
Синтез речи давно перестал быть экспериментом из лаборатории. Он работает в навигаторах, электронных книгах, голосовых помощниках, экранных дикторах, сервисах доставки, банковских автоинформаторах, образовательных курсах и видеороликах. Когда приложение читает статью вслух, сообщает время прибытия такси или формирует закадровую дорожку по сценарию, оно использует один и тот же базовый принцип: получает текст, анализирует его и создаёт звуковую волну с человеческой речью.
Современная технология TTS умеет работать не только с отдельными словами. Она распознаёт границы предложений, учитывает знаки препинания, преобразует числа в словесную форму, выбирает произношение сокращений, расставляет паузы и строит интонацию. Нейросетевые модели делают голос заметно естественнее прежних роботизированных дикторов. При этом итоговое качество зависит не только от выбранного сервиса. Большую роль играет подготовка сценария: длина фраз, расстановка пауз, проверка ударений и корректная запись имён, дат и обозначений.
Ниже разобраны устройство синтеза речи, этапы развития технологии, причины неестественного звучания и шесть практических способов получить озвучку: чтение страницы в Microsoft Edge, системная настройка Android, Yandex SpeechKit Playground, SaluteSpeech App, ElevenLabs Text to Speech и Microsoft Audio Content Creation. Для более узкой практической задачи также пригодится отдельное руководство о том, как сделать озвучку для видео самостоятельно.
Что такое синтез речи простыми словами
Синтез речи — это автоматическое создание голосового аудио по написанному тексту. Англоязычное обозначение технологии — Text-to-Speech, сокращённо TTS. На вход система получает буквы, цифры, знаки препинания и служебную разметку. На выходе формируется звуковой сигнал, который можно воспроизвести сразу или сохранить в аудиофайл.
Простейший пример — чтение веб-страницы браузером. Пользователь открывает статью, запускает голосовое воспроизведение и слушает текст вместо чтения с экрана. Более сложный пример — подготовка закадровой дорожки для ролика. Автор вставляет сценарий, выбирает голос, регулирует темп, исправляет ударения, добавляет паузы, прослушивает результат и сохраняет WAV или MP3 для дальнейшего монтажа.
Синтезатор речи не читает буквы по одной. Между текстом и звуком проходит несколько этапов обработки. Система разбирает предложение, преобразует написание в фонетическое представление, строит длительность звуков, определяет паузы, создаёт акустическую модель фразы и только затем формирует слышимую речь.
Основные термины
| Термин | Что означает | Пример |
|---|---|---|
| TTS | Преобразование текста в голос | Озвучивание статьи или инструкции |
| STT | Преобразование речи в текст | Расшифровка интервью |
| ASR | Автоматическое распознавание речи | Голосовой ввод в приложении |
| Голосовой движок | Компонент, который создаёт речь | Системный диктор смартфона |
| Просодия | Ритм, паузы, темп, высота тона и интонация | Вопросительная интонация в конце фразы |
| Фонема | Минимальная звуковая единица языка | Различие звуков в похожих словах |
| Вокодер | Компонент, который превращает акустическое представление в звуковую волну | Формирование финального аудио |
| SSML | Разметка для управления произношением | Пауза, ударение, темп и смена голоса |
| Клонирование голоса | Создание цифровой модели конкретного диктора | Фирменный голос бренда с разрешения владельца |
| Voice conversion | Изменение уже записанной речи | Перенос тембра на готовую реплику |
Чем TTS отличается от распознавания речи и изменения голоса
Технологии обработки речи часто смешивают, хотя они решают разные задачи.
Синтез речи создаёт аудио по тексту. Сценарий уже написан, а система должна произнести его выбранным голосом.
Распознавание речи работает в обратную сторону: получает микрофонную запись или аудиофайл и превращает речь в текст. Эта технология нужна для субтитров, расшифровки встреч, голосового ввода и поиска по записям.
Голосовой помощник совмещает несколько компонентов. Он принимает речь пользователя, распознаёт её, определяет смысл команды, формирует ответ и произносит его через TTS.
Клонирование голоса создаёт цифровую модель конкретного человека по образцам речи. После обучения модель озвучивает новые фразы узнаваемым тембром. Для такой работы требуется разрешение владельца голоса.
Voice conversion меняет уже записанную реплику. Слова и интонационный рисунок исходной записи сохраняются, а тембр преобразуется. Для отдельной практической задачи пригодится руководство о том, как поменять голос на видео.
Где применяется синтез речи
Озвучивание текста нужно не только для голосовых помощников. У технологии десятки бытовых и профессиональных сценариев.
Доступность интерфейсов
Экранные дикторы помогают людям с нарушениями зрения работать со смартфоном и компьютером. Система читает пункты меню, кнопки, уведомления, содержимое страницы и текст документов. TTS также полезен людям, которым тяжело долго читать с экрана, и тем, кто лучше воспринимает информацию на слух.
Навигаторы и транспортные приложения
Навигатор не хранит заранее записанную реплику для каждого адреса. Он формирует фразу динамически: сообщает название улицы, расстояние до поворота, номер съезда и предупреждение о перестроении. Синтез речи позволяет быстро произнести новый маршрут без участия диктора.
Колл-центры и голосовые меню
Телефонный робот озвучивает статус заказа, сумму задолженности, время визита, код подтверждения или состояние заявки. В отличие от набора заранее записанных файлов, TTS умеет произносить персональные данные и новые формулировки, которые создаются в момент звонка.
Обучение и электронные книги
Синтезатор речи превращает конспект, статью или учебный материал в аудиоверсию. Ученик слушает текст в дороге, повторяет термины и быстрее замечает ошибки в собственном сценарии. Для длинных материалов важны стабильный темп, предсказуемые паузы и точное чтение фамилий, дат и обозначений.
Видео, подкасты и презентации
TTS применяют для черновой дорожки, обучающих роликов, демонстраций интерфейса, коротких вертикальных видео, локализации и голосовых подсказок. При работе с видео полезно заранее выбрать формат дорожки, потому что WAV удобнее для монтажа, а MP3 занимает меньше места. Подборка программ для озвучивания видео пригодится для сравнения рабочих инструментов.
Анимация и игровые прототипы
В производстве мультфильма или игры синтезатор помогает быстро проверить длительность реплик и ритм сцены. Черновые голоса заменяют временные записи разработчиков, пока финальная озвучка ещё не готова. Для домашнего проекта можно отдельно разобрать, как озвучить мультфильм самостоятельно.
Голосовые уведомления
Сервисы доставки, банки, медицинские центры и корпоративные системы формируют короткие сообщения автоматически. В них меняются имя, номер заказа, дата, сумма и адрес. Синтез речи снижает объём ручной записи и ускоряет обновление текста.
Как работает синтез речи: путь от текста до звука
Современный TTS-конвейер состоит из нескольких этапов. Конкретная реализация зависит от модели, но общая логика сохраняется: текст очищается, преобразуется в фонетическое представление, дополняется просодией и превращается в аудио.
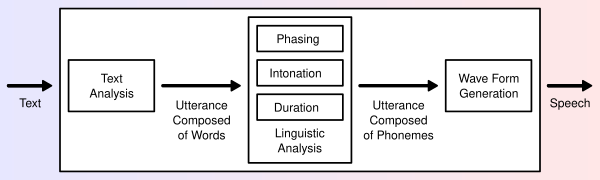
Упрощённая схема: текст проходит лингвистический разбор, после чего акустическая часть формирует слышимую речь.
Этап 1. Нормализация текста
На первом этапе система приводит запись к форме, которую можно произнести. Для человека строка 12.05.2026 понятна визуально, но голосовой движок должен определить, что перед ним дата, и произнести её словами. То же самое относится к суммам, процентам, телефонным номерам, адресам, сокращениям и единицам измерения.
Нормализатор анализирует контекст. Число 2026 в дате, номере заказа и техническом обозначении читается по-разному. Строка 10:30 обычно означает время. Запись 5 кг требует согласования числительного и единицы измерения. Аббревиатура может произноситься по буквам, как слово или в полной форме.
| Исходная запись | Задача системы | Возможное произношение |
|---|---|---|
| 12.05.2026 | Распознать дату | двенадцатого мая две тысячи двадцать шестого года |
| 10:30 | Распознать время | десять часов тридцать минут |
| 15% | Распознать процент | пятнадцать процентов |
| 5 кг | Согласовать число и единицу | пять килограммов |
| 8 800 555-35-35 | Разбить телефон на удобные группы | восемь восемьсот, пятьсот пятьдесят пять, тридцать пять, тридцать пять |
| 3D | Выбрать чтение букв и цифры | три дэ |
| 2500 ₽ | Распознать сумму | две тысячи пятьсот рублей |
Даже хорошая модель ошибается, когда запись неоднозначна. Поэтому в финальном сценарии важные числа лучше записывать так, как они должны прозвучать. Для телефонного номера полезно заранее разбить цифры на группы. Для сложного сокращения стоит выбрать единый вариант произношения во всём тексте.
Этап 2. Разбор структуры предложения
После нормализации система определяет границы предложений и смысловые части. Пунктуация помогает понять, где поставить короткую паузу, где завершить мысль, а где поднять интонацию. Запятая, точка, двоеточие и вопросительный знак влияют на звучание по-разному.
На этом же этапе учитывается контекст слов. В русском языке встречаются омографы: написание совпадает, но ударение меняет значение. Модель должна отличить замок как строение от замка в двери, муку от муки, атлас от атласа. В сложном материале такие места проверяются вручную.
Этап 3. Преобразование графем в фонемы
Буквы и звуки не совпадают один к одному. Одна и та же буква произносится по-разному в зависимости от соседних звуков, положения в слове и ударения. Технология grapheme-to-phoneme, сокращённо G2P, преобразует написание в фонетическую последовательность.
Фонетическая запись особенно важна для имён, географических названий, иностранных брендов и профессиональной терминологии. Когда сервис поддерживает фонемные подсказки, автор может задать произношение вручную и не менять видимый текст сценария.
Этап 4. Построение просодии
Одних правильных фонем недостаточно. Фраза без ритма и пауз звучит механически. Просодическая часть определяет:
-
длительность звуков;
-
положение пауз;
-
скорость произношения;
-
высоту основного тона;
-
логические акценты;
-
интонацию завершённости;
-
вопросительный рисунок;
-
эмоциональную окраску.
Человек обычно произносит заголовок, инструкцию и рекламный слоган по-разному. Хорошая модель учитывает тип предложения и контекст. При профессиональной подготовке автор дополнительно регулирует темп и паузы разметкой или средствами интерфейса.
Этап 5. Создание акустического представления
Далее модель строит акустическое представление будущей фразы. Часто используется мел-спектрограмма: изображение, на котором по горизонтали идёт время, по вертикали — частоты, а интенсивность показывает энергию сигнала.
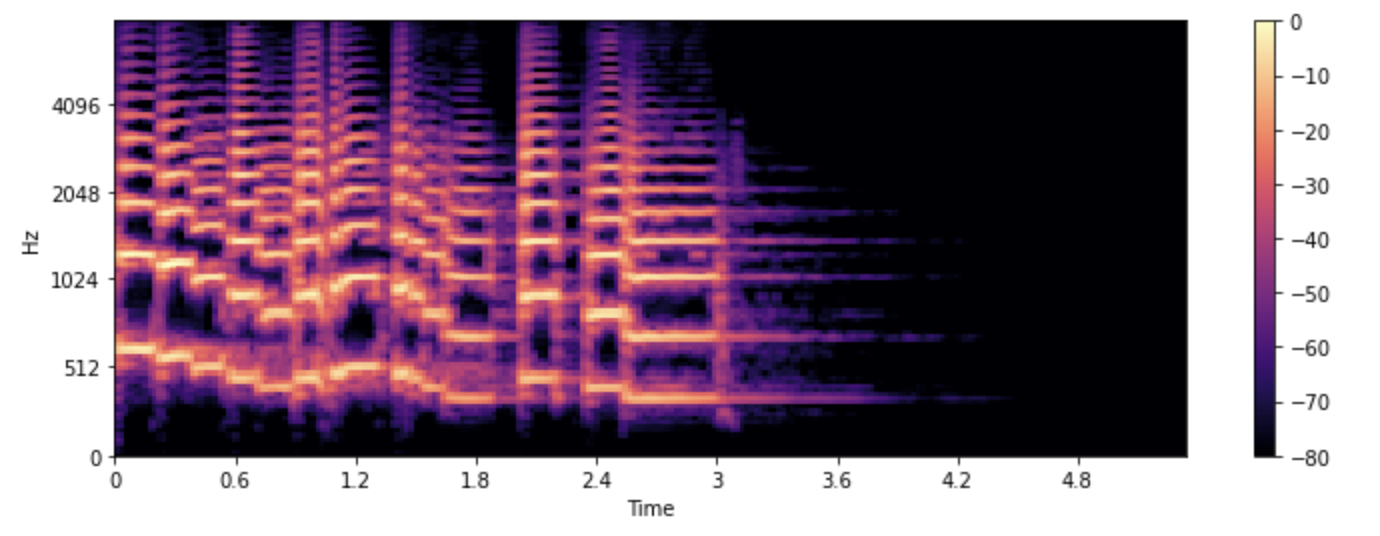
Спектрограмма показывает, как распределяется энергия речи во времени и по частотам.
Модель должна предсказать не только набор звуков, но и плавные переходы между ними. В реальной речи соседние фонемы влияют друг на друга. Артикуляция меняется непрерывно, поэтому неудачная склейка слышна как щелчок, рывок или странное окончание слова.
Этап 6. Работа вокодера
Вокодер превращает акустическое представление в звуковую волну. От него зависит натуральность тембра, чистота высоких частот и отсутствие металлического оттенка. Слабый вокодер делает голос плоским, шипящим или чрезмерно сглаженным. Современные нейросетевые вокодеры заметно улучшили качество TTS и приблизили синтезированную речь к студийной записи.
Этап 7. Постобработка
После генерации фрагменты прослушивают и готовят к использованию. Типовой набор действий:
-
Удалить лишнюю тишину в начале и конце.
-
Проверить, нет ли щелчков и резких стыков.
-
Выровнять громкость соседних фрагментов.
-
Разделить длинную дорожку на главы или сцены.
-
Сохранить исходный WAV.
-
Подготовить отдельный MP3 для публикации или отправки.
Почему синтезатору недостаточно просто прочитать буквы
Одна из главных ошибок новичка — вставить большой необработанный текст и сразу использовать первый результат. Даже сильная модель требует чистого сценария. Написанный текст рассчитан на чтение глазами, а озвучка подчиняется другим правилам.
Числа и даты
Цифровая запись экономит место, но создаёт неоднозначность. Строку 01.02.03 можно понять как дату, версию продукта или последовательность номеров. В голосовом сценарии лучше использовать словесную форму там, где ошибка недопустима.
Сокращения
Сокращение млн читается как миллионов, а AI может прозвучать по буквам или как английское словосочетание. Название продукта часто требует отдельной проверки. В длинном материале один вариант произношения фиксируют заранее и используют последовательно.
Имена и фамилии
Имена собственные чаще всего требуют ручной проверки. Даже распространённая фамилия получает разное ударение в разных семьях. При коммерческой озвучке правильный вариант уточняют у заказчика или владельца имени.
Иностранные слова
Система может прочитать латиницу с русским акцентом, перейти на другой язык или озвучить символы по буквам. Выбор зависит от движка. Перед экспортом прослушивают все бренды, названия функций и географические объекты.
Знаки препинания
Пунктуация в озвучке работает как режиссёрская разметка. Короткая фраза после точки звучит увереннее. Запятая создаёт небольшую паузу. Двоеточие подготавливает перечисление. Тире помогает выделить уточнение. Многоточие замедляет фразу, но при частом употреблении делает голос неестественно задумчивым.
Как развивался синтез речи
Современный нейросетевой голос появился не внезапно. До него инженеры несколько столетий изучали речевой тракт, резонансы, форманты, способы кодирования и методы сборки фраз из записанных элементов.
Механические говорящие машины
В XVIII веке исследователи пытались воспроизвести человеческую речь с помощью механики. Кристиан Кратценштейн создавал резонансные трубки для моделирования гласных. Вольфганг фон Кемпелен разработал говорящую машину с мехами, вибрирующим источником звука и элементами, имитирующими работу речевого тракта.

Механические устройства помогли понять, что тембр речи зависит от источника звука и формы резонаторов.
Эти аппараты не были универсальными синтезаторами в современном смысле. Ими управлял человек, а качество зависело от навыка оператора. Но сама идея оказалась фундаментальной: речь можно разложить на управляемые физические компоненты.
VODER и вокодерная логика
В 1930-х годах инженер Bell Labs Гомер Дадли разработал VODER. Аппарат демонстрировался на Всемирной выставке в Нью-Йорке в 1939 году. Оператор управлял источником возбуждения, высотой тона и частотными полосами. Для понятной речи требовалась тренировка, однако VODER показал, что голос можно синтезировать электронно без готовой записи диктора.
Вокодерная идея получила дальнейшее развитие в связи, обработке аудио и речевых технологиях. Сигнал анализировался по параметрам, после чего восстанавливался на принимающей стороне. Позднее похожая логика стала частью цифрового синтеза речи.
Формантный синтез
Форманты — это области усиления частот, связанные с резонансами речевого тракта. Их положение помогает различать гласные и влияет на характер звучания. Формантный синтез создаёт речь с помощью параметров: частот, длительностей, основного тона и правил перехода между звуками.
Преимущество метода — компактность и управляемость. Недостаток — характерный роботизированный тембр. Такой голос хорошо подходит для демонстрации принципа, но быстро утомляет при прослушивании длинного текста.
Компьютерная речь и ранние эксперименты
С развитием вычислительной техники исследователи начали переносить правила синтеза в программы. Одним из известных ранних примеров стала компьютерная версия песни Daisy Bell, созданная на IBM 704 в начале 1960-х годов. Этот эпизод показал, что компьютер способен воспроизводить не только отдельные звуки, но и узнаваемую вокальную фразу.
В СССР развивались собственные исследования вокодеров и речевых синтезаторов. Серия ФОНЕМОН предназначалась для формирования речи по фонемному представлению. Поздние варианты работали с персональными компьютерами своего времени и использовались для дальнейших экспериментов с машинным голосом.
Конкатенативный синтез
Следующий заметный шаг — сборка речи из записанных фрагментов. Диктор заранее начитывал набор единиц, а программа соединяла подходящие элементы в новую фразу. В качестве единиц могли использоваться фонемы, дифоны, слоги и более длинные отрезки.
Чем длиннее фрагмент, тем естественнее он звучит внутри знакомого контекста. Но большая база занимает больше места и сложнее подбирается. На стыках слышны артефакты, когда соседние элементы отличаются темпом, высотой или характером произношения.
Unit Selection
Метод Unit Selection развил конкатенативный подход. Вместо одного варианта звуковой единицы система хранит множество фрагментов и выбирает наиболее подходящую последовательность. Учитываются фонетический контекст, ударение, положение в предложении и стоимость стыка.
Такой синтезатор способен звучать естественно в удачных фразах, потому что использует реальные записи диктора. Но гибкость ограничена корпусом. Для нового голоса приходится записывать и размечать большой объём материала.
Статистический параметрический синтез
Статистические модели начали предсказывать акустические параметры речи вместо прямой склейки фрагментов. Они лучше сглаживали переходы и требовали меньше записей. Распространение получили HMM-модели и методы предсказания длительности. Речь стала стабильнее, но часто звучала чрезмерно усреднённо.
Нейросетевой этап
Глубокие нейросети заметно изменили качество TTS. Модели научились строить акустическое представление по тексту, учитывать контекст и создавать более естественные переходы. Архитектуры Tacotron показали сильный результат в преобразовании текста в спектрограмму. WaveNet улучшил генерацию звуковой волны. FastSpeech ускорил синтез и сделал длительность более управляемой. VITS объединил несколько этапов в единую модель и упростил получение выразительной речи.
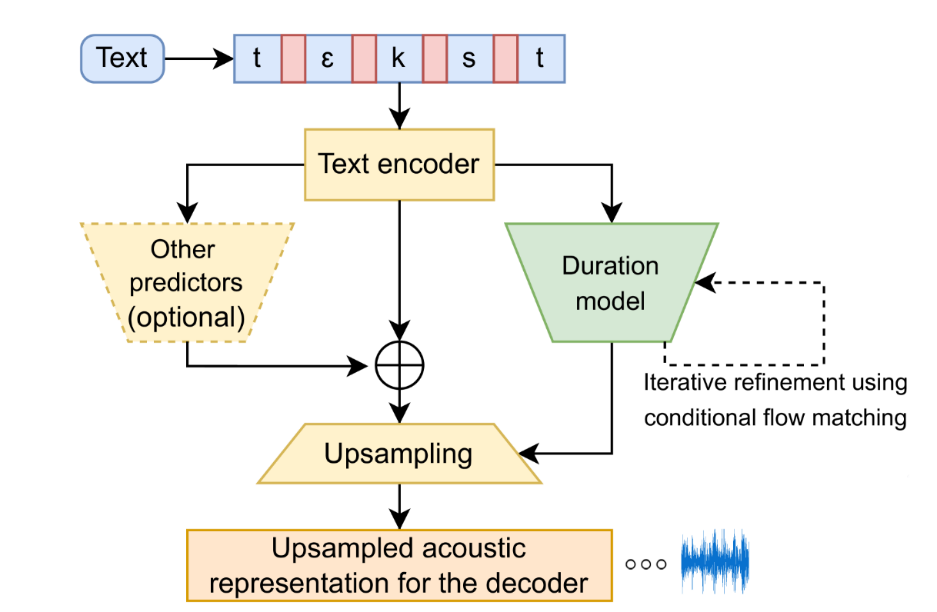
В современных моделях длительность фонем рассчитывается отдельно, чтобы контролировать ритм и ускорять генерацию.
Основные типы синтеза речи
| Подход | Как формируется голос | Сильная сторона | Ограничение |
|---|---|---|---|
| Артикуляционный | Моделируется работа речевого тракта | Научная наглядность | Сложная реализация |
| Формантный | Используются правила и резонансные параметры | Компактность | Роботизированный тембр |
| Конкатенативный | Склеиваются записанные элементы | Реальные фрагменты диктора | Артефакты на стыках |
| Unit Selection | Из корпуса выбираются подходящие отрезки | Естественность удачных фраз | Большой корпус и слабая гибкость |
| Статистический параметрический | Акустические параметры предсказываются моделью | Плавность и компактность | Усреднённое звучание |
| Нейросетевой | Нейросеть строит акустику и аудио по тексту | Натуральность, гибкость и масштабирование | Требовательность к данным и вычислениям |
В пользовательских сервисах чаще всего встречается нейросетевой синтез. Однако внутри одного продукта могут сочетаться разные методы: отдельный блок отвечает за нормализацию, другой — за фонетику, третий — за акустику, четвёртый — за финальную звуковую волну.
Что влияет на естественность цифрового голоса
Качество синтеза нельзя оценивать только по тембру. Голос может звучать приятно на короткой демонстрации и плохо справляться с длинной статьёй. Для рабочего материала важны разборчивость, стабильность и корректное произношение сложных мест.
Качество речевого корпуса
Нейросетевая модель обучается на записях дикторов. Если записи чистые, равномерные и разнообразные по интонации, модель получает больше полезной информации. Шумы, комнатное эхо, клиппинг и неравномерная громкость ухудшают результат.
Фонетическое покрытие
В корпусе должны встречаться разные сочетания звуков, типы предложений и речевые ситуации. Недостаток примеров делает отдельные слова нестабильными. Особенно заметны проблемы с редкими именами, иностранными названиями и сложными согласными сочетаниями.
Просодия
Естественная речь не идёт с постоянной скоростью. Диктор замедляется перед важной мыслью, делает паузу после заголовка, повышает тон в вопросе и выделяет смысловой центр. Модель без убедительной просодии звучит монотонно даже при приятном тембре.
Подготовка текста
Чистый сценарий повышает качество без смены сервиса. Полезно разбивать перегруженные предложения, убирать лишние скобки, приводить даты к понятной форме, проверять ударения и отделять логические блоки пустыми строками.
Вокодер
Акустическая модель может правильно построить интонацию, но слабый вокодер испортит финальное звучание. Типичные симптомы — шипение, металлический оттенок, размытые согласные и странные окончания слов.
Длина фрагмента
Короткие реплики проще контролировать. В длинном абзаце голос иногда теряет ритм, ускоряется или неправильно распределяет паузы. Для монтажа удобнее создавать фрагменты по одному смысловому блоку, а затем собирать дорожку.
Типичные дефекты синтезированной речи и способы исправления
| Проблема | Причина | Что сделать |
|---|---|---|
| Неверное ударение | Неоднозначное слово или редкое имя | Задать ударение разметкой или изменить запись слова |
| Монотонная подача | Недостаток пауз и слабая структура текста | Разбить абзац, добавить знаки препинания, уменьшить длину фразы |
| Слишком быстрый темп | Завышенная скорость или перегруженное предложение | Снизить скорость, разделить предложение |
| Металлический оттенок | Особенность модели или вокодера | Выбрать другой голос, сравнить другую модель |
| Неровная громкость | Фрагменты созданы разными голосами или в разных режимах | Выровнять дорожки перед монтажом |
| Странное чтение числа | Неоднозначная цифровая запись | Написать число словами |
| Ошибка в иностранном слове | Неверный язык или фонетика | Использовать фонетическую подсказку или отдельный языковой фрагмент |
| Резкая пауза | Неудачное деление текста | Перенести границу фрагмента и изменить пунктуацию |
| Шум в персонализированном голосе | Некачественные образцы речи | Подготовить чистые записи без музыки и эха |
| Театральная подача | Слишком сильная стилистическая настройка | Ослабить эмоцию и сравнить несколько вариантов |
Как прослушать страницу через Microsoft Edge
Microsoft Edge подходит для быстрого чтения веб-страниц и PDF-документов. Этот способ не требует отдельного редактора и удобен, когда нужно прослушать статью, проверить собственный текст на слух или снизить нагрузку на глаза.
В панели чтения Microsoft Edge доступны управление воспроизведением, выбор голоса и настройка скорости.
Как запустить чтение
-
Откройте веб-страницу или PDF-документ в Microsoft Edge.
-
Откройте меню браузера.
-
Перейдите к дополнительным инструментам.
-
Выберите
Read aloud. -
Используйте кнопку воспроизведения для старта и паузы.
-
Переходите между абзацами кнопками на панели.
-
Откройте
Voice options. -
Выберите голос и отрегулируйте скорость.
-
Закройте панель после прослушивания.
Команду также удобно запускать сочетанием Ctrl + Shift + U. При чтении статьи браузер последовательно выделяет текущий фрагмент, поэтому пользователь видит, какое предложение звучит в данный момент.
Когда способ полезен
-
прослушивание длинной статьи;
-
чтение PDF-инструкции;
-
проверка ритма собственного текста;
-
работа с материалом без установки отдельного приложения;
-
быстрое сравнение нескольких системных голосов.
Ограничения
Microsoft Edge рассчитан на прослушивание. Встроенная команда не создаёт готовый WAV или MP3 для монтажа. Для экспорта дорожки нужен отдельный TTS-инструмент.
Плюсы
-
Не требуется отдельная программа.
-
Быстрый запуск.
-
Поддержка веб-страниц и PDF.
-
Регулировка скорости.
-
Выбор доступного голоса.
-
Удобная подсветка читаемого фрагмента.
Минусы
-
Нет сохранения аудиофайла.
-
Нет подробной настройки ударений.
-
Нет монтажа нескольких реплик.
-
Нет пакетной обработки длинных сценариев.
Как настроить синтез речи на Android
Android использует системный голосовой движок для чтения текста в совместимых приложениях и функциях доступности. Пользователь выбирает движок, язык, скорость и высоту тона. Расположение пункта меню зависит от производителя смартфона и версии оболочки.
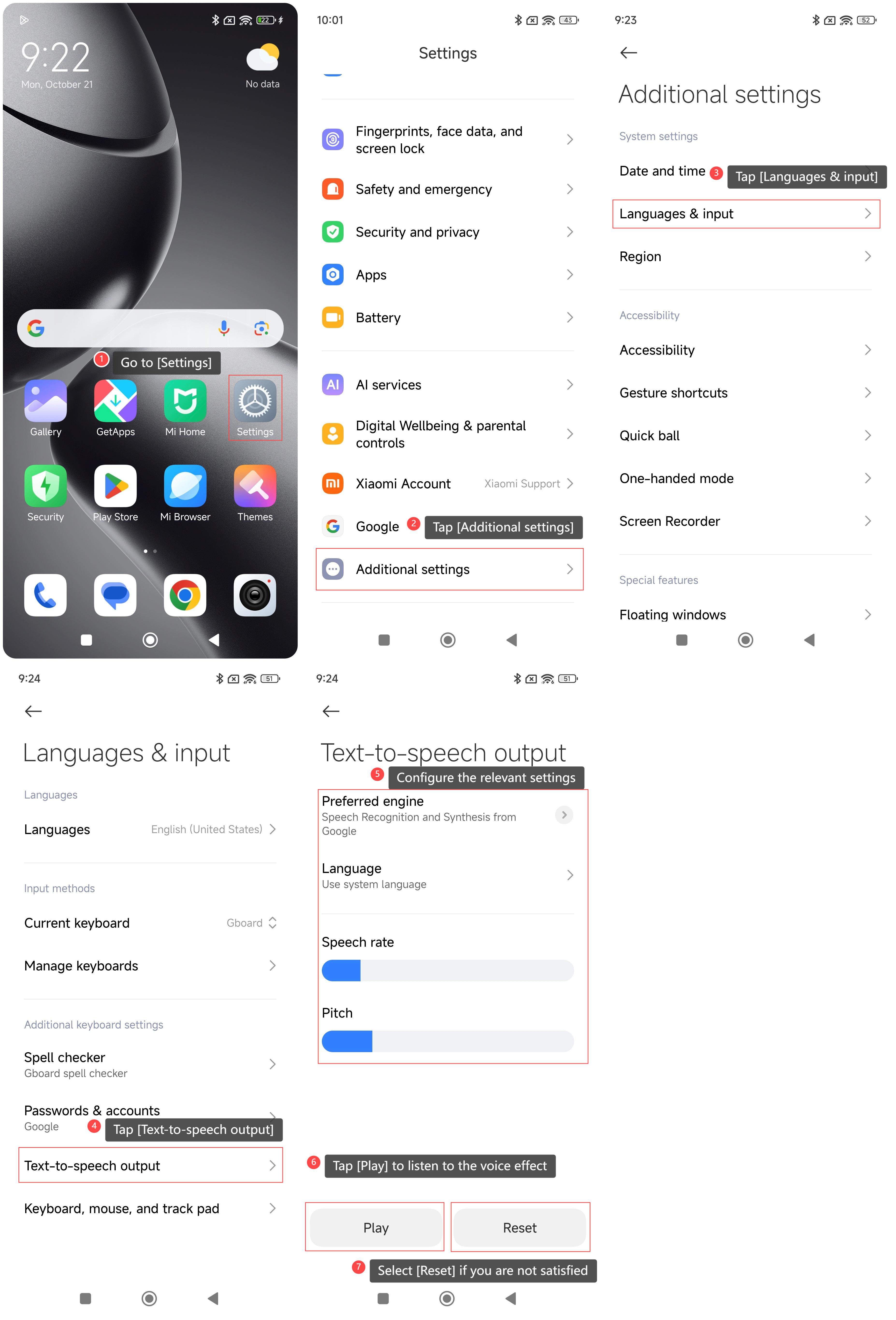
В системных настройках Android регулируются движок, язык, скорость и высота тона.
Как открыть настройки
-
Откройте настройки смартфона.
-
Перейдите в раздел специальных возможностей.
-
Откройте экран синтеза речи.
-
Выберите предпочтительный движок.
-
Укажите язык.
-
Отрегулируйте скорость речи.
-
Отрегулируйте высоту тона.
-
Запустите тестовое воспроизведение.
-
При необходимости установите дополнительные голосовые данные.
На отдельных смартфонах нужный пункт находится внутри расширенных настроек или дополнительного раздела специальных возможностей. Логика остаётся одинаковой: движок создаёт голос, а системные параметры задают базовую манеру чтения.
Что дают основные настройки
Движок определяет набор голосов и качество синтеза.
Язык влияет на фонетику и чтение слов. Для русскоязычного текста выбирают русский голосовой пакет.
Скорость меняет темп чтения. Слишком высокая скорость снижает разборчивость, особенно в инструкциях и учебных материалах.
Высота тона делает голос выше или ниже. Этот параметр не заменяет выбор другого диктора, но помогает настроить комфортное звучание.
Когда способ полезен
-
чтение текста в приложениях;
-
работа TalkBack;
-
прослушивание учебных материалов;
-
настройка системного диктора;
-
проверка того, как смартфон произносит уведомления.
Плюсы
-
Системная интеграция.
-
Работа в совместимых приложениях.
-
Поддержка функций доступности.
-
Настройка языка.
-
Регулировка скорости и высоты тона.
-
Тестовое воспроизведение прямо в настройках.
Минусы
-
Нет профессионального редактора озвучки.
-
Нет готовой дорожки для монтажа.
-
Набор голосов зависит от движка и устройства.
-
Путь к настройкам отличается у разных производителей.
Как создать аудиофайл в Yandex SpeechKit Playground
Yandex SpeechKit Playground подходит для русскоязычной озвучки через браузер. В интерфейсе можно вставить текст, выбрать язык, голос, амплуа, скорость, высоту голоса и формат аудио. Отдельные элементы разметки помогают управлять паузами, ударениями и фонетикой.
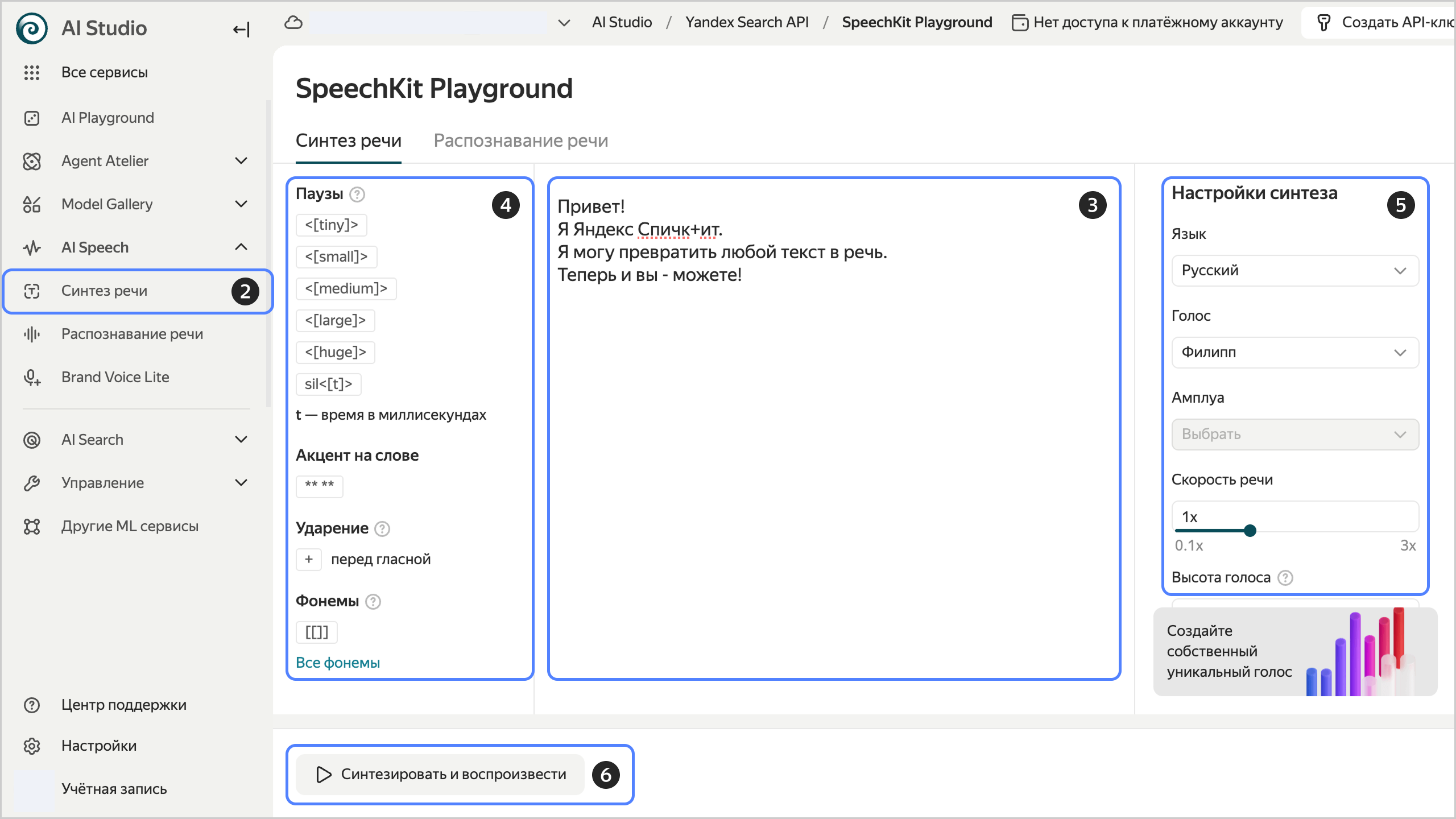
В Playground текст, голос и параметры аудио собраны в одном рабочем окне.
Как открыть Playground
-
Откройте консоль Yandex Cloud.
-
Перейдите в каталог проекта.
-
Откройте SpeechKit.
-
Перейдите в Playground.
-
Выберите вкладку
Синтез речи.
Как создать озвучку
-
Вставьте текст в редактор.
-
Проверьте, чтобы объём одного фрагмента не превышал 5000 символов.
-
Выберите язык.
-
Выберите голос.
-
Выберите амплуа.
-
Настройте скорость.
-
Отрегулируйте высоту голоса.
-
Выберите формат аудио.
-
Добавьте паузы.
-
Исправьте ударения.
-
При необходимости задайте фонетическую подсказку.
-
Запустите синтез и прослушивание.
-
Скачайте результат.
Как управлять паузами
Playground поддерживает короткие паузы и паузы заданной длительности. Для естественной речи паузы ставят после заголовков, перед важным выводом, между пунктами перечисления и на границе смысловых блоков. Не стоит заполнять разметкой каждую запятую: базовую интонацию модель строит самостоятельно.
Пример короткой паузы:
Первый шаг завершён. <[small]> Переходим к настройке голоса.
Пример паузы заданной длительности:
Сохраните проект. sil<[700]> Затем скачайте готовый файл.
Как исправить ударение
Для слова с неоднозначным произношением отметьте ударную гласную знаком +:
Проверьте з+амок на входной двери.
Для дополнительного контроля используйте фонетическую запись. Это полезно для фамилий, названий компаний, иностранных терминов и редких географических объектов.
Как работать с длинным сценарием
Не вставляйте весь материал одним массивом. Разделите сценарий на абзацы по 800–2500 символов. Для каждого блока сохраните понятное имя файла: 01_intro, 02_definition, 03_examples. Такой подход облегчает повторную генерацию и монтаж.
Плюсы
-
Работа через браузер.
-
Подробная настройка русскоязычной озвучки.
-
Выбор голоса и амплуа.
-
Регулировка скорости и высоты голоса.
-
Разметка пауз.
-
Исправление ударений.
-
Фонетические подсказки.
-
Скачивание результата.
Минусы
-
Один фрагмент ограничен 5000 символами.
-
Длинный сценарий приходится делить на части.
-
Расширенная автоматизация строится через API.
-
Финальный материал требует прослушивания перед публикацией.
Как озвучить текст в SaluteSpeech App
SaluteSpeech App — настольное приложение для Windows и macOS. Оно работает с синтезом и распознаванием речи, а также использует GigaChat API для генерации текста. Для озвучивания доступна вкладка Синтез, где можно выбрать голос, добавить разметку и скачать WAV-файл.
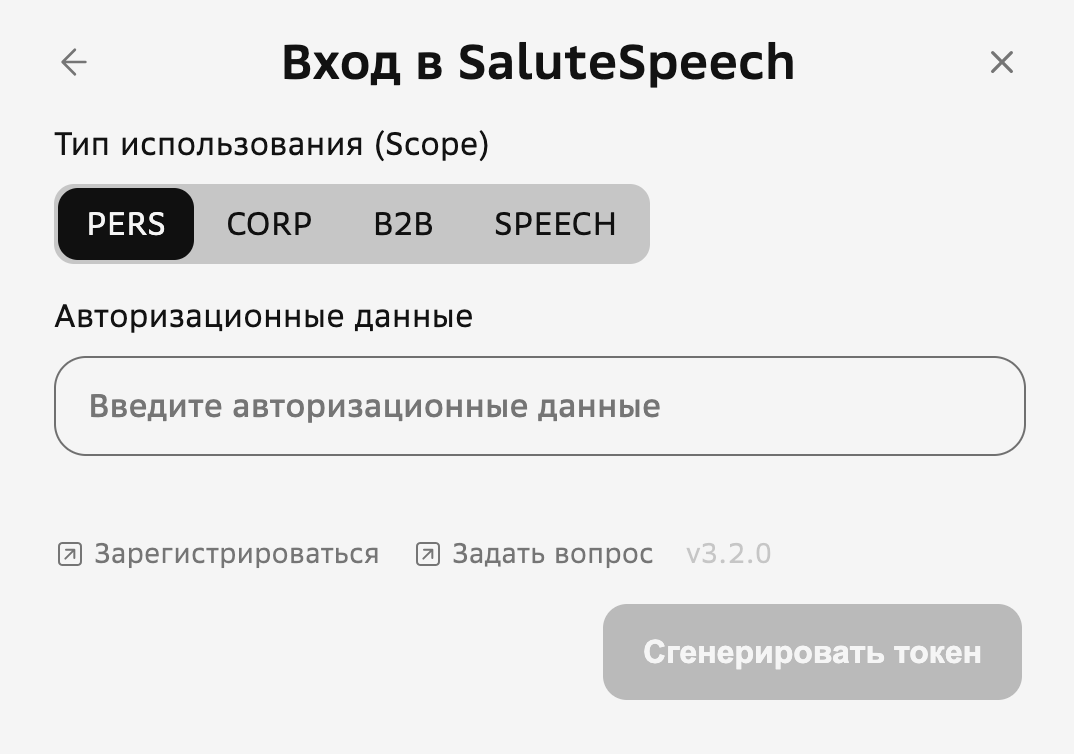
После авторизации пользователь переходит к вкладке синтеза и создаёт голосовые фрагменты.
Подготовка приложения
-
Установите SaluteSpeech App для Windows или macOS.
-
Зарегистрируйтесь в Studio.
-
Создайте проект.
-
Выберите тариф.
-
Получите токен доступа.
-
Авторизуйтесь в приложении.
Токен действует ограниченное время, поэтому при завершении сессии его обновляют. Это нормальная часть авторизации, а не ошибка приложения.
Как создать голосовой фрагмент
-
Откройте вкладку
Синтез. -
Выберите основной голос.
-
При необходимости добавьте второй голос для отдельной реплики.
-
Вставьте текст.
-
Выделите слово и используйте команду
Ударение. -
Добавьте смысловой акцент.
-
Настройте паузу.
-
Используйте дополнительный голос для диалога.
-
Настройте интонацию.
-
Добавьте эмоциональный режим.
-
Нажмите
Синтезировать. -
Откройте блок
История синтезов. -
Прослушайте результат.
-
Скачайте WAV-файл.
Управление эмоциями
В интерфейсе доступны эмоциональные режимы:
-
раздражение;
-
радость;
-
грусть;
-
шёпот.
Эмоция должна соответствовать сценарию. Для инструкции и корпоративного уведомления обычно подходит спокойная подача. Для персонажа, рекламного фрагмента или художественной реплики уместна более заметная окраска. Перед экспортом сравните несколько версий одного предложения.
Работа с несколькими голосами
Дополнительный голос полезен для диалога, вопросов и ответов, учебного упражнения или короткой сценки. Не стоит собирать длинный разговор без предварительного плана. Сначала распределите реплики по персонажам, затем создайте короткие фрагменты и проверьте громкость каждого голоса.
Плюсы
-
Отдельное приложение для Windows и macOS.
-
Визуальные команды разметки.
-
Работа с ударениями и паузами.
-
Эмоциональные режимы.
-
Дополнительный голос внутри материала.
-
История созданных фрагментов.
-
Скачивание WAV-файла.
Минусы
-
Требуется регистрация.
-
Для авторизации нужен токен.
-
Токен периодически обновляется.
-
Мобильной версии приложения нет.
-
Длинную озвучку удобнее собирать из отдельных блоков.
Как создать выразительную озвучку в ElevenLabs Text to Speech
ElevenLabs Text to Speech подходит для закадровой речи, роликов, подкастов, персонажей и мультиязычных материалов. В рабочем окне пользователь вставляет текст, выбирает голос и модель, настраивает параметры, запускает генерацию и скачивает результат.
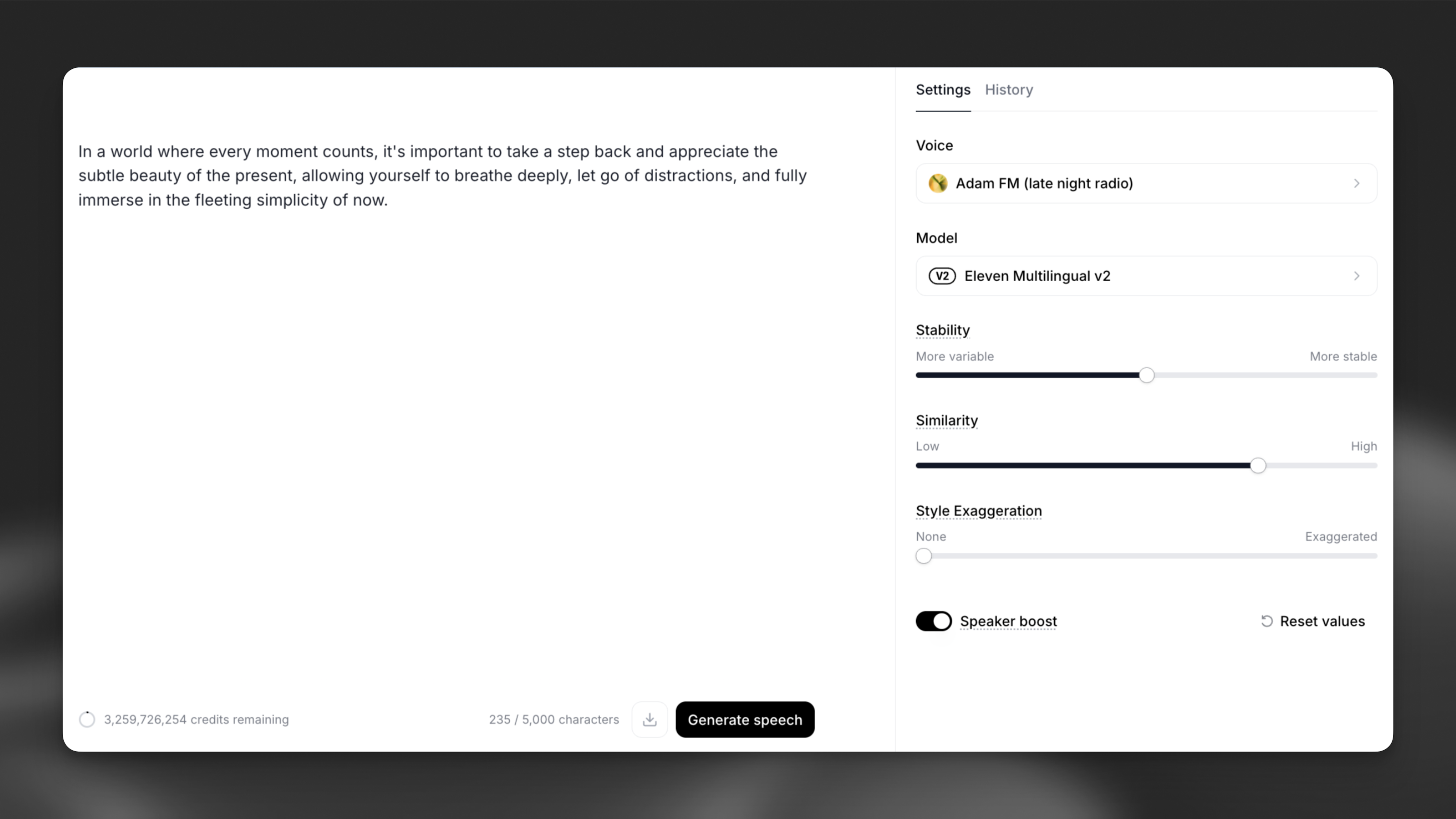
В ElevenLabs текст и основные настройки голоса находятся рядом, поэтому несколько вариантов удобно сравнивать последовательно.
Как создать аудио
-
Откройте Text to Speech.
-
Вставьте сценарий.
-
Выберите голос.
-
Выберите модель.
-
Отрегулируйте
Speed. -
Настройте
Stability. -
Настройте
Similarity. -
При необходимости используйте
Style exaggeration. -
Проверьте
Speaker boost, когда параметр доступен для выбранной модели. -
Запустите генерацию.
-
Прослушайте результат.
-
Создайте ещё один вариант для сравнения.
-
Скачайте удачную версию.
Что делает Speed
Speed регулирует скорость произношения. Базовое значение — 1.0. Для спокойной инструкции темп немного снижают. Для короткого динамичного ролика допустимо умеренное ускорение. Сильное ускорение ухудшает разборчивость и делает паузы неестественно короткими.
Что делает Stability
Stability влияет на стабильность и вариативность подачи. Более низкое значение делает речь эмоциональнее и менее предсказуемой. Более высокое значение помогает получить ровную манеру, но чрезмерная стабильность приводит к монотонности.
Для дикторской инструкции полезен сдержанный режим. Для художественной реплики можно снизить стабильность и сравнить несколько генераций. Один и тот же текст даёт разные нюансы, поэтому финальный вариант выбирают после прослушивания.
Что делает Similarity
Similarity регулирует сходство с характеристиками выбранного голоса. Слишком высокое значение иногда переносит шумы и артефакты из неидеальных образцов персонализированного диктора. Если речь начинает звучать грязно, уменьшите параметр и проверьте качество исходных записей.
Что делает Style exaggeration
Style exaggeration усиливает стилистические особенности. Параметр используют осторожно: заметное усиление увеличивает задержку и снижает стабильность. Для большинства нейтральных сценариев его оставляют на минимальном уровне.
Что делает Speaker boost
Speaker boost усиливает сходство с выбранным голосом. Эффект обычно тонкий, а обработка занимает больше времени. Параметр доступен не для каждой модели.
Как подготовить сценарий
Разделяйте длинный текст на сцены. Для каждого фрагмента фиксируйте голос, модель и настройки. Это особенно важно при монтаже курса или серии роликов: случайная смена параметров создаёт заметные различия между главами.
Плюсы
-
Выразительная интонация.
-
Большой выбор голосов.
-
Несколько моделей для разных задач.
-
Настройка скорости.
-
Регулировка стабильности.
-
Работа со сходством и стилистикой.
-
Удобное сравнение вариантов.
-
Подходит для мультиязычных материалов.
Минусы
-
Результат нужно прослушивать и отбирать.
-
Низкая стабильность даёт непредсказуемую подачу.
-
Высокая стабильность делает голос монотонным.
-
Сильная стилистика увеличивает задержку и снижает стабильность.
-
Плохие образцы персонализированного голоса переносят шумы и артефакты.
Как подготовить профессиональную дорожку в Microsoft Audio Content Creation
Microsoft Audio Content Creation — инструмент без программирования для подготовки TTS-аудио в Microsoft Foundry и Speech Studio. Он рассчитан на более внимательную работу со сценарием: пользователь создаёт файл, выбирает язык и голос, прослушивает результат, настраивает произношение, паузы, высоту тона, скорость, интонацию и стиль, а затем экспортирует WAV или MP3.
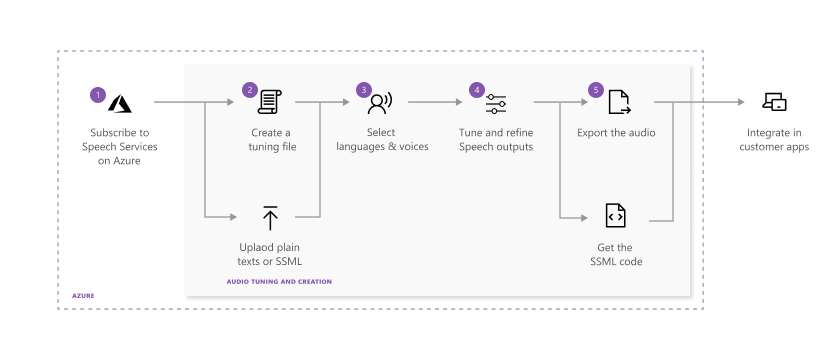
Рабочий процесс состоит из подготовки текста, настройки звучания, проверки и экспорта.
Как начать работу
-
Откройте Microsoft Foundry.
-
Перейдите к Speech playground.
-
Откройте
Text to speech. -
Выберите
Audio content creation. -
Создайте файл настройки.
-
Вставьте обычный текст или SSML-разметку.
-
Выберите язык.
-
Выберите голос.
-
Запустите предпрослушивание.
-
Исправьте проблемные места.
-
Сохраните проект.
-
Экспортируйте результат.
Работа с длинным текстом
Один текстовый файл содержит до 20 000 символов. Более длинный сценарий делят на части. Для автоматического разделения используются абзацы, заданное количество символов или регулярные выражения. Перед загрузкой файлы сохраняют в UTF-8 и дают им уникальные имена.
Хорошая схема для курса или аудиокниги:
01_intro.txt
02_chapter_one.txt
03_chapter_two.txt
04_summary.txt
Каждый файл прослушивают отдельно. После экспорта дорожки собирают в монтажной программе и выравнивают по громкости.
Что можно настроить
-
произношение отдельных слов;
-
длительность пауз;
-
скорость;
-
высоту тона;
-
интонацию;
-
голосовой стиль;
-
формат экспорта;
-
частоту дискретизации.
Когда инструмент особенно полезен
-
аудиокнига;
-
длинный обучающий курс;
-
новостные фрагменты;
-
голосовые уведомления;
-
озвучивание чат-бота;
-
серия однотипных роликов;
-
проект с SSML-разметкой.
Плюсы
-
Работа без написания программного кода.
-
Поддержка обычного текста и SSML.
-
Настройка произношения.
-
Управление паузами, скоростью и высотой тона.
-
Работа с длинными материалами.
-
Экспорт WAV и MP3.
-
Удобная структура проекта.
Минусы
-
Требуется учётная запись и облачный ресурс.
-
Интерфейс сложнее бытовых решений.
-
Длинный сценарий нужно заранее организовать.
-
После экспорта требуется финальная проверка дорожек.
Какой способ выбрать
| Задача | Подходящий способ | Почему он удобен |
|---|---|---|
| Прослушать статью или PDF | Microsoft Edge | Быстрый старт без отдельного редактора |
| Настроить чтение на смартфоне | Android | Системный голосовой движок работает в совместимых приложениях |
| Получить русскоязычный аудиофайл через браузер | Yandex SpeechKit Playground | Есть голос, амплуа, скорость, высота голоса и разметка произношения |
| Создать WAV на компьютере | SaluteSpeech App | Настольное приложение, эмоции, паузы и дополнительные голоса |
| Подготовить выразительную закадровую речь | ElevenLabs Text to Speech | Гибкая настройка подачи и сравнение вариантов |
| Собрать длинный производственный материал | Microsoft Audio Content Creation | Проекты, SSML, работа с большими сценариями и экспорт |
| Сравнить больше инструментов | Нейросети для озвучки текста голосом | Подборка решений для разных сценариев |
| Найти отдельное приложение | Программы для озвучки текста | Сравнение настольных, мобильных и браузерных вариантов |
Как подготовить текст для естественной озвучки
Даже дорогой сервис не исправит плохо организованный сценарий полностью. Перед генерацией обработайте текст как материал для диктора.
Делите длинные предложения
Одна фраза должна содержать одну основную мысль. Предложение с несколькими уточнениями, скобками и перечислениями лучше разделить. Так модель точнее расставит паузы, а слушателю будет проще следить за смыслом.
Плохо:
После установки приложения, которое работает на Windows и macOS и позволяет создавать голосовые фрагменты, откройте проект, настройте параметры, проверьте сценарий и скачайте файл, который затем добавьте в монтажную программу.
Лучше:
Установите приложение для Windows или macOS. Откройте проект и настройте параметры. Проверьте сценарий. Скачайте готовый файл и добавьте его в монтажную программу.
Записывайте числа так, как они должны звучать
Для короткой заметки можно оставить цифры. Для коммерческого ролика, инструкции и телефонного уведомления важные значения лучше преобразовать в слова.
Плохо:
Встреча состоится 05.06 в 10:30.
Лучше:
Встреча состоится пятого июня в десять часов тридцать минут.
Проверяйте имена и названия
Составьте отдельный список сложных слов. Прослушайте каждое имя, фамилию, бренд и географическое название. Зафиксируйте корректное произношение в рабочей таблице проекта.
| Слово | Как должно звучать | Где используется | Проверено |
|---|---|---|---|
| Фамилия диктора | Уточнённое ударение | Вступление | Да |
| Название продукта | Фонетическая форма | Реклама | Да |
| Город | Нормативное произношение | Маршрут | Да |
| Английский термин | Нужный язык и акцент | Обучающий курс | Да |
Используйте короткие абзацы
Абзац из двух–пяти предложений проще прослушать и заменить. При ошибке не придётся повторно создавать всю главу. Такой подход экономит время при монтаже.
Не перегружайте разметку
Пунктуации часто достаточно для базовой интонации. Дополнительные паузы нужны в местах, где модель стабильно ошибается или где требуется режиссёрский акцент. Избыточная разметка делает голос рубленым.
Сохраняйте версии
Для каждого фрагмента храните исходный текст и несколько аудиоверсий. Названия файлов должны отражать содержание и номер попытки:
03_definition_v1.wav
03_definition_v2.wav
03_definition_final.wav
Что такое SSML и зачем нужна разметка
SSML — это язык разметки для управления синтезированной речью. Он помогает задать паузы, темп, высоту тона, громкость, произношение и голос. Набор поддерживаемых элементов зависит от платформы, поэтому готовый сценарий проверяют в выбранном сервисе.
Пауза
<speak>
Сначала сохраните проект.
<break time="700ms" />
Затем скачайте аудиофайл.
</speak>
Замедление фрагмента
<speak>
Запишите номер телефона:
<prosody rate="slow">восемь восемьсот пятьсот пятьдесят пять тридцать пять тридцать пять</prosody>.
</speak>
Изменение высоты тона
<speak>
<prosody pitch="+5%">Этот фрагмент звучит немного выше.</prosody>
</speak>
Смысловой акцент
<speak>
Сохраните именно <emphasis level="strong">исходный WAV-файл</emphasis>.
</speak>
Когда SSML особенно полезен
-
телефонное меню;
-
длинная инструкция;
-
голосовое уведомление с числами;
-
аудиокнига;
-
обучающий курс;
-
сценарий с иностранными названиями;
-
диалог нескольких голосов;
-
ролик с точным таймингом.
Как подготовить длинную озвучку без хаоса
Длинный материал нельзя обрабатывать как один файл. Даже при технической возможности удобнее разделить сценарий на части. Это упрощает прослушивание, исправление ошибок и монтаж.
Шаг 1. Разбейте текст на главы
Сначала используйте смысловую структуру:
00_intro
01_definition
02_how_it_works
03_history
04_tools
05_faq
06_summary
Шаг 2. Разделите главы на короткие фрагменты
Один фрагмент должен быть достаточно коротким для быстрого повторного создания. Обычно удобно работать с одним–тремя абзацами. Для динамичного ролика допустимы отдельные реплики по одному предложению.
Шаг 3. Зафиксируйте голос и настройки
Создайте таблицу проекта:
| Фрагмент | Голос | Скорость | Стиль | Формат | Статус |
|---|---|---|---|---|---|
| 00_intro | Диктор 1 | 0.95 | Нейтральный | WAV | Готово |
| 01_definition | Диктор 1 | 0.95 | Нейтральный | WAV | На проверке |
| 02_example | Диктор 2 | 1.00 | Дружелюбный | WAV | Черновик |
Шаг 4. Сначала исправьте текст, затем звук
Когда ошибка связана с ударением, паузой или темпом, не пытайтесь маскировать её монтажом. Исправьте сценарий и создайте фрагмент заново. Монтаж нужен для сборки и финального выравнивания, а не для ремонта неудачного произношения.
Шаг 5. Сохраняйте исходный WAV
WAV занимает больше места, но подходит для обработки. MP3 используйте для публикации, быстрой отправки и прослушивания. Не стоит многократно перекодировать MP3: каждое повторное сжатие ухудшает качество.
Шаг 6. Проверьте дорожку целиком
Отдельные фрагменты могут звучать хорошо, а собранная глава — неровно. Прослушайте материал в наушниках и на обычных колонках. Проверьте переходы, длительность тишины и разницу громкости.
WAV, MP3 и другие форматы: что выбрать
| Формат | Для чего подходит | Преимущество | Ограничение |
|---|---|---|---|
| WAV | Монтаж, архив, мастер-файл | Высокое качество без потерь | Большой размер |
| MP3 | Публикация, отправка, прослушивание | Небольшой размер и широкая совместимость | Сжатие с потерями |
| OGG Opus | Веб, приложения, голосовые интерфейсы | Хорошее качество при небольшом битрейте | Не каждый редактор открывает формат одинаково удобно |
| PCM | Телефония, интеграции, обработка | Предсказуемый несжатый сигнал | Большой объём данных |
Для видеомонтажа сохраняйте WAV. Для финальной публикации создавайте отдельную копию нужного формата. Для телефонии заранее уточняйте частоту дискретизации и кодирование, потому что требования голосового меню отличаются от требований видеоролика.
Облачный, локальный и системный синтез речи
Облачный сервис
Облачная платформа обрабатывает текст на сервере и возвращает аудио. Пользователь получает современные модели, разные голоса и обновления без ручной установки. Такой вариант подходит для разовых задач, контент-производства и интеграций через API.
Плюсы:
-
Современные модели.
-
Большой выбор голосов.
-
Доступ через браузер.
-
Удобное масштабирование.
-
Обновления без ручной установки.
Минусы:
-
Требуется интернет.
-
Текст передаётся внешней платформе.
-
Действуют тарифы и лимиты.
-
Для автоматизации нужна настройка API.
Локальный движок
Локальная модель работает на компьютере или сервере пользователя. Такой подход выбирают для закрытых данных, автономной работы и собственных исследований.
Плюсы:
-
Контроль над данными.
-
Работа без постоянного доступа к интернету.
-
Возможность встроить модель в закрытую инфраструктуру.
-
Независимость от браузерного интерфейса.
Минусы:
-
Сложнее установка.
-
Требуются вычислительные ресурсы.
-
Качество зависит от выбранной модели.
-
Обновления и обслуживание выполняются вручную.
Системный синтез
Системный голосовой движок встроен в операционную систему или устройство. Он удобен для чтения интерфейса и повседневных задач.
Плюсы:
-
Быстрая настройка.
-
Интеграция с устройством.
-
Поддержка функций доступности.
-
Минимум действий для запуска.
Минусы:
-
Небольшой набор настроек.
-
Нет профессионального экспорта.
-
Ограниченный выбор голосов.
-
Не подходит для сложной режиссуры озвучки.
Как встроить TTS в приложение или сервис
Для массовых задач браузерного интерфейса недостаточно. Сервис доставки, голосовой помощник или корпоративная система обращается к API. Приложение отправляет текст и параметры, получает аудио и воспроизводит его пользователю.
Потоковый синтез
Потоковый режим начинает отдавать аудио до завершения всей фразы. Он нужен для помощников и диалоговых интерфейсов, где задержка особенно заметна. Пользователь должен услышать начало ответа как можно быстрее.
Пакетная обработка
Пакетный режим подходит для аудиокниг, обучающих курсов и больших архивов уведомлений. Система получает набор текстов, формирует файлы и сохраняет результат для последующего использования.
Кэширование
Часто повторяющиеся реплики не нужно создавать каждый раз заново. Фразы Заказ принят, Подождите на линии и Операция завершена сохраняют в готовом виде. Динамические части, например имя и сумма, создают отдельно или соединяют по правилам продукта.
Контроль ошибок
Интеграция должна учитывать:
-
превышение лимита длины текста;
-
отсутствие нужного голоса;
-
временную недоступность сервиса;
-
неверный формат аудио;
-
ошибки авторизации;
-
слишком долгую обработку;
-
пустой текст;
-
неправильную кодировку.
Как оценить качество готовой озвучки
Прослушивание должно быть системным. Не ограничивайтесь первой минутой. Ошибки часто проявляются в середине длинного файла, на стыках, в списках и в предложениях с числами.
Разборчивость
Проверьте, понятны ли слова без напряжения. Согласные не должны сливаться, окончания — исчезать, а иностранные слова — превращаться в набор случайных звуков.
Естественность
Оцените ритм и паузы. Голос не должен спешить в длинном предложении и делать странную остановку перед служебным словом. Вопрос должен звучать как вопрос, а завершённая мысль — как завершённая.
Стабильность
Сравните соседние фрагменты. Убедитесь, что голос не меняет характер, скорость и громкость без причины. Особенно внимательно проверяйте материалы, которые создавались в несколько дней или несколькими авторами.
Техническое качество
Проверьте:
-
отсутствие щелчков;
-
отсутствие клиппинга;
-
ровную громкость;
-
корректную тишину в начале и конце;
-
подходящий формат;
-
нужную частоту дискретизации;
-
отсутствие лишнего фонового шума;
-
правильный порядок файлов.
Чек-лист перед публикацией
-
Текст вычитан.
-
Имена проверены.
-
Даты прослушаны.
-
Телефонные номера прослушаны.
-
Сокращения проверены.
-
Иностранные слова проверены.
-
Паузы исправлены.
-
Громкость выровнена.
-
WAV сохранён отдельно.
-
Финальная копия экспортирована.
-
Дорожка прослушана целиком.
Синтез речи, клонирование голоса и безопасность
Нейросетевой синтез делает цифровой голос убедительным. Это полезно для доступности, обучения и контент-производства, но требует осторожности при работе с узнаваемым тембром конкретного человека.
Получайте разрешение владельца голоса
Персонализированную модель создают только с согласия диктора. Условия использования фиксируют заранее: где будет звучать голос, как долго действует разрешение, разрешена ли коммерческая публикация, можно ли создавать новые фразы и кто хранит исходные записи.
Не используйте чужой тембр для обмана
Поддельная запись может имитировать родственника, руководителя, сотрудника банка или публичного человека. Такой аудиофайл применяют для социальной инженерии, вымогательства и манипуляций. Голосовое сообщение само по себе не подтверждает личность отправителя.
Проверяйте важные просьбы по другому каналу
Для семьи и команды полезна простая процедура:
-
Не переводить деньги после одного голосового сообщения.
-
Перезвонить человеку по сохранённому номеру.
-
Уточнить известный только участникам факт.
-
Использовать заранее согласованную кодовую фразу.
-
Передать подозрительную запись ответственному сотруднику.
Храните образцы речи безопасно
Чистые записи диктора ценны для обучения модели. Не размещайте их в открытом каталоге без необходимости. Ограничьте доступ, храните резервную копию и фиксируйте, кто получил файлы.
Маркируйте искусственно созданную озвучку в чувствительных сценариях
В образовательном, корпоративном и публичном материале полезно сообщать, что голос создан автоматически, когда это влияет на восприятие. Особенно важно избегать двусмысленности в новостях, финансовых сообщениях и обращениях от имени реального человека.
Частые вопросы
Синтез речи работает без интернета?
Да, когда используется локальный или системный движок. Облачные сервисы обрабатывают текст на сервере, поэтому им нужен интернет. Android и встроенные функции устройства работают в рамках возможностей установленного движка и загруженных голосовых данных.
Можно ли сохранить чтение Microsoft Edge в MP3?
Встроенная команда Read aloud предназначена для прослушивания страницы или PDF. Для создания MP3 используйте отдельный TTS-инструмент с экспортом.
Как исправить неверное ударение?
Используйте разметку ударения, фонетическую подсказку или другую запись слова. После исправления прослушайте предложение целиком: изменение одного слова иногда меняет ритм всей фразы.
Почему голос звучит роботизированно?
Причина находится в модели, вокодере, неподходящем голосе или плохо подготовленном тексте. Разбейте длинные предложения, уменьшите скорость, сравните другой голос и проверьте сложные слова.
Как озвучить длинную статью?
Разделите материал на главы и короткие фрагменты. Зафиксируйте единые настройки. Сохраняйте WAV, собирайте дорожку в редакторе и прослушивайте готовую главу целиком.
Какой формат выбрать для монтажа видео?
Используйте WAV. Он занимает больше места, но сохраняет качество и подходит для обработки. MP3 оставьте для публикации или отправки.
Что лучше для русскоязычной озвучки?
Выбор зависит от сценария. Для браузерной генерации с настройкой ударений подходит Yandex SpeechKit Playground. Для настольной работы с эмоциями и WAV подходит SaluteSpeech App. Для выразительной закадровой речи сравните ElevenLabs. Для длинного производственного проекта используйте Microsoft Audio Content Creation. Дополнительные варианты собраны в рейтинге нейросетей для озвучки текста голосом.
Чем TTS отличается от голосового помощника?
TTS отвечает только за создание речи. Голосовой помощник дополнительно распознаёт речь пользователя, определяет смысл команды, получает данные и формирует ответ.
Нужен ли SSML для каждого текста?
Нет. Для короткого нейтрального материала достаточно хорошей пунктуации. SSML нужен, когда требуется точно управлять паузами, темпом, высотой тона, акцентами и произношением сложных слов.
Можно ли использовать цифровую копию голоса другого человека?
Только с разрешения владельца и в согласованных сценариях. Узнаваемый тембр нельзя применять для имитации чужого заявления, обмана или давления на слушателя.
Итоги
Синтез речи — это не простое чтение букв вслух, а последовательная обработка текста. Система нормализует запись, разбирает структуру предложения, строит фонетическое представление, рассчитывает просодию, создаёт акустическую модель и формирует звуковую волну. Современные нейросети делают голос естественнее, но качество по-прежнему зависит от сценария и проверки результата.
Для быстрого прослушивания страницы достаточно Microsoft Edge. На смартфоне системный движок настраивается в Android. Yandex SpeechKit Playground удобен для русскоязычного аудиофайла через браузер. SaluteSpeech App подходит для настольной работы с эмоциями и WAV. ElevenLabs помогает создавать выразительные варианты. Microsoft Audio Content Creation удобен для длинных проектов и SSML.
Главное правило практической работы — не использовать первую генерацию без проверки. Делите текст на смысловые фрагменты, исправляйте ударения, приводите числа к понятной форме, сохраняйте WAV и прослушивайте дорожку целиком. Тогда цифровой диктор станет рабочим инструментом, а не источником случайных ошибок.
Чтобы оставить комментарий, авторизуйтесь или зарегистрируйтесь.