходит для чувствительных документов;
-
редактировать текст удобнее в PDF-редакторе;
-
качество зависит от скана.
Smallpdf OCR
Smallpdf удобен пользователям, которым нужен быстрый онлайн-цикл: загрузить PDF, распознать, конвертировать в Word или получить файл с выбираемым текстом. Сервис проще профессиональных редакторов и хорошо подходит для разовых офисных задач.
Что можно сделать
-
загрузить сканированный PDF;
-
распознать текст;
-
конвертировать PDF в Word;
-
скачать результат;
-
использовать браузер без установки.
Инструкция
-
Откройте инструмент Smallpdf.
-
Перетащите PDF в окно загрузки.
-
Запустите OCR или конвертацию.
-
Дождитесь обработки.
-
Скачайте Word или PDF.
-
Проверьте структуру документа.
Плюсы
-
простой интерфейс;
-
удобно для PDF в Word;
-
работает в браузере;
-
подходит для разовых файлов;
-
не требует настройки.
Минусы
-
облачная загрузка документов;
-
бесплатный режим ограничен;
-
сложные таблицы требуют проверки;
-
для постоянной работы выгоднее настольная программа.
NewOCR
NewOCR — простой онлайн-сервис для распознавания текста с изображений и PDF. Он подходит для случаев, когда нужна быстрая расшифровка фрагмента, страницы или небольшого документа. Интерфейс проще, чем у профессиональных OCR-платформ: загрузка файла, выбор языка, запуск распознавания, копирование результата.
Что можно сделать
-
распознать JPG, PNG, PDF;
-
выбрать язык документа;
-
получить текст в браузере;
-
скопировать результат;
-
быстро обработать небольшую страницу.
Инструкция
-
Откройте NewOCR.
-
Загрузите файл.
-
Выберите язык.
-
Запустите OCR.
-
Скопируйте текст.
-
Проверьте ошибки и переносы строк.
Плюсы
-
простой онлайн-сценарий;
-
подходит для небольших файлов;
-
не требует установки;
-
быстро выдает текст;
-
полезен как запасной сервис.
Минусы
-
нет полноценного PDF-редактирования;
-
облачная обработка;
-
сложная верстка распознается хуже;
-
результат требует вычитки.
Приложения для распознавания текста на iPhone
Apple Live Text
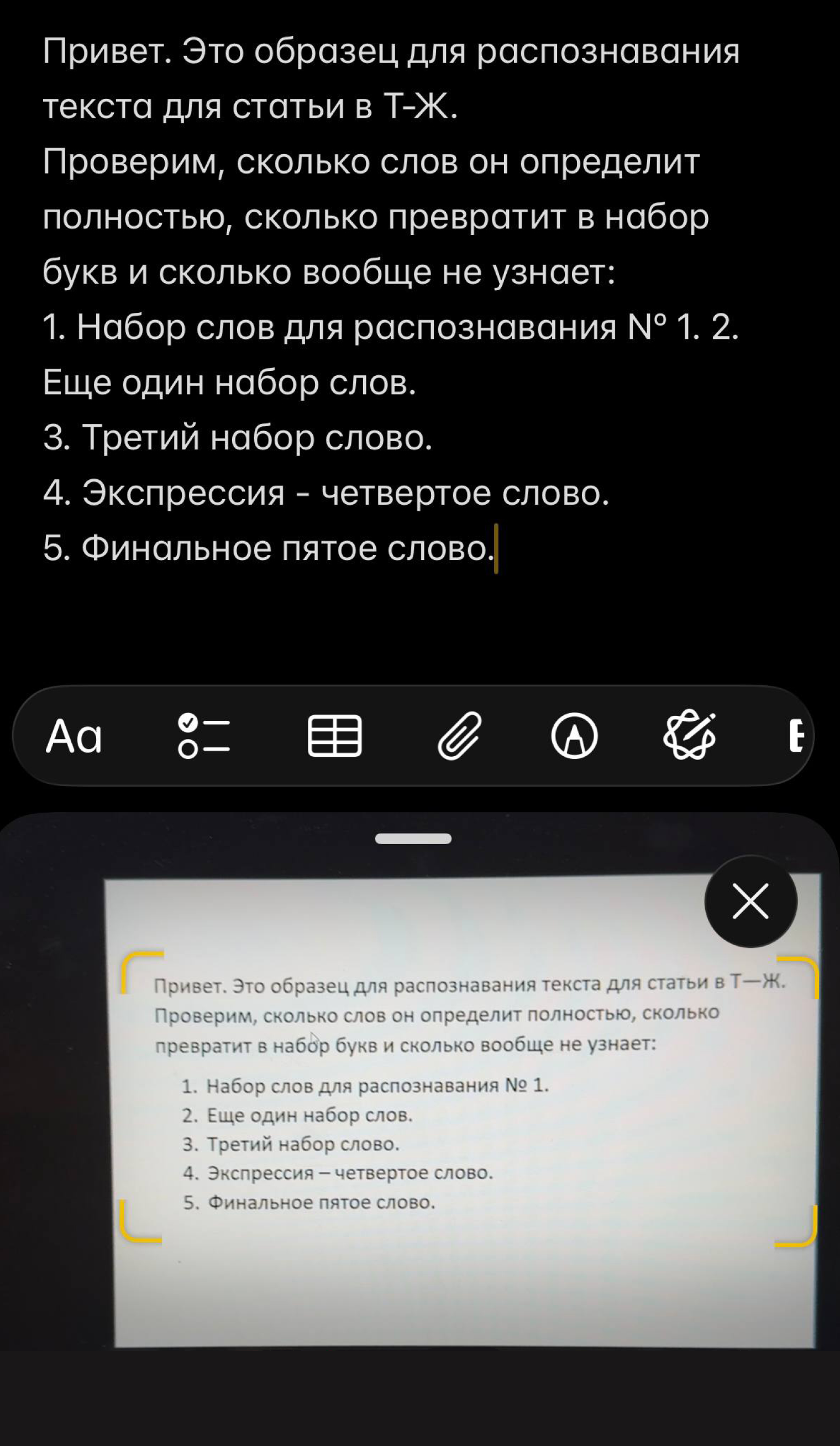
Apple Live Text встроен в iPhone и iPad. Через камеру можно копировать, искать, переводить и отправлять текст, который попал в кадр. В камере появляется желтая рамка вокруг найденного текста, затем нажимается кнопка распознавания, после чего доступны Copy, Select All, Look Up, Translate, Search Web и Share. Также система выполняет быстрые действия: звонок по номеру, переход на сайт, письмо по email и конвертация валют.
Live Text удобен для повседневных задач: афиша, визитка, объявление, номер телефона, адрес, надпись на упаковке, фрагмент книги, конспект, экран другого устройства. Для многостраничных PDF лучше Adobe Scan, CamScanner или FineReader.
Что можно сделать
-
скопировать текст из камеры;
-
выделить текст на фото;
-
перевести фрагмент;
-
перейти по ссылке;
-
позвонить по номеру с изображения;
-
вставить текст в Заметки, Сообщения или Почту.
Инструкция
-
Откройте Камера.
-
Наведите iPhone на текст.
-
Дождитесь желтой рамки.
-
Нажмите кнопку распознавания текста.
-
Выделите фрагмент.
-
Выберите Copy, Translate, Share или другое действие.
-
Вставьте текст в нужное приложение.
Плюсы
-
встроено в iPhone;
-
работает быстро;
-
не требует отдельного сканера;
-
удобно для коротких фрагментов;
-
поддерживает быстрые действия.
Минусы
-
не предназначено для пакетного OCR;
-
доступность зависит от языка и региона;
-
таблицы переносятся плохо;
-
для офисных PDF нужны отдельные приложения.
Adobe Scan

Adobe Scan превращает iPhone в мобильный сканер: приложение захватывает страницу, корректирует перспективу, улучшает вид документа, сохраняет PDF и применяет OCR. Adobe описывает Scan как инструмент, который исправляет перспективу, повышает резкость печатного и рукописного текста, удаляет блики и тени, а OCR превращает сканы в редактируемые и поисковые PDF.
Что можно сделать
-
отсканировать документ камерой;
-
автоматически обрезать страницу;
-
очистить тени и блики;
-
сохранить PDF;
-
распознать текст;
-
отправить файл в Acrobat;
-
работать с чеками, визитками, конспектами, договорами.
Инструкция
-
Откройте Adobe Scan.
-
Наведите камеру на документ.
-
Дождитесь автозахвата или нажмите кнопку съемки.
-
Проверьте границы страницы.
-
Сохраните скан.
-
Дождитесь OCR.
-
Откройте PDF, скопируйте текст или отправьте файл.
Плюсы
-
удобное мобильное сканирование;
-
автообрезка страниц;
-
улучшение качества изображения;
-
OCR для searchable PDF;
-
интеграция с Adobe Acrobat.
Минусы
-
нужен аккаунт Adobe;
-
часть функций связана с облаком;
-
для массовой офисной обработки удобнее настольная программа;
-
конфиденциальные документы требуют внимательного отношения к настройкам хранения.
CamScanner

CamScanner — популярный мобильный сканер с OCR, экспортом и синхронизацией. Он извлекает текст из изображений, поддерживает распознавание в десятках языков, позволяет сохранять PDF и JPEG, отправлять документы и работать с файлами на разных устройствах. CamScanner описывает функцию Extract Text как перевод текста из изображений в редактируемый вид и заявляет поддержку 41 языка.
Что можно сделать
-
сканировать документы телефоном;
-
улучшать качество страницы;
-
распознавать текст;
-
экспортировать PDF и JPEG;
-
извлекать текст из фото;
-
синхронизировать документы;
-
делиться ссылками и файлами.
Инструкция
-
Откройте CamScanner.
-
Нажмите кнопку камеры.
-
Снимите документ.
-
Проверьте и поправьте рамку обрезки.
-
Выберите фильтр улучшения.
-
Запустите OCR или Extract Text.
-
Сохраните PDF или скопируйте текст.
Плюсы
-
удобная камера-сканер;
-
есть OCR;
-
поддерживает много языков;
-
хорошо подходит для чеков, квитанций и страниц;
-
есть экспорт и синхронизация.
Минусы
-
облачные функции требуют внимания к приватности;
-
бесплатный режим ограничен;
-
сложные таблицы нужно проверять;
-
рукописный текст распознается нестабильно.
iScanner

iScanner подходит для пользователей, которым нужен мобильный сканер с быстрым созданием PDF, распознаванием текста, обработкой документов, удостоверений, чеков, конспектов и страниц книг. Приложение делает акцент на простом сценарии: сфотографировать страницу, обрезать, улучшить, сохранить и извлечь текст.
Что можно сделать
-
сканировать бумажные документы;
-
распознавать текст;
-
сохранять PDF;
-
работать с удостоверениями и чеками;
-
объединять страницы;
-
отправлять документы из телефона.
Инструкция
-
Откройте iScanner.
-
Выберите режим сканирования.
-
Наведите камеру на страницу.
-
Сделайте снимок.
-
Проверьте границы.
-
Запустите OCR.
-
Сохраните PDF или скопируйте текст.
Плюсы
-
удобен для iPhone;
-
подходит для быстрых сканов;
-
есть обработка изображения;
-
можно собирать многостраничные документы;
-
сценарий понятен новичку.
Минусы
-
часть функций платная;
-
облачные функции требуют контроля;
-
таблицы и плохие снимки требуют проверки;
-
для сложных PDF лучше настольный OCR.
Google Lens на iPhone через Google Photos

Google Lens на iPhone удобен для копирования и перевода текста с фотографий. Обычно он используется через Google Photos или Google app: открываете фото, нажимаете значок Lens, выделяете текст и копируете его. Для быстрого перевода вывески, инструкции, упаковки, объявления или визитки это один из самых удобных мобильных способов.
Что можно сделать
-
скопировать текст с фото;
-
перевести текст;
-
найти информацию по изображению;
-
распознать адрес, ссылку, телефон;
-
перенести фрагмент в заметки.
Инструкция
-
Откройте Google Photos.
-
Выберите фотографию с текстом.
-
Нажмите значок Google Lens.
-
Перейдите к текстовому режиму.
-
Выделите нужный фрагмент.
-
Нажмите копирование или перевод.
Плюсы
-
удобно для фото;
-
хорошо подходит для перевода;
-
быстро распознает короткие фрагменты;
-
работает с визитками, объявлениями и упаковками;
-
не требует PDF-редактора.
Минусы
-
нужен Google-сервис;
-
не лучший вариант для многостраничных PDF;
-
таблицы переносятся плохо;
-
облачная обработка не подходит для чувствительных документов.
Приложения для распознавания текста на Android
Google Lens
Google Lens на Android — быстрый способ распознать текст камерой или из уже готового фото. Lens умеет выполнять действия по содержимому изображения, а текст переводится средствами Google Translate. Для Android это один из самых простых вариантов: открыть Lens, навести камеру, перейти в режим текста, выделить фрагмент и скопировать его.
Что можно сделать
-
распознать текст камерой;
-
скопировать текст из фото;
-
перевести надпись;
-
открыть сайт с изображения;
-
сохранить данные визитки;
-
использовать распознавание через Google Photos.
Инструкция
-
Откройте Google Lens или Google Photos.
-
Наведите камеру на текст или выберите фото.
-
Перейдите в режим текста.
-
Выделите фрагмент.
-
Нажмите копирование, перевод или поиск.
-
Вставьте текст в нужное приложение.
Плюсы
-
встроен в экосистему Google;
-
быстро работает с камерой;
-
удобен для перевода;
-
распознает текст на фото;
-
подходит для бытовых задач.
Минусы
-
не заменяет PDF-сканер;
-
многостраничные документы неудобны;
-
облачная обработка;
-
сложные таблицы распознаются плохо.
Adobe Scan для Android
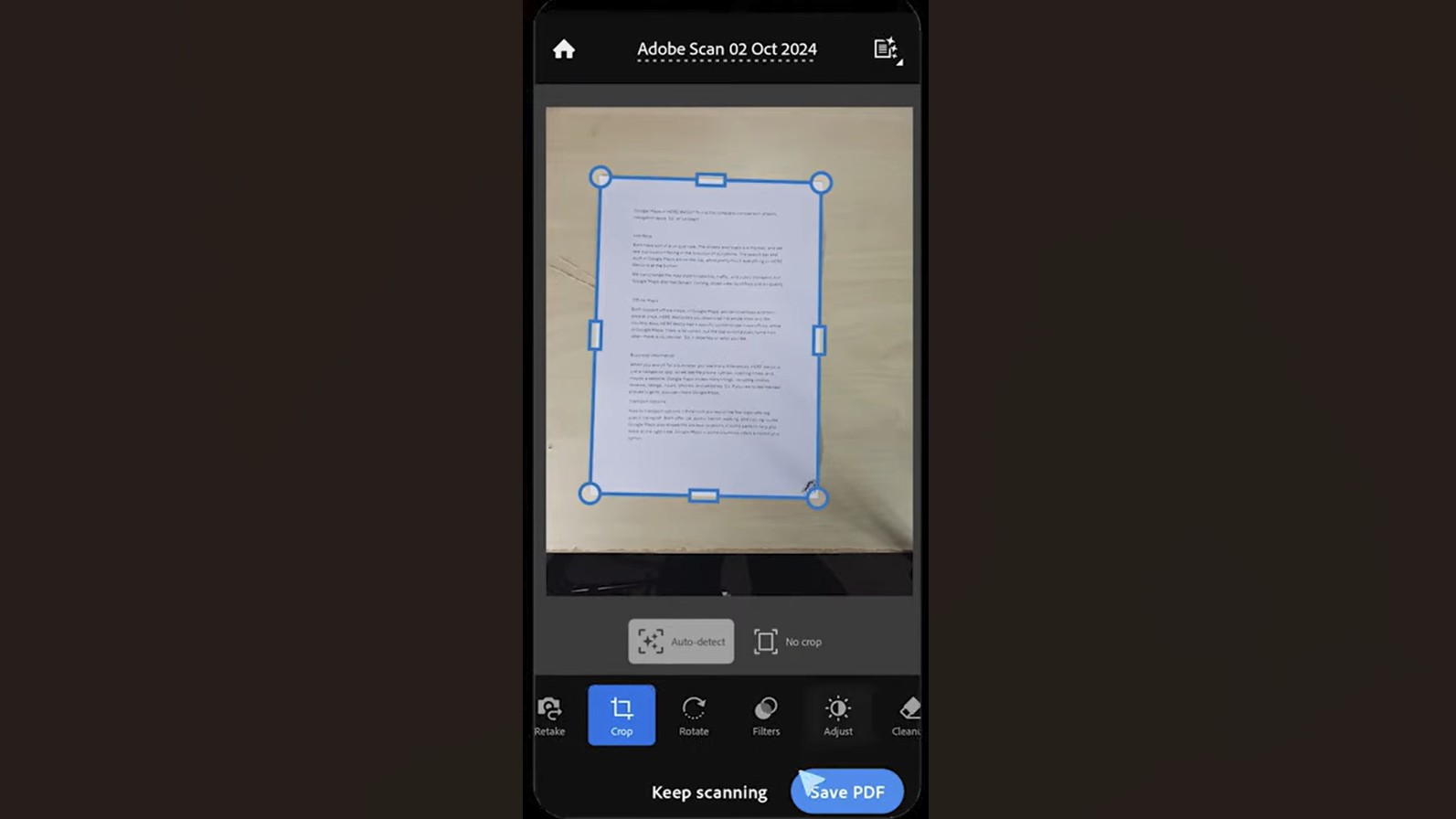
Adobe Scan на Android работает как полноценный мобильный сканер: захватывает страницу, выравнивает перспективу, очищает изображение и сохраняет PDF с распознанным текстом. В Google Play приложение описано как бесплатный PDF-сканер, который сохраняет и организует бумажные документы в цифровые файлы, а также включает инструменты очистки сканов.
Что можно сделать
-
сканировать документы камерой Android;
-
сохранять PDF;
-
распознавать текст;
-
улучшать качество страницы;
-
убирать дефекты;
-
отправлять документ в Adobe Acrobat.
Инструкция
-
Откройте Adobe Scan.
-
Наведите камеру на документ.
-
Сделайте снимок или дождитесь автозахвата.
-
Проверьте границы.
-
Примените улучшение.
-
Сохраните PDF.
-
Откройте распознанный текст.
Плюсы
-
хороший мобильный сканер;
-
автозахват и автообрезка;
-
OCR для PDF;
-
интеграция с Adobe;
-
подходит для чеков и документов.
Минусы
-
нужен аккаунт;
-
часть функций работает через облако;
-
большой архив удобнее обрабатывать на ПК;
-
требуются проверки на плохих снимках.
CamScanner для Android

CamScanner на Android подходит для пользователей, которые часто фотографируют документы телефоном: счета, накладные, конспекты, квитанции, удостоверения, книги, заявления. OCR-функция распознает текст в изображениях и PDF, после чего его можно искать, редактировать или отправлять.
Что можно сделать
-
сфотографировать документ;
-
обрезать и улучшить страницу;
-
применить фильтры;
-
распознать текст;
-
сохранить PDF или JPEG;
-
отправить файл ссылкой или вложением;
-
синхронизировать архив.
Инструкция
-
Запустите CamScanner.
-
Нажмите кнопку сканирования.
-
Снимите документ.
-
Поправьте рамку.
-
Выберите фильтр.
-
Запустите Text Recognition или Extract Text.
-
Сохраните результат.
Плюсы
-
удобен для мобильного архива;
-
OCR встроен в приложение;
-
поддерживает много языков;
-
есть экспорт и обмен;
-
работает с PDF и изображениями.
Минусы
-
бесплатный режим ограничен;
-
облачная синхронизация требует контроля;
-
сложные документы нужно сверять;
-
для конфиденциальных бумаг лучше локальный ПК-инструмент.
Text Fairy
Text Fairy — простое Android-приложение для распознавания текста с изображений. Оно полезно для книг, листовок, объявлений, распечаток, учебных материалов и фотографий страниц. Главная идея — получить обычный текст из снимка без сложного PDF-редактора.
Что можно сделать
-
распознать текст с фото;
-
выбрать язык;
-
скопировать результат;
-
исправить текст вручную;
-
сохранить или отправить распознанный фрагмент.
Инструкция
-
Откройте Text Fairy.
-
Сделайте фото или выберите изображение.
-
Обрежьте область с текстом.
-
Укажите язык.
-
Запустите распознавание.
-
Проверьте результат.
-
Скопируйте текст.
Плюсы
-
простое приложение;
-
подходит для Android;
-
работает с фотографиями;
-
удобно для коротких текстов;
-
не перегружено PDF-функциями.
Минусы
-
не лучший выбор для сложных PDF;
-
таблицы переносятся плохо;
-
качество зависит от камеры и света;
-
рукописный текст требует серьезной правки.
OneDrive Scan
OneDrive Scan стоит рассматривать как замену Microsoft Lens. Microsoft объявила, что приложение Microsoft Lens выводится из эксплуатации на iOS и Android с 9 января 2026 года и перестает поддерживаться после 9 февраля 2026 года. Для пользователей Microsoft 365 логичный сценарий — сканировать документы через OneDrive, сохранять их в облачную папку и дальше работать с PDF на компьютере.
Что можно сделать
-
сканировать документы телефоном;
-
сохранять файлы в OneDrive;
-
создавать PDF;
-
передавать документы на компьютер;
-
хранить сканы рядом с рабочими файлами Microsoft 365.
Инструкция
-
Откройте OneDrive на телефоне.
-
Нажмите кнопку добавления.
-
Выберите сканирование.
-
Наведите камеру на документ.
-
Сделайте снимок и поправьте границы.
-
Сохраните файл в нужную папку.
-
Откройте PDF на компьютере для дальнейшего OCR или редактирования.
Плюсы
-
удобно для пользователей Microsoft 365;
-
сканы сразу попадают в облачную папку;
-
подходит для рабочего документооборота;
-
заменяет базовое мобильное сканирование Lens;
-
доступно на iPhone и Android.
Минусы
-
нет прежнего набора функций Microsoft Lens;
-
хранение завязано на OneDrive;
-
для продвинутого OCR нужен отдельный инструмент;
-
локальное хранение организовано менее удобно, чем в самостоятельных сканерах.
Как улучшить качество распознавания текста
OCR ошибается не только из-за программы. Чаще проблема в исходнике: кривой снимок, тени, размытые буквы, низкое разрешение, сильное JPEG-сжатие, мелкий шрифт, заломы бумаги, фон с текстурой, блики от лампы, рукописные вставки, печати поверх текста.
Для лучшего результата используйте такие правила:
-
сканируйте бумагу при хорошем освещении;
-
держите камеру параллельно листу;
-
убирайте тени от рук и телефона;
-
не фотографируйте документ под углом;
-
выбирайте 300 DPI для обычных бумажных документов;
-
перед OCR поворачивайте страницу правильно;
-
выбирайте язык документа вручную;
-
для русского и английского текста включайте оба языка;
-
не сжимайте изображение перед распознаванием;
-
таблицы проверяйте по строкам и столбцам;
-
номера договоров, ИНН, суммы и даты сверяйте вручную;
-
сохраняйте исходный скан до финального редактирования.
Для плохих сканов помогает предобработка: повышение контраста, перевод в черно-белый режим, удаление шума, исправление перспективы, обрезка пустых полей, выравнивание страницы. В NAPS2 такие параметры вынесены в настройки OCR: режим Fast или Best, исправление белого баланса, удаление шума и автоматический запуск OCR после сканирования.
Что выбрать для разных задач
| Задача | Лучший выбор |
|---|---|
| Распознать PDF на Windows и сразу отредактировать | PDF Commander |
| Максимальная точность на договорах и таблицах | ABBYY FineReader PDF |
| OCR внутри полного PDF-документооборота | Adobe Acrobat Pro |
| Бесплатное сканирование и searchable PDF | NAPS2 |
| Автоматизация OCR и обработка папок | Tesseract OCR |
| Быстро скопировать текст с картинки в заметку | OneNote |
| Текст с экрана Windows | Capture2Text |
| Текст с экрана Mac | TextSniper |
| Быстро распознать онлайн без установки | OnlineOCR, OCR.space, PDF24 OCR |
| PDF в Word через браузер | Smallpdf, Google Docs |
| Сканирование телефоном на iPhone | Apple Live Text, Adobe Scan, CamScanner |
| Сканирование телефоном на Android | Google Lens, Adobe Scan, CamScanner, Text Fairy |
| Документы Microsoft 365 после ухода Lens | OneDrive Scan |
Итог
Для Windows первым стоит рассмотреть PDF Commander: он закрывает базовый и самый частый сценарий — открыть сканированный PDF, распознать русский или английский текст, выбрать страницы, затем сразу продолжить работу с PDF. Для максимальной точности и сложной верстки лучше подходит ABBYY FineReader PDF. Для компаний, где PDF нужно подписывать, комментировать, защищать и редактировать, логичен Adobe Acrobat Pro.
Для бесплатного локального OCR выбирайте NAPS2, особенно когда нужно сканировать бумаги и сохранять поисковые PDF. Для автоматизации и серверной обработки лучше Tesseract. Для быстрых фрагментов с экрана — Capture2Text на Windows и TextSniper на Mac. Для телефона удобнее всего встроенные и мобильные инструменты: Apple Live Text, Google Lens, Adobe Scan и CamScanner.
Главное правило: чем важнее документ, тем меньше стоит полагаться на полностью автоматический результат. OCR отлично экономит время, но суммы, даты, ФИО, номера договоров, реквизиты и строки таблиц всегда нужно сверять с исходником.