
Cognitive OpenOCR CuneiForm — это программа для оптического распознавания текста, которая превращает отсканированные страницы, изображения документов и графические файлы с печатным текстом в редактируемый текст. Это не просто еще одна OCR-утилита, а конкретная система распознавания с собственной историей, отдельным движком, графическим интерфейсом для Windows и консольным применением в Linux-среде.
Главная задача OCR CuneiForm — взять изображение, найти на нем текстовые блоки, определить структуру страницы, распознать символы и выдать результат в формате, который можно открыть в текстовом редакторе, офисной программе или использовать в дальнейшей обработке. В программе есть не только базовое извлечение текста, но и анализ разметки страницы, распознавание текстового формата, выбор языка, режимы для факсов и матричной печати, а также сохранение результата в нескольких форматах, включая plain text, RTF, HTML и hOCR.
CuneiForm особенно интересна тем, что она изначально создавалась как полноценная OCR-система для документов, а не как простая утилита картинка в текст. Поэтому программа пытается работать не только с буквами, но и с общей логикой страницы: колонками, таблицами, картинками, шрифтами и блоками. Это важное отличие от примитивных OCR-инструментов, которые просто проходят по изображению и выдают сплошной поток символов.
При этом CuneiForm нельзя воспринимать как современный PDF-комбайн. Это возрастная, практичная и местами грубая программа для распознавания печатных документов. Она полезна там, где нужно локально обработать сканы, получить редактируемый текст, сохранить базовую структуру документа и не зависеть от облачных сервисов. Но для сложных PDF, рукописей, фотографий с телефона и документов с тяжелой современной версткой лучше сразу оценивать ограничения.
Скачать OCR CuneiForm
- Работа с PDF
- Редактирование документов
- Совместимость Windows/Linux
- Только распознавание текста
- Сложный интерфейс
- Нет редактирования PDF
Что такое Cognitive OpenOCR CuneiForm
Название программы встречается в нескольких вариантах: CuneiForm, Cognitive OpenOCR, OCR CuneiForm, CuneiForm OpenOCR. В обзоре речь идет об одной и той же OCR-системе, разработанной Cognitive Technologies. В Windows-среде пользователь чаще сталкивается с графической программой Cognitive OpenOCR CuneiForm, а в Linux — с командой cuneiform, которую можно запускать из терминала или подключать к графическим оболочкам.
По назначению CuneiForm относится к программам OCR, то есть к системам оптического распознавания символов. Она берет изображение текста и превращает его в машинно-читаемый текст. Это нужно в ситуациях, когда документ существует только в виде скана, фотографии, TIFF-файла, JPEG-картинки или другого графического файла, но его нужно редактировать, копировать, искать по нему слова или переносить в Word, LibreOffice Writer, базу данных, архив или систему документооборота.
CuneiForm не является PDF-редактором в современном смысле. Она не предназначена для полноценной правки PDF-страниц, аннотирования, подписания документов или сложной работы с формами. Ее рабочая зона — распознавание текста. Если документ отсканирован как картинка, программа помогает получить из него текстовый слой или редактируемый результат.
Программа выполняет несколько действий:
-
анализирует страницу и ищет текстовые области;
-
определяет фрагменты с таблицами и изображениями;
-
распознает буквы, цифры и знаки препинания;
-
учитывает выбранный язык распознавания;
-
формирует результат в выбранном формате;
-
позволяет сохранить распознанный текст для дальнейшей правки.
CuneiForm ценна именно как локальная программа для распознавания текста. Ей не нужен интернет для базовой OCR-обработки, она не отправляет документы в облако и может использоваться в закрытых рабочих сценариях, где сканы нельзя загружать в онлайн-сервисы.
История и место программы среди OCR-инструментов
CuneiForm появилась как коммерческая OCR-система Cognitive Technologies, а затем стала открытым и свободно распространяемым решением. Linux-порт CuneiForm описывается как многоязычная OCR-система, изначально разработанная и открытая Cognitive Technologies; первоначально это была Windows-программа, позднее перенесенная на Linux.
Эта история объясняет главное свойство программы: CuneiForm выглядит как продукт из эпохи классического настольного OCR. В ней нет современного интерфейса с крупными плитками, облачной синхронизации, встроенного хранилища документов и автоматического распознавания по нажатию одной большой кнопки. Зато есть понятная логика старых офисных программ: меню, панели инструментов, окно изображения, область результата, настройки сканирования, выбор языка и сохранение в офисный формат.
В Linux-сценариях CuneiForm стала скорее OCR-движком, чем самостоятельным приложением с богатым интерфейсом. Ее можно запускать из командной строки, использовать в скриптах, подключать к оболочкам и автоматизировать обработку документов. Консольная версия принимает входной файл, параметры языка, формат вывода и имя результата.
Такой подход делает CuneiForm удобной для тех, кто работает с пачками сканов и хочет встроить распознавание в простой конвейер: изображение на входе, текстовый файл или RTF на выходе. Для обычного пользователя Windows важнее графический интерфейс, а для администратора, разработчика или Linux-пользователя — возможность вызвать OCR из терминала.
Для каких задач подходит OCR CuneiForm
CuneiForm лучше всего подходит для распознавания печатного текста. Это могут быть страницы книг, инструкции, договоры, старые офисные документы, архивные материалы, технические тексты, распечатки, факсы и сканы с обычного планшетного или протяжного сканера.
Типовые задачи программы:
-
распознать страницу книги и получить редактируемый текст;
-
извлечь текст из отсканированного договора;
-
перевести изображение документа в TXT или RTF;
-
обработать русскоязычный или англоязычный скан;
-
распознать смешанный русско-английский документ;
-
получить HTML или hOCR для дальнейшей обработки;
-
обработать одноколоночный документ без сложной верстки;
-
распознать факс в специальном режиме;
-
распознать текст, напечатанный матричным принтером;
-
сохранить результат для редактирования в офисной программе.
CuneiForm полезна в случаях, когда исходный документ выглядит как нормальная сканированная страница: ровная ориентация, достаточное разрешение, хороший контраст, четкие буквы, без сильных теней и размытия. Чем ближе изображение к чистому скану, тем лучше результат OCR.
Программа особенно уместна для старых архивов. Например, есть папка с отсканированными инструкциями в TIFF или PNG. Вручную перепечатывать их бессмысленно, а загружать в облачный сервис нельзя. CuneiForm позволяет распознать такие материалы локально, получить текстовые файлы и затем уже вычитать ошибки.
Где CuneiForm слабее
CuneiForm не стоит выбирать для распознавания рукописного текста. Программа ориентирована на печатные документы, а не на почерк. Даже если отдельные рукописные слова будут визуально понятны человеку, OCR-движок будет воспринимать их как нестандартные и плохо разделимые символы.
Слабые сценарии:
-
фотографии документов под углом;
-
страницы с сильной перспективой;
-
снимки с бликами, тенями и шумом;
-
низкое разрешение;
-
мелкий серый текст;
-
декоративные шрифты;
-
рукописные пометки;
-
сложные журнальные развороты;
-
многоязычные страницы с частым переключением языка;
-
документы, где нужно идеально восстановить верстку;
-
PDF с векторными элементами, формами, слоями и сложным дизайном.
CuneiForm может распознать часть текста в таких документах, но результат придется серьезно править. Это нормальное ограничение для возрастной OCR-программы. Ее сильная сторона — не магическое восстановление любого документа, а прагматичное распознавание достаточно чистых сканов.
Интерфейс программы
Графический интерфейс Cognitive OpenOCR CuneiForm построен по классической схеме настольной Windows-программы. В верхней части окна расположено меню File, Edit, View, Recognition, Window, Help. Под меню находятся панели инструментов с кнопками для открытия файла, сканирования, работы с изображением, запуска распознавания, масштабирования и просмотра результата.
В центральной части отображается изображение документа. Если программа нашла на странице текстовые блоки, они выделяются рамками. В нижней области показывается увеличенный фрагмент изображения или распознанный текст, в зависимости от режима просмотра. Строка состояния внизу отображает служебную информацию: разрешение изображения, язык распознавания, режимы и подсказки.
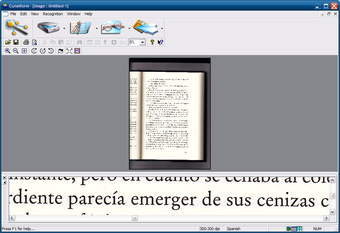
Интерфейс нельзя назвать современным, но он функционален. Пользователь видит саму страницу, может оценить, какие области распознаны как текст, а какие будут проигнорированы. Это важно для OCR: ошибка часто возникает не на этапе распознавания букв, а раньше — когда программа неверно поняла структуру страницы.
У CuneiForm есть несколько характерных элементов интерфейса:
| Элемент | Для чего нужен |
|---|---|
| File | Открытие изображения, сохранение результата, работа с файлами |
| View | Масштабирование и просмотр документа |
| Recognition | Запуск распознавания и команды, связанные с OCR |
| General settings | Настройки сканирования, разметки, языка и форматирования |
| Панель инструментов | Быстрый доступ к открытию, сканированию, распознаванию и просмотру |
| Область изображения | Просмотр исходного скана и найденных блоков |
| Нижняя панель | Увеличенный просмотр фрагмента или результат распознавания |
| Строка состояния | Разрешение, язык, режим и служебные подсказки |
Интерфейс CuneiForm не пытается скрыть процесс распознавания. Напротив, программа показывает, что происходит с документом: где найдены текстовые области, как выглядит исходный фрагмент, какой язык выбран, какое разрешение у изображения. Для пользователя, который занимается не разовым OCR, а регулярной обработкой сканов, это полезнее, чем красивая кнопка без контроля.
Основные функции OCR CuneiForm
CuneiForm выполняет набор задач, который нужен именно для распознавания документов, а не для общего редактирования изображений. В центре программы находится OCR-движок, а остальные функции обслуживают процесс: открыть источник, настроить параметры, распознать, проверить, сохранить.
Открытие изображения
Пользователь может открыть уже готовый файл со сканом. Это базовый сценарий: документ заранее отсканирован или сохранен как изображение, после чего его нужно распознать. В графическом интерфейсе для этого используется команда открытия файла, а в консольной версии — передача имени входного файла последним аргументом команды.
В Linux-сценарии CuneiForm может обработать одностраничное изображение, которое умеет открывать GraphicsMagick. Это дает гибкость по входным форматам, но важно помнить про ограничение: речь идет именно об обработке одиночной страницы как изображения, а не о полноценном многостраничном PDF-редакторе.
Сканирование документа
В Windows-интерфейсе CuneiForm предусмотрена работа со сканером. В окне выбора источника можно указать, откуда брать изображение: открыть файл или получить страницу со сканирующего устройства. В диалогах встречаются элементы Open image, Open…, Scan, поле с выбранным сканером и кнопка Change… для смены устройства.
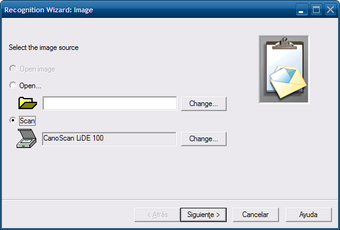
Такой мастер удобен, когда документ еще не сохранен как файл. Пользователь выбирает сканер, задает параметры страницы, получает изображение и сразу передает его на распознавание. На практике качество OCR сильно зависит от настроек сканирования: низкое разрешение, слабый контраст или серый фон быстро ухудшают результат.
Настройка страницы перед распознаванием
В окне Recognition Wizard: Settings задаются параметры изображения: источник, размер страницы, границы, разрешение, цветовой режим и параметры вывода. В видимых элементах интерфейса есть поля Image size, Borders, Resolution, Horizontal, Vertical, Colour, а также кнопки навигации мастера: Atrás, Siguiente >, Cancelar, Ayuda в локализованном интерфейсе.
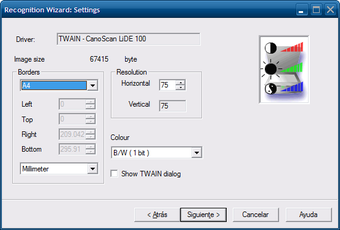
Для OCR особенно важны три вещи: разрешение, контраст и правильные границы. Если на странице много пустых полей или обрезанных краев, программа может хуже определить структуру. Если буквы слишком мелкие, распознавание будет ошибаться. Если фон серый, а текст бледный, возрастает количество неверно распознанных символов.
Распознавание текста
После открытия или сканирования документа запускается распознавание. CuneiForm анализирует страницу, выделяет блоки, определяет текстовые фрагменты, отделяет изображения и таблицы, затем формирует результат. В консольной версии эта логика вызывается одной командой cuneiform, а в графическом интерфейсе — через меню Recognition и кнопки панели инструментов.
Важно, что CuneiForm не просто читает буквы. В ее описании присутствует анализ разметки страницы и распознавание текстового формата: программа пытается понять, где расположены блоки, как организована страница, и в каком виде лучше сохранить результат.
Выбор языка распознавания
Язык распознавания — одна из ключевых настроек. Если документ русский, нужно выбирать русский. Если текст смешанный, полезен режим Russian-English. Если документ английский, используется English. Неверный язык приводит к типичным ошибкам: латинские буквы путаются с кириллицей, похожие символы распознаются неправильно, словарная коррекция работает хуже.
В консольном CuneiForm язык задается параметром -l. Например, -l rus включает русский, -l eng — английский, -l ruseng — смешанный русско-английский режим. Среди поддерживаемых языковых кодов есть Bulgarian, Czech, Danish, Dutch, English, Estonian, French, German, Croatian, Hungarian, Italian, Latvian, Lithuanian, Polish, Portuguese, Romanian, Russian, mixed Russian/English, Slovenian, Spanish, Serbian, Swedish, Turkish и Ukrainian.
Сохранение результата
CuneiForm может сохранять результат в нескольких форматах. В консольной версии формат задается параметром -f, а файл вывода — параметром -o. Доступны форматы html, hocr, native, rtf, smarttext, text; обычный текст используется по умолчанию.
Выбор формата зависит от задачи:
| Формат | Когда использовать |
|---|---|
text |
Нужно просто извлечь текст без верстки |
rtf |
Нужно открыть результат в Word или LibreOffice с базовым форматированием |
html |
Нужен результат в виде HTML-документа |
hocr |
Нужна OCR-разметка для дальнейшей обработки |
smarttext |
Нужен plain text с TeX-подобными абзацами |
native |
Нужен родной формат Cuneiform 2000 |
Для обычного пользователя чаще всего достаточно text или rtf. Для автоматизации, архивирования и последующей обработки документов интереснее hocr, потому что он хранит не просто текст, а структурированную OCR-разметку.
Настройки программы
Окно General settings в Cognitive OpenOCR CuneiForm разделено на вкладки Scanning, Markup and recognition, Formatting. Это логичная структура: сначала задается, как получить изображение, затем — как распознавать страницу, затем — как оформлять результат.
Во вкладке Markup and recognition находятся параметры, которые напрямую влияют на OCR:
-
Spell checking — проверка орфографии;
-
Single column — режим одной колонки;
-
Dot matrix printer — режим для текста, напечатанного матричным принтером;
-
Fax — режим для факсимильных документов;
-
Recognition language — выбор языка распознавания;
-
Search tables — поиск таблиц;
-
Search pictures — поиск изображений;
-
Colours of blocks — цвета блоков текста, картинок и таблиц.
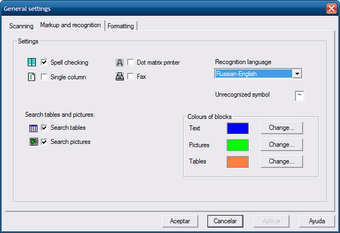
Этот экран хорошо показывает характер CuneiForm: программа дает не абстрактную кнопку улучшить распознавание, а конкретные режимы. Если документ одноколоночный, включается Single column. Если это факс, используется Fax. Если текст напечатан матричным принтером, включается Dot matrix printer. Если нужно сохранить структуру таблиц, остается включенным Search tables.
Во вкладке Formatting настраивается сохранение форматирования RTF. Видны параметры Preserve bold, Preserve italic, Preserve font size, Preserve fragment position, а также выбор шрифтов: Serif, Sans Serif, Fixed font. Это важно, когда результат нужен не просто как текст, а как документ, похожий на исходный скан.
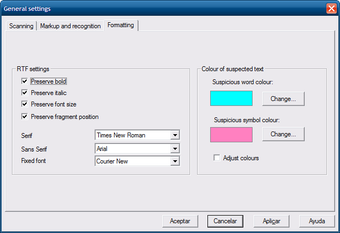
Эти настройки не делают из CuneiForm полноценный настольный издательский пакет. Но они помогают сохранить базовые признаки документа: жирный текст, курсив, размер шрифта, позицию фрагментов. Для распознанных договоров, инструкций и технических страниц этого часто достаточно, чтобы результат было удобнее вычитывать.
Как распознать текст в CuneiForm
Практический сценарий работы в графической версии выглядит так: пользователь открывает изображение, проверяет настройки языка и разметки, запускает распознавание, смотрит результат и сохраняет его в нужном формате.
Шаг 1. Открыть скан или выбрать сканер
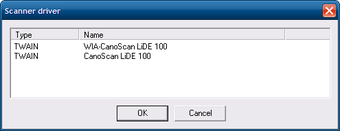
В меню File открывается готовое изображение документа. Если нужно получить страницу напрямую со сканера, используется мастер распознавания, где выбирается источник Scan и нужное устройство. В окне выбора сканера отображается список TWAIN- или WIA-устройств, например WIA-CanoScan LiDE 100 и CanoScan LiDE 100, а подтверждение выполняется кнопкой OK.
На этом этапе лучше не экономить на качестве. Для обычного печатного текста практичнее использовать четкий черно-белый или серый скан без перекоса. Если скан получается слишком темным, нужно скорректировать яркость и контраст до распознавания, иначе программа будет путать шум с точками, запятыми и мелкими буквами.
Шаг 2. Проверить область страницы
После загрузки изображения CuneiForm показывает страницу в рабочей области. Если документ повернут, затемнен или сильно обрезан, лучше исправить это до запуска OCR. Программа может работать с неидеальными исходниками, но качество результата будет зависеть от того, насколько хорошо видны буквы.
На этом этапе стоит проверить:
-
не перевернута ли страница;
-
не обрезан ли текст по краям;
-
не попали ли в область распознавания лишние черные полосы;
-
достаточно ли контрастный текст;
-
не слишком ли маленький масштаб букв;
-
нет ли сильного наклона строк.
Если страница состоит из одной колонки, имеет смысл включить Single column. Этот режим отключает сложный анализ разметки и сообщает программе, что изображение состоит из одной текстовой колонки. В консольной версии то же поведение задается параметром --singlecolumn.
Шаг 3. Выбрать язык
В настройках Recognition language выбирается язык документа. Для русских текстов используется Russian, для английских — English, для смешанных русско-английских страниц — Russian-English. В консольной версии это соответствует кодам rus, eng и ruseng.
Неверный язык — одна из самых частых причин плохого результата. Например, если русский документ распознавать как английский, программа будет пытаться интерпретировать кириллицу через латинские формы. Если англоязычные термины встречаются в русском тексте, смешанный режим обычно дает более аккуратный результат.
Шаг 4. Запустить распознавание
После выбора языка и параметров запускается распознавание через меню Recognition или соответствующую кнопку на панели инструментов. Программа анализирует страницу, выделяет блоки и формирует результат. В нижней части окна можно увидеть увеличенный фрагмент распознаваемого текста и визуально сравнить его с исходником.
CuneiForm показывает найденные области синими рамками. Это удобно: сразу видно, где программа нашла текст, где таблицу, где картинку, а какие части страницы остались без внимания. Если блоки определены неверно, можно изменить настройки разметки и повторить распознавание.
Шаг 5. Проверить результат
После OCR результат нужно вычитать. Это обязательный этап для любой программы распознавания, особенно если документ старый, плохо напечатан или отсканирован не идеально. CuneiForm может ошибаться в похожих символах: о и 0, l и 1, rn и m, русская с и латинская c, дефисы и тире.
Проверять нужно не только отдельные слова, но и структуру:
-
не потерялись ли заголовки;
-
не склеились ли колонки;
-
не перепутался ли порядок абзацев;
-
не исчезли ли строки таблицы;
-
не попали ли в текст фрагменты рисунков;
-
не появились ли лишние переносы строк.
Шаг 6. Сохранить в нужном формате
Если нужен простой текст для копирования, выбирается plain text. Если документ нужно открыть в Word или LibreOffice Writer, лучше использовать RTF. Если результат будет передаваться в дальнейшую обработку, можно выбрать HTML или hOCR. В Linux-команде формат задается через -f, а имя выходного файла через -o.
Примеры команд:
cuneiform -l rus -f text -o result.txt scan.pngЭта команда распознает русскоязычный скан scan.png и сохранит результат в обычный текстовый файл result.txt.
cuneiform --singlecolumn -l ruseng -f rtf -o result.rtf page.tifЭта команда включает одноколоночный режим, использует русско-английское распознавание и сохраняет результат в RTF.
cuneiform --fax -l eng -f hocr -o result.html fax-image.pngЭта команда включает режим для факса, распознает английский текст и сохраняет результат в hOCR HTML.
cuneiform --dotmatrix -l rus -f text -o matrix.txt old-print.pngЭта команда подходит для старого документа, напечатанного матричным принтером.
Работа через командную строку
Командная строка — одна из сильных сторон CuneiForm. В Linux-среде программа не требует обязательного графического интерфейса. Достаточно вызвать cuneiform, передать изображение и нужные параметры.
Базовая структура команды выглядит так:
cuneiform [--dotmatrix] [--fax] [--singlecolumn] [-f format] [-l language] [-o output] inputЭта схема включает несколько групп параметров:
| Параметр | Назначение |
|---|---|
--dotmatrix |
Режим для текста, напечатанного матричным принтером |
--fax |
Режим для документа, прошедшего через факс |
--singlecolumn |
Режим одной колонки без сложного анализа макета |
-f format |
Выбор формата вывода |
-l language |
Выбор языка распознавания |
-o output |
Имя выходного файла |
input |
Входное изображение |
Такой интерфейс удобен для пакетной обработки. Например, можно пройтись по папке с изображениями и для каждого файла получить текстовый результат. Это не самый красивый сценарий для обычного пользователя, но для архивов, лабораторной обработки, внутреннего документооборота и серверных задач он практичен.
Пример простого цикла:
for file in *.tif; do cuneiform -l rus -f text -o "${file%.tif}.txt" "$file"doneТакой подход превращает пачку TIFF-сканов в набор TXT-файлов. После этого текст можно индексировать, искать по нему слова, складывать в архив, передавать редактору или загружать в другую систему.
Поддерживаемые языки
CuneiForm работает с несколькими языками, включая кириллицу и латиницу. Для русскоязычных пользователей особенно важны режимы rus и ruseng. Первый нужен для чисто русского текста, второй — для документов, где вместе с русскими словами встречаются английские термины, названия программ, адреса, команды, технические обозначения и фрагменты латиницы.
В консольной версии используются языковые коды. Среди них:
| Код | Язык |
|---|---|
eng |
English |
rus |
Russian |
ruseng |
mixed Russian/English |
fra |
French |
ger |
German |
spa |
Spanish |
ita |
Italian |
ukr |
Ukrainian |
pol |
Polish |
cze |
Czech |
dut |
Dutch |
swe |
Swedish |
tur |
Turkish |
bul |
Bulgarian |
srp |
Serbian |
Список поддерживаемых языков важен не только формально. OCR-движок использует языковую модель и словарные ожидания. Когда выбран правильный язык, программа лучше различает похожие символы, аккуратнее собирает слова и реже превращает нормальный текст в набор случайных букв.
Для русских документов выбор языка особенно критичен. Кириллица содержит символы, которые внешне похожи на латиницу: А, В, Е, К, М, Н, О, Р, С, Т, Х. Если язык выбран неверно, результат может выглядеть правдоподобно, но быть фактически испорченным: в словах появятся латинские буквы вместо кириллических, что потом мешает поиску, копированию и проверке орфографии.
Форматы входных файлов
CuneiForm работает с изображениями документов. В Linux-сценарии входной файл — это одностраничное изображение, которое может открыть GraphicsMagick. Это означает, что программа не ограничивается одним типом файла, но фактическая поддержка зависит от того, какие форматы доступны через графическую библиотеку.
На практике для OCR лучше всего подходят:
-
TIFF;
-
PNG;
-
BMP;
-
JPEG высокого качества;
-
отсканированные изображения без сильного сжатия;
-
черно-белые или серые изображения с четким текстом.
JPEG стоит использовать осторожно. Формат хорошо подходит для фотографий, но может создавать артефакты вокруг букв. Если документ сканируется специально для OCR, лучше выбрать TIFF или PNG. Если JPEG уже есть, нужно следить, чтобы он не был чрезмерно сжатым.
Для многостраничных документов лучше разбивать материал на страницы. CuneiForm удобнее работает с отдельной страницей как с изображением. Если есть длинный PDF, его обычно сначала превращают в набор изображений, затем распознают страницы, а потом собирают результат в нужном виде.
Форматы экспорта
Выбор формата вывода определяет, насколько результат будет удобен для дальнейшей работы. CuneiForm поддерживает несколько вариантов, и каждый решает свою задачу.
TXT
Обычный текст — самый надежный формат для извлечения содержания. Он не сохраняет оформление, зато легко открывается в любом редакторе, индексируется поиском, обрабатывается скриптами и переносится между системами.
TXT подходит для:
-
архивного поиска;
-
копирования текста;
-
передачи материала редактору;
-
извлечения содержания без верстки;
-
технической обработки.
Минус очевиден: исчезает оформление. Таблицы могут превратиться в плохо выровненные строки, заголовки потеряют размер, а колонки могут смешаться, если распознавание макета прошло неидеально.
RTF
RTF полезен, когда результат нужно открыть в Word, LibreOffice Writer или другом офисном редакторе. Этот формат может сохранить базовое оформление: шрифты, размер, жирность, курсив, позиции фрагментов. В настройках CuneiForm есть отдельные параметры сохранения RTF-оформления, включая Preserve bold, Preserve italic, Preserve font size и Preserve fragment position.
RTF стоит выбирать для договоров, инструкций, писем, документов с заголовками и простыми таблицами. Это лучший вариант, когда результат нужно не просто получить, а дальше редактировать как документ.
HTML
HTML удобен, если результат нужен для публикации, внутреннего просмотра, передачи в веб-систему или дальнейшего парсинга. Он может сохранить больше структуры, чем plain text, но не всегда удобен для обычного редактирования.
hOCR
hOCR — специальный формат для OCR-разметки. Он важен не столько для обычного чтения, сколько для автоматической обработки. Такой результат может использоваться в цепочках, где нужно знать не только распознанный текст, но и его положение на странице.
hOCR полезен для:
-
создания поискового слоя;
-
последующей сборки searchable PDF внешними инструментами;
-
анализа расположения слов;
-
обработки архивов;
-
интеграции с другими системами.
Native Cuneiform 2000
Родной формат нужен в специфических сценариях, связанных с экосистемой CuneiForm. Для обычной работы чаще выбираются TXT, RTF, HTML или hOCR.
Пакетное распознавание
Пакетное распознавание — важный сценарий для OCR CuneiForm. Сама идея проста: обрабатывается не одна страница, а группа файлов. Это полезно, когда нужно распознать папку сканов, главы книги, набор архивных документов или серию однотипных бланков.
В графической Windows-среде пакетная обработка зависит от конкретной оболочки и сборки, а в Linux ее удобно строить через командную строку. CuneiForm хорошо вписывается в такую модель: один входной файл, один выходной файл, параметры языка и формата. Дальше все решается скриптом.
Пример пакетного распознавания русских PNG-сканов:
mkdir -p recognizedfor file in *.png; do base="${file%.png}" cuneiform -l rus -f text -o "recognized/${base}.txt" "$file"doneПример сохранения в RTF:
mkdir -p rtffor file in *.tif; do base="${file%.tif}" cuneiform -l ruseng -f rtf -o "rtf/${base}.rtf" "$file"doneПакетный режим требует дисциплины. Если в одной папке лежат разные по качеству страницы, перевернутые изображения, фотографии под углом и сканы с разными языками, результат будет неоднородным. Перед массовым OCR лучше подготовить изображения: выровнять, обрезать поля, привести к одному разрешению, убрать мусор, разделить документы по языку и типу.
Работа с таблицами и изображениями
CuneiForm умеет искать не только текстовые блоки, но и таблицы с изображениями. В настройках Markup and recognition есть флажки Search tables и Search pictures, а также отдельные цвета блоков для Text, Pictures, Tables. Это показывает, что программа воспринимает страницу как набор разных зон, а не как сплошную картинку.
Для документов с таблицами это важно. Если OCR не понимает, что перед ним таблица, он может прочитать ячейки в неправильном порядке: сначала весь левый столбец, потом правый, затем заголовки, затем случайные числа. CuneiForm пытается выделять таблицы отдельно, чтобы сохранить их структуру в результате.
Но здесь нужно быть осторожным. Сохранение таблиц в OCR-программах почти всегда зависит от качества исходника. Простая таблица с четкими линиями и печатным текстом распознается лучше. Таблица без границ, с мелкими цифрами, серым фоном и плотной сеткой будет проблемной. После распознавания такие документы обязательно нужно проверять вручную.
Изображения внутри документа CuneiForm может определить как нетекстовые области. Это помогает не превращать рисунки, логотипы и схемы в бессмысленный набор символов. Но сложные диаграммы, подписи, подписи внутри картинок и мелкий текст на схемах могут потребовать отдельного подхода.
Одноколоночный режим
Параметр Single column в графическом интерфейсе и ключ --singlecolumn в командной строке нужны для документов простой структуры. Если страница состоит из одного основного текстового столбца, нет смысла заставлять OCR-движок искать сложную многоступенчатую разметку. Одноколоночный режим сообщает программе: перед тобой обычный поток текста, распознавай его как одну колонку.
Это полезно для:
-
страниц книг;
-
инструкций;
-
писем;
-
договоров без сложной верстки;
-
статей, сверстанных в одну колонку;
-
технических описаний.
Если включить одноколоночный режим на сложной странице с несколькими колонками, результат может стать хуже: программа начнет читать фрагменты не в том порядке. Поэтому настройка не является универсальным улучшателем качества. Ее нужно включать тогда, когда структура страницы действительно простая.
Режим для факсов
Параметр Fax и ключ --fax включают режим, оптимизированный для текста, прошедшего через факс. Факсимильные документы обычно имеют характерные дефекты: полосы, шум, потерю тонких деталей, неравномерный контраст, размытые края букв. Обычный OCR может воспринимать эти дефекты как части символов или терять фрагменты букв.
Режим факса полезен для:
-
старых деловых сообщений;
-
архивов факсимильной переписки;
-
документов, пересланных через офисные МФУ;
-
копий с низким качеством;
-
черно-белых изображений с шумом.
Он не делает плохой факс идеальным, но задает программе другой режим распознавания. Если обычное распознавание дает много ошибок на факсимильном изображении, стоит повторить OCR с включенным Fax.
Режим для матричной печати
Параметр Dot matrix printer и ключ --dotmatrix рассчитаны на текст, напечатанный матричным принтером. Такие документы отличаются от лазерной или струйной печати: буквы состоят из точек, контуры неровные, символы могут быть разорванными, а качество зависит от ленты, бумаги и состояния принтера.
Обычный OCR иногда плохо воспринимает матричную печать, потому что символы выглядят не как цельные буквы, а как набор точек. Специальный режим помогает учитывать эту особенность.
Этот режим может пригодиться для:
-
старых бухгалтерских распечаток;
-
складских документов;
-
накладных;
-
ведомостей;
-
технических журналов;
-
документов из архивов 1990-х и начала 2000-х.
Если документ напечатан обычным лазерным принтером, режим матричной печати включать не нужно. Он предназначен именно для специфического точечного рисунка символов.
Качество распознавания
Качество OCR в CuneiForm зависит от исходного изображения сильнее, чем от любых настроек. Программа может хорошо справиться с чистым сканом, но заметно ошибаться на плохой фотографии. Это нормальная особенность OCR: движок не понимает документ как человек, он анализирует форму символов и статистику языка.
На результат влияют:
| Фактор | Как влияет |
|---|---|
| Разрешение | Низкое разрешение делает буквы слишком грубыми |
| Контраст | Бледный текст хуже отделяется от фона |
| Шум | Пыль, точки и артефакты превращаются в ложные символы |
| Перекос | Наклон строк ухудшает сегментацию |
| Сжатие JPEG | Артефакты вокруг букв мешают распознаванию |
| Язык | Неверный язык резко увеличивает ошибки |
| Шрифт | Декоративные и нестандартные шрифты распознаются хуже |
| Колонки | Неверный анализ макета ломает порядок текста |
| Таблицы | Сложная сетка требует ручной проверки |
| Качество печати | Старые копии и матричная печать сложнее для OCR |
Лучший исходник для CuneiForm — ровная страница с черным печатным текстом на светлом фоне. Чем меньше в изображении художественного оформления, пятен, теней, наклона и сжатия, тем лучше программа справляется.
Для повышения качества перед распознаванием стоит:
-
сканировать документ ровно;
-
использовать достаточное разрешение;
-
избегать слишком сильного JPEG-сжатия;
-
обрезать лишние поля;
-
убирать черные полосы по краям;
-
повышать контраст бледных страниц;
-
разделять двухстраничные развороты на отдельные страницы;
-
выбирать правильный язык;
-
включать специальные режимы только по назначению.
Работа с русским текстом
Поддержка русского языка — одна из причин, по которой CuneiForm до сих пор вспоминают среди OCR-программ. Для русских печатных документов программа подходит лучше, чем многие простые англоязычные OCR-утилиты старого поколения. Наличие режима ruseng делает ее удобной для технических документов, где русский текст смешан с английскими терминами.
Русско-английские документы встречаются часто:
-
инструкции по программам;
-
технические руководства;
-
договоры с английскими названиями;
-
спецификации;
-
учебные материалы;
-
документы с командами и путями файлов;
-
страницы с email, URL и названиями компаний.
Если такой документ распознавать только как русский, латиница может пострадать. Если только как английский — пострадает кириллица. Поэтому смешанный режим является практичным компромиссом.
Отдельная проблема русского OCR — похожие символы. Например, программа может спутать кириллическую О с нулем, З с цифрой 3, Ч с похожими графическими формами на плохих сканах. После распознавания русских документов особенно важно проверять даты, суммы, номера договоров, фамилии и технические обозначения.
Сохранение форматирования
CuneiForm пытается сохранять не только текст, но и структуру документа. Это не означает идеального восстановления исходной страницы. Корректнее говорить так: программа старается передать базовую разметку, фрагменты, шрифтовые признаки и расположение блоков там, где это возможно.
В RTF-настройках есть параметры сохранения жирного начертания, курсива, размера шрифта и позиции фрагментов. Это полезно для документов, где визуальная структура помогает читать результат: заголовки, подзаголовки, списки, отдельные блоки, таблицы.
Хороший результат возможен, если исходник простой:
-
один или два столбца;
-
четкие заголовки;
-
стандартные шрифты;
-
понятные интервалы;
-
простые таблицы;
-
минимум декоративных элементов.
Сложная верстка — слабое место. Газетные страницы, журнальные макеты, рекламные листовки, документы с несколькими врезками и плотной сеткой могут распознаваться частично правильно, но порядок текста придется восстанавливать вручную.
Графические оболочки и использование CuneiForm в Linux
В Linux CuneiForm часто используется как OCR-движок, к которому подключаются графические оболочки. Такой подход отделяет сам распознаватель от пользовательского интерфейса. Движок отвечает за OCR, а оболочка — за открытие изображений, предварительный просмотр, выбор областей и сохранение результата.
Пример такой оболочки — Cuneiform-Qt. Она представляет собой графический интерфейс для Cuneiform OCR: позволяет открыть сканированное изображение, посмотреть его в панели предпросмотра, распознать текст через Cuneiform и сохранить результат в HTML. Среди функций есть простой графический интерфейс, открытие и отображение изображения, распознавание через Cuneiform, отображение и сохранение результата в HTML.
Другой пример — YAGF, графическая оболочка для Cuneiform и Tesseract. Она позволяет открывать уже отсканированные изображения, получать новые через XSane, подготавливать изображение к распознаванию, выбирать области, задавать язык, редактировать распознанный текст, сохранять его на диск или копировать в буфер обмена.
Это важно для понимания программы: CuneiForm — не только старое Windows-окно. Это OCR-движок, который можно использовать в разных рабочих средах. Там, где нужен удобный визуальный интерфейс, подключается оболочка. Там, где нужна автоматизация, используется командная строка.
Практические сценарии использования
Распознавание страницы книги
Для книги лучше использовать ровный скан отдельной страницы, а не фотографию разворота. Если скан содержит одну колонку, включается Single column или --singlecolumn. Язык выбирается по тексту: rus, eng или ruseng. Результат лучше сохранять в TXT, если нужно просто получить содержание, или в RTF, если важны заголовки и форматирование.
Последовательность:
-
Отсканировать страницу без перекоса.
-
Открыть изображение в CuneiForm.
-
Выбрать язык.
-
Включить Single column, если страница одноколоночная.
-
Запустить распознавание.
-
Проверить абзацы и переносы.
-
Сохранить результат.
Извлечение текста из договора
Для договора важны точность дат, сумм, имен, реквизитов и нумерации пунктов. Поэтому после OCR нельзя ограничиваться беглым просмотром. Нужно сверять критичные поля с оригиналом.
Лучший формат вывода — RTF, потому что договор обычно имеет структуру: заголовок, пункты, подпункты, реквизиты, подписи. CuneiForm может сохранить часть этой структуры, что облегчит вычитку.
Распознавание старой инструкции
Старые инструкции часто содержат таблицы, схемы и технические обозначения. В настройках стоит оставить включенным Search tables и Search pictures, чтобы программа пыталась отделить текст от изображений и таблиц. Если инструкция русско-английская, нужно выбирать смешанный режим.
После распознавания особенно внимательно проверяются:
-
технические термины;
-
обозначения моделей;
-
единицы измерения;
-
номера деталей;
-
таблицы характеристик;
-
подписи к рисункам.
Обработка пачки TIFF-файлов
Для папки сканов лучше использовать командную строку. Если все страницы одного типа и одного языка, пакетный OCR работает предсказуемо. Если страницы разные, их лучше сначала разделить по группам.
Пример:
for file in pages/*.tif; do name=$(basename "$file" .tif) cuneiform -l rus -f text -o "txt/${name}.txt" "$file"doneТакой сценарий удобен для архивов, где нужно получить поисковый текст по каждой странице.
Получение hOCR для дальнейшей обработки
Если задача не в ручной правке, а в создании структурированного результата, нужен hOCR. Он полезен, когда распознанный текст будет совмещаться с изображением страницы или передаваться в другую программу.
Пример:
cuneiform -l ruseng -f hocr -o page.html page.pngПосле этого результат можно использовать в дальнейших конвейерах обработки документов.
Плюсы OCR CuneiForm
Локальная работа
CuneiForm выполняет распознавание на компьютере пользователя. Для базовой OCR-задачи не требуется отправлять документ в онлайн-сервис. Это важно для договоров, внутренних инструкций, архивов, персональных данных и любых материалов, которые нельзя передавать сторонним облачным платформам.
Поддержка русского языка
Программа умеет работать с русским текстом и смешанным русско-английским режимом. Для русскоязычного OCR это существенное преимущество, особенно при работе со старыми документами и техническими материалами.
Несколько форматов вывода
CuneiForm не ограничивается одним TXT. Поддержка RTF, HTML и hOCR расширяет сценарии применения: от простой вычитки до дальнейшей автоматической обработки. Форматы вывода задаются явно через -f, что удобно для скриптов и повторяемых процессов.
Командная строка
CLI-режим делает CuneiForm удобной для автоматизации. Можно распознавать документы пакетно, запускать OCR по расписанию, подключать программу к скриптам и использовать ее как часть внутреннего рабочего процесса.
Специальные режимы
Наличие режимов Fax, Dot matrix printer и Single column показывает, что CuneiForm рассчитана на разные типы бумажных документов. Это не универсальная магия, но полезный набор конкретных режимов для старых и нестандартных исходников.
Анализ разметки
CuneiForm выполняет не только распознавание текста, но и анализ структуры страницы. Она пытается определить блоки, таблицы, изображения и формат. Это особенно важно при работе не с отдельной строкой текста, а с полноценным документом.
Минусы OCR CuneiForm
Устаревший интерфейс
Графический интерфейс выглядит старомодно. Пользователю, привыкшему к современным PDF-приложениям, CuneiForm может показаться жесткой и непривычной. Здесь нет плавного UX, крупных подсказок, визуального мастера для новичков и автоматического исправления всех проблем.
Требует вычитки
Результат OCR почти всегда нужно проверять. Особенно это касается плохих сканов, документов с таблицами, смешанных языков и материалов с мелким шрифтом. CuneiForm не заменяет редактора и не гарантирует безошибочный текст.
Не подходит для рукописей
Программа ориентирована на печатный текст. Рукописные записи, подписи, пометки на полях и нестандартные символы распознаются плохо или не распознаются как нормальный текст.
Ограниченная работа со сложными PDF
CuneiForm — это OCR-система, а не современный PDF-редактор. Если нужно редактировать PDF, сравнивать документы, добавлять комментарии, работать с формами и юридически значимыми процессами, лучше использовать специализированные PDF-пакеты.
Сложная верстка требует ручной правки
Колонки, таблицы, рисунки, врезки и плотная журнальная верстка могут нарушить порядок текста. Программа пытается анализировать макет, но результат не всегда будет готовым документом без дополнительной обработки.
Возрастной характер программы
CuneiForm воспринимается как зрелый, но старый инструмент. Это не минус для архивных и локальных задач, но минус для пользователей, которые ждут современного интерфейса, регулярных улучшений UX и встроенных облачных сценариев.
Сравнение с аналогами
CuneiForm корректно сравнивать не с абстрактными программами для OCR, а с конкретными решениями: ABBYY FineReader PDF, Tesseract OCR, NAPS2, gImageReader, YAGF и FreeOCR. У каждого инструмента своя роль.
| Программа | Сильные стороны относительно CuneiForm | Где CuneiForm выглядит лучше |
|---|---|---|
| ABBYY FineReader PDF | Современная работа с PDF, редактирование, конвертация, защита, совместная работа, сильный OCR для офисного документооборота | CuneiForm проще как локальный бесплатный OCR-движок для базовых задач |
| Tesseract OCR | Активно используемый open-source OCR-движок, развитая экосистема, командная строка, LSTM-распознавание | CuneiForm интересна для старых русскоязычных OCR-сценариев и отдельных документов с классической структурой |
| NAPS2 | Удобное сканирование, сохранение в PDF/TIFF/JPEG/PNG, OCR для searchable PDF, современный кроссплатформенный интерфейс | CuneiForm лучше рассматривать как OCR-движок, когда нужен именно текстовый результат в TXT/RTF/HTML/hOCR |
| gImageReader | Удобная графическая оболочка к Tesseract, импорт PDF и изображений, обработка нескольких документов, редактирование текста рядом с изображением | CuneiForm может быть проще в старых рабочих процессах, где уже используется его движок |
| YAGF | Оболочка для Cuneiform и Tesseract, подготовка изображения, выбор областей, редактор результата, работа с XSane | Сам CuneiForm остается движком распознавания, который можно использовать без оболочки |
| FreeOCR | Простой Windows-интерфейс для базового OCR | CuneiForm сильнее как самостоятельная OCR-система с анализом структуры и несколькими форматами вывода |
ABBYY FineReader PDF заметно сильнее как современный коммерческий пакет: он рассчитан на работу с PDF, редактирование, конвертацию, защиту, совместное использование и полный офисный цикл. CuneiForm в этом сравнении выигрывает не качеством экосистемы, а простотой локального OCR и бесплатностью для базовых сценариев.
Tesseract OCR — главный open-source-аналог на уровне движка. Он содержит OCR-движок libtesseract и командную программу tesseract; начиная с Tesseract 4 в нем используется LSTM-движок распознавания строк. Для новых проектов чаще выбирают Tesseract, но CuneiForm остается интересной системой для тех, кому нужен именно его подход к распознаванию документов и старым русскоязычным материалам.
NAPS2 — другой тип программы. Это прежде всего удобное приложение для сканирования документов в PDF и другие форматы, с OCR для создания searchable PDF. Оно работает на Windows, Mac и Linux, поддерживает сканирование и сохранение в PDF, TIFF, JPEG и PNG. Если задача — быстро отсканировать много страниц и собрать PDF, NAPS2 практичнее. Если задача — получить текст через CuneiForm-движок, CuneiForm остается отдельным инструментом.
gImageReader — графическая оболочка к Tesseract. Она умеет импортировать PDF, изображения, сканы, данные из буфера и скриншоты, обрабатывать несколько документов, задавать области распознавания, выводить plain text или hOCR и показывать распознанный текст рядом с изображением. По удобству интерфейса gImageReader ближе к современному ожиданию пользователя, но это уже другая OCR-экосистема.
YAGF интересна тем, что может работать с Cuneiform и Tesseract. Она закрывает то, чего не хватает консольному CuneiForm: визуальная подготовка изображения, выбор областей, редактор результата, копирование в буфер и сохранение текста. Для Linux-пользователя связка CuneiForm + YAGF может быть удобнее, чем чистая командная строка.
Когда стоит выбрать CuneiForm
CuneiForm стоит использовать, если задача четко совпадает с ее сильными сторонами. Это локальное распознавание печатных документов, особенно русских или русско-английских, с возможностью сохранить результат в TXT, RTF, HTML или hOCR.
Программа подойдет:
-
для архивных сканов;
-
для старых печатных документов;
-
для русскоязычного OCR;
-
для документов без сложной верстки;
-
для локальной обработки без облака;
-
для автоматизации через командную строку;
-
для задач, где нужен hOCR или RTF;
-
для пользователей, которым важен сам OCR-движок, а не современный PDF-интерфейс.
CuneiForm особенно уместна в рабочих процессах, где результат все равно будет вычитываться человеком. Например, нужно быстро получить текст из старой инструкции, затем редактор вручную проверит ошибки. В таком сценарии программа экономит время, даже если не дает идеального результата.
Когда лучше выбрать другую программу
Если нужен готовый современный PDF-процесс, CuneiForm будет слабым выбором. Для офисной работы с PDF, конвертации в Word, сравнения документов, редактирования страниц и сохранения сложной верстки лучше подходит ABBYY FineReader PDF или похожий коммерческий пакет.
Если нужен современный open-source OCR-движок для нового проекта, чаще разумнее смотреть в сторону Tesseract. У него шире экосистема, больше современных оболочек, активнее используется в новых инструментах и лучше интегрируется в актуальные OCR-конвейеры.
Если главная задача — сканирование, сборка PDF и быстрое создание searchable PDF, практичнее NAPS2. CuneiForm в этом сценарии не заменяет удобное сканирующее приложение.
Если нужен удобный Linux-интерфейс с выбором областей и редактированием результата, лучше рассматривать YAGF или gImageReader. CuneiForm можно использовать как движок, но без оболочки он требует более технического подхода.
CuneiForm не стоит выбирать, если нужны:
-
распознавание рукописного текста;
-
идеальная верстка сложных PDF;
-
современный интерфейс;
-
облачная синхронизация;
-
мобильное OCR;
-
автоматическая обработка фотографий с телефона;
-
промышленный OCR с контролем качества;
-
юридически значимый PDF-документооборот;
-
редактирование PDF как в полноценном PDF-редакторе.
Советы по подготовке сканов
Чтобы CuneiForm работала лучше, нужно готовить входные изображения. OCR-программа не может полностью исправить плохой исходник. Если текст размыт, повернут, обрезан или покрыт шумом, ошибки неизбежны.
Практичные правила:
-
Сканировать ровно.
Перекос строк ухудшает распознавание и анализ блоков. -
Не использовать слишком низкое разрешение.
Мелкие буквы должны быть четкими, иначе программа будет путать похожие символы. -
Избегать сильного JPEG-сжатия.
Артефакты вокруг букв выглядят как шум. -
Обрезать лишние поля.
Черные полосы, края разворота и тени мешают определению структуры. -
Разделять развороты.
Две страницы на одном изображении сложнее для OCR, чем отдельные страницы. -
Выбирать правильный язык.
Для русско-английского документа использовать смешанный режим. -
Проверять таблицы отдельно.
Табличные данные часто требуют ручной сверки. -
Не ждать идеала от плохого факса.
Режим Fax помогает, но не восстанавливает утраченное качество. -
Использовать RTF только там, где нужно оформление.
Если нужен чистый текст, TXT проще и надежнее. -
Сохранять исходники.
После OCR всегда нужно иметь возможность сверить результат с оригиналом.
Типичные ошибки пользователя
Неверный язык
Пользователь открывает русский документ, оставляет English и получает испорченный текст. Это самая простая и самая частая ошибка. Перед распознаванием всегда нужно проверять Recognition language.
Попытка распознать фотографию как скан
Фотография с телефона может быть наклонена, иметь перспективу, тени и неравномерную резкость. CuneiForm лучше работает со сканами, чем с бытовыми фотографиями. Если другого источника нет, изображение нужно предварительно выровнять и улучшить.
Ожидание идеального Word-документа
RTF-вывод помогает сохранить базовое оформление, но не превращает любой скан в идеальный документ. После OCR форматирование часто нужно править.
Пакетная обработка без проверки
Если распознать сотню страниц и не проверить результат, ошибки попадут в архив. Пакетный режим экономит время, но не отменяет контроль качества.
Использование специальных режимов без причины
Fax, Dot matrix printer и Single column нужно применять по назначению. Если включать их случайно, качество может не улучшиться, а ухудшиться.
Оценка удобства
CuneiForm удобна для пользователя, который понимает базовую логику OCR: источник, язык, разметка, распознавание, формат вывода, проверка результата. Для новичка программа может быть не самой дружелюбной, потому что она не объясняет каждый шаг современным языком и не скрывает технические параметры.
Сильная сторона удобства — прямой контроль. Пользователь видит меню, настройки, блоки, язык, формат. Можно явно выбрать одноколоночный режим, включить поиск таблиц, изменить параметры RTF и сохранить результат в нужном виде.
Слабая сторона — отсутствие современного рабочего потока. В новых программах пользователь часто нажимает одну кнопку Сканировать и распознать, получает searchable PDF и сразу отправляет его по почте. CuneiForm требует больше ручного внимания.
Оценка функциональности
По функциональности CuneiForm остается полноценной OCR-системой для своего класса. У нее есть:
-
распознавание текста;
-
анализ макета;
-
распознавание текстового формата;
-
поддержка нескольких языков;
-
русский и русско-английский режим;
-
специальные режимы для факса и матричной печати;
-
одноколоночный режим;
-
поиск таблиц и изображений;
-
сохранение в TXT, RTF, HTML, hOCR;
-
командная строка;
-
возможность использования в оболочках.
Этого достаточно для базового и среднего уровня OCR-задач. Но этого недостаточно для современного PDF-офиса, где нужны редактирование, сравнение, подписи, комментарии, автоматические профили, интеграция с облаком и сложная конвертация.
Оценка качества результата
На чистых печатных сканах CuneiForm может давать хороший результат. Особенно если выбран правильный язык и документ не содержит сложной верстки. На старых, шумных и плохо подготовленных изображениях качество становится нестабильным.
Оценивать CuneiForm нужно честно: это не инструмент, который гарантирует идеальное распознавание в любых условиях. Это программа, которая может существенно сократить ручной набор текста, но требует проверки.
Лучшие результаты:
-
печатные документы;
-
ровные сканы;
-
стандартные шрифты;
-
хорошее разрешение;
-
высокий контраст;
-
один язык или понятная языковая смесь;
-
простая структура страницы.
Худшие результаты:
-
фотографии под углом;
-
рукописный текст;
-
сложная верстка;
-
серые копии;
-
таблицы с мелким шрифтом;
-
документы с потерянными фрагментами букв;
-
декоративные заголовки;
-
изображения с сильным шумом.
Итоговая оценка Cognitive OpenOCR CuneiForm
Cognitive OpenOCR CuneiForm — это практичная OCR-программа для распознавания печатного текста со сканов и изображений. Она сильна как локальный инструмент, особенно для русских и русско-английских документов, архивных материалов, простых сканов, пакетной обработки через командную строку и сохранения результата в нескольких форматах.
Ее не нужно идеализировать. Интерфейс устарел, сложные PDF ей не по профилю, рукописи она не решает, а результат почти всегда требует вычитки. Но для конкретной задачи — превратить изображение печатного документа в редактируемый текст — CuneiForm остается понятным и полезным инструментом.
Главная ценность программы в том, что она делает OCR локально, поддерживает несколько языков, умеет работать с разметкой страницы и дает пользователю контроль над форматами вывода. Если нужен простой, проверяемый и не облачный способ распознать сканы, CuneiForm заслуживает внимания. Если нужен современный PDF-процесс с максимальным качеством и минимумом ручной правки, лучше выбрать более новый инструмент.