
MindGems Fast Duplicate File Finder — это не просто программа для поиска одинаковых файлов на компьютере, а инструмент с несколькими разными сценариями работы: он умеет находить точные дубликаты по содержимому, похожие документы и бинарные файлы, совпадения по размеру, а также файлы с одинаковыми или похожими именами. За счет этого программа закрывает сразу несколько задач: освобождение места, разбор архивов, сравнение папок, очистку рабочих каталогов после копирования и поиск лишних копий на внешних и сетевых носителях.
Важная особенность Fast Duplicate File Finder в том, что это обзор конкретной программы, а не класса duplicate finder в целом. У нее есть вполне узнаваемая логика работы: справа находится список папок и блок сканирования, по центру — результирующая таблица с группами совпадений, снизу — зона Auto Check & Delete / Move or Copy, а над списком — набор кнопок Add Folder, Filter, Start Scan, Auto Check, Quick Check и Options. Интерфейс здесь не маскирует функции за мастером-пошаговиком, а дает прямой контроль над каждым этапом.
Программа особенно хороша в тех случаях, когда обычный поиск дубликатов по имени уже не помогает. Например, когда один и тот же файл лежит в нескольких каталогах под разными именами, когда после ручных переносов накопилось много дублей документов, когда нужно сравнить исходную и резервную папку, либо когда требуется быстро отфильтровать одинаковые файлы на внешнем диске. Для таких задач Fast Duplicate File Finder предлагает не один способ сравнения, а сразу несколько режимов, и именно в этом состоит его сильная сторона.
Скачать Fast Duplicate File Finder
- Оптимизация системы
- Очистка мусора
- Ускорение ПК
- Только дубликаты
- Платная версия
- Сложно новичкам
Что именно умеет программа
Fast Duplicate File Finder решает несколько разных типов задач, которые многие утилиты смешивают в одну кнопку Scan. Здесь логика намного понятнее: сначала выбирается, что именно считать дубликатом, потом — где это искать, а затем — как автоматически отметить лишние копии. Такой подход делает программу удобной не только для разовой очистки папки Downloads, но и для аккуратной работы с большими архивами документов, исходников, установщиков, фотоэкспортов и резервных копий.
Основные возможности программы выглядят так:
-
поиск 100% Equal Files — точных дубликатов по фактическому содержимому файла, даже если имена разные;
-
поиск Similar Files — похожих документов, архивов и бинарных файлов одного типа, когда содержимое частично совпадает;
-
поиск Similar File Names — совпадений и похожих названий файлов, включая перестановку слов; при уровне сходства 100% этот режим превращается в поиск одинаковых имен;
-
поиск дублей по File Size — быстрый режим для файлов одинакового размера;
-
фильтрация по папкам, расширениям, размеру, датам и маскам имени;
-
автоматическая пометка через Auto Check и ручная ускоренная пометка через Quick Check/Uncheck;
-
предпросмотр файлов, открытие через связанную программу, переход к файлу через Locate in Explorer, переименование прямо в списке, экспорт в XML/CSV и сохранение проекта;
-
перемещение, копирование, удаление в корзину, удаление без корзины и даже замена клонов символическими ссылками.
За счет этого Fast Duplicate File Finder полезен не только как duplicate remover Windows, но и как рабочий инструмент для аудита хранилищ. В реальной эксплуатации это означает, что программу можно использовать и для простого сценария найти одинаковые файлы на компьютере, и для более точной задачи — например, проверить две папки на дубль документов, не трогая эталонный каталог.
Интерфейс программы: где что находится и как это устроено
На главном экране Fast Duplicate File Finder почти все видно сразу. Сверху находится классическая панель инструментов. На ней вынесены команды New Project, Open Project, Save Project, Add Folder, Filter, Start Scan, Pause, Auto Check, Quick Check и Options. Под ней — строка состояния проекта и таблица найденных совпадений, в которой выводятся как минимум имя файла, папка, размер, дата, показатель Similarity и номер группы. Справа размещен блок Folders, где можно добавлять и убирать каталоги, включать подпапки и управлять режимом сравнения, а внизу — зона операций с отмеченными файлами.
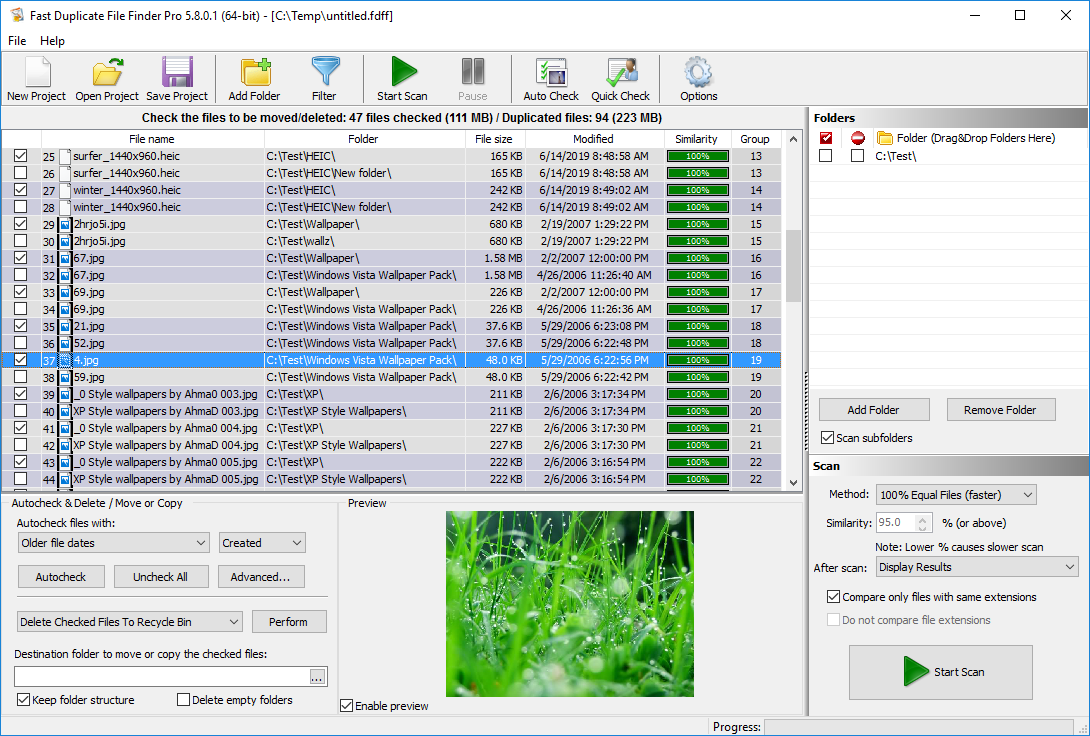
Самый важный элемент интерфейса — центральная таблица результатов. Программа не сваливает все совпадения в одну длинную простыню. Она группирует дубликаты, и это сразу упрощает проверку. Внутри группы видно, какие файлы относятся друг к другу, из каких папок они взяты, насколько они похожи и какие из них уже отмечены для последующего действия. Благодаря этому Fast Duplicate File Finder хорошо подходит для ручной ревизии: не нужно постоянно открывать дополнительные окна, чтобы понять, какой файл откуда взялся и почему программа считает его дублем.
Правая часть окна отвечает за постановку задачи на сканирование. Здесь указываются папки, включается Scan subfolders, выбирается Method, задается Similarity для режимов похожих файлов или имен, а также настраивается поведение после проверки. На скриншоте хорошо видно, что панель сканирования сделана без перегруза: папки сверху, параметры поиска ниже, кнопка Start Scan — внизу справа. Это удачное решение, потому что логика работы читается буквально сверху вниз.
Нижняя область Autocheck & Delete / Move or Copy — то место, где Fast Duplicate File Finder отделяется от простых аналогов. Здесь можно выбрать правило автопометки, нажать Autocheck, снять все отметки через Uncheck All, перейти к расширенным условиям через Advanced…, а затем выполнить действие: удалить, переместить или скопировать отмеченные копии. Здесь же задается папка назначения, включается Keep folder structure, при необходимости удаляются пустые папки и включается Enable preview. То есть программа объединяет поиск, проверку и последующую обработку в одном окне, без лишних мастер-диалогов.
С точки зрения удобства это старомодный, но очень функциональный интерфейс. Визуально программа не старается выглядеть как современный минималистичный cleaner, зато у нее нет ощущения урезанности. Наоборот, практически каждая кнопка отвечает за реальное действие, которое действительно используется в сценарии поиск дубликатов файлов Windows → проверка → выбор лишних копий → удаление или перенос.
Основные режимы поиска: не один scan, а четыре разных инструмента
Большинство пользователей начинают работу с Fast Duplicate File Finder именно с режима 100% Equal Files, и это правильно. Он предназначен для поиска точных дубликатов по реальным данным файла. Программа сравнивает содержимое, а не только имя, размер или хеш. Поэтому она находит одинаковые файлы даже под разными именами и в разных каталогах. Для сценария удалить дубликаты файлов после ручного копирования это основной и самый надежный режим.
Второй режим — Similar Files. Это уже не обычный exact duplicate files поиск, а анализ сходства файлов. Он рассчитан на документы, архивы и бинарные файлы одного формата, где содержимое частично совпадает. Важный нюанс: Fast Duplicate File Finder умеет находить похожие документы даже тогда, когда в них переставлены абзацы, а не просто изменено несколько символов. За счет этого режим полезен для редакций файлов, черновиков, разных версий отчетов и похожих сборок архивов. Но именно этот режим требует дисциплины: его лучше запускать по подготовленному подмножеству папок, а не по всему диску подряд.
Третий режим — File Size. Это самый быстрый способ проверки. Он не анализирует содержимое так глубоко, как 100% Equal Files, а ориентируется на одинаковый размер и, при необходимости, на расширение. Такой подход полезен в качестве чернового прохода, когда нужно быстро отсечь потенциальные повторы в крупном хранилище. Но использовать его как единственный критерий для окончательного удаления стоит осторожно: одинаковый размер не гарантирует одинаковое содержимое. Именно поэтому Fast Duplicate File Finder держит этот режим рядом с более точными способами сравнения, а не выдает его за универсальное решение.
Четвертый режим — Similar File Names. Он нужен в тех случаях, когда задача состоит не в сравнении содержимого, а в разборе хаоса имен. Программа умеет находить похожие названия даже при перестановке слов. Примерно так и работает сценарий с каталогами вроде red rabbit jumping.mov и 23 jumping rabbit (red).mov. При повышении уровня сходства до 100% этот же режим превращается в инструмент поиска файлов с одинаковыми именами в разных папках. Для больших медиатек, выгрузок с облака и архивов проектов это очень полезный вариант.
Практически режимы распределяются так:
-
100% Equal Files — основной вариант для очистки накопившихся точных дублей;
-
Similar Files — рабочий инструмент для похожих документов, архивов и бинарных файлов;
-
File Size — быстрый предварительный отбор;
-
Similar File Names — поиск одинаковых или близких названий файлов в разных папках.
Именно наличие этих четырех режимов делает Fast Duplicate File Finder более гибким, чем программы, которые умеют только ищи одинаковые файлы или смотри по имени и размеру. Здесь под каждую задачу есть свой метод, и этим программа выигрывает в точности повседневного использования.
Как искать точные дубликаты: пошаговая инструкция
Первый сценарий, ради которого многие ставят Fast Duplicate File Finder, — это поиск точных копий файлов. Алгоритм работы здесь очень прямой. Сначала в список справа добавляются папки через Add Folder. После этого при необходимости включается Scan subfolders, чтобы программа проходила не только по корневому каталогу, но и по вложенным папкам. Затем в поле Method выбирается 100% Equal Files. После этого можно сразу запускать Start Scan, либо сначала включить фильтр, если задача требует ограничить область поиска.
Пошагово процесс выглядит так:
-
Нажать Add Folder и добавить один или несколько каталогов.
-
При необходимости оставить включенным Scan subfolders, чтобы программа захватывала подпапки.
-
Выбрать Method → 100% Equal Files.
-
При необходимости открыть Filter и задать ограничения.
-
Нажать Start Scan.
-
Просмотреть сгруппированные совпадения, отметить лишние копии вручную или использовать Auto Check.
-
Выбрать итоговое действие: удаление, перенос или копирование.
После завершения сканирования программа показывает группы найденных дубликатов. У каждой строки есть чекбокс, а сверху в таблице можно оценить имя, папку, размер, дату и принадлежность к группе. Сходство для точных дублей отображается максимально наглядно, и именно здесь становится ясно, почему Fast Duplicate File Finder удобен как duplicate remover Windows: у пользователя перед глазами не просто список подозрительных файлов, а уже разобранные группы с логикой эти файлы совпадают между собой.
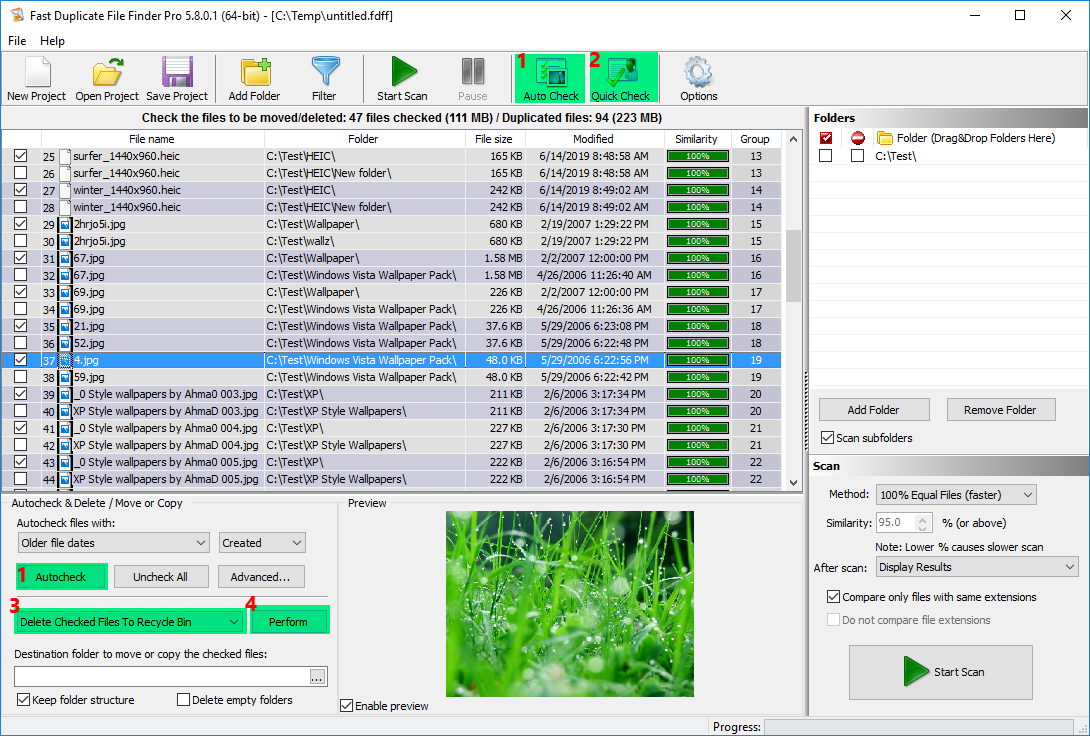
Самый безопасный подход в этом сценарии — сначала использовать удаление в корзину, а не безвозвратное удаление. Программа поддерживает оба варианта, но для первой ревизии диска правильнее выбрать Delete Checked Files To Recycle Bin. Так удобнее проверить, не попало ли в выборку что-то важное. В случае ошибки восстановление делается стандартными средствами Windows. Для серьезной чистки хранилища такой маршрут заметно надежнее, чем агрессивное массовое удаление без промежуточной страховки.
Полезная деталь: Fast Duplicate File Finder разделяет понятия выделенный и отмеченный файл. Выделение нужно для работы в интерфейсе, а отметка чекбоксом — для последующего действия. Это кажется мелочью, но на практике помогает не путаться при массовой обработке. Можно спокойно просматривать одну группу, переключаться между файлами, а затем отдельно управлять именно теми копиями, которые пойдут на удаление, перенос или копирование.
Поиск похожих файлов и похожих имен: где программа раскрывается сильнее всего
Режим Similar Files — одна из наиболее интересных функций Fast Duplicate File Finder. Он нужен там, где точные дубликаты уже не главная проблема. Например, когда в папках накопились разные версии документов, слегка измененные отчеты, несколько архивов с частично совпадающим содержимым или экспортированные копии бинарных файлов одного типа. В таких случаях стандартный поиск одинаковых файлов ничего не найдет, а Fast Duplicate File Finder как раз и нужен для анализа сходства.
Ключевой параметр в этом режиме — Similarity. По умолчанию программа использует уровень 95%, и для обычной практики это разумный компромисс между чувствительностью и количеством ложных срабатываний. При снижении процента сканирование замедляется, а вероятность спорных совпадений растет. Поэтому Similar Files — не тот режим, который стоит запускать на весь диск ради эксперимента. Он гораздо лучше работает как точечный инструмент: сначала выбрать нужные папки, при необходимости сузить диапазон расширений и только потом проверять сходство.
Важно понимать границы этого режима. Fast Duplicate File Finder хорошо работает с похожими документами, архивами и бинарными файлами, но не является специализированным duplicate photo cleaner или duplicate mp3 finder. Для визуально похожих изображений и похожих песен у MindGems есть отдельные продукты. Поэтому использовать Similar Files для найти похожие фото из разных фотосессий — не лучший сценарий. А вот для папки с договорами, отчетами, DOCX, PDF, XLS и похожими экспортами — наоборот, очень удачный.
Режим Similar File Names — другой тип работы, тоже весьма практичный. Он полезен, когда файлы нужно разбирать по паттернам именования. В корпоративных архивах, папках с вложениями, скачанными документами или коллекциях медиаматериалов нередко встречаются варианты вроде copy of report, report final, final report, report (1) и так далее. Fast Duplicate File Finder умеет искать именно такие пересечения. При этом режим анализирует не только простую подстроку, а сходство названий в целом, включая перестановку слов.
Отдельно стоит подчеркнуть, что при Similarity = 100% в режиме Similar File Names программа ищет именно дубликаты имен. Это удобно, когда задача звучит не как найти одинаковое содержимое, а как найти файлы с одинаковыми именами в разных папках. Такой подход часто нужен при проверке архивов, где одно и то же название файла встречается в нескольких версиях проекта или резервных копиях.
Фильтрация: одна из самых полезных частей программы
Фильтрация в Fast Duplicate File Finder сделана не как второстепенная опция, а как полноценный рабочий инструмент. Кнопка Filter на панели — это не декоративный флажок, а один из главных способов превратить общий поиск дубликатов файлов в точный аудит конкретного массива. Особенно это полезно на крупных хранилищах, где бессмысленно прогонять весь объем данных целиком.
Когда фильтр включен, программа позволяет ограничить поиск по нескольким направлениям сразу: по папкам, расширениям, размеру, датам и имени файла. Важно и то, что фильтр может работать в двух режимах — Exclude matches и Include only matches. Это означает, что Fast Duplicate File Finder умеет как исключать определенный набор файлов из проверки, так и наоборот, сканировать только заранее заданный сегмент. Для большого архива разница между этими подходами принципиальна.
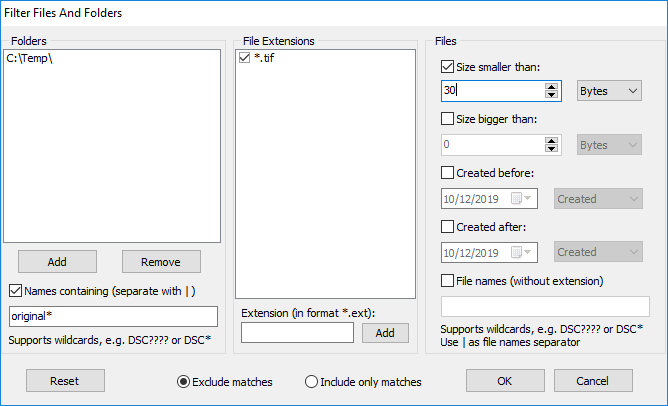
На практике фильтр решает несколько типовых задач:
-
исключить системные, сервисные или временные каталоги;
-
проверять только определенные типы файлов, например
*.pdf,*.docx,*.zip,*.tif; -
искать дубликаты только в диапазоне размеров, например крупнее 50 МБ;
-
ограничить поиск по дате создания или модификации;
-
работать с масками имени — от стандартного
Copy of *до более сложных шаблонов с*и?.
Особенно удачно реализована фильтрация по имени. Программа поддерживает подстановочные символы и позволяет использовать маски вроде A*LOT?OF* или Copy of *. В реальной работе это полезно не столько для экзотических шаблонов, сколько для очень земных сценариев: быстро исключить из поиска служебные копии, старые экспортные файлы, пакеты с типовыми префиксами или, наоборот, оставить в анализе только их.
Фильтр нужно настраивать до запуска сканирования. В этом состоит его практический смысл. Программа не просто скрывает лишнее в результатах, а сокращает область анализа заранее. За счет этого поиск дублей документов, видеоархивов или повторяющихся установщиков проходит быстрее и дает меньше мусорных совпадений. Именно поэтому Fast Duplicate File Finder особенно хорошо чувствуется на больших хранилищах: фильтр здесь работает как инструмент подготовки выборки, а не как косметическое сито после сканирования.
Предпросмотр и ручная проверка: почему в этой программе удобно не спешить с удалением
Хороший duplicate finder отличается от посредственного не только тем, как он ищет, но и тем, как он позволяет проверить результат. Fast Duplicate File Finder в этом смысле сделан правильно. Он поддерживает внутренний предпросмотр файлов и позволяет просматривать найденные элементы до того, как пользователь выполнит удаление, перенос или копирование. Для популярных форматов предусмотрен встроенный просмотр, а в более сложных случаях файл можно открыть через связанную программу.
В нижней части главного окна предусмотрена область Preview. Это особенно удобно при работе с изображениями, текстовыми файлами и документами: не нужно каждый раз открывать проводник и запускать внешний просмотрщик, чтобы убедиться, что перед вами действительно лишняя копия. В Fast Duplicate File Finder предпросмотр встроен в основной сценарий работы, а значит пользователь тратит меньше времени на верификацию групп.
Для более сложных форматов программа тоже не ограничивается базовым набором. В списке возможностей у нее есть предварительный просмотр PDF, RAW и бинарных файлов, а также отдельная опция для включения предпросмотра документов Microsoft Office. То есть программа не зацикливается только на JPG и TXT, а покрывает гораздо более широкий набор повседневных форматов. Это заметно повышает ценность Fast Duplicate File Finder для офисной работы и архивов документации.
Отдельный плюс — возможность Locate in Explorer и открытие файлов связанной программой. Это важно в тех случаях, когда одинаковые файлы лежат в похожих каталогах, а принять решение что оставить нужно с учетом контекста: рядом лежат исходники, служебные документы, сопровождающие файлы, каталоги проекта. Быстрое открытие через Проводник Windows и запуск стандартным приложением дают этой программе качество полноценного рабочего инструмента, а не одноразового cleaner.
Ручная проверка особенно нужна в двух режимах: Similar Files и Similar File Names. В точных дублях риск ошибки ниже, а в похожих документах и названиях решение почти всегда должно принимать человек. Fast Duplicate File Finder устроен так, что не заставляет бездумно доверять автоматике: он сначала группирует, показывает свойства, дает предпросмотр и только потом предлагает действие. Это правильная логика для безопасной очистки данных.
Auto Check и Quick Check: автоматическая пометка, которая реально экономит время
Одна из самых сильных сторон Fast Duplicate File Finder — это не только поиск, но и выбор того, что удалять. В простых утилитах на этом месте начинаются ручные мучения: пользователь видит группу из 8 файлов и должен сам проставлять чекбоксы. Здесь такую рутинную работу на себя берет Auto Check. Программа может автоматически отметить все лишние копии в группе, при этом гарантированно оставляя минимум один файл неотмеченным.
Правила автопометки у Fast Duplicate File Finder не примитивные. Отметка может строиться по датам, размерам, расположению, длине имени, длине пути и другим свойствам файла. То есть программа умеет выбирать, например, более старые или более новые копии, файлы в определенных каталогах, варианты с более коротким или длинным путем, а также сочетать критерии через расширенные параметры. Для регулярной чистки сетевых папок, архивов и каталогов проектов это огромное преимущество.
Нужно понимать и другую сторону этой функции: Auto Check специально играет в безопасный режим. Он всегда старается сохранить хотя бы одну копию в группе и не делает рискованных отметок в условиях конфликта правил. Если задать взаимоисключающие условия — например, исключить один каталог из автопометки и одновременно требовать выбора самого нового файла — программа может оставить больше одного элемента неотмеченным. Это не недостаток, а защита от ошибочного удаления.
Для сложных сценариев у Fast Duplicate File Finder есть Advanced…. Там задаются более тонкие условия автопометки, в том числе исключения по типам файлов и фрагментам имени. Такой подход особенно полезен, когда нужно массово удалить мусорные повторы, но сохранить, например, PSD, исходники, документы с определенным префиксом или все файлы из эталонной папки.
Отдельный инструмент — Quick Check/Uncheck. Он нужен не для полной автоматизации, а для быстрого ручного применения правил к уже найденным группам. Здесь можно отметить или снять отметку по папкам, расширениям, размеру, датам и маскам имени. Встроенное правило Check All Except First in Group особенно удобно: оно автоматически оставляет одну копию в группе и помечает все остальные. Для очистки папок с бэкапами, дубликатами инсталляторов или многократно скопированными документами это один из самых быстрых рабочих приемов.
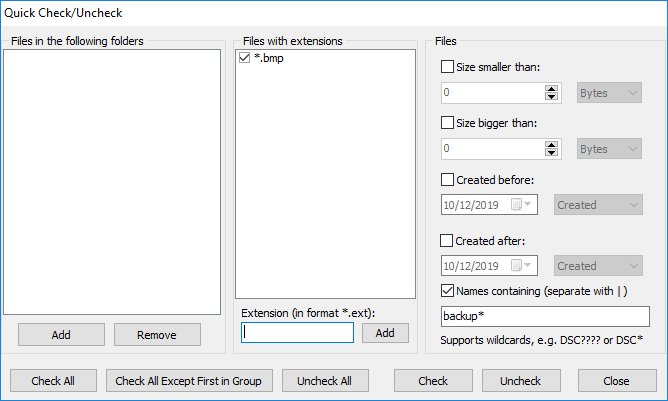
Кроме того, у программы есть удобные контекстные команды для специальных случаев. Можно использовать Check → Check All in This Folder, чтобы быстро отметить все дубликаты внутри выбранной папки, или Check → All Except Excluded, если часть каталогов заранее помечена как исключенная из автоотметки. Это очень полезно в сценарии есть source-папка, ее трогать нельзя, а все совпадения вне нее нужно отметить.
Именно по связке Auto Check + Quick Check + ручная корректировка Fast Duplicate File Finder производит сильное впечатление. Он не просто показывает повторы, а предлагает зрелую систему отбора лишних копий. Для тех, кто регулярно чистит архивы или сравнивает рабочие каталоги, это почти важнее самого алгоритма поиска.
Что можно сделать с найденными файлами
После того как дубликаты найдены и лишние копии отмечены, Fast Duplicate File Finder предлагает несколько вариантов обработки. Базовый набор включает удаление в Recycle Bin, безвозвратное удаление, move и copy. Но на этом возможности не заканчиваются: программа умеет сохранять структуру каталогов при переносе, переименовывать файлы прямо в списке результатов, открывать через ассоциированное приложение, сохранять проект и экспортировать отчет в CSV или XML.
Удаление в корзину — лучший режим для первой очистки. Он дает запас на восстановление и подходит для бытовой и офисной эксплуатации. Когда пользователь уже уверен в алгоритме своей разметки, можно переходить к удалению без корзины, но именно корзина — самый безопасный старт. Для программ класса duplicate remover это важная деталь, и Fast Duplicate File Finder в этом отношении работает так, как должен работать зрелый desktop-инструмент.
Перенос и копирование отмеченных файлов особенно полезны в крупных архивах. Нередко дубликаты не хочется сразу удалять: сначала удобнее вынести их в отдельную папку на проверку. В Fast Duplicate File Finder для этого есть поле Destination folder to move or copy the checked files и опция Keep folder structure. Программа умеет воспроизводить исходную структуру директорий в целевой папке, а значит можно безопасно выгрузить дубль-набор в карантинный каталог и проверить его отдельно.
Переименование прямо в списке результатов — еще одна полезная функция. Она не так часто встречается в дешевых утилитах и особенно выручает в режиме Similar File Names, когда часть конфликта решается не удалением, а нормализацией имен. Для рабочих каталогов, где важно сохранить все версии, но привести названия к единообразию, это очень практичная возможность.
Сохранение и загрузка проектов важны при длинных ревизиях. Большой поиск дубликатов редко делается по схеме открыл — нажал — сразу удалил. Обычно сначала идет сканирование, потом проверка, потом пауза, затем продолжение. Fast Duplicate File Finder позволяет сохранять результаты и возвращаться к ним позже. В бесплатной редакции проект можно сохранить, но загрузка проекта уже ограничена, тогда как в Pro эта связка работает полноценно. Для долгой работы с корпоративными архивами это ощутимая разница.
Экспорт в XML/CSV полезен там, где нужен не только cleanup, но и отчетность. Например, для инвентаризации архива, согласования удаления с коллегами или передачи списка на последующий анализ в Excel. Экспорт больших проектов в CSV в программе отдельно оптимизирован, и это хорошо видно по тому, что функция вынесена в перечень ключевых возможностей, а в изменениях программы экспорт фигурирует как важная часть рабочего сценария.
Настройки безопасности и поведения программы
Окно Options в Fast Duplicate File Finder не перегружено, но очень практично. Здесь собраны настройки, которые напрямую влияют на безопасность очистки и удобство просмотра результатов. Среди них — Protect system files and folders, Skip zero byte files, предупреждение в случае, когда в группе отмечены все элементы для удаления, цветовое или жирное выделение вручную отмеченных файлов, Process priority, Enable logging и опция просмотра документов Microsoft Office.
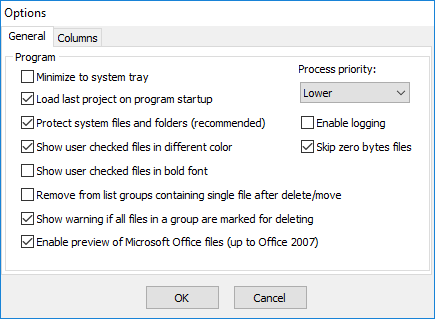
Самая важная настройка здесь — Protect system files and folders. Она включена по умолчанию и не дает программе бездумно вмешиваться в чувствительные каталоги. Это важный момент, потому что дубликаты в системных директориях могут существовать намеренно, а удаление таких файлов способно повредить систему или пользовательскую среду. Программа относится к таким случаям осторожно, и именно благодаря этому ее можно рекомендовать не только опытным пользователям, но и тем, кто не хочет рисковать Windows ради нескольких сэкономленных гигабайт.
Отдельный плюс — предупреждение, если в группе отмечены все файлы. На первый взгляд это простая галочка, но на практике она спасает от самой неприятной ошибки: случайно уничтожить все экземпляры файла вместо удаления лишних копий. В хороших инструментах для поиска дубликатов именно такие защитные барьеры отличают осмысленный workflow от безответственной автоматизации. Fast Duplicate File Finder этот барьер ставит.
Настройка Process priority важна при больших сканированиях. Она позволяет запускать проверку дубликатов в фоне и не превращать работу за компьютером в ожидание завершения очередного анализа. В результате программу удобно использовать даже тогда, когда идет параллельная работа с документами, браузером или IDE. Для длинных прогонов по внешним дискам, NAS и крупным проектам это полезнее, чем кажется.
Опции выделения пользовательских отметок цветом и жирным шрифтом тоже сделаны не для галочки. На большом списке групп быстро теряется понимание, что программа отметила автоматически, а что пользователь дорабатывал вручную. В Fast Duplicate File Finder это можно визуально разделить, и такая мелочь заметно упрощает контроль над финальным набором действий.
Сравнение папок: один из самых практичных сценариев
Fast Duplicate File Finder умеет работать не только по схеме сканируй все подряд, но и как инструмент сравнения двух или нескольких папок. Для этого используется функция Exclude from self-scan. Ее смысл в том, что элементы внутри выбранной папки не сравниваются между собой, а сопоставляются только с файлами из других каталогов в списке. Это очень удобный сценарий для задачи есть source и target, нужно найти только то, что повторяется между ними.
На практике эта функция полезна в нескольких типовых ситуациях. Первая — сравнение исходной папки и копии после ручного переноса. Вторая — ревизия backup-каталога на предмет того, какие файлы уже присутствуют в рабочем архиве. Третья — слияние папок из разных накопителей, когда нужно сохранить содержимое одной как эталон, а из другой убрать лишние повторы. Fast Duplicate File Finder для этого подходит очень хорошо именно потому, что позволяет задавать исходный и целевой контекст без дополнительных мастеров и профилей.
В дополнение к Exclude from self-scan есть и Exclude from auto-check для отдельной папки. Эта опция нужна тогда, когда файлы из определенного каталога должны всегда оставаться неотмеченными, даже если программа массово помечает дубль-набор для удаления или переноса. В результате Fast Duplicate File Finder позволяет выстроить понятную схему: source-папка защищена от автоотметки, target-папки анализируются, совпадения находятся, лишние копии в неэталонных каталогах быстро отмечаются.
Для такого сценария особенно удобна контекстная команда Check → All Except Excluded. Она отмечает все дубликаты, кроме тех, что находятся в исключенных папках или заранее исключены через дополнительные правила. В сочетании с отключением self-scan и защитой source-каталога это превращает Fast Duplicate File Finder в очень сильный инструмент сравнения двух папок на дубликаты. Для реальной работы с архивами эта функция ценнее, чем просто красивый процент нашли N повторов.
Бесплатная и Pro-редакция: что действительно важно знать
Fast Duplicate File Finder существует в вариантах Free и Pro, и различия между ними нужно понимать заранее. Бесплатная редакция не выглядит пустой демо-заглушкой: в ней полноценно доступен поиск точных дубликатов, предпросмотр, Auto Check и базовые действия над exact duplicates. Для обычной домашней задачи найти одинаковые файлы на компьютере и удалить лишнее Free-версии чаще всего достаточно.
Но как только начинается более сложная работа, ограничения становятся заметны. В Pro доступны полноценные Similar Files, Similar File Names, фильтрация, Quick Check/Uncheck, экспорт в XML/CSV, загрузка проектов, отключение сохранения целостности группы при сортировке, отключение папки от self-scan, исключение папок из auto-check и командная строка. Плюс расширяется поддержка предпросмотра: например, PDF и RAW в бесплатной редакции доступны только для первых 10 групп.
Фактически логика разделения такая:
-
Free — сильный инструмент для поиска exact duplicates и базовой очистки;
-
Pro — редакция для точной фильтрации, похожих файлов, похожих имен, проектов, отчетов и сценариев сравнения папок.
Это честное деление. Бесплатная часть закрывает повседневную очистку, а профессиональная — более сложные сценарии, ради которых программу и выбирают вместо простых duplicate finder freeware с одним сканированием и бедным управлением результатами.
Работа с большими архивами: где программа ощущается особенно хорошо
Fast Duplicate File Finder рассчитан не только на несколько папок документов, но и на крупные массивы данных. У него нет жесткого ограничения на количество файлов, папок, дисков или сетевых ресурсов, а само приложение умеет работать с локальными, внешними и сетевыми хранилищами. Это делает программу пригодной не только для домашней чистки, но и для более серьезных сценариев, где архивы давно вышли за пределы одного SSD.
Но может сканировать много не означает, что программу нужно запускать без стратегии. На больших наборах данных особенно важны три вещи: правильный режим поиска, грамотная фильтрация и аккуратная автопометка. Для exact duplicates программа отлично масштабируется, потому что режим 100% Equal Files рассчитан на реальную повседневную работу. А вот Similar Files нужно использовать дозированно: выделять под него только тот сегмент данных, где действительно нужен поиск похожих документов или бинарных файлов.
Для крупных архивов очень помогает сохранение проекта. Большой аудит редко заканчивается за один проход: сначала идет первичное сканирование, потом сортировка, проверка нескольких десятков спорных групп, подготовка списка на перенос, повторное открытие результатов. Именно здесь Fast Duplicate File Finder ведет себя как взрослая программа для систематической работы, а не как кнопка очистить.
Еще один сильный сценарий — перенос отмеченных дублей в отдельный каталог с сохранением структуры. Это особенно удобно на старых фото- и видеоархивах, резервных дисках и общих сетевых папках, где сразу удалять дубликаты слишком рискованно. Вместо радикальной чистки можно сначала выгрузить лишние копии в карантинную папку, сохранить дерево директорий и только потом принять окончательное решение. Fast Duplicate File Finder эту схему поддерживает нативно.
Реальные сценарии использования
Разбор папки Downloads и рабочего стола
Это самый очевидный сценарий: в Downloads скапливаются повторные загрузки установщиков, архивов, PDF и документов. Здесь лучше всего работает 100% Equal Files с фильтром по крупным типам файлов или по размеру. После сканирования можно использовать Check All Except First in Group или автоотметку по дате, а затем удалить лишнее в корзину. Если в списке появятся системно важные объекты, защита системных папок и предупреждение о полной разметке группы добавляют безопасности.
Сравнение исходной папки и резервной копии
Для этого сценария Fast Duplicate File Finder подходит особенно хорошо. Одна папка ставится как source, для нее можно отключить self-scan и исключить ее из auto-check. Вторая и третья папки анализируются относительно нее. После сканирования достаточно использовать All Except Excluded, чтобы быстро отметить копии вне эталонного каталога. Для ревизии backup-структур это один из самых сильных режимов программы.
Очистка архива документов
Когда в папках лежат версии договоров, актов, презентаций, отчётов и PDF, точные дубли — только часть проблемы. Здесь к 100% Equal Files часто стоит добавить Similar Files и поднять внимание к предпросмотру. Сначала программа находит exact duplicate files, затем можно отдельным проходом проверить похожие документы с высоким порогом Similarity. Такой режим не надо запускать на весь диск, но на одном архиве документов он дает очень полезный результат.
Поиск файлов с одинаковыми именами в разных каталогах
Иногда задача не в содержимом, а в том, чтобы найти пересечения по названиям — например, invoice.pdf, report final.docx, scan 001.jpg, video final.mp4. Тут отлично срабатывает Similar File Names с высоким уровнем сходства или со 100% для точного совпадения имен. После этого можно либо переименовать конфликтующие элементы прямо в списке, либо уже вручную решать, что удалить.
Ревизия внешнего диска или NAS
Для внешних накопителей и сетевых хранилищ Fast Duplicate File Finder удобен тем, что умеет работать не только с локальными папками. Здесь важнее всего заранее ограничить область поиска и не запускать похожие файлы по всему массиву сразу. Оптимальная схема — exact duplicates для первичного прохода, затем выборочные фильтры по размеру и расширению, потом перенос лишних копий в отдельную папку с сохранением структуры.
Плюсы программы
У Fast Duplicate File Finder много сильных сторон, но в обзоре программы важнее выделить именно те, которые действительно влияют на повседневное использование.
1. Несколько разных режимов поиска
Программа не ограничивается точными дубликатами. Есть 100% Equal Files, Similar Files, File Size и Similar File Names. Это делает ее гибкой и полезной не только для простой очистки, но и для разбора больших архивов, где дубликаты бывают разного типа.
2. Очень сильная система отбора файлов
Связка Auto Check, Quick Check/Uncheck, расширенные исключения и контекстные команды вроде Check All in This Folder и All Except Excluded — один из главных аргументов в пользу этой программы. Именно тут Fast Duplicate File Finder дает больше контроля, чем многие упрощенные аналоги.
3. Удобное сравнение папок
Поддержка Exclude from self-scan и исключения папок из auto-check превращают программу в сильный инструмент сравнения source и target каталогов. Для архивов, резервных копий и объединения папок это критически полезно.
4. Продуманные меры безопасности
Защита системных папок, предупреждение при выборе всех файлов в группе, работа через корзину и возможность предварительного просмотра значительно снижают риск ошибки. Для duplicate remover это не косметика, а основа доверия к программе.
5. Проектная логика работы
Сохранение результатов, загрузка проектов в Pro, экспорт в CSV/XML, перенос с сохранением структуры каталогов — все это делает программу удобной для длительной и аккуратной ревизии, а не только для разового клика почистить.
Минусы и ограничения
1. Интерфейс функциональный, но не современный визуально
Программа выглядит как серьезный desktop-инструмент старой школы. Для опытного пользователя это не проблема, но тем, кто привык к сверхупрощенным мастерам, сначала придется немного освоиться. При этом функционально интерфейс силен, и после первого знакомства он начинает работать на скорость, а не против нее.
2. Similar Files требует аккуратного применения
Режим похожих файлов — мощная функция, но не универсальная кнопка. Его лучше запускать на ограниченном наборе данных, а не на всем диске. Иначе сканирование будет идти дольше, а количество спорных результатов вырастет. Для фото и музыки это вообще не основной сценарий программы.
3. Часть самых интересных функций сосредоточена в Pro
Для простого exact duplicate files поиска Free-редакция хороша, но похожие файлы, похожие имена, полная фильтрация, загрузка проектов и экспорт — это уже территория Pro. Тем, кому нужна глубокая работа с архивами, почти наверняка понадобится именно она.
4. Нужна внимательность при массовой авторазметке
Auto Check работает безопасно, но не отменяет необходимость просмотра результата. Особенно когда в ход идут правила по датам, расположению или сложные исключения. Программа дает инструменты контроля, однако окончательное решение по удалению дубликатов все равно должно быть осознанным.
Сравнение с аналогами
На рынке утилит для поиска дублей у Fast Duplicate File Finder много конкурентов, но сравнивать его имеет смысл не со сферическим аналогом, а с конкретными программами, которые чаще всего рассматривают рядом: Duplicate Cleaner, dupeGuru, Auslogics Duplicate File Finder и Czkawka. У каждой из них есть своя сильная сторона, и именно на этом фоне легче понять, чем хорош продукт MindGems.
Duplicate Cleaner
Duplicate Cleaner силен за счет трех выделенных режимов — Regular Mode, Image Mode и Audio Mode, а также мощного Selection Assistant, который умеет выбирать файлы по группам, датам, папкам и другим критериям. У него есть и отдельная работа с duplicate folders, что делает его особенно интересным для пользователей, которым нужен широкий инструментарий в одном приложении.
На фоне Duplicate Cleaner Fast Duplicate File Finder выглядит более узко специализированным, но и более прямолинейным в повседневной работе с обычными файлами. У MindGems очень сильны режимы 100% Equal Files, Similar Files, Similar File Names, а также сценарий source/target через Exclude from self-scan и Exclude from auto-check. Если задача — именно поиск дубликатов файлов, сравнение папок и аккуратная очистка документов, архивов и бинарных файлов, Fast Duplicate File Finder выглядит проще по логике и быстрее в освоении. Duplicate Cleaner выигрывает в мультирежимности, особенно когда рядом нужны изображения и аудио. MindGems выигрывает в четкой файловой специализации и удобной схеме сравнения каталогов.
dupeGuru
dupeGuru — известный open-source инструмент с кроссплатформенной природой. Его сильные стороны — Windows, macOS и Linux, портативность, а также идея трех режимов: стандартного, музыкального и графического. У него есть fuzzy matching, и для пользователей, которым нужен бесплатный и легкий duplicate finder на нескольких платформах, это очень привлекательный вариант.
Fast Duplicate File Finder на фоне dupeGuru производит впечатление более офисного и более дисциплинированного инструмента под Windows. У него лучше проработан блок отбора действий после сканирования: Auto Check, Quick Check, исключения по папкам, сравнение source и target, сохранение структуры каталогов при переносе, проекты и экспорт. dupeGuru хорош там, где важна кроссплатформенность и базовый fuzzy-поиск, а Fast Duplicate File Finder — там, где нужен плотный контроль над разметкой результатов и более практичная логика очистки рабочих архивов.
Auslogics Duplicate File Finder
Auslogics Duplicate File Finder известен как более простой и дружелюбный для новичка вариант. Он умеет искать дубликаты на локальных и внешних дисках, а также допускает поиск без учета имен файлов через опцию Ignore file names. Для быстрого бытового прохода по диску это удобная схема, особенно когда нужен максимально понятный интерфейс.
Но по глубине сценариев Fast Duplicate File Finder заметно сильнее. У него есть отдельные режимы Similar Files и Similar File Names, полноценная фильтрация, автопометка по множеству критериев, расширенные исключения и сценарии сравнения папок. Auslogics удобен как стартовый инструмент почистить дубликаты без лишних настроек. Fast Duplicate File Finder выигрывает в точности и в количестве реальных рабочих механизмов, которые нужны при регулярной ревизии архивов и многокаталожных хранилищ.
Czkawka
Czkawka — это уже не узкая duplicate file finder программа, а более широкий cleanup-комбайн. Она умеет искать не только дубликаты файлов, но и пустые папки, временные файлы, похожие изображения, похожие видео и другие типы лишних данных. В части дубликатов Czkawka использует сравнение по имени, размеру и хешу, а также предлагает отдельные инструменты для медиа.
На фоне Czkawka продукт MindGems выглядит менее универсальным, но более специализированным именно как программа для поиска дубликатов файлов Windows. Fast Duplicate File Finder дает более детальный контроль над группами, разметкой, исключениями, compare folders и дальнейшими действиями над файлами. Czkawka хороша как универсальный чистильщик системы и медиаархива. Fast Duplicate File Finder лучше там, где нужен точный, предсказуемый и удобный workflow именно вокруг duplicate files, similar files и similar file names.
В сухом остатке сравнение выглядит так: Duplicate Cleaner шире по мультимедийным режимам, dupeGuru сильнее в кроссплатформенности и открытости, Auslogics проще для новичков, Czkawka универсальнее как cleanup-suite, а Fast Duplicate File Finder — один из самых удобных именно для детальной файловой ревизии на Windows, где важно не только найти повторы, но и грамотно решить, что с ними делать дальше.
Кому программа подойдет лучше всего
Fast Duplicate File Finder особенно хорошо подходит тем, кто регулярно работает с большими папками документов, архивами, экспортами, сетевыми каталогами, резервными копиями и переносами между дисками. Для такого пользователя важны не только поиск одинаковых файлов на компьютере, но и фильтрация, сравнение папок, автоматическая пометка и безопасная последующая обработка. Именно здесь программа показывает себя с лучшей стороны.
Домашнему пользователю программа тоже подойдет, если задача не сводится к одному разовому удалению пары лишних MP4 или JPG. Когда в системе годами копились скачанные архивы, дубликаты PDF, повторные установщики, копии документов и резервные каталоги, Fast Duplicate File Finder оказывается очень практичным. Он не требует долгого обучения, но при этом дает достаточно настроек, чтобы не действовать вслепую.
Меньше всего программа нужна тем, кто ищет именно визуально похожие фотографии или похожую музыку. Для этого существуют отдельные специализированные продукты, а режим Similar Files в Fast Duplicate File Finder рассчитан в первую очередь на документы, архивы и бинарные файлы. То есть программа сильнее в файловой логике, чем в мультимедийной похожести.
Итог
MindGems Fast Duplicate File Finder — это сильная, детально продуманная программа для поиска дубликатов и похожих файлов, которая выигрывает не за счет яркой оболочки, а за счет правильной организации процесса. Она умеет находить точные дубликаты по содержимому, искать похожие документы и бинарные файлы, сравнивать похожие имена, фильтровать выборку до запуска сканирования, быстро отмечать лишние копии, безопасно удалять или переносить их и работать по схеме source/target при сравнении папок.
Главное достоинство программы — не одна конкретная функция, а цельный workflow. Add Folder → Method → Filter → Start Scan → Auto Check / Quick Check → Perform. Именно из-за этой связности Fast Duplicate File Finder ощущается не как очередной cleaner, а как полноценный инструмент для ревизии файловых хранилищ. Для Windows-пользователя, которому нужен точный duplicate finder с серьезным контролем над результатом, это очень удачный выбор.
Если оценивать программу по тому, насколько уверенно она справляется с реальными задачами — поиск дублей документов, сравнение архивов, разбор резервных копий, поиск файлов с одинаковыми именами в разных папках, перенос лишних копий в карантинный каталог, — Fast Duplicate File Finder оставляет впечатление зрелого и практичного инструмента. Он не пытается понравиться красивыми обещаниями. Он просто дает точные режимы поиска, хорошие фильтры и очень сильный блок работы с результатами. А для программы этого класса именно это и важно.