
CuneiForm OCR, он же Cognitive OpenOCR, — это не просто ещё одна программа распознавания текста, а классический настольный OCR-инструмент с очень узнаваемой логикой работы: загрузил изображение или получил страницу со сканера, задал язык, уточнил режим распознавания, проверил результат и вывел документ в редактируемый вид. Программа выросла из коммерческой системы Cognitive Technologies, затем стала freeware и открытой OCR-системой, а её сильная сторона — именно работа с печатными документами, где важны разметка страницы, таблицы, картинки и внятный вывод в текстовые форматы.
CuneiForm интересна тем, что у неё очень конкретная специализация. Она не пытается быть комбайном для PDF, совместной работы, рецензирования и электронных подписей. Это программа распознавания текста со скана и изображения, заточенная под офлайн-сценарий: открыть страницу, провести OCR, получить редактируемый текст, при необходимости сохранить структуру документа и отдельно обработать пачку файлов через batch-компонент. Именно поэтому обзор CuneiForm имеет смысл писать как обзор конкретной программы, а не как общий материал про OCR для Windows.
Скачать CuneiForm
- Редактирование PDF
- Русский интерфейс
- Просто для новичков
- Устаревшая программа
- Среднее качество OCR
- Редкие обновления
Что такое CuneiForm и чем программа ценна на практике
CuneiForm — это OCR-система, которая помимо собственно распознавания текста умеет выполнять layout analysis и text format recognition. Для пользователя это означает очень важную вещь: программа старается не только вытащить символы, но и понять структуру страницы — где обычный текст, где графика, где таблица, где одноколоночный макет, а где сложная полоса. Для старой десктопной OCR-программы это принципиально: чем лучше она понимает страницу, тем меньше ручной правки понадобится после распознавания.
Программа была разработана Cognitive Technologies как коммерческий OCR-продукт, позже перешла в freeware-режим, а ядро OCR-движка стало доступно под BSD-лицензией. Вокруг неё существовали и Windows-версия с собственным графическим интерфейсом, и Linux-порт, причём Linux-направление рассматривалось как перенос оригинального Windows-движка на другие платформы. Это важный момент для понимания характера CuneiForm: её интерфейс и рабочий поток — именно из эпохи классических OCR-утилит, где всё подчинено задаче распознавания, а не сервисной экосистеме.
Если говорить совсем прямо, CuneiForm сильна там, где у пользователя есть печатная страница, скан, копия документа, фотография страницы или набор изображений, из которых нужно получить редактируемый текст. Она умеет работать с файлами изображений с диска и со сканером, поддерживает spell check, умеет искать таблицы и картинки в структуре страницы, а результат может выводить в RTF и другие форматы, пригодные для дальнейшего редактирования. Это и есть её основная зона пользы.
Для каких задач подходит CuneiForm
Наиболее естественный сценарий для CuneiForm — распознавание текста со скана, сделанного на планшетном сканере или МФУ. Если у вас есть офисный документ, договор, статья, инструкция, бухгалтерская форма, распечатка, отпечаток на матричном принтере или старый факс, программа распознавания текста CuneiForm даёт понятный рабочий процесс: загрузить страницу, задать язык, включить или отключить поиск таблиц и картинок, выполнить OCR, затем сохранить результат в редактируемый формат.
Вторая сильная задача — распознавание текста с изображения. CuneiForm открывает типовые графические файлы вроде JPG, BMP и PNG и обрабатывает их как источник OCR. Это удобно, когда документ уже получен не через сканер, а как фотография или экспортированная картинка. При этом программа ориентирована именно на изображение страницы, а не на богатый PDF-пайплайн: если исходник уже живёт как скан внутри PDF, то логика CuneiForm значительно менее современная и менее удобная, чем у новых конкурентов.
Отдельно стоит выделить работу с нетипичными, но до сих пор встречающимися источниками: факсы и документы с dot matrix printer. В CuneiForm для них есть не абстрактные обещания, а отдельные режимы Fax и Dot matrix printer. Это очень характерная особенность программы. Она показывает, что CuneiForm исторически проектировалась не только под идеальные книжные сканы, но и под реальные офисные документы с шумом, плохой печатью и низким качеством исходника.
Третий важный сценарий — таблицы. Для CuneiForm тема таблиц не декоративная: и в описаниях, и в интерфейсе программы есть отдельная логика для таблиц, а batch-компонент умеет ориентироваться на табличный вывод. Это не значит, что программа превращает любую сложную таблицу в идеальную электронную таблицу без ручной правки, но по логике работы CuneiForm видно, что табличная структура страницы для неё — не второстепенный случай.
Не менее важна и многоязычность. CuneiForm поддерживает 23 языка распознавания и отдельный смешанный режим ruseng для документов, где русский и английский живут на одной странице. Для русскоязычного документооборота это практическая вещь, а не формальность: счета, инструкции, каталоги, технические листы и внутренние документы очень часто содержат английские термины, артикулы, модели и служебные сокращения. Если нужен OCR CuneiForm именно для таких страниц, смешанный русско-английский режим — одно из самых полезных достоинств программы.
Поддерживаемые языки, форматы и общий профиль программы
Языковой набор у CuneiForm действительно широкий для лёгкой OCR-программы. Поддерживаются Bulgarian, Czech, Danish, Dutch, English, Estonian, French, German, Croatian, Hungarian, Italian, Latvian, Lithuanian, Polish, Portuguese, Romanian, Russian, Slovenian, Spanish, Serbian, Swedish, Turkish и Ukrainian, а отдельно вынесен режим mixed Russian/English. Для задачи распознавание текста со скана этого набора более чем достаточно, особенно если речь идёт о латинице и кириллице.
По входу программа ориентируется на одностраничные изображения и на работу со сканером. В Windows GUI CuneiForm без проблем укладывается в классическую схему Open image или Scan, а Linux-движок работает с тем, что умеет открыть GraphicsMagick. Для обычного пользователя это переводится на простой язык: CuneiForm любит страницы как картинки, а не сложные контейнеры документов. Именно поэтому она ощущается как инструмент для OCR изображения, а не как современный центр управления PDF-файлами.
По выводу у движка CuneiForm есть несколько форматов: plain text, RTF, HTML, hOCR, native и smarttext. В Windows-сценариях особенно заметны RTF и текстовые форматы, а batch-мастер показывает ещё и варианты, связанные с табличным выводом и внутренним форматом проекта. Для практики это значит следующее: CuneiForm не запирает пользователя внутри своего интерфейса, а отдаёт результат наружу в редактируемый вид.
Интерфейс CuneiForm: как устроена программа
Главное окно CuneiForm не производит впечатления современного софта, но быстро даёт понять, чем программа занимается. Верхняя часть интерфейса аскетична, рядом с меню стоят крупные кнопки панели инструментов, а центральная логика крутится вокруг запуска мастера распознавания, работы со сканером, просмотра страницы и вывода результата. Это очень настольный OCR-интерфейс старой школы: без лишней графики, но с акцентом на последовательность действий.
Первый элемент, который действительно имеет смысл нажимать, — Recognition Wizard. В CuneiForm это не второстепенный помощник, а фактически основной вход в программу. Через него пользователь сразу выбирает источник изображения, язык, параметры OCR и дальше доходит до результата без блуждания по десяткам настроек. Для новичка это удобно, для опытного пользователя — быстро. Именно поэтому CuneiForm воспринимается как программа, где OCR начинается не с бесконечной подготовки проекта, а с конкретного мастера.
Мастер Recognition Wizard
Ниже — типичный экран мастера, на котором задаётся источник страницы: файл изображения или сканер.
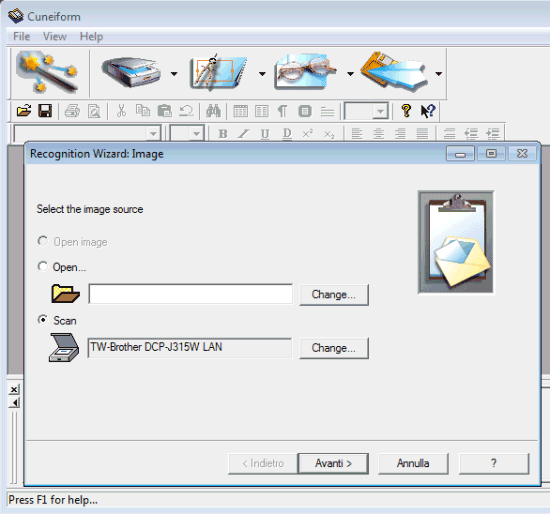
На этом шаге CuneiForm показывает вполне конкретные элементы: заголовок Recognition Wizard: Image, блок Select the image source, варианты Open image и Scan, поля выбора и кнопки Change..., а внизу — стандартные Next >, Cancel и кнопка справки. Такой экран хорошо объясняет философию программы: сначала источник, потом параметры, потом распознавание. Для OCR-софта это правильная логика, потому что пользователь сразу понимает, с чем именно будет работать движок — с файлом или со сканером.
Практическая ценность этого шага ещё и в том, что CuneiForm не прячет работу со сканером где-то в меню. Источник документа задаётся в лоб. Нужен файл — открываете изображение. Нужен сканер — выбираете устройство. Для программы распознавания текста со скана это куда лучше, чем интерфейс, в котором OCR-функция спрятана за десятым пунктом настроек.
Окно параметров распознавания
Следующий важный экран — это собственно настройка OCR. Здесь CuneiForm уже перестаёт быть просто кнопкой распознать и показывает, за счёт чего она справляется с разными типами документов.
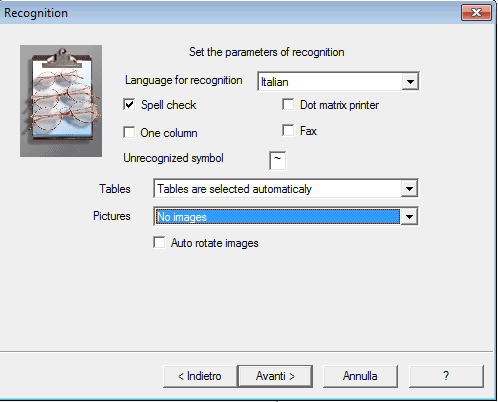
На этом окне видны те самые рабочие параметры, которые и делают CuneiForm конкретной программой, а не обезличенным OCR-движком. Здесь есть Language for recognition, флажки Spell check, Dot matrix printer, One column, Fax, поле Unrecognized symbol, выпадающие параметры для Tables и Pictures, а также Auto rotate images. Уже по одному этому экрану видно, что программа умеет подстраиваться под тип документа, а не только запускать распознавание в одном универсальном режиме.
Spell check полезен там, где нужен быстрый черновой OCR с автоматическим сглаживанием очевидных ошибок. One column стоит включать для обычной статьи, письма, договора или служебной страницы без сложной верстки: это отключает анализ многоколоночной структуры и помогает программе не переусложнять разметку. Dot matrix printer — режим под распечатки с характерной точечной структурой, а Fax — под факсовые страницы с низким качеством передачи. Всё это звучит старомодно, но на практике как раз и показывает, что CuneiForm умеет работать с реальными бумажными архивами, а не только с идеальными PDF.
Параметры Tables и Pictures важны не меньше. В CuneiForm вопрос искать таблицы и картинки или нет не декоративный. Если страница действительно табличная, включённый поиск таблиц даёт программе шанс корректнее разметить структуру документа. Если картинок нет, их поиск можно не навязывать. Это тот случай, когда правильная настройка OCR прямо влияет на качество результата и на объём последующей правки.
Как работать в CuneiForm: пошаговый сценарий
Рабочий сценарий в CuneiForm лучше всего описывать как последовательность конкретных действий, потому что программа сама устроена именно так. Здесь нет ощущения, что надо сначала долго изучать интерфейс. У неё понятный маршрут, и если придерживаться его, OCR проходит предсказуемо.
1. Запуск мастера
После открытия программы первым делом стоит запускать Recognition Wizard. Для CuneiForm это правильная точка входа. Через мастер вы не пропускаете выбор источника и сразу приходите к настройкам, которые действительно влияют на распознавание текста с изображения или со скана.
2. Выбор источника: Open image или Scan
Если страница уже сохранена как JPG, BMP или PNG, логично идти через Open image. Если документ ещё лежит на бумаге, выбирается Scan и нужное устройство. Такой шаг кажется очевидным, но именно он определяет всю дальнейшую стабильность OCR: CuneiForm заметно лучше чувствует себя там, где источник страницы прозрачен и предсказуем.
3. Настройка языка
После выбора источника нужно задать Language for recognition. Это критический пункт. Для русскоязычного документа выбирается русский, для англоязычного — английский, а для смешанных страниц с русским и английским текстом — русско-английский режим. Если документ содержит технические обозначения, англоязычные артикулы и русские подписи, смешанный режим особенно полезен. Для OCR CuneiForm это один из самых практичных вариантов настройки, и его нельзя игнорировать.
4. Включение нужных режимов OCR
Дальше нужно не лениться и посмотреть на флажки. Если перед вами обычная одноколоночная страница, включение One column часто помогает. Если источник — старая офисная распечатка с характерной точечной печатью, нужен Dot matrix printer. Если это плохой факс — Fax. Если на странице есть таблицы, оставляйте их поиск включённым. Если иллюстрации не нужны и только мешают разметке, работу с ними можно упростить. Именно здесь CuneiForm показывает, что умеет не просто читать буквы, а учитывать тип документа.
5. Запуск распознавания
После настройки параметров запускается сам OCR-проход. В этот момент CuneiForm уже не угадывает всё подряд, а работает по заранее заданному профилю страницы. Для старых OCR-программ это ключевой принцип: чем точнее пользователь описал документ, тем лучше результат. На хороших печатных страницах это особенно заметно, потому что программа не тратит усилия на лишние предположения о структуре.
6. Проверка результата
После распознавания результат нужно читать глазами. Это касается любой OCR-программы, но для CuneiForm особенно важно. Программа умеет spell checking и старается удерживать структуру документа, однако идеального OCR без проверки не бывает. В типовом сценарии после распознавания пользователь быстро просматривает абзацы, заголовки, цифры, таблицы и подозрительные места, а затем уже сохраняет документ.
7. Сохранение в редактируемый формат
Финальный шаг — вывод результата наружу. Именно здесь CuneiForm оправдывает своё назначение: распознанный текст можно забрать в RTF, текстовый формат или другой пригодный для дальнейшей правки вариант. Если задача была превратить скан в редактируемый документ, на этом этапе она фактически выполнена.
Что действительно влияет на качество распознавания
Самая частая ошибка при работе с CuneiForm — относиться к ней как к полностью автоматической магии. Это не та программа, где стоит бездумно жать одну кнопку. У CuneiForm качество результата очень чувствительно к правильному выбору режима, и в этом есть как её слабость, так и сила. Слабость — потому что нужен минимум осознанности. Сила — потому что при корректной настройке программа ведёт себя лучше, чем слепой OCR в универсальном режиме.
Language for recognition — настройка номер один. Ошибка на этом этапе почти гарантированно ударяет по качеству OCR сильнее, чем любая другая мелочь. Если у документа смешанный язык, не надо принудительно загонять его в чистый русский или чистый английский профиль. Если страница на одном языке, наоборот, не стоит без нужды включать смешанный режим. Чем ближе язык OCR к реальному содержимому страницы, тем меньше мусора в результате.
One column особенно полезен на простых страницах: книги, письма, акты, договоры, инструкции. Когда колонок нет, эта опция помогает не переоценивать сложность макета. Но если страница реально двухколоночная или табличная, бездумное включение One column может сломать разметку. В CuneiForm это надо понимать буквально: настройка не косметическая, а структурная.
Dot matrix printer и Fax — редкие по современным меркам, но крайне показательные параметры. Они подтверждают, что CuneiForm ориентирована на проблемный бумажный источник. Если вы оцифровываете старые отчёты, архивные распечатки, факсовые копии и ведомости, эта программа потенциально полезнее, чем многие красивые OCR-утилиты, где таких режимов вообще нет как класса.
Spell check стоит включать в большинстве нормальных сценариев, где нужен связный печатный текст. Он не заменяет ручную вычитку, но заметно сокращает количество очевидных ошибок. При этом проверку орфографии не нужно переоценивать: если исходный скан грязный или страница плохо снята, орфографический словарь уже не спасёт сломанную структуру слова. Он исправляет мелкие промахи, а не фундаментально плохой OCR.
Параметры Tables и Pictures влияют прежде всего на структуру. Если документ табличный, их лучше не игнорировать. CuneiForm как раз сильна тем, что не пытается свести любую страницу к плоскому тексту. Но если на странице нет ценных иллюстраций, а нужны только буквы и цифры, избыточный поиск картинок может не помочь, а только усложнить макет. В этом смысле CuneiForm — программа, которая любит адекватно подготовленный сценарий.
Качество OCR: где CuneiForm сильна, а где слабее
На чистом печатном тексте CuneiForm выглядит вполне убедительно даже по современным меркам для бесплатного OCR. Программа заточена под печатные документы, умеет выполнять анализ макета и распознавание форматирования, а также использует словарную проверку. Это хорошее сочетание для обычных офисных страниц, книг, инструкций и архивных распечаток. Здесь CuneiForm работает как добротная классическая OCR-программа: без изысков, но по делу.
На сложной журнальной верстке, разноуровневых блоках, современных брошюрах и перегруженных PDF-сценариях программа уже воспринимается более ограниченной. Причина не в том, что CuneiForm вообще не умеет макет, а в том, что её макетная логика — это логика старой школы: она хорошо чувствует базовую структуру, но не превращается в полноценный современный редактор документов. Там, где нужно не просто OCR, а ещё и последующая глубокая работа с PDF, сравнение документов, формы, комментарии и защита, CuneiForm объективно не про это.
С таблицами у CuneiForm ситуация интереснее. Программа действительно умеет учитывать табличную структуру страницы, а её batch-компонент показывает, что табличный вывод для неё — не случайность. Поэтому на документах с умеренно сложными таблицами CuneiForm выглядит полезнее, чем многие совсем простые OCR-утилиты, которые без разбора превращают всё в поток текста. Но ждать от неё уровня современного офисного парсинга с почти безошибочным переносом любой сложной сетки тоже не стоит. Это хорошая табличная OCR-программа старой школы, а не волшебный конвертер бухгалтерии в идеальную электронную форму.
На плохих факсах, старых копиях и dot-matrix распечатках CuneiForm чувствует себя на удивление органично именно потому, что у неё есть специальные режимы под такие источники. Это не значит, что она чудесно восстановит безнадёжную страницу. Но в сравнении с OCR-утилитами, где таких профилей просто нет, CuneiForm выглядит более предметным инструментом для архивной и офисной рутины.
С рукописным текстом, декоративной типографикой и сильно нестандартными документами CuneiForm, наоборот, не стоит переоценивать. Вся архитектура программы, набор опций и общий профиль движка говорят о печатных документах, а не о handwriting OCR. Если нужна именно работа с рукописью, сложными формами, мобильными фото без подготовки и перегруженными PDF-потоками, CuneiForm лучше сразу воспринимать как не тот инструмент.
Работа со сканером: сильные стороны и ограничение TWAIN
CuneiForm умеет брать страницу напрямую со сканера, и это один из её базовых сценариев. В мастере источник выбирается явно, а дальше программа может вести пользователя по настройке распознавания. Для человека, который работает именно со сканами, это удобно: не нужно сначала прогонять документ через десяток внешних этапов, если устройство корректно определяется и отдаёт изображение.
Но здесь есть и очень конкретное ограничение. CuneiForm не всегда корректно дружит со всеми современными TWAIN-драйверами. В ряде случаев сканирование стартует, а потом заканчивается сообщением Can’t save the image. Это важный практический минус программы: теоретически сканер поддерживается, но в реальном рабочем процессе надёжность связки может зависеть от конкретного устройства и драйвера. Для старого OCR-софта это типичная проблема, и её нужно честно учитывать.
Если сканерный путь дал сбой, нормальная схема для CuneiForm — сначала получить изображение любой стабильной сканирующей утилитой, а потом уже кормить программе готовые картинки. С точки зрения результата это не трагедия: CuneiForm в любом случае любит именно изображения страниц. Но с точки зрения удобства становится понятно, что это OCR-решение рассчитано на пользователя, который готов чуть-чуть управлять процессом, а не только нажимать одну кнопку в идеальном современном интерфейсе.
Отдельно нужно помнить про PDF. CuneiForm не выглядит полноценным инструментом для OCR PDF-файлов со сканированными страницами как исходным контейнером. Её естественный вход — это либо сканер, либо изображение. Поэтому если рабочий архив у вас уже собран в многостраничных PDF, CuneiForm придётся подстраивать под этот сценарий обходными путями, и в таком режиме современные аналоги уже удобнее.
Пакетное распознавание: второй важный компонент программы
Одна из недооценённых сторон CuneiForm — наличие отдельного batch-компонента. Это не встроенная мелочь в стиле пакетный режим somewhere in menu, а фактически отдельный сценарий работы с множеством файлов. Для тех, кто обрабатывает сразу пачку страниц, это одна из самых полезных функций программы.
Ниже — старт batch-мастера.
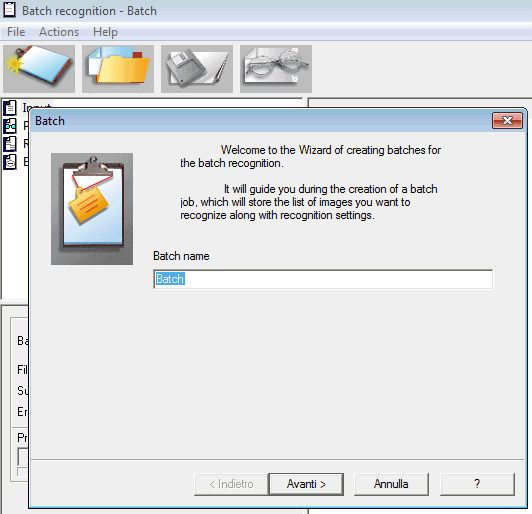
Этот экран показывает, что пакетный режим в CuneiForm устроен довольно последовательно: пользователь создаёт batch job, задаёт имя процедуры и дальше ведёт программу по шагам. Это хороший подход для архивов, договорных папок, технической документации и любых наборов страниц, которые неудобно распознавать по одной. Вместо хаотического запуска OCR на каждом файле CuneiForm даёт отдельную механику под серию документов.
После создания batch-процедуры программа просит задать язык, указать наличие таблиц и изображений, затем выбрать папку с файлами, а после этого — решить, что делать с исходниками и в какие форматы сохранять результат. По сути, это уже не просто OCR одной страницы, а маленький конвейер распознавания. Для бесплатной OCR-программы это серьёзный плюс, особенно когда поток документов идёт через один и тот же шаблон.
Выгрузка результата в batch-режиме
Ниже — финальный шаг batch-мастера с выбором форматов сохранения.
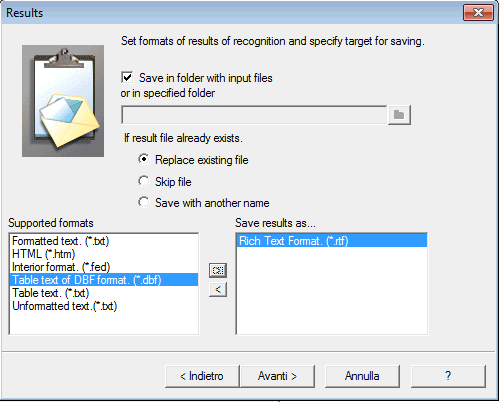
На этом экране видно, что CuneiForm в пакетном режиме ориентируется не на один-единственный выходной формат. Среди доступных вариантов просматриваются Rich Text Format \*.rtf\*.rtf\*.rtf, HTML \*.htm\*.htm\*.htm, Formatted text \*.txt\*.txt\*.txt, Unformatted text \*.txt\*.txt\*.txt, внутренний формат \*.fed\*.fed\*.fed и варианты, связанные с табличным выводом. Это лишний раз подчёркивает специфику программы: она не запирает OCR-результат в своём документе, а готова отдавать его в редактор, текстовый поток или табличную обработку.
Для реальной работы это означает простую вещь. Если вам нужно массово распознать набор договоров, инструкций, ведомостей или писем и сразу получить RTF либо HTML, CuneiForm решает задачу без тяжёлой экосистемы вокруг. Её batch recognition — это не корпоративная автоматизация уровня ECM, но для локального офлайн-сценария она вполне рабочая и логичная.
Экспорт и дальнейшее редактирование
Смысл OCR не в самом факте распознавания, а в том, чтобы с результатом можно было что-то делать дальше. В этом отношении CuneiForm работает правильно: текст можно отдавать в редактируемые форматы, а значит — править, дооформлять, копировать, отправлять в Word-совместимую среду, вытаскивать фрагменты в рабочие документы и так далее. Программа ценна не тем, что видит буквы, а тем, что переводит бумагу в рабочий цифровой текст.
Если сравнивать чисто утилитарно, CuneiForm особенно хороша там, где после OCR нужен не красивый PDF-архив, а нормальный редактируемый текст. Для офиса, архива, учебной работы, переноса старых распечаток в электронный вид это часто важнее, чем десятки сопутствующих функций. Взяли скан, сделали OCR, получили RTF, поправили ошибки, сохранили итоговый документ — именно в таком маршруте CuneiForm выглядит убедительно.
При этом от экспорта не стоит ждать чудес. Если страница была сложной, многоблочной, с хитрой версткой, то даже при неплохом OCR после выгрузки почти наверняка понадобится ручная доводка. Но это уже не недостаток именно CuneiForm, а нормальная реальность OCR-класса как такового. Важнее другое: программа даёт основу для правки, а не мёртвую картинку.
Сравнение с аналогами
Если сравнивать CuneiForm не абстрактно, а с реальными программами-аналогами, картина получается довольно чёткой. У неё есть узнаваемая ниша, и она не обязана побеждать в каждом параметре, чтобы оставаться полезной. Важно понимать, где именно она сильнее по логике работы, а где уступает современным решениям. Сопоставление ниже опирается на функциональность самих продуктов: ABBYY FineReader PDF как полноценной PDF/OCR-платформы, gImageReader как GUI для Tesseract, NAPS2 как сканерно-OCR-системы и OCRFeeder как layout-oriented OCR-инструмента.
ABBYY FineReader PDF
ABBYY FineReader PDF — это решение другого веса и другого класса. Оно умеет не только OCR, но и редактирование PDF, создание форм, согласование, сравнение документов, защиту и подписание, а OCR в нём встроен в более широкую документную платформу. По сравнению с ним CuneiForm выглядит гораздо уже: это не PDF-центр, а конкретная OCR-программа для распознавания текста с изображений и сканов.
Но именно из этого сравнения видно главное достоинство CuneiForm. Если задача узкая — извлечь текст из скана, получить редактируемый документ, обработать архив распечаток, включить режим под факс или матричную печать — CuneiForm проще и прямолинейнее. Она не перегружает пользователя функциями, которые ему не нужны. ABBYY — это целая экосистема PDF и OCR; CuneiForm — это OCR как самостоятельный инструмент. Когда нужен именно второй вариант, её прямота оказывается плюсом.
По качеству, удобству сложной верстки и современному уровню обработки документов ABBYY заметно сильнее. По простоте входа в чистый офлайн-OCR на старом рабочем месте, где важны сканы, картинки, таблицы и RTF, CuneiForm остаётся вполне осмысленной. Здесь нельзя честно сказать, что одна программа просто лучше другой. Они решают задачи разной ширины.
gImageReader
gImageReader — это уже другой тип конкурента. Он работает как front-end к Tesseract, умеет импортировать PDF и изображения с диска, со сканирующих устройств, из буфера обмена и со скриншотов, поддерживает пакетную обработку, ручное и автоматическое выделение зон, plain text и hOCR, выводит распознанный текст рядом с изображением и умеет постобработку со spellchecking. По широте современного открытого OCR-workflow gImageReader выглядит заметно гибче.
На этом фоне CuneiForm выглядит более узкой и более старомодной, но одновременно и более цельной как отдельная OCR-программа. В ней не нужно думать, что под капотом Tesseract, как лучше построить зону распознавания и какой workflow выбрать между hOCR и PDF. CuneiForm проще в том смысле, что у неё меньше развилок: мастер, язык, режим, OCR, экспорт. Это делает её понятной для пользователей, которым нужен не конструктор OCR-процесса, а программа распознавания текста как готовый прикладной инструмент.
Если нужен именно современный open-source OCR для PDF, скриншотов, многостраничных импортов и гибкой разметки, gImageReader объективно интереснее. Если нужен лёгкий и прямой OCR по классической модели страница → параметры → результат, CuneiForm выигрывает простотой маршрута.
NAPS2
NAPS2 — это прежде всего очень сильная сканирующая программа, которая умеет сканировать в PDF, TIFF, JPEG и PNG, работать с WIA и TWAIN, поддерживает ADF, обрезку, поворот, deskew, редактирование страниц и OCR для создания searchable PDF на более чем 100 языках. По сути, NAPS2 — это scanner-first workflow, в котором OCR встроен как часть большого пути от устройства к готовому PDF.
CuneiForm устроена наоборот. Она OCR-first. Сканер для неё важен, но не как центр экосистемы, а как один из способов получить изображение. Поэтому при сравнении этих программ очень важно не перепутать жанр. NAPS2 удобнее как универсальный сканирующий центр и инструмент для searchable PDF. CuneiForm удобнее как специализированная OCR-программа, где пользователь сознательно работает с языком, структурой страницы, таблицами, картинками, факсом и dot-matrix-профилями.
Если в вашем процессе главное — быстро сканировать, собирать PDF и делать его поисковым, NAPS2 выглядит рациональнее. Если в центре процесса именно распознавание текста с изображения и вывод в редактируемый формат, а не PDF-архивация, у CuneiForm остаётся свой смысл.
OCRFeeder
OCRFeeder интересен тем, что сам по себе тоже ориентирован на layout analysis: он автоматически обводит содержимое страницы, различает текст и графику, умеет импортировать PDF, сохранять проект, экспортировать результат в несколько форматов, а основным форматом для него является ODT. В этом смысле OCRFeeder ближе к CuneiForm по философии, чем тот же NAPS2.
Но OCRFeeder ощущается как более современная и более открытая площадка для ручной корректировки областей, рамок и проекта документа. CuneiForm же предлагает более прямой, но и более жёсткий маршрут. Она удобна, когда нужно быстро провести OCR и не тратить время на длинную настройку макета. OCRFeeder интереснее тогда, когда пользователь готов глубже вмешиваться в зоны распознавания и выравнивать структуру документа вручную.
В итоге CuneiForm против OCRFeeder — это выбор между быстрой классической OCR-программой и более гибким layout-aware инструментом open-source среды. В первом случае побеждает CuneiForm, во втором — OCRFeeder.
Плюсы CuneiForm
У CuneiForm есть несколько сильных сторон, которые и делают её интересной даже на фоне более новых решений.
-
Чёткая специализация. Это именно OCR-программа, а не распылённый PDF-комбайн.
-
Понятный мастер Recognition Wizard. Для старта не нужно изучать половину интерфейса. Путь через мастер короткий и логичный.
-
Поддержка таблиц и картинок как элементов структуры страницы. Это серьёзно повышает практическую ценность на деловых документах и инструкциях.
-
Специальные режимы Fax и Dot matrix printer. Очень редкая, но реально полезная вещь для старых распечаток и архивов.
-
23 языка плюс смешанный русско-английский режим. Для русскоязычного документооборота это большое преимущество.
-
Spell check. Не панацея, но хорошая страховка от части типовых OCR-ошибок.
-
Отдельный batch-компонент. Для серийной обработки документов это намного удобнее, чем распознавать всё по одному файлу.
-
Вывод в редактируемые форматы. RTF, текстовые и HTML-сценарии делают программу пригодной не только для просмотра, но и для нормальной дальнейшей работы.
Минусы CuneiForm
Недостатки у программы тоже вполне конкретные, и их нельзя замалчивать.
-
Старый интерфейс. Он рабочий, но визуально и логически принадлежит прошлой эпохе настольных утилит.
-
Не самый удобный путь для PDF-сценариев. CuneiForm естественно работает со сканером и изображениями, а не с полноценным PDF-потоком.
-
Проблемы совместимости со сканерами через TWAIN. Ошибка
Can’t save the image— не теоретическая мелочь, а практический риск. -
Ограниченность как современной документной среды. В ней нет того уровня PDF-редактирования, сравнения, совместной работы и защиты, который есть у ABBYY FineReader PDF.
-
Не лучший выбор для рукописей и перегруженных современных макетов. Архитектура программы заточена под печатные документы.
Кому CuneiForm подходит лучше всего
CuneiForm хорошо подходит тем, кто работает с бумажными архивами, офисными распечатками, инструкциями, договорами, бланками и старой документацией, где нужен именно OCR офлайн и именно редактируемый результат. Если пользователь привык мыслить категориями скан/изображение → текст/RTF, а не облачный PDF-workflow, программа ложится в задачу очень органично.
Она также подходит тем, кто хочет бесплатную OCR-программу с ясной логикой и не нуждается в тяжёлой экосистеме вокруг документа. В этом смысле CuneiForm ближе к инструменту, чем к платформе. И это часто плюс, а не минус.
Особенно уместна CuneiForm там, где встречаются смешанные русско-английские документы, табличные страницы, старые копии, факсы и матричные распечатки. Для таких сценариев в ней есть не абстрактные обещания, а конкретные режимы и настройки. Это делает обзор CuneiForm не просто ностальгией по старому OCR-софту, а разговором о реально прикладном инструменте.
Кому лучше выбрать другой инструмент
Если основной документный поток уже живёт в PDF, нужен searchable PDF как основной результат, важно стабильное сканирование через современные драйверы и нужна массовая рутинная работа именно со сканером, рациональнее смотреть на NAPS2. Он лучше решает сканерный цикл как таковой.
Если нужен современный open-source OCR с импортом PDF, поддержкой скриншотов, hOCR и гибкой работой с зонами распознавания, логичнее выбрать gImageReader. Если требуется более визуальный layout-based open-source инструмент с сохранением проекта и ручной доводкой зон, лучше смотрится OCRFeeder. Если нужен большой профессиональный PDF/OCR-комбайн с мощной экосистемой, сравнение почти автоматически уводит к ABBYY FineReader PDF.
Итог
CuneiForm OCR — это добротная классическая программа распознавания текста, которая не распыляется на лишние роли. Её сильные стороны очень конкретны: понятный Recognition Wizard, работа со сканером и изображениями, spell check, поддержка таблиц и картинок, отдельные режимы Fax и Dot matrix printer, пакетное распознавание и вывод в редактируемые форматы. Она хорошо показывает себя как OCR для Windows в старом, но до сих пор практичном смысле этого слова: взять бумажную страницу и превратить её в текст, с которым уже можно работать.
Главный вывод по CuneiForm такой: это не универсальная PDF-платформа и не современный визуальный редактор документов. Это конкретная OCR-программа со своим характером. Там, где нужен чистый, понятный, офлайн-ориентированный workflow для распознавания текста со скана и изображения, она остаётся полезной. Там, где нужны продвинутые PDF-сценарии, тонкая работа с современными форматами и безусловная совместимость со всем новым железом, у неё уже начинаются ограничения. Но как специализированный инструмент CuneiForm по-прежнему заслуживает внимательного взгляда — именно потому, что она честно делает то, ради чего вообще ставят OCR-софт.