
ScanPapyrus — это не просто оболочка для команды сканировать страницу. Программа построена вокруг самой практичной части оцифровки: быстро получить ровные страницы, автоматически обработать их, сложить в правильном порядке и сохранить в удобный формат без лишней рутины. Она умеет работать с обычными листами, книжными разворотами, фотографиями, многостраничными пачками через ADF, двухсторонним сканированием, а затем экспортировать результат в PDF, DjVu или набор графических файлов.
Главная идея ScanPapyrus — убрать постоянное хождение между сканером и компьютером. В обычной программе пользователь каждый раз возвращается к экрану, снова запускает сканирование, затем поправляет кривую страницу, режет поля и следит за порядком листов. В ScanPapyrus основа процесса другая: задается интервал, включается Batch Scanning, страницы сменяются одна за другой, а программа сама выравнивает, обрезает, усиливает контраст и при необходимости режет книжный разворот на две отдельные страницы.
Если говорить точно, ScanPapyrus сильнее всего раскрывается в трех сценариях: когда нужно быстро перегнать в PDF пачку бумажных документов, когда нужно оцифровать книгу со стекла планшетного сканера, и когда требуется получить чистые, ровные, пригодные для архива страницы без долгой ручной обработки. Это программа именно про захват и подготовку страниц, а не про полноценное редактирование PDF как офисного документа. Экспорт в PDF сохраняет страницы как изображения, а OCR вынесен в отдельный контур через вкладку Recognition.
Скачать ScanPapyrus
- Редактирование PDF
- Русский интерфейс
- Просто для новичков
- Платная версия
- Требует драйверы
- Средний интерфейс
Для каких задач ScanPapyrus подходит лучше всего
В реальной работе ScanPapyrus не распыляется на десятки побочных функций. Она сосредоточена на том, что происходит между нажатием кнопки сканирования и получением готового документа. Программа подходит для сканирования договоров, актов, заявлений, архивных бумаг, методичек, учебников, конспектов, инструкций, брошюр, фотоотпечатков и других бумажных материалов, которые нужно быстро привести к аккуратному цифровому виду.
Особенно удачно ScanPapyrus выглядит там, где в обычных утилитах начинается раздражающая рутина. Например, пользователь кладет на стекло разворот книги, а на выходе хочет не один широкий скан, а две отдельные страницы в правильном порядке. Или ему нужно прогнать через автоподатчик длинный договор с двусторонними листами. Или отсканировать пачку однотипных бланков, не возвращаясь каждый раз к мыши. Во всех этих случаях программа использует один и тот же набор сильных инструментов: Batch Scanning, Split the book spread into two pages, Auto Crop, Auto Deskew, Auto Contrast, Auto-Sort и экспорт в PDF/DjVu/изображения.
Отдельно стоит выделить работу с проектами. ScanPapyrus сохраняет сам проект сканирования в файл .scppy, а не только конечный PDF или DjVu. Это полезно, когда большой документ нужно оцифровывать по частям: сегодня отсканировали половину, сохранили проект, завтра открыли его через Open Project и продолжили с того же места. Такой режим сильно упрощает длинные архивные задачи и работу с объемными книгами.
Программа также умеет импортировать уже существующие страницы из PDF, DjVu, JPEG, TIFF, BMP и PNG. Это важно, когда документ собирается из разных источников: часть страниц пришла со сканера, часть уже есть в PDF, часть лежит как изображения. В таком сценарии ScanPapyrus работает не только как сканер, но и как сборщик итогового документа. При этом при извлечении из PDF загружаются именно изображения страниц, а не текстовый слой PDF.
Интерфейс ScanPapyrus: как устроено главное окно
Главное окно ScanPapyrus разделено на шесть рабочих зон: System menu, Toolbar, Sidebar, Work Area, Page List и Status bar. Это не декоративное деление. Вся логика программы строится вокруг него: сверху находятся команды по этапам работы, слева — быстрые действия над страницей, в центре — текущий лист, справа — порядок документа, внизу — техническая сводка по выбранной странице.
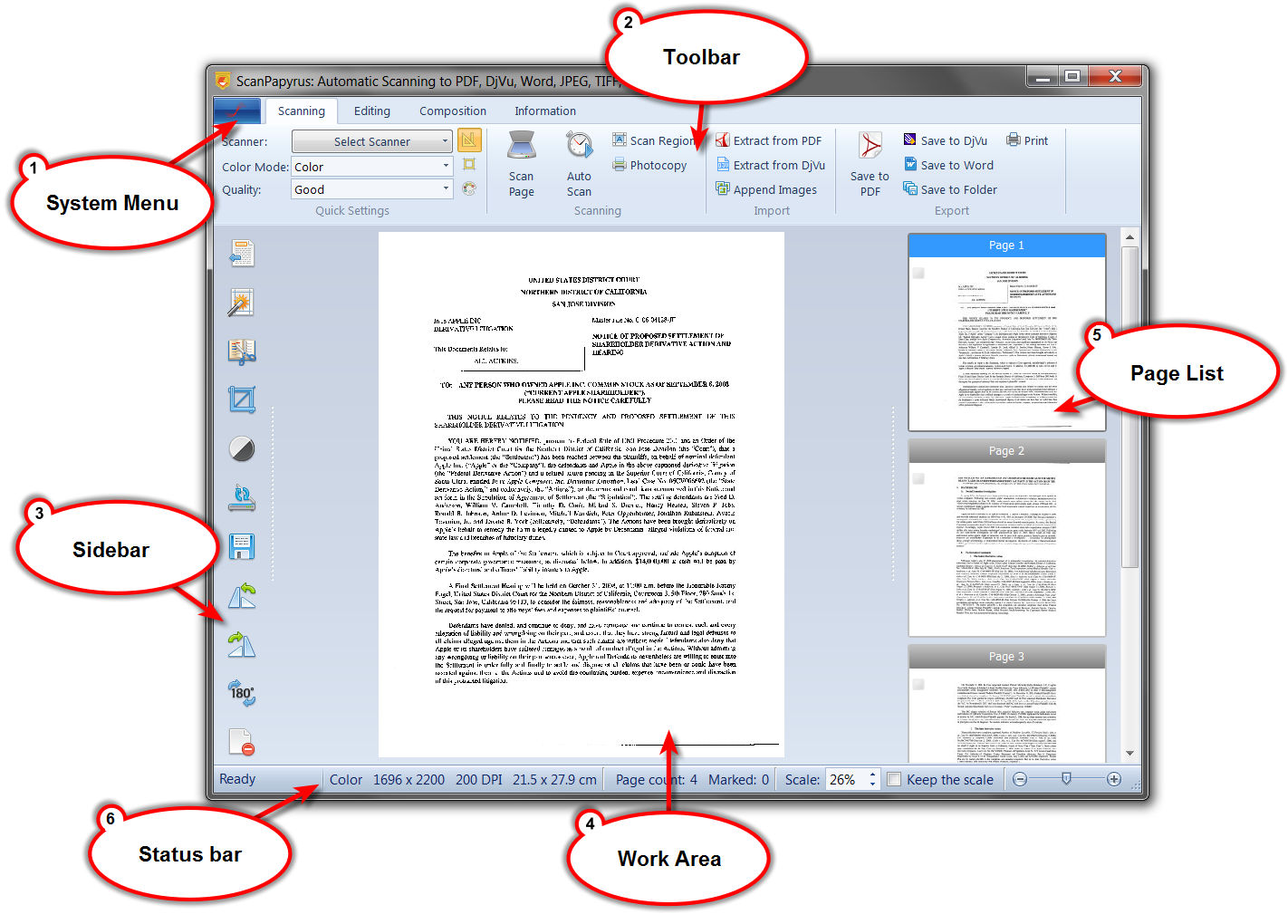
В System menu находятся команды New Project, Open Project, Save Project, Recover Project, Settings и Quit. Здесь же виден список недавних проектов и ранее экспортированных PDF/DjVu. Для длинной работы это важнее, чем кажется: ScanPapyrus не навязывает идею отсканировал и сразу закрыл, а позволяет вести несколько документов параллельно, переключаясь между проектами без потери структуры.
Toolbar разбит на вкладки Scanning, Editing, Composition, Information, а справа находится меню Style. Такой порядок очень логичен: сначала захват страницы, затем исправление изображения, потом сборка документа, потом сервисные функции. В ScanPapyrus не приходится искать команды по разным контекстным меню — основные этапы работы всегда лежат в одной верхней ленте.
Sidebar в левой части окна дублирует самые ходовые команды и превращает программу в инструмент быстрого потока. Отсюда можно восстановить оригинал страницы, запустить автоматическую обрезку, разделить разворот на две страницы, отсортировать по номеру, перейти в ручную обрезку, открыть корректировку яркости/контраста, пересканировать страницу, сохранить ее в графический файл, повернуть влево или вправо, перевернуть на 180 градусов и удалить текущий лист. При этом часть операций работает как групповые: если страницы отмечены галочками в Page List, действие применяется сразу ко всем отмеченным.
Work Area показывает текущую страницу. Здесь есть масштабирование колесом мыши, перетаскивание изображения внутри области просмотра и контекстное меню по правому клику. Это контекстное меню включает Turn Left, Turn Right, Flip Image, Zoom In, Zoom Out, Fit to Window, Crop the Image, Contrast и Remove Page. Для рутинной правки это удобно: часть операций выполняется прямо над текущим листом без переключения вкладок.
Page List справа — это не просто миниатюры. Каждая плитка страницы имеет номер, чекбокс для групповых операций, собственное контекстное меню и участвует в сборке документа. Через плитки можно двигать листы вверх и вниз, переносить их в начало и конец, удалять и вручную поправлять порядок после автоматической сортировки. Размер плиток регулируется ползунком, а когда они достаточно малы, они раскладываются в две колонки, что удобно при длинных документах.
Status bar снизу дает очень полезную информацию по текущей странице: цветовой режим, размер в пикселях, DPI, физический размер в сантиметрах, общее число страниц в проекте, число отмеченных страниц, текущий масштаб, флажок Keep the scale и ползунок размера миниатюр. Для обычного просмотра это мелочи, но при поточном сканировании такие данные позволяют быстро понять, не ушла ли страница в неверный DPI, не оказался ли лист в черно-белом режиме вместо grayscale и не сломалась ли логика масштаба при проверке документа.
Быстрый старт: как ScanPapyrus сканирует страницу
Рабочая логика программы начинается с блока Quick Settings на вкладке Scanning. В нем находятся Select Scanner, выпадающие списки Color Mode и Quality, а также три кнопки постобработки: Auto Deskew, Auto Cropping и Auto Contrast. Это главный оперативный центр для повседневного сканирования: большая часть типовых задач решается отсюда без открытия окна Settings.
Через Select Scanner выбирается конкретный драйвер сканера. В ScanPapyrus лучше выбирать устройство без префикса WIA. Если в списке есть, например, CanoScan LiDE 90 и WIA-CanoScan LiDE 90, выбирать нужно первый вариант. Программа может работать с WIA, но нормальный поток и корректное поведение у нее завязаны прежде всего на TWAIN-драйверы. Если в списке доступен только WIA-вариант, практический смысл сводится к одному: поставить нормальный TWAIN-драйвер производителя.
Color Mode переключает режим сканирования между Color, Black-and-White и Grayscale. Здесь важно не путать режимы. Для договоров и типовых текстовых бумаг чаще всего удобнее Grayscale, потому что вместе с Auto Contrast программа уверенно осветляет фон и усиливает буквы. Для иллюстрированных документов и фотографий логичнее использовать Color, а для очень контрастных бумажных оригиналов иногда полезен Black-and-White, если нужна максимально легкая итоговая картинка.
Quality задает разрешение. В ScanPapyrus предусмотрены пресеты Medium, Good и High, а также ручной режим Manual. По умолчанию это 200, 300 и 600 DPI соответственно. Для большинства офисных документов оптимален Good, то есть 300 DPI: этого достаточно для читаемого PDF, OCR и нормальной печати. High нужен там, где важны мелкие детали, например фрагменты штампов, мелкий шрифт, таблицы с тонкими линиями или старые бумажные оригиналы. Medium уместен, когда приоритет — скорость и компактный размер файла.
| Preset в ScanPapyrus | DPI по умолчанию | Типичный сценарий |
|---|---|---|
Medium |
200 DPI | быстрый рабочий PDF, черновой архив |
Good |
300 DPI | основной режим для документов и OCR |
High |
600 DPI | мелкие детали, таблицы, фрагменты, проблемные оригиналы |
Manual |
произвольное значение | нестандартная задача под конкретный сканер |
Эти пресеты доступны прямо в Quick Settings, а их значения можно изменить на вкладке Resolution в окне Settings.
Три кнопки автоматической обработки рядом с Quick Settings — одна из причин, почему ScanPapyrus быстрее типичных драйверных утилит. Auto Deskew выпрямляет слегка перекошенные страницы, Auto Cropping убирает лишние поля и черные полосы от приоткрытой крышки, Auto Contrast очищает блеклый фон и делает текст темнее и четче. В реальной работе этот набор почти всегда стоит держать включенным для бумажных документов, особенно если страницы кладутся на стекло неидеально. Для цветных иллюстраций Auto Contrast нужно включать осторожно, потому что он может искажать цвет.
Основные команды вкладки Scanning
На вкладке Scanning ScanPapyrus собрала все, что связано с захватом, импортом и экспортом. Основные кнопки сканирования — Scan Page, Batch Scanning, Scan Region, Photocopy и Rescan Page. Каждая из них решает свою задачу, и это важно понимать, потому что у программы нет одной кнопки на все случаи.
Scan Page — базовая команда. Она запускает сканирование в выбранном устройстве с учетом текущих настроек Color и Quality, а затем применяет постобработку, если активированы Auto Deskew, Auto Cropping и Auto Contrast. Это основной режим для разовых страниц, коротких документов и ADF-сценария, когда автоподатчик уже настроен в Settings.
Batch Scanning — центральная функция программы. Она запускает мастер пакетного сканирования с таймером и позволяет не возвращаться к клавиатуре после каждой страницы. Этот режим годится и для обычных многостраничных документов, и для книг, и даже для последовательного сканирования фотографий. В нем ScanPapyrus сама запускает следующий проход через заданный интервал, а пользователь в это время лишь меняет лист на стекле или переворачивает разворот книги.
Scan Region работает иначе. Сначала программа делает предварительный скан всей страницы с низким разрешением, затем показывает рамку выделения, после чего выбранная область сканируется уже в высоком разрешении. Это очень полезный инструмент для штампа, печати, подписи, фотографии внутри документа или небольшого фрагмента схемы: вместо того чтобы гнать весь лист в 600 DPI, ScanPapyrus берет только нужную область. Главное правило этого режима простое — после предварительного скана нельзя сдвигать оригинал на стекле.
Photocopy превращает программу в цифровой копир: ScanPapyrus сканирует страницу с текущими параметрами и сразу отправляет результат на принтер по умолчанию. Для домашнего и малого офисного сценария это неожиданно полезная кнопка, особенно когда у МФУ неудобная штатная панель, а копия нужна быстро и с понятными настройками разрешения и цвета.
Rescan Page пересканирует текущий лист и заменяет им существующую страницу в проекте. Это одна из самых недооцененных функций программы. Когда на десятой странице видно, что конкретный лист получился смазанным, нет нужды удалять его, искать позицию вручную и потом снова вставлять — достаточно перейти на страницу, положить оригинал и нажать Rescan Page. В длинных проектах это экономит массу времени.
Что делает каждая команда на практике
| Кнопка | Практический смысл |
|---|---|
Scan Page |
один проход сканирования с текущими параметрами |
Batch Scanning |
серия проходов по таймеру без возврата к ПК |
Scan Region |
высокое разрешение только для выбранного фрагмента |
Photocopy |
сканирование с немедленной печатью |
Rescan Page |
замена текущего листа новым сканом |
Так ScanPapyrus разделяет режимы не по формальному признаку, а по реальному сценарию работы у сканера.
Настройки сканера: Paper Source, Duplex Mode, Scan Area и Preview
Когда быстрых параметров уже недостаточно, нужно идти в Settings. Самая важная вкладка здесь — Scanner. В ней задаются Paper Source, Duplex Mode, Scan Area, а также флажки Deskew scanned pages, Auto-crop scanned pages, Adjust contrast of scanned pages и Scan with preview.
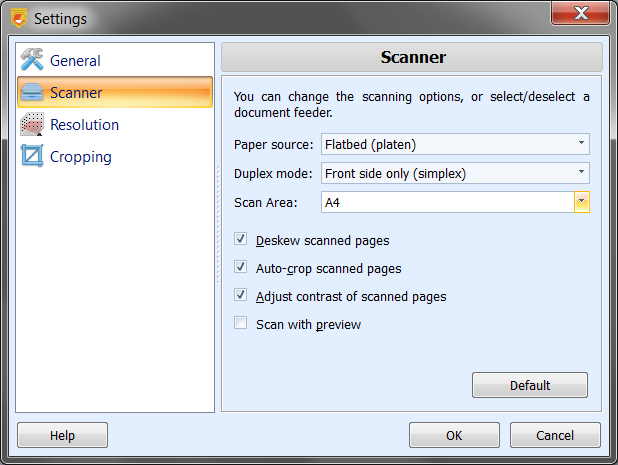
Paper Source определяет, откуда сканер берет бумагу. Варианты три: Flatbed (platen), Automatic feeder (ADF) и Automatic paper detection. Первый режим — классическое стекло. Второй — автоподатчик. Третий особенно удобен, если устройство умеет определять наличие бумаги в ADF: ScanPapyrus автоматически берет листы из автоподатчика, а если он пуст, переключается на стекло. Для гибридной офисной работы это очень удобный режим, потому что не приходится каждый раз лазить в настройки.
Duplex Mode нужен для устройств, которые поддерживают двухстороннее сканирование. Варианты: Front side only (simplex) и Both sides (duplex). Если автоподатчик и драйвер сканера работают корректно, ScanPapyrus способна прогонять двусторонние документы за один цикл. Это особенно важно для договоров, бухгалтерских бумаг и делопроизводственных архивов, где обороты часто содержат подписи, резолюции или дополнительные реквизиты.
Scan Area позволяет ограничить область стекла, которую будет проходить сканирующая головка. По умолчанию используется вся поверхность, но при желании ее можно ограничить форматом A4, Letter, Legal, A5 или A6. Смысл у этого режима очень практический: если документ физически занимает только часть стекла, сканирование можно ускорить за счет меньшего хода головки. В ScanPapyrus этот прием особенно полезен при серийной оцифровке небольших бланков, квитанций и фотографий.
Scan with preview открывает системное окно предварительного просмотра драйвера. Это зависит уже от конкретного сканера, а не от ScanPapyrus, но в некоторых случаях режим полезен: через родной preview диалог устройства можно включить специфические аппаратные опции, которые сама программа не дублирует. После сканирования страница все равно поступает обратно в ScanPapyrus и проходит ее постобработку.
На вкладке General есть еще одна полезная вещь — Page direction, где выбирается направление страниц в книге: Left to right или Right to left. Для обычной западной или русскоязычной книги это кажется мелочью, но для арабского или ивритного книжного потока настройка действительно влияет на удобство. Это хороший пример того, что ScanPapyrus не просто умеет резать разворот, а именно понимает книжный сценарий как отдельный тип работы.
Пакетное сканирование документов: главный режим ScanPapyrus
Если выделять одну функцию, которая лучше всего объясняет, зачем вообще существует ScanPapyrus, это Batch Scanning. Режим заставляет программу запускать следующий проход через заданный интервал времени, благодаря чему пользователь меняет только бумагу, а не повторяет команду сканирования мышью или клавишей после каждого листа. Именно из-за этой логики ScanPapyrus заметно быстрее типовых комплектных утилит сканера, когда документ длиннее двух-трех страниц.
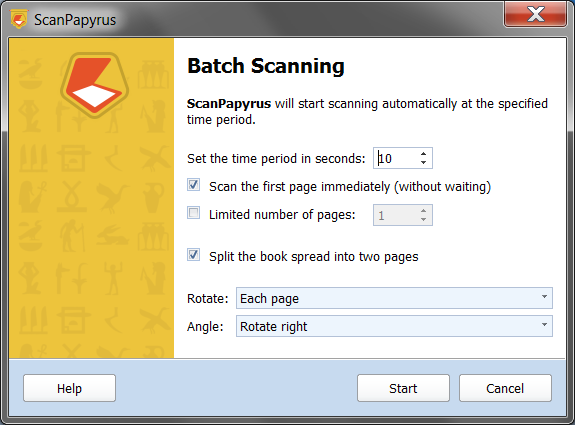
На первом шаге мастер предлагает настроить параметры. Здесь задается время ожидания в секундах — от 1 до 60. Практически 5–10 секунд хватает для большинства сценариев: заменить лист на стекле, перевернуть страницу книги, поправить положение оригинала. Для книг темп чаще ставят ближе к 3–5 секундам, а для более капризных документов — чуть выше. Важно, что ScanPapyrus считает не итоговые страницы, а проходы сканирования: если один разворот разрезается на две страницы, это все равно один проход.
Флажок Scan the first page immediately (without waiting) определяет старт процесса. Если он включен, первый проход начинается сразу после запуска мастера. Если выключен, программа сначала выдерживает заданный интервал. Для обычной офисной пачки удобнее включать этот флажок, а для книги иногда удобнее выключить и спокойно положить первый разворот после запуска.
Limited number of pages — полезный ограничитель для серийных задач. Он заставляет программу остановиться после заданного числа проходов. Например, если нужно оцифровать ровно 20 бланков или точно известно, что книга делается порциями по 25 разворотов, этот режим позволяет контролировать поток без ручного подсчета. После достижения лимита таймер просто встает на паузу.
Параметр Rotate вместе с Rotation Angle — это не второстепенная опция, а очень практичный инструмент. ScanPapyrus умеет вращать Each page, Every odd page или Every even page. Такой режим полезен, когда устройство или конструкция крышки заставляют укладывать нечетные и четные листы в разной ориентации. Программа автоматически выправляет этот технический беспорядок уже на входе, а не после сканирования вручную.
После старта мастер переходит в фазу отсчета. Пока таймер идет, пользователь меняет страницу. Если ждать не хочется, есть кнопка Scan Now >, которая немедленно запускает следующий проход. Кнопка Stop временно останавливает отсчет, Finish завершает весь пакетный режим. У этого процесса есть и горячие клавиши: Space — пауза, Enter — следующий проход без ожидания, Esc — завершение. Для поточной оцифровки это очень хороший уровень продуманности интерфейса.
В результате Batch Scanning — это не просто серия повторных вызовов сканера. Это режим, в котором одновременно работают таймер, автоматическая коррекция, при необходимости разрезание разворота на две страницы, ротация по четности и добавление результата прямо в проект. Именно поэтому ScanPapyrus так хорошо подходит для больших документов: она сокращает не только число кликов, но и количество точек, где пользователь обычно допускает ошибку.
Сканирование книг и разворотов: сильнейшая сторона ScanPapyrus
Для книжной оцифровки в ScanPapyrus есть конкретная логика, а не абстрактная опция разделить изображение пополам. В мастере пакетного сканирования включается Split the book spread into two pages, после чего каждый скан рассматривается как разворот и пытается быть автоматически разделенным на левую и правую страницу. Если разворот лежит горизонтально и сгиб различим, программа использует линию сгиба как индикатор разделителя.
Это важный момент. ScanPapyrus не режет разворот тупо посередине по ширине кадра. Для нее ориентир — именно место стыка страниц. Поэтому на реальной книге результат обычно заметно лучше, чем у примитивного пополам-разделения в графическом редакторе. Если разворот уложен более-менее ровно, программа не только делит его на две страницы, но и одновременно убирает лишние поля, осветляет фон и компенсирует перекос.
В книжном режиме особенно удобно то, что крышку сканера можно не опускать полностью. ScanPapyrus сама убирает лишние поля и черные области по краям. На практике это сильно ускоряет процесс: открыл книгу, положил разворот, дождался скана, перевернул страницу, положил следующий разворот. Для домашней оцифровки учебников, справочников и конспектов это один из самых рациональных сценариев среди настольных программ сканирования.
После завершения прохода разворот попадает в проект уже как две страницы. Их сразу видно в Page List, и если книга случайно положена вверх ногами, исправление занимает секунды: Turn Left, Turn Right или Flip Image. Это важный штрих: ScanPapyrus не требует идеальной укладки каждого разворота. Она допускает рабочий поток с небольшими отклонениями и дает быстрые способы поправить результат.
Однако у книжного режима есть свои жесткие правила, которые лучше знать заранее. Для корректного разделения левый лист должен действительно находиться слева, а правый — справа. Сам разворот должен лежать в естественной горизонтальной ориентации, как при обычном чтении. Если линия сгиба выражена слабо или оригинал уложен нестандартно, результат становится менее предсказуемым, и тут уже лучше либо поправить укладку, либо использовать ручную доработку после сканирования.
С точки зрения производительности у книжного режима есть еще одно преимущество: один проход дает две страницы на выходе. В большой книге это радикально сокращает время. Неудивительно, что именно связка Batch Scanning + Split the book spread into two pages воспринимается как центральная идея всей программы. Для обычных документов это просто удобно, а для книг — это уже профильный рабочий сценарий.
Автоматическая обработка страниц после сканирования
У ScanPapyrus сильная сторона не только в захвате изображения, но и в том, что происходит сразу после скана. Программа умеет автоматически выполнить несколько операций: выровнять перекошенную страницу, обрезать белые и черные поля, поднять контраст, осветлить серый фон и в batch-режиме при необходимости разделить разворот на две страницы. Это означает, что пользователь получает на выходе не сырой снимок со стекла, а уже подготовленную страницу, пригодную для сборки документа.
Auto Deskew полезен там, где лист на стекле лежал с небольшим наклоном. Функция выравнивает страницу, но при очень низком качестве сканирования может слегка деформировать исходное изображение. Поэтому логика простая: для документов ее почти всегда стоит держать включенной, а для деликатных иллюстраций или фото — смотреть по результату. В обычной бумажной оцифровке польза от нее значительно выше возможных побочных эффектов.
Auto Cropping — одна из самых полезных функций программы. Она отрезает не только лишние белые поля документа, но и черные полосы, которые появляются по краям при сканировании с приоткрытой крышкой. Это особенно заметно на книгах и толстых подшивках, которые физически неудобно плотно прижимать к стеклу. В ScanPapyrus эта операция завязана и на дополнительные параметры: если в Settings задан Insert margins, то после автообрезки программа может добавить поля обратно, чтобы текст не оказался слишком близко к краю.
Auto Contrast очищает бледный бумажный фон и делает текст более плотным. Для серых офисных ксерокопий, старых распечаток и учебных материалов это часто дает очень заметный прирост читаемости. Но здесь же лежит и типичное ограничение: для цветного режима такая коррекция иногда нежелательна, потому что способна увести цвета. Поэтому у ScanPapyrus есть очень внятная практическая логика: документы — да, цветные изображения — осторожно.
В batch-режиме к этой тройке добавляется автоматическая ротация и разрезание разворота. Это превращает весь пакетный поток в почти автономную цепочку: сканер отдает кадр, программа его выравнивает, чистит, усиливает, при необходимости делит на две страницы и сразу добавляет в проект в пригодном для дальнейшей сборки виде. Именно из-за такого набора ScanPapyrus воспринимается как программа для реальной поточной оцифровки, а не как простая прослойка между сканером и PDF.
Редактирование страниц в ScanPapyrus
После сканирования работа переходит на вкладку Editing. Здесь ScanPapyrus делит редактирование на четыре группы: Processing, Rotation, Scaling и Correction. Такой расклад удобен тем, что пользователь сразу понимает, идет ли речь об автоматической переработке изображения, о его повороте, о масштабе просмотра или о ручной корректировке.

В Processing находятся Restore, Auto Crop и Auto Split. Restore возвращает страницу к исходному состоянию, то есть откатывает все сделанные изменения и восстанавливает оригинал, полученный со сканера. Для рабочего потока это ключевая страховка: можно без опаски пробовать обрезку, повороты и коррекцию, зная, что исходник не потерян.
Auto Crop на вкладке Editing используется уже как локальная операция над конкретной страницей, а не как глобальная настройка при сканировании. Это удобно, когда большинство страниц нормальные, а один лист требует дополнительной обрезки. Если при этом включены Auto Deskew и Auto Contrast, программа при автообрезке может одновременно выровнять страницу и подправить яркость/контраст. То есть Auto Crop здесь — не только про поля, а про быстрый повторный цикл автоматической доводки.
Auto Split в Editing позволяет отдельно взять уже полученный широкий скан и разрезать его на две страницы. Это полезно, если развороты были отсканированы без книжного режима и только потом стало понятно, что документ нужно разложить на отдельные листы. Условия те же: разворот должен быть ориентирован горизонтально, в естественном положении для чтения. Тогда программа заменяет одну страницу двумя новыми.
В Rotation находятся Turn Left, Turn Right, Flip Image и Rotate Angle. Первые три решают типовые проблемы мгновенно. Rotate Angle — инструмент для более тонкой ситуации, когда лист лежит криво не на 90 градусов, а, например, на 2–5 градусов или вообще под произвольным углом. После вызова этой команды Page List временно заменяется панелью управления углом, где можно вращать колесо мышью и сразу видеть результат в предпросмотре. Это один из тех элементов, по которым видно, что программа рассчитана на реальную правку сканов, а не только на базовый поворот.
Группа Scaling меняет только размер просмотра: Zoom In, Zoom Out, Fit to Window. Сама страница от этого не перезаписывается. Это важно, потому что в ScanPapyrus масштаб просмотра и реальное DPI страницы — разные вещи. Для контроля мелкого текста, подписи или печати можно приблизить страницу, не вмешиваясь в исходное изображение.
В Correction доступны ручная обрезка через Crop the Image и коррекция Image Contrast. Это уже тот уровень, где пользователь доводит единичные проблемные страницы. Если автоматике не хватило точности — например, край страницы захвачен неидеально или фон надо подправить вручную, — именно здесь ScanPapyrus переходит из режима сделай сама в режим точечной доработки. Она не пытается конкурировать с полноценным графическим редактором, но набор операций для сканов у нее достаточный и очень по делу.
Сборка документа и управление порядком страниц
После сканирования и редактирования наступает этап Composition. Это вкладка, которая отвечает за логику документа как целого: в каком порядке идут листы, какие страницы отмечены, что нужно удалить и можно ли автоматически выстроить последовательность по номеру страницы.
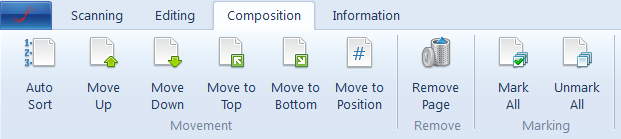
В группе Movement находятся Auto-Sort, Move Up, Move Down, Move to Top, Move to Bottom, Move to Position. Команды перемещения говорят сами за себя, но главная здесь — Auto-Sort. Она заставляет ScanPapyrus распознать номера страниц и отсортировать документ в возрастающем порядке. Перед этим программа спрашивает, где искать номер — Top of the page или Bottom of the page.
Работает это не как магия в один клик, а как контролируемый полуавтоматический инструмент. После распознавания ScanPapyrus накладывает распознанные номера на миниатюры страниц в Page List. Если какой-то номер распознан ошибочно, его можно поправить вручную. Если программа не распознала номер вообще, вместо него появится ?, и нужное значение можно ввести самостоятельно. После проверки нужно нажать Accept, и только тогда документ перестраивается в новом порядке. Такой подход разумен: программа ускоряет сортировку, но не забирает у пользователя контроль над результатом.
Remove Page удаляет текущую страницу или сразу все отмеченные страницы. Перед удалением ScanPapyrus запрашивает подтверждение. Для больших документов это нормальная защита от случайной потери листов, особенно когда пользователь отмечал страницы под групповую операцию и забыл снять выделение.
Mark All и Unmark All служат не только для удаления. Через отметки строится вся логика групповых операций в программе. Если несколько страниц отмечены в Page List, к ним можно разом применять восстановление оригинала, автообрезку, разделение разворотов, повороты и другие операции из боковой панели. Это очень удобный механизм для серийной доработки проблемных страниц, например когда 15 листов из одного блока надо одинаково повернуть или повторно обрезать.
Для навигации в документе тоже все сделано прагматично. Есть клавиатурные сочетания Ctrl+Up и Ctrl+Down для перемещения страницы, Del для удаления и Ctrl+A для выделения всех страниц. В интерфейсе ScanPapyrus вообще много хороших мелочей такого рода: они не делают программу красивее, но делают ее заметно быстрее в длинной работе.
Экспорт из ScanPapyrus: PDF, DjVu, изображения и печать
После того как страницы отсканированы, обработаны и выстроены в нужном порядке, ScanPapyrus предлагает четыре основных направления вывода: Save to PDF, Save to DjVu, Save to Folder и Print. Это важный набор, потому что он покрывает почти все практические сценарии: архивный PDF, компактный DjVu, набор отдельных изображений или бумажный вывод на принтер.
Save to PDF
Экспорт в PDF в ScanPapyrus сделан подробно. Окно Export to PDF состоит из настроек слева и предпросмотра справа. В General задаются Scale, Paper size, Orientation, режим сохранения Save to file, Append pages to an existing file, Save to Folder и флажок Open the newly created PDF document. Это уже показывает, что ScanPapyrus умеет не только создать новый PDF, но и дописывать страницы в существующий файл.
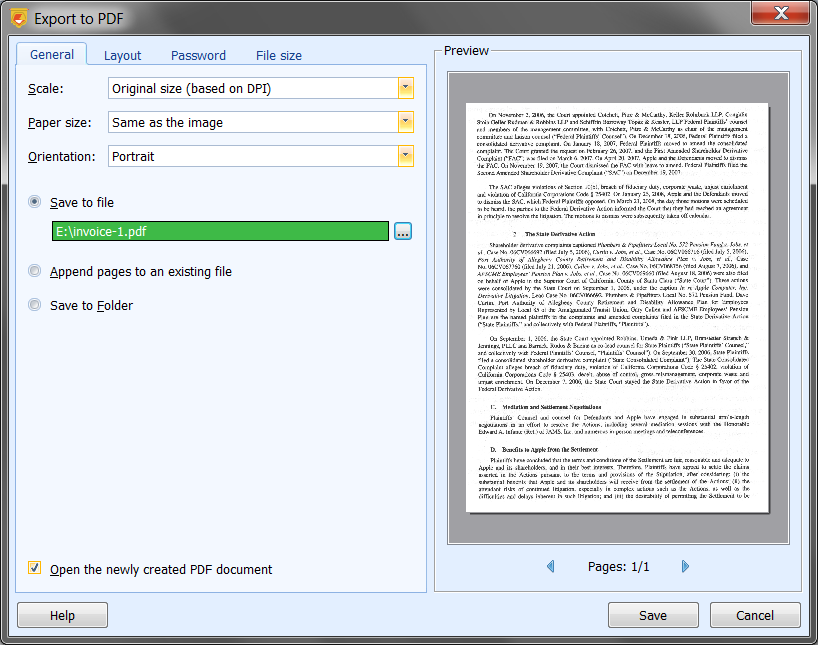
Параметр Scale предлагает три логики: Original size (based on DPI), Stretch the image to fill the page и Stretch the image while keeping its proportions. Для документов это очень важно. Если нужно, чтобы скан физически соответствовал исходному размеру, используется первый вариант. Если нужно заполнить страницу PDF, можно растянуть изображение, но при этом легко потерять пропорции. Самым универсальным обычно оказывается режим с сохранением пропорций.
Paper size поддерживает A4, Letter, A0, A1, A2, A3, A5, A6 и Same as the image. Orientation умеет работать в режимах Portrait, Landscape, Automatically for each page и Manually for each page. Последний вариант особенно полезен для смешанных документов, где часть листов портретная, а часть альбомная: пользователь может пролистать страницы в preview и выставить ориентацию для каждой вручную.
Есть и дополнительные параметры: PDF quality, вкладка Layout с обязательными полями и позиционированием изображения на странице, вкладка Password для защиты документа паролем и вкладка File size для ограничения максимального размера итогового PDF. Важная особенность ScanPapyrus здесь в другом: при обычном Save to PDF программа не делает OCR, а сохраняет страницы как изображения. Благодаря этому внешний вид страницы совпадает с бумажным оригиналом. OCR выполняется отдельно через Recognition.
Save to DjVu
Save to DjVu — отдельная экспортная ветка для тех случаев, когда нужен компактный многостраничный файл и сам формат DjVu уместен. В этом окне задается компрессия: чем она выше, тем меньше итоговый файл и тем хуже качество страниц. Стандартная логика ScanPapyrus тут предельно прямая — регулировать компромисс между размером и качеством, а не маскировать его сложными профилями. Для архивирования черно-белых и серых текстовых материалов DjVu все еще остается разумным вариантом.
Save to Folder
Save to Folder сохраняет страницы как отдельные файлы форматов JPEG, TIFF, PNG или BMP, а также умеет собирать их в один Multipage TIFF file. Для JPEG можно задать качество от 50% до 100%, по умолчанию используется 85%. Для TIFF доступны алгоритмы LZW, RLE, JPEG и CCITT Group 4, причем последний предназначен для черно-белых изображений. Здесь же задаются File Prefix, счетчик, дата в имени файла и опция открытия папки после экспорта. Это хороший режим для тех случаев, когда дальше страницы будут идти в архив изображений, в другую OCR-систему или в сторонний редактор.
Команда Print отправляет документ на печать, а перед этим показывает окно предварительного просмотра. В preview можно прокрутить документ, сменить ориентацию и проверить, как страницы будут выглядеть на бумаге. Это логичное продолжение идеи программы: ScanPapyrus работает не только на сохранение сканов, но и на быстрый бумажный цикл, включая режим Photocopy.
OCR в ScanPapyrus: как программа распознает текст
В ScanPapyrus распознавание текста вынесено на вкладку Recognition. Это правильное архитектурное решение: обычный поток сканирования и экспорта не смешивается с OCR, а значит пользователь может сначала собрать чистый проект, а уже потом решать, нужен ему просто графический PDF или полноценный searchable PDF и редактируемый текстовый документ. На вкладке Recognition есть как минимум Recognize Online, Task List и Service Settings.
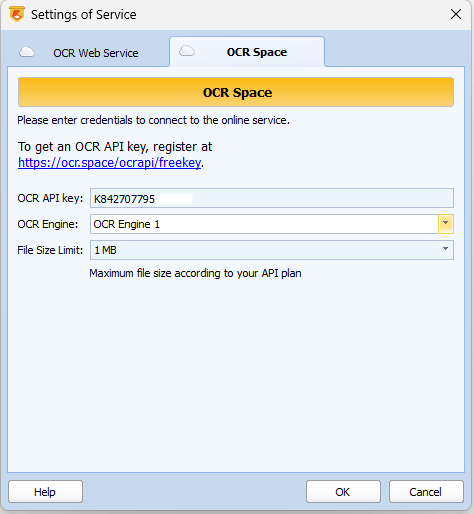
Через Service Settings ScanPapyrus подключается к облачным сервисам распознавания. Один из вариантов — OCR Web Service, второй — OCR Space. В первом случае в окне настроек вводятся параметры аккаунта, после чего распознавание запускается через Recognize Online. В окне Recognition Options можно выбрать язык документа или сразу несколько языков, если текст смешанный. Это полезно для инструкций, юридических материалов и технических документов, где русский текст часто соседствует с английским.
Через OCR Web Service ScanPapyrus умеет выдавать результат в нескольких форматах: Word (*.doc/*.docx), Excel (*.xls/*.xlsx), PDF, Rich Text и Plain Text. Если исходник — таблица, можно сразу получить Excel. Если нужен редактируемый документ с сохранением структуры и вставленными изображениями, подходит Word. Если нужен просто распознаваемый PDF, используется PDF-выгрузка с текстом. После завершения распознавания результат попадает в окно статусов, откуда его можно сохранить через Save As….
Через OCR Space поток выглядит немного иначе. В Service Settings задаются OCR API key, движок распознавания и лимит размера файла, а в окне распознавания доступны варианты PDF with an invisible text layer, PDF with a visible text layer и Plain Text. Первый вариант — классический searchable PDF: изображение страницы остается как есть, а поверх него накладывается невидимый текстовый слой для поиска и копирования. Второй вариант делает текстовый слой видимым. Это удобно, если надо сразу проверить качество распознавания прямо в документе.
Очень важно понимать разницу между обычным Save to PDF и OCR-веткой. Обычный PDF в ScanPapyrus — это визуально точная упаковка страниц-изображений. OCR — отдельная операция после сканирования, которая уже превращает документ в searchable PDF или в редактируемые форматы. Для серьезной работы это плюс: можно сначала добиться идеального внешнего вида страниц, а потом уже решать вопрос распознавания, не смешивая одно с другим.
Практические сценарии использования ScanPapyrus
Как быстро отсканировать пачку договоров в один PDF
Самый практичный маршрут выглядит так:
-
Нажать
Select Scannerи выбрать драйвер без префиксаWIA. -
В
Color ModeвыставитьGrayscale, а вQuality—Good. -
Оставить включенными
Auto Deskew,Auto Croppingи при необходимостиAuto Contrast. -
Если документ идет через автоподатчик, в
SettingsвыбратьPaper Source: Automatic feeder (ADF), а при двухсторонних листах —Duplex Mode: Both sides (duplex). -
Для разового прогона через ADF достаточно нажать
Scan Page: ScanPapyrus прогонит весь набор листов из автоподатчика. -
После проверки порядка страниц открыть
Save to PDF, выставитьOriginal size (based on DPI)илиStretch the image while keeping its proportions, затем сохранить файл.
В этом сценарии ScanPapyrus хороша тем, что не требует отдельно чистить поля, поворачивать листы и заново собирать документ в сторонней программе. Основной поток укладывается в одно окно и пару вкладок.
Как оцифровать книгу со стекла сканера
Для книги разумнее идти другим путем:
-
На вкладке
ScanningнажатьBatch Scanning. -
Выставить интервал, чаще всего 3–5 секунд для нормального темпа переворачивания страниц.
-
Включить
Split the book spread into two pages. -
При необходимости задать ротацию для всех, четных или нечетных страниц.
-
Положить разворот горизонтально, чтобы левый лист был слева, а правый — справа.
-
После каждого прохода просто перелистывать книгу; для немедленного старта следующего скана использовать
Scan Now >или клавишуEnter. -
По окончании проверить несколько миниатюр в
Page List, поправить спорные страницы черезTurn Left,Turn RightилиFlip Image, затем сохранить в PDF или DjVu.
Именно в этом режиме ScanPapyrus чувствуется как специализированная книжная программа, а не как стандартный сканер-драйвер.
Как вытащить из документа только печать, подпись или фрагмент
Если нужна не вся страница, а только кусок, используется Scan Region:
-
Нажать
Scan Region. -
Дождаться предварительного скана всей страницы в низком разрешении.
-
Выделить нужный участок рамкой.
-
В нижней части диалога задать финальное разрешение, например 600 DPI.
-
Выполнить окончательный проход и не двигать оригинал между первым и вторым сканом.
Это один из самых рациональных способов получить качественный штамп или подпись без лишнего тяжелого скана всей страницы.
Как собрать mixed-документ из сканов и готовых файлов
ScanPapyrus умеет не только сканировать, но и добавлять страницы извне. Для этого используются Extract from PDF, Extract from DjVu и Append Images. Практический сценарий выглядит так: часть страниц отсканировали, затем добавили имеющийся PDF-приложение, после чего докинули несколько JPEG-страниц и уже весь собранный документ отсортировали, при необходимости удалили дубли и сохранили в один PDF. Надо помнить, что при Extract from PDF программа забирает из PDF именно изображения страниц, игнорируя текстовый слой.
Как получить searchable PDF
Если нужен PDF с поиском по тексту, маршрут такой:
-
Сначала отсканировать документ в нормальном качестве, обычно
Good/300 DPI. -
Проверить, что страницы выровнены и аккуратно обрезаны.
-
Перейти на вкладку
Recognition. -
Настроить сервис через
Service Settings. -
Нажать
Recognize Online, указать язык документа и выбратьPDF with an invisible text layerлибо обычныйPDFв OCR Web Service, если нужен распознаваемый PDF с текстом. -
После завершения сохранить результат через
Save As….
Важная логика здесь в том, что качественный OCR начинается не с вкладки Recognition, а с хорошего скана и нормальной автоматической очистки страницы. ScanPapyrus как раз и удобна тем, что закрывает оба этапа в одном проекте.
Тонкости, которые влияют на качество результата
У ScanPapyrus есть несколько практических правил, которые резко повышают качество на выходе. Первое — выбирать TWAIN-драйвер, а не WIA. Второе — не злоупотреблять Auto Contrast на цветных оригиналах. Третье — для книжного режима всегда класть разворот в естественной горизонтальной ориентации. Четвертое — для OCR не экономить слишком сильно на DPI и не сводить все к 200 DPI, если документ мелкий или проблемный. Все это не советы со стороны, а нормальная внутренняя логика самой программы.
Еще одна сильная деталь — возможность вручную ограничить Scan Area. Если на стекле лежит маленький оригинал, нет смысла гнать всю поверхность сканера. То же самое касается Scan Region: он полезен не только для качества, но и для скорости. В ScanPapyrus довольно много таких мелочей, которые по отдельности выглядят незаметно, а вместе создают очень плотный, производительный рабочий поток.
Наконец, не стоит забывать про проектный режим .scppy. В повседневной работе это огромный плюс. Пользователь может не торопиться с финальным экспортом, а сначала накопить аккуратный проект, поправить проблемные листы, отсортировать страницы, удалить мусор, прогнать OCR и только потом выгружать итоговый PDF. Это куда надежнее, чем сканировать документ вслепую сразу в финальный файл.
Ограничения и спорные моменты
При всех сильных сторонах ScanPapyrus не пытается быть всем сразу. Это не полноценный PDF-редактор уровня офисного комбайна. Внутри нее нет режима глубокого редактирования уже готового PDF как текстового документа. Ее сила — получить, очистить, выровнять, разложить, отсортировать и сохранить страницы, а не переписывать содержание PDF вручную. Даже OCR вынесен в отдельный поток и не смешан с обычным Save to PDF.
Второй важный момент — зависимость от корректного драйвера сканера. ScanPapyrus заметно лучше чувствует себя с TWAIN, а при WIA возможны проблемы и нестабильное поведение. Это не катастрофа, но в реальной эксплуатации это означает простое правило: если сканер ведет себя странно, первым делом нужно смотреть именно на драйвер и выбранный источник в Select Scanner.
Третий момент касается OCR. В самой логике ScanPapyrus распознавание тесно завязано на внешние сервисы через Service Settings. Это удобно тем, что программа не перегружается собственным тяжелым локальным движком, но одновременно означает, что OCR — отдельная облачная ветка процесса, а не полностью автономная офлайн-функция внутри стандартного экспорта. Для одних пользователей это нейтрально, для других — принципиальный критерий выбора.
Сравнение с аналогами
NAPS2
NAPS2 — это бесплатная open-source программа сканирования, которая работает на Windows, Mac и Linux, умеет сканировать с устройств разных производителей, сохранять результат в PDF, TIFF, JPEG и PNG и поддерживает OCR. Ее сильная сторона — простота и универсальность.
На фоне NAPS2 ScanPapyrus выглядит более специализированной именно под поток оцифровки документов и книг. Там, где NAPS2 делает ставку на простую универсальную схему сканировать и сохранить, ScanPapyrus делает ставку на Batch Scanning, разделение разворотов, сортировку по номеру страницы, проектный режим .scppy, книжную ориентацию и более явную постобработку сканов прямо внутри потока. Если задача — быстро сканировать и складывать простые PDF с минимальным количеством настроек, NAPS2 очень рациональна. Если задача — регулярно возиться с бумажными архивами и книгами, ScanPapyrus дает более предметный инструментарий именно под этот тип работы.
VueScan
VueScan позиционируется как универсальное сканирующее ПО для Windows, macOS и Linux и работает не только с планшетными и документными сканерами, но и с пленочными и слайдовыми устройствами. Это совсем другой акцент: не столько поток документов, сколько максимальная широта аппаратной совместимости и разнообразие сценариев сканирования.
На этом фоне ScanPapyrus выигрывает не универсальностью, а профилированностью. Ее интерфейс прямо заточен под документный поток: Scan Page, Batch Scanning, Split the book spread into two pages, Auto-Sort, Save to PDF, Save to DjVu, групповые операции по отмеченным страницам. Для домашнего архива бумаг, офисных пакетов и оцифровки книг такая специализация оказывается полезнее, чем просто широкий охват устройств. VueScan логичнее выбирать, когда приоритет — экзотическое железо, пленка, слайды и сценарии за пределами классического бумажного архива. ScanPapyrus логичнее выбирать, когда приоритет — именно документы и книги.
PaperScan
PaperScan — это мощное TWAIN/WIA-приложение для Windows, ориентированное на сканирование, OCR, просмотр, печать, коррекцию изображения, компрессию и импорт большого числа форматов. В линейке PaperScan есть и выраженный акцент на batch scanning, автодескью, удаление границ и кроп.
По духу PaperScan ближе к ScanPapyrus, чем NAPS2 или VueScan, но акценты все равно различаются. PaperScan — это более широкий сканирующий комбайн. ScanPapyrus — более сфокусированный инструмент под сценарий бумага/книга → чистые страницы → правильно собранный документ. В ScanPapyrus книжный поток и разделение разворотов встроены в саму основу интерфейса и batch-логики, а не выглядят как дополнительная возможность среди десятков других. Если нужен максимально широкий набор функций по импорту, просмотру и общей обработке, PaperScan выглядит сильнее как универсальный центр. Если нужен более прямой и быстрый цикл именно для документов и книг, ScanPapyrus часто оказывается удобнее.
ABBYY FineReader PDF
ABBYY FineReader PDF позиционируется как PDF-решение для цифрового документооборота: оно умеет оцифровывать, находить, редактировать, защищать, делиться и совместно использовать PDF и сканы, опираясь на OCR. Это уже другая категория программ — ближе к полноценной работе с документами после захвата, чем к собственно процессу сканирования.
На фоне FineReader PDF ScanPapyrus выглядит уже не как конкурент во всем, а как более узкий, но очень эффективный инструмент именно на этапе сканирования и первичной подготовки страниц. У ScanPapyrus сильнее поток сканирования со стекла и через ADF, книжный режим, пакетный таймер, автообработка и сборка документа из страниц. У FineReader PDF сильнее последующая жизнь документа: OCR-центричность, работа именно с PDF как офисным объектом, редактирование и более широкий документооборот. Если задача начинается со слова оцифровать, ScanPapyrus очень уместна. Если задача начинается со слова редактировать PDF и работать с ним дальше, FineReader PDF логичнее.
Короткий вывод по сравнению с аналогами
Если нужен максимально простой бесплатный сканер на все платформы — ближе NAPS2. Если нужна максимальная универсальность по устройствам и нестандартным сценариям — ближе VueScan. Если нужен широкий Windows-комбайн для захвата и обработки — ближе PaperScan. Если нужен полноценный PDF/OCR-офис — ближе ABBYY FineReader PDF. А ScanPapyrus занимает очень конкретную и понятную нишу: документный и книжный поток, где важны пакетное сканирование, автообработка, правильный порядок страниц и быстрый выход в PDF/DjVu без лишней суеты.
Кому ScanPapyrus подходит лучше всего
ScanPapyrus лучше всего подойдет тем, кто регулярно работает именно с бумажным источником. Это домашний архив документов, бухгалтерские и юридические пачки, сканирование учебников, конспектов и методичек, цифровка старых папок с распечатками, сборка приложений к договорам, подготовка searchable PDF через отдельный OCR-контур. В этих задачах ее преимущества складываются в систему: таймер, развороты, автообрезка, автоконтраст, сортировка по номерам страниц, проектный режим и несколько форматов экспорта.
Меньше всего смысл в ScanPapyrus будет там, где пользователь почти не сканирует, а в основном редактирует уже существующие PDF-файлы как рабочие документы. В этом случае сила программы используется не полностью. ScanPapyrus раскрывается не в офисном поправить PDF, а в цепочке бумага → скан → очистка → сборка → экспорт → при необходимости OCR.
Итоги
ScanPapyrus — это сильная специализированная программа для тех, кто сканирует не случайные два листа в месяц, а регулярно работает с бумажными документами, книгами и архивами. Ее главные достоинства не в эффектных маркетинговых функциях, а в практичной архитектуре: понятная лента Scanning / Editing / Composition / Information, хороший набор точных команд вроде Scan Page, Batch Scanning, Scan Region, Rescan Page, надежная автоматическая обработка, реальная работа с книжными разворотами, удобная сборка документа и отдельный OCR-контур через Recognition.
Если оценивать программу именно как инструмент оцифровки, ScanPapyrus производит очень цельное впечатление. Она не пытается заменить собой все возможные категории PDF-софта и из-за этого выигрывает в главном: быстро и аккуратно превращает бумагу в нормально собранный цифровой документ. Для обзорного текста о конкретной программе этого достаточно, чтобы сделать прямой вывод: ScanPapyrus особенно хороша там, где нужно много сканировать, мало суетиться и получать предсказуемый результат.