
Similarity byGAR Sofware — это программа для поиска похожих и одинаковых музыкальных файлов, очистки аудиоколлекции от дублей, проверки качества треков и дополнительного поиска похожих изображений. Ее главная специализация — не обычное сравнение файлов по имени, размеру или контрольной сумме, а анализ музыки по содержимому. Поэтому Similarity полезна там, где стандартные duplicate finder-инструменты быстро упираются в проблему: одна и та же песня может лежать в MP3 и FLAC, иметь разные теги, отличаться битрейтом, называться по-разному, быть скачанной из разных источников или находиться в нескольких папках одновременно.
Программа работает с аудиоколлекциями, где беспорядок появляется постепенно: пользователь годами переносит музыку между дисками, копирует папки с ноутбука на ПК, добавляет рипы CD, скачивает сборники, сохраняет отдельные треки, импортирует старые архивы. В результате в библиотеке появляются одинаковые композиции с разными именами, копии в разных форматах, низкокачественные версии рядом с нормальными, альбомные и одиночные варианты, а также файлы с неполными или ошибочными тегами. Similarity помогает разобрать такую коллекцию не вслепую, а через сравнение по нескольким признакам: теги, содержимое, precise-алгоритм acoustic fingerprint, длительность, качество записи и дополнительные параметры анализа.
В отличие от универсальных утилит, которые просто ищут одинаковые файлы, Similarity ориентирована именно на музыкальную коллекцию. Она показывает группы похожих треков, выводит проценты совпадения по разным алгоритмам, позволяет прослушивать файлы, запускать анализ качества, сортировать результаты, отмечать лишние копии и удалять их через Recycle Bin. Это не чистильщик в один клик, а рабочий инструмент для тех, кто хочет сохранить лучшую версию композиции и убрать лишние дубли без риска потерять нужный файл.
Программа поддерживает распространенные музыкальные форматы, включая MP3, AAC, M4A, WMA, OGG, WAV, FLAC, APE, WV, MPC, OPUS, TTA и другие. Для тегов используются ID3v1, ID3v2, APEv2, WMA и Vorbis, поэтому Similarity умеет работать как с популярными MP3-файлами, так и с lossless-архивами. Дополнительно в ней есть встроенный tag editor, file name and tag converter, анализ спектра, sonogram, folder groups и автоматическая разметка файлов в Premium-режиме.
Скачать Similarity
- Оптимизация системы
- Очистка мусора
- Ускорение ПК
- Только медиафайлы
- Платные функции
- Нет очистки системы
Какие задачи можно решить в Similarity
Similarity нужна не только для удаления одинаковых MP3. Ее сильная сторона — комплексная работа с музыкальной библиотекой. Программа помогает найти похожие аудиофайлы, сравнить качество дублей, выбрать лучшую копию, исправить теги и аккуратно обработать результаты.
Основные задачи, которые реально выполняются в Similarity:
| Задача | Как это решается в программе |
|---|---|
| Найти одинаковые песни с разными именами | Сравнение по содержимому и acoustic fingerprint |
| Найти MP3 и FLAC-копии одной композиции | Сравнение звучания без привязки к расширению файла |
| Проверить треки с плохими тегами | Сравнение не ограничивается Artist, Title и Album |
| Выбрать лучшую копию из нескольких | Вкладка Analysis, Rating, Bitrate, Sample rate, Clipping, Max Freq. |
| Удалить или переместить лишние копии | Команды Mark/Unmark, Delete marked, Move |
| Проверить новую папку перед добавлением в архив | Folder groups: старая коллекция как group #1, новые файлы как group #2 |
| Ускорить обработку больших коллекций | Настройка алгоритмов, thresholds, precise algorithm, кеш |
| Найти похожие изображения | Вкладка Results: Images и алгоритмы сравнения изображений |
| Исправить метаданные | Встроенный Tag editor с полями Title, Artist, Album, Year, Track, Genre, Comment |
Similarity особенно полезна в музыкальных архивах, где есть несколько версий одного трека. Например, одна композиция может быть в папке Albums, в сборнике Best Of, в старом каталоге Downloads, в lossless-архиве и в отдельной папке для телефона. По имени файла такие варианты часто не совпадают. По тегам они тоже могут отличаться: где-то указан исполнитель, где-то нет, в одном файле название написано с ошибкой, в другом добавлен номер трека. Similarity решает эту проблему через анализ звука и показывает совпадения в виде групп.
Кому подойдет Similarity
Similarity стоит рассматривать в первую очередь тем, кто хранит музыку локально. Это программа для людей, у которых есть папка Music, внешний диск, домашний медиасервер, коллекция FLAC/MP3, архив старых альбомов или большой набор скачанных треков. Она не заменяет стриминговый сервис и не превращает компьютер в медиатеку сама по себе, зато хорошо выполняет практическую задачу: находит музыкальный мусор, дубли и подозрительные файлы.
Программа подойдет:
-
пользователям с большой коллекцией MP3, FLAC, WMA, OGG, AAC и WAV;
-
тем, кто часто переносил музыку между разными компьютерами и дисками;
-
владельцам архивов, где одна песня встречается в нескольких форматах;
-
тем, кто хочет найти одинаковые песни с разными названиями;
-
пользователям, которым важен не только факт дубля, но и качество оставляемого файла;
-
тем, кто хочет сравнивать старую коллекцию с новыми папками;
-
людям, которые чистят музыкальный архив вручную и хотят видеть понятные группы результатов;
-
пользователям, которым нужна программа для поиска дубликатов музыки, а не просто универсальный поиск одинаковых файлов.
Similarity менее уместна, когда нужно быстро удалить абсолютно одинаковые документы, архивы или копии фотографий по хешу. Для такой задачи хватает универсальных duplicate finder-программ. Сила Similarity раскрывается именно в аудио: сравнение по звуку, анализ качества, теги, рейтинг, спектр, длительность, группировка похожих композиций и ручной контроль перед удалением.
Интерфейс Similarity: как устроено главное окно
Главное окно Similarity сделано в стиле файлового менеджера. Верхняя часть содержит меню File, Scanning, Tools, Help, а также панель с крупными кнопками. Самая заметная кнопка на панели — Play с синим треугольником. Она запускает сканирование выбранных папок. Рядом находятся кнопки управления процессом, а также кнопка с инструментами для перехода к настройкам.
Рабочая область разделена на несколько зон:
-
слева находится дерево папок;
-
справа отображается содержимое выбранной папки;
-
внизу слева расположен блок Selected folders;
-
сверху рабочей области находятся вкладки Folders, Results: Audio, Results: Images, Analysis.
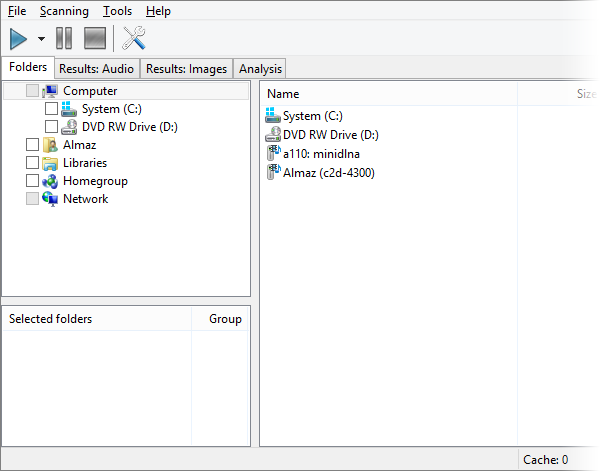
Вкладка Folders используется для выбора папок. Здесь пользователь отмечает нужные каталоги галочками. После выбора они появляются в списке Selected folders. Это удобно: перед запуском сканирования видно, какие именно папки попадут в обработку.
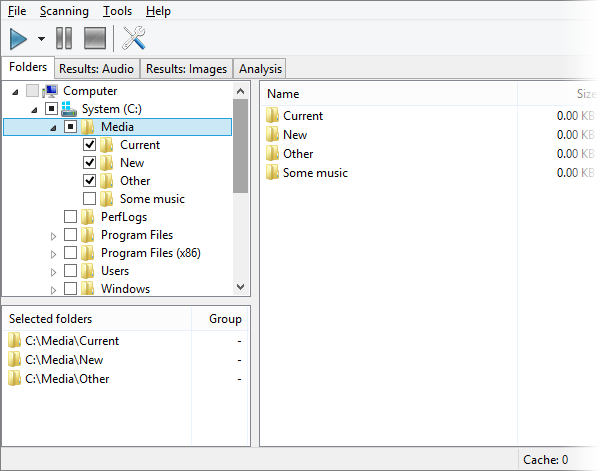
Вкладка Results: Audio показывает найденные аудиодубликаты и похожие треки. Название вкладки содержит число в скобках — количество групп дубликатов. Внутри таблицы отображаются пути к файлам, проценты совпадения, длительность и другие параметры. Группы визуально отделяются цветом и номером слева, поэтому пользователь видит не просто список файлов, а структуру совпадений.
Вкладка Results: Images работает по похожему принципу, но относится к изображениям. Это дополнительная функция Similarity: программа умеет искать похожие и одинаковые изображения, хотя основной акцент все равно сделан на аудио.
Вкладка Analysis предназначена для анализа качества музыкальных файлов. Здесь появляются колонки Rating, Sample rate, Size, Bitrate, Channels, Duration, Clipping, Silence, Mean(Abs.), Step, Max(abs.), Max Freq., Spectrum, Clicks. Эта вкладка особенно важна, когда в одной группе найдено несколько копий одной песни и нужно понять, какую оставить.
Как Similarity ищет музыкальные дубликаты
Similarity использует несколько подходов к сравнению аудиофайлов. Это важно, потому что музыкальные дубли редко бывают полностью одинаковыми на уровне байтов. Одна и та же композиция может быть перекодирована, иметь другой битрейт, другой контейнер, другую громкость, другую длину тишины в начале или конце, разные теги и разные имена файлов.
Сравнение по тегам
Сравнение по тегам работает с метаданными музыкального файла. Similarity анализирует информацию вроде исполнителя, названия, альбома и других тегов. Такой способ быстрый и полезный, если библиотека аккуратно оформлена: у треков заполнены Artist, Title, Album, Track, Year, Genre.
Проблема тегов в том, что они часто ошибаются. В одной копии может быть Queen, в другой Queen & David Bowie; название может быть написано с лишними пробелами, номером трека, пометкой (Remastered), (Live) или (Radio Edit). Иногда теги вообще отсутствуют. Поэтому Similarity не ограничивается тегами и предлагает сравнение по фактическому содержимому.
Сравнение по содержимому
Сравнение по содержимому анализирует аудиоданные, а не только текстовые поля. Это помогает находить композиции, которые звучат одинаково или почти одинаково, но имеют разные имена, теги, расширения и битрейты. Такой подход особенно важен для коллекций, где треки попадали из разных источников.
В результатах Similarity колонка % content показывает процент совпадения по содержимому. Высокое значение означает, что файлы похожи по аудиоданным. При этом пользователь все равно должен смотреть на контекст: концертная версия, ремастер, обрезанная версия, радио-версия и альбомная версия могут быть похожими, но не всегда являются дублями, которые нужно удалять.
Precise algorithm и acoustic fingerprint
В Premium-режиме доступен Precise-алгоритм. Он построен на acoustic fingerprint и дает более точное сравнение музыкальных файлов. В интерфейсе результаты этого алгоритма выводятся в колонке % precise. Для серьезной чистки больших аудиоколлекций это один из ключевых элементов Similarity: программа сравнивает звучание, а не только внешние признаки файла.
Когда % precise показывает 100%, а % content и % tags тоже дают высокие значения, это сильный признак дубля. Если совпадает только теговая часть, а содержимое слабое, удалять файл опасно. Если совпадает содержимое, но теги разные, нужно прослушать треки и проверить длительность. Если совпадение высокое, но длительность отличается, возможны разные версии: extended mix, short edit, live recording, remaster, intro/outro cut.
Сравнение изображений
Similarity также поддерживает поиск похожих изображений. Для этого предусмотрена вкладка Results: Images и два алгоритма сравнения изображений. Это полезное дополнение, если вместе с музыкальной коллекцией хранятся обложки альбомов, сканы буклетов, картинки из папок Covers, Artwork, Scans. Но в обзоре Similarity важно понимать приоритет: программа наиболее интересна именно как поиск дубликатов музыки и анализатор аудиокачества, а не как специализированный менеджер фотографий.
Пошаговая инструкция: как найти дубликаты музыки в Similarity
Рабочий процесс в Similarity строится вокруг четырех действий: выбрать папки, запустить сканирование, изучить результаты, отметить и удалить лишние файлы. Программа не заставляет проходить сложный мастер. Все делается из основного окна.
Шаг 1. Открыть вкладку Folders
После запуска Similarity открывается вкладка Folders. Слева отображается дерево: Computer, системный диск, съемные накопители, сетевые папки, библиотеки и другие доступные расположения. Пользователь раскрывает нужный диск и находит папку с музыкой.
Шаг 2. Отметить папки галочками
В дереве папок нужно поставить галочки напротив каталогов, которые будут сканироваться. Можно выбрать одну папку, несколько папок, весь музыкальный архив, внешний диск или сетевую папку. Выбранные каталоги появляются в нижнем блоке Selected folders.
Важно не выбирать сразу весь системный диск без необходимости. Для поиска дубликатов музыки лучше указывать конкретные папки: Music, Albums, FLAC, MP3, Downloads\Music, New, Other. Так результаты будут чище, а сканирование быстрее.
Шаг 3. Проверить Selected folders
Блок Selected folders показывает список выбранных путей. Если папка попала в список случайно, ее можно убрать через контекстное меню. Это простая, но важная проверка: Similarity будет сравнивать именно то, что находится в этом списке.
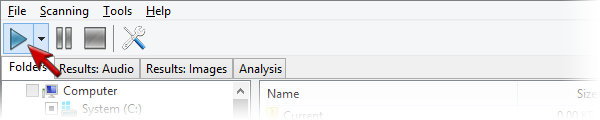
Шаг 4. Нажать кнопку Play
Для запуска сканирования используется кнопка Play на панели инструментов. Она выглядит как синий треугольник. После нажатия Similarity начинает анализировать выбранные папки.
Во время сканирования программа показывает прогресс и постепенно наполняет результаты. С найденными группами можно начинать работать еще до полного завершения процесса, но для аккуратной очистки лучше дождаться конца сканирования, особенно если коллекция большая.
Шаг 5. Перейти во вкладку Results: Audio
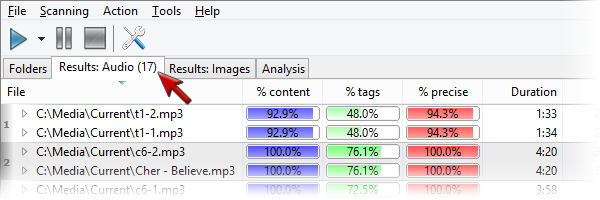
Когда Similarity находит совпадения, они появляются во вкладке Results: Audio. Число в скобках рядом с названием вкладки показывает количество групп. Например, Results: Audio (17) означает, что найдено 17 групп похожих аудиофайлов.
Каждая группа содержит файлы, которые Similarity считает похожими. Слева у группы есть номер, а строки внутри группы визуально отделены. В колонках отображаются проценты совпадения:
-
% content — совпадение по содержимому;
-
% tags — совпадение по тегам;
-
% precise — результат precise-алгоритма;
-
Duration — длительность трека.
Эти колонки дают быстрый способ понять, насколько уверенно программа считает файлы дублями.
Шаг 6. Отсортировать результаты
В таблице можно сортировать данные по колонкам. Это удобно для обработки больших списков: можно вывести наверх группы с максимальным % precise, найти файлы с низким рейтингом, посмотреть короткие версии, сравнить битрейт или размер.
Сортировка в Similarity работает не как обычная сортировка плоской таблицы. Программа сначала сортирует файлы внутри группы, а затем сами группы по первому файлу. Поэтому группировка дублей сохраняется, а результаты остаются удобными для анализа.
Шаг 7. Запустить Analyze all
Если нужно выбрать лучшую копию, в контекстном меню или в меню Action используется команда Analyze all. Similarity анализирует файлы из списка дублей и добавляет оценку качества. После анализа появляется колонка Rating, а подробные данные доступны во вкладке Analysis.
Шаг 8. Проверить спорные совпадения
Перед удалением стоит открыть группу, сравнить длительность, качество, формат, битрейт и теги. Если есть сомнения, файл лучше прослушать. В контекстном меню доступна команда Play, которая запускает файл в плеере по умолчанию. Для ручной проверки это важнее, чем кажется: Similarity может правильно найти похожие треки, но пользователь сам решает, является ли конкретная версия лишней.
Шаг 9. Отметить лишние файлы через Mark/Unmark
Чтобы не удалять файлы по одному, используется разметка. В контекстном меню есть команда Mark/Unmark, также она доступна через меню Action. Отмеченные файлы выделяются темно-красным цветом. После этого к ним можно применить массовую операцию.
Разметка удобна, когда в результатах много групп. Пользователь проходит по списку, отмечает лишние копии, а затем удаляет или перемещает все отмеченное одним действием.
Шаг 10. Удалить отмеченные через Delete marked
После проверки и разметки используется команда Delete marked. Она находится в контекстном меню и в меню Action. Файлы перемещаются в Recycle Bin, а строки исчезают из соответствующих групп в окне результатов.
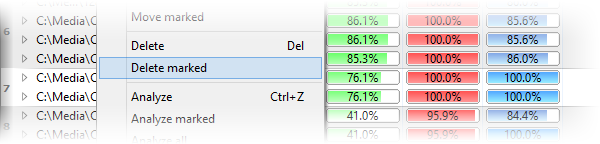
Удалять всю группу целиком нельзя: в группе должен остаться лучший файл. Правильная логика такая: в каждой группе выбрать одну копию, которую нужно оставить, а остальные отметить. Если группа содержит разные версии одной песни, например live и studio, лучше оставить обе.
Как читать результаты поиска в Results: Audio
Вкладка Results: Audio — главный рабочий экран Similarity. Именно здесь решается, какие файлы являются дублями, какие нужно оставить, а какие можно удалить.
Основные элементы таблицы:
| Элемент | Что означает |
|---|---|
| Номер группы слева | Объединяет похожие файлы в одну группу |
| File | Путь к аудиофайлу |
| % content | Степень совпадения по аудиосодержимому |
| % tags | Совпадение по музыкальным тегам |
| % precise | Результат precise-алгоритма |
| Duration | Длительность композиции |
| Цветные индикаторы | Визуальная оценка процента совпадения |
| Rating | Оценка качества после анализа |
Группа дубликатов — это набор файлов, которые Similarity считает связанными между собой. Внутри группы могут быть точные дубли, разные копии одного трека, версии с разными тегами, перекодированные файлы или похожие композиции. Именно поэтому программа показывает не только один общий результат, а несколько колонок сравнения.
Проценты нужно интерпретировать аккуратно:
-
100% precise — сильный признак фактического дубля;
-
высокий % content при низком % tags — часто означает одинаковую песню с плохими или разными тегами;
-
высокий % tags при низком % content — повод проверить вручную, потому что теги могут совпадать у разных версий;
-
разные значения Duration — признак обрезки, live-версии, extended mix или другого издания;
-
низкий Rating — повод рассмотреть файл как кандидата на удаление, если в группе есть более качественная копия.
Особенно внимательно нужно относиться к композициям с пометками Remaster, Live, Radio Edit, Extended, Instrumental, Acoustic, Demo, Mono, Stereo. Similarity может сгруппировать их как похожие, но с точки зрения коллекции это могут быть разные треки. Программа показывает совпадения, а решение остается за пользователем.
Анализ качества аудио во вкладке Analysis
Одна из самых сильных функций Similarity — анализ качества музыкальных файлов. Обычный поиск дублей отвечает на вопрос: Какие файлы похожи?. Similarity идет дальше и помогает ответить на другой вопрос: Какую копию лучше оставить?.
Вкладка Analysis выводит подробные параметры аудиофайлов. После команды Analyze all или запуска анализа по выбранным файлам программа рассчитывает рейтинг и технические показатели. Это особенно полезно, когда в группе есть, например, MP3 128 Kbit, MP3 320 Kbit и FLAC-копия одной композиции. Без анализа пользователь может ориентироваться только на размер и формат, а Similarity показывает больше признаков.
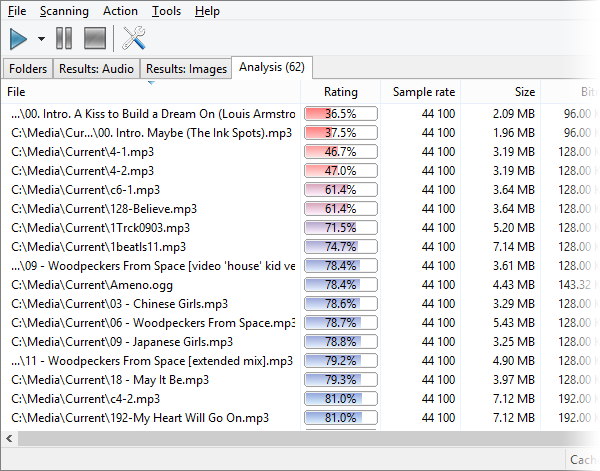
Rating
Rating — итоговая оценка качества файла. Чем выше рейтинг, тем предпочтительнее файл как кандидат на сохранение. Оценка строится на основе нескольких параметров: sample rate, bitrate, channels, clipping, mean amplitude, max frequency и других показателей.
Rating не нужно воспринимать как абсолютную музыкальную истину. Это техническая оценка файла, а не художественная оценка записи. Но при выборе между несколькими копиями одной песни рейтинг очень полезен. Если два файла действительно являются дублями, а один имеет заметно более высокий Rating, чаще всего именно его логично оставить.
Sample rate
Sample rate показывает частоту дискретизации. Для обычной CD-качества типично значение 44 100 Hz. Низкие значения, например 22 050 Hz, могут указывать на ограниченное качество источника или сильное упрощение аудиоданных. В Similarity этот параметр участвует в расчете рейтинга.
Bitrate
Bitrate показывает среднее количество бит в секунду. Для MP3 и других lossy-форматов это один из заметных признаков качества, но его нельзя использовать изолированно. MP3 320 Kbit не всегда лучше честного FLAC, а файл с высоким битрейтом может быть перекодирован из плохого источника. Similarity помогает не ограничиваться битрейтом, а дополнительно смотреть на Max Freq., Spectrum и другие признаки.
Channels
Channels показывает количество каналов: Mono или Stereo. Для большинства музыкальных коллекций stereo-версия предпочтительнее mono, если это не историческая запись, специальное издание или осознанный mono-master.
Duration
Duration важна при проверке дублей. Если два файла имеют почти одинаковое звучание, но разную длительность, нужно смотреть внимательнее. Разница в несколько секунд может быть тишиной в начале или конце, а может означать, что один файл обрезан. Большая разница часто говорит о разных версиях композиции.
Clipping
Clipping показывает искажения амплитуды. Высокие значения могут указывать на неудачный ремастеринг, неправильную конвертацию или плохой исходный файл. Для коллекции, где важен звук, этот параметр особенно ценен: внешне файл может выглядеть нормальным, иметь высокий битрейт и правильные теги, но при этом страдать от клиппинга.
Silence
Silence показывает количество тихих блоков в начале и конце композиции. Этот параметр не всегда говорит о плохом качестве. Иногда тишина является частью трека или альбома. Но при сравнении дублей он помогает понять, почему Duration отличается.
Mean(Abs.) и Max(abs.)
Mean(Abs.) связан со средней амплитудой, а Max(abs.) показывает максимальную абсолютную амплитуду. Эти параметры помогают оценить использование динамического диапазона. Сильно проблемные значения могут указывать на потерю качества, перекодирование или неправильную нормализацию.
Max Freq.
Max Freq. показывает максимальную частоту по алгоритму Similarity. Этот показатель полезен для обнаружения файлов, которые были искусственно перекодированы в высокий битрейт. Например, файл может иметь 320 Kbit, но по спектру быть похожим на исходник низкого качества с обрезанными высокими частотами. В таком случае большой битрейт не означает реальное качество.
Spectrum
Spectrum — мини-спектрограмма в таблице анализа. Она помогает визуально оценивать частотный диапазон. В Premium-режиме доступны подробные спектральные графики и микроспектрограммы, которые позволяют быстрее находить низкокачественные записи и перекодированные файлы.
Spectrum Analysis и Sonogram Analysis
В Similarity есть инструменты для более глубокого анализа аудио: Spectrum Analysis и Sonogram Analysis. Они особенно полезны, когда нужно проверить файл, который выглядит подозрительно: высокий битрейт, но низкая максимальная частота; хороший размер, но слабый Rating; разные копии одной песни с непонятной разницей в звучании.
Spectrum Analysis показывает частотный график. В окне анализа есть параметры FFT size, FFT overlap и кнопка Rebuild. График строится отдельно для каналов, а значения отображаются в децибелах. Синий график показывает среднее, красный — максимум. Такой вид помогает увидеть резкий спад высоких частот, характерный для файлов, перекодированных из источника более низкого качества.
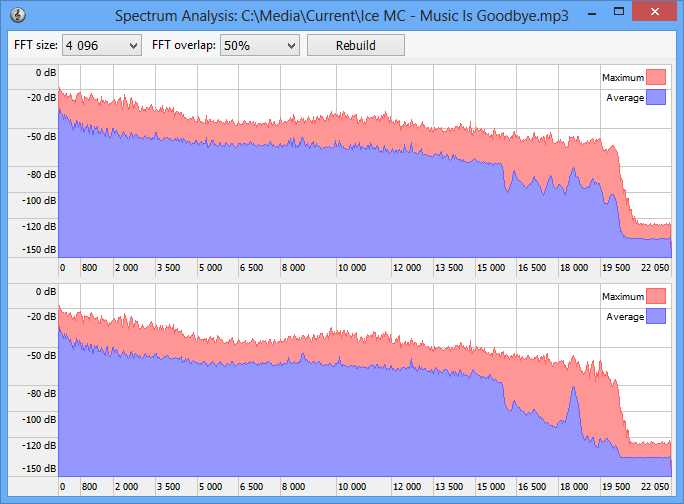
Практический пример: в группе есть два файла одной песни. Первый — MP3 320 Kbit, второй — FLAC. По тегам они совпадают, Duration почти одинаковая. Но в Spectrum Analysis у MP3 виден резкий обрыв частот, а у FLAC спектр выглядит полнее. В таком случае Similarity помогает не попасться на красивый битрейт и оставить файл с реальным качеством.
Sonogram Analysis полезна для визуального анализа распределения частот во времени. Она показывает, как меняется спектр по ходу композиции. В обычной чистке дублей эта функция нужна не каждому пользователю, но для аудиофилов, архивистов и тех, кто собирает качественную локальную коллекцию, она дает дополнительный уровень проверки.
Tag Editor: редактирование тегов внутри Similarity
Similarity содержит встроенный Tag editor. Он открывается через команду Edit в контекстном меню результатов. Редактор создан для быстрой правки тегов в группе дублей, когда пользователь уже видит похожие файлы и хочет привести метаданные к нормальному виду.
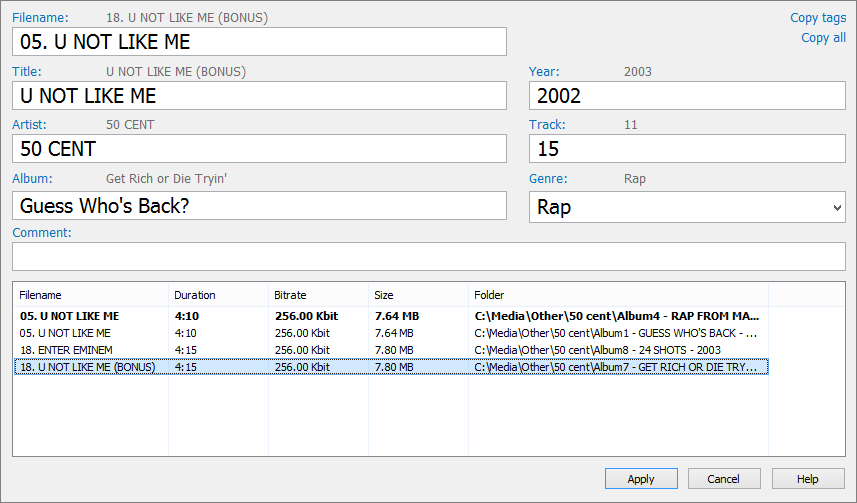
В верхней части окна Tag editor расположены поля:
-
Filename;
-
Title;
-
Artist;
-
Album;
-
Year;
-
Track;
-
Genre;
-
Comment.
Ниже находится список дублей. Файл, который редактируется, выделяется жирным шрифтом. В списке видны длительность, битрейт, размер и папка. Это удобно: можно сравнить несколько копий, выбрать правильные данные и быстро перенести их в нужные поля.
В Tag editor есть ссылки Copy tags и Copy all. Copy tags копирует только теги, а Copy all копирует теги и имя файла. Также рядом с полями отображаются подсказки из других файлов группы: можно перенести название альбома, исполнителя или заголовок, если в одной копии теги заполнены лучше, чем в другой.
Контекстное меню внутри Tag editor содержит команды:
| Команда | Назначение |
|---|---|
| Play | Воспроизвести файл в плеере по умолчанию |
| Browse… | Открыть папку файла в Explorer |
| Ignore | Исключить пару из дальнейшего отображения как дубль |
| Delete | Удалить файл в Recycle Bin |
После редактирования используется кнопка Apply. Если изменения не нужны, нажимается Cancel. Такой редактор не заменяет специализированные программы вроде MusicBrainz Picard или Mp3tag для массового наведения порядка в тегах, но внутри Similarity он полезен: можно исправить данные именно у тех файлов, которые попали в группы дублей.
Automark files: автоматическая разметка дублей
Automark files — одна из самых практичных функций Similarity для больших результатов. Она не удаляет файлы сама, а только отмечает кандидатов на удаление или перемещение. После разметки пользователь сам решает, что делать с отмеченными файлами: удалить, переместить, снять отметки или проверить вручную.
Окно Automatically mark files содержит три вкладки приоритетов:
-
General;
-
Folders;
-
File formats.
Во вкладке General задается порядок критериев. В списке доступны:
-
Rating;
-
Bitrate;
-
Size;
-
Tags;
-
Format;
-
Group;
-
Folder;
-
Duration.
Логика простая: Similarity смотрит на верхний критерий, затем на следующий, затем на следующий. Если сверху стоит Rating, файлы с более низким рейтингом будут рассматриваться как худшие кандидаты. Если важнее сохранить FLAC, чем MP3, используется приоритет форматов. Если важнее оставить файлы из основной папки, настраивается приоритет папок.
В нижней части окна находятся Thresholds:
-
Tags;
-
Content;
-
Precise.
Пороговые значения работают как фильтр. Например, можно указать, что автоматическая разметка применяется только к парам, где Content выше 90%, а Precise выше 80%. Это снижает риск отметить похожие, но не одинаковые композиции. Thresholds работают по принципу AND: файл попадает в обработку только при выполнении всех выбранных условий.
Внизу окна находятся кнопки:
-
Mark — применить разметку;
-
Cancel — закрыть окно без изменений;
-
Help — открыть справку.
Правильный сценарий использования Automark files:
-
Сначала выполнить поиск дублей.
-
Запустить Analyze all, если в приоритетах используется Rating.
-
Открыть Automark files.
-
Настроить приоритеты.
-
Установить строгие thresholds.
-
Нажать Mark.
-
Просмотреть отмеченные файлы.
-
Только после проверки использовать Delete marked или Move marked.
Automark особенно полезен, когда в результатах сотни групп. Но использовать его без проверки не стоит. Музыкальные коллекции часто содержат разные версии одного трека, и автоматическая логика не всегда понимает, что для пользователя live-версия, extended mix или remaster важны отдельно.
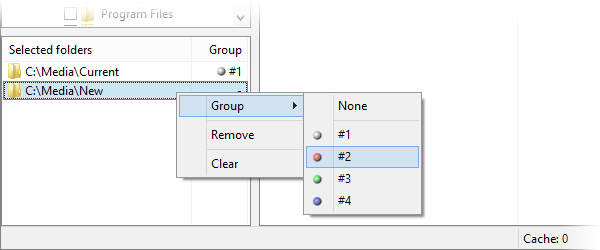
Folder groups: сравнение старой коллекции с новыми файлами
Folder groups — функция для сравнения разных наборов папок между собой. Она нужна, когда пользователь не хочет искать дубли внутри всей коллекции, а хочет проверить новые файлы относительно уже разобранного архива.
Типичный сценарий:
-
есть основная коллекция
C:\Music\Collection; -
есть новая папка
C:\Music\New; -
старую коллекцию трогать нельзя;
-
нужно понять, какие новые файлы уже есть в архиве.
В Similarity для этого выбираются обе папки, затем в списке Selected folders через контекстное меню назначаются группы. Основная коллекция получает group #1, новая папка — group #2. После этого файлы внутри одной группы не сравниваются между собой, а сравниваются с файлами из другой группы.
Такой подход сильно экономит время и делает результаты чище. Если задача — проверить новые треки перед добавлением в архив, не нужно получать дубли внутри старой коллекции. Достаточно увидеть пересечения между старым набором и новым.
Folder groups также помогают ускорять сканирование. Чем меньше лишних сравнений выполняет программа, тем быстрее она работает и тем проще потом разбирать результаты. Для больших коллекций это один из самых полезных инструментов Similarity.
Options: настройка алгоритмов и порогов
В окне Options настраиваются методы сравнения и пороговые значения. Для музыкальной коллекции особенно важна вкладка General, где расположены блоки Audio comparison methods, Duration check, Image comparison methods и Caches.
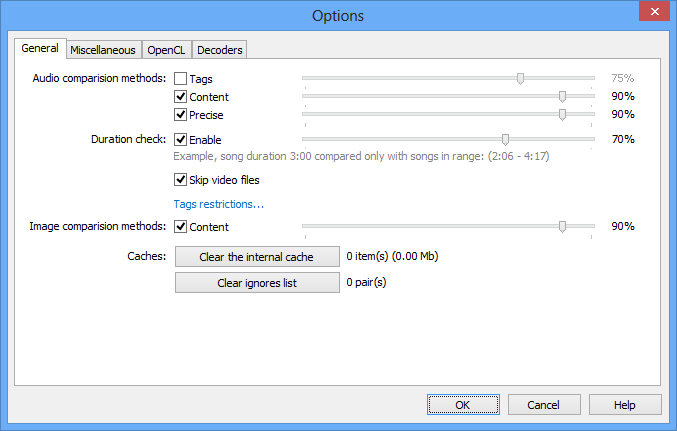
В блоке Audio comparison methods находятся основные флажки:
-
Tags;
-
Content;
-
Precise.
Рядом с ними расположены ползунки порогов. Чем выше порог, тем строже Similarity относится к совпадениям. Для небольшой коллекции можно использовать более мягкие настройки, чтобы найти больше потенциальных дублей. Для большой коллекции лучше повышать thresholds, иначе появится много ложных групп.
Duration check помогает учитывать длительность композиции. Это важно, потому что похожие треки с сильно разной длительностью часто не являются настоящими дублями. В интерфейсе также есть флажок Skip video files, который позволяет не тратить время на видео при аудиосканировании.
В блоке Image comparison methods включается сравнение изображений по содержимому. Это отдельная часть программы, полезная для поиска похожих обложек и графических файлов.
В блоке Caches есть кнопки:
-
Clear the internal cache;
-
Clear ignores list.
Кеш ускоряет повторное сканирование, потому что Similarity не приходится заново пересчитывать часть данных для уже обработанных файлов. Список игнорирования используется, когда пользователь исключает определенные пары из результатов.
Работа с большими музыкальными коллекциями
Similarity можно использовать не только для папки из нескольких сотен песен, но и для больших архивов. Однако с крупными коллекциями нужно работать аккуратно. Чем больше файлов, тем выше нагрузка на память, тем больше возможных пар сравнения и тем сложнее потом разбирать результаты.
Для коллекций на десятки тысяч файлов лучше придерживаться нескольких правил.
Не сканировать лишнее
Не стоит выбирать весь диск, если музыка лежит в двух конкретных папках. Чем точнее задана область сканирования, тем быстрее Similarity завершит работу и тем меньше будет мусорных результатов.
Отключать сравнение по тегам при плохих метаданных
Если теги заполнены плохо, сравнение по Tags может создавать много ложных совпадений. В больших архивах это особенно заметно: одинаковые названия альбомов, пустые поля, шаблонные значения и ошибки приводят к росту групп. В таких случаях лучше отключить Tags и опираться на Content и Precise.
Повышать пороги совпадения
Для большой коллекции лучше использовать строгие thresholds: например, 85–95% для precise-сравнения и высокие значения для content-сравнения. Это уменьшает количество спорных результатов и оставляет более уверенные совпадения.
Использовать folder groups
Когда нужно сравнить старую коллекцию с новыми файлами, folder groups дают более чистый результат. Similarity не сравнивает файлы внутри одной группы, а проверяет пересечения между группами. Это особенно удобно при регулярном добавлении новых треков.
Сначала искать очевидные дубли
Для огромного архива разумно двигаться по этапам:
-
Сначала включить строгие пороги и найти почти точные совпадения.
-
Удалить очевидные дубли.
-
Затем снизить пороги и проверить более спорные группы.
-
Отдельно разобрать файлы с плохим Rating.
-
После этого проверять изображения и обложки, если нужно.
Такой подход лучше, чем сразу запускать максимально широкий поиск и получать огромную таблицу, где сложно отличить настоящие дубли от похожих песен.
Free и Premium: что дает платная функциональность
Базовые функции Similarity доступны бесплатно: поиск дублей, удаление и перемещение файлов, редактирование тегов, массовые операции и базовая работа с результатами. Premium-режим добавляет функции, которые особенно важны для больших коллекций и более точного анализа.
| Возможность | Free | Premium |
|---|---|---|
| Поиск аудиодубликатов | Да | Да |
| Сравнение по тегам | Да | Да |
| Сравнение по содержимому | Да | Да |
| Precise algorithm | Нет | Да |
| Колонка % precise | Нет | Да |
| Анализ качества файлов | Да | Да |
| Подробный Spectrum Analysis | Нет | Да |
| Sonogram Analysis | Нет | Да |
| Automark files | Ограниченно/недоступно для полного сценария | Да |
| Folder groups | Нет | Да |
| Сохранение и восстановление результатов | Нет | Да |
| Автоматическое сохранение состояния сканирования | Нет | Да |
| OpenCL acceleration | Нет | Да |
| Расширенные возможности JavaScript API | Нет | Да |
Для небольшой музыкальной папки бесплатной функциональности может быть достаточно. Можно выбрать папку, запустить поиск, посмотреть результаты, вручную отметить лишние файлы и удалить их. Для большой коллекции Premium заметно удобнее: precise algorithm повышает качество сравнения, Automark files ускоряет обработку, folder groups позволяют сравнивать наборы папок, а сохранение состояния помогает не терять прогресс при длительной работе.
Безопасность удаления: как не потерять нужные треки
Similarity дает мощные инструменты для удаления дублей, но музыкальная коллекция требует осторожности. Одинаковые на первый взгляд треки не всегда являются лишними копиями. В архиве могут быть разные издания, концертные версии, ремастеры, радио-версии, инструментальные версии, демо, треки с бонусных дисков.
Безопасный порядок работы:
-
Не удалять файлы сразу после сканирования.
-
Сначала смотреть группу целиком.
-
Проверять % content, % tags, % precise.
-
Сравнивать Duration.
-
Запускать Analyze all для оценки качества.
-
Слушать спорные пары через Play.
-
Отмечать лишнее через Mark/Unmark.
-
Удалять только отмеченные файлы через Delete marked.
-
Проверять Recycle Bin перед окончательной очисткой.
Особенно опасны группы, где совпадение высокое, но длительность отличается. Это может быть одна и та же песня с обрезанной тишиной, а может быть extended mix или live-версия. Если пользователь собирает полную дискографию, такие варианты лучше не удалять автоматически.
Для папок с новой музыкой безопаснее использовать folder groups: старая коллекция остается основной, а новая папка проверяется как источник потенциальных дублей. В этом случае удалять или перемещать можно только файлы из новой папки, не трогая уже разобранный архив.
Практические сценарии использования Similarity
Очистить папку Music от дублей
Самый простой сценарий — выбрать основную папку с музыкой, нажать Play, открыть Results: Audio и разобрать группы. Для небольшой коллекции можно оставить настройки по умолчанию. После сканирования стоит запустить Analyze all, чтобы получить Rating и сравнить качество копий.
Пример логики:
-
если два файла имеют одинаковый % precise и одинаковую длительность, оставить файл с лучшим Rating;
-
если Rating близкий, оставить файл с лучшими тегами;
-
если один файл лежит в правильно организованной папке альбома, а второй в
Downloads, оставить альбомную копию; -
если один файл FLAC, а другой MP3, оставить FLAC, если это действительно та же композиция и качество подтверждается анализом.
Проверить новые треки перед добавлением в архив
Для этого используется folder groups. Основная коллекция получает группу #1, новая папка — #2. Similarity сравнивает файлы между группами и показывает, какие новые треки уже есть в архиве. После проверки можно удалить или переместить дубли из новой папки.
Такой сценарий полезен после скачивания сборников, покупки цифровых альбомов, восстановления старого диска или импорта музыки с телефона.
Найти одну песню в разных форматах
Если в библиотеке есть одна и та же композиция в MP3, FLAC, WMA или OGG, Similarity может сгруппировать их по содержимому и acoustic fingerprint. Это удобно, когда нужно оставить lossless-версию, а сжатую копию удалить или перенести в отдельную папку для мобильного устройства.
Убрать низкокачественные версии
Для этой задачи важна вкладка Analysis. Нужно выбрать папки, запустить анализ, отсортировать файлы по Rating, Bitrate, Sample rate, Clipping или Max Freq.. Затем можно найти файлы с подозрительно низким качеством и проверить, есть ли в коллекции более качественная копия.
Разобрать старый архив Downloads
Папка Downloads часто содержит хаотичный набор треков: неполные альбомы, копии из мессенджеров, файлы с неправильными именами. Similarity позволяет сравнить эту папку с основной коллекцией и удалить то, что уже давно есть в нормальном архиве.
Найти похожие изображения и обложки
Если вместе с музыкой хранятся обложки, буклеты и сканы, можно использовать Results: Images. Similarity помогает найти одинаковые или похожие картинки, например повторяющиеся cover.jpg, folder.jpg, front.png, которые занимают место в разных папках.
Преимущества Similarity
Similarity выделяется тем, что воспринимает музыкальные файлы как музыку, а не просто как набор байтов. Для аудиоколлекции это принципиально: две копии одной песни почти никогда не совпадают полностью на уровне файла, если они получены из разных источников или перекодированы в разные форматы.
Главные плюсы программы:
| Преимущество | Почему это важно |
|---|---|
| Acoustic fingerprint | Помогает находить одинаковые песни с разными именами и тегами |
| Несколько алгоритмов сравнения | Можно комбинировать tags, content и precise |
| Анализ качества | Помогает выбрать лучший файл в группе |
| Rating | Упрощает сортировку и принятие решений |
| Spectrum и Sonogram | Позволяют выявлять перекодированные и низкокачественные файлы |
| Folder groups | Удобно сравнивать старую коллекцию с новыми папками |
| Automark files | Экономит время при большом количестве дублей |
| Tag editor | Позволяет исправлять метаданные прямо в процессе чистки |
| Поддержка многих аудиоформатов | Программа подходит для смешанных MP3/FLAC/WMA/OGG/AAC-архивов |
| Recycle Bin при удалении | Снижает риск необратимой потери файла |
В Similarity хорошо продумана логика ручного контроля. Программа не пытается агрессивно удалить все найденное, а показывает группы и дает инструменты для принятия решения. Это правильный подход для музыки: автоматическое удаление без проверки может уничтожить редкие версии, концертные записи или нужные ремастеры.
Еще одно преимущество — сочетание поиска дублей и анализа качества. Многие программы находят одинаковые файлы, но не помогают понять, какую копию оставить. Similarity показывает Rating, Bitrate, Sample rate, Clipping, Max Freq. и Spectrum. Благодаря этому очистка музыкальной коллекции становится более осмысленной.
Недостатки Similarity
Similarity — сильный инструмент, но у него есть особенности, которые нужно учитывать.
Первый минус — интерфейс выглядит утилитарно. Он понятный, но не современный: таблицы, вкладки, контекстные меню, старый стиль панели инструментов. Для опытного пользователя это скорее плюс, потому что все элементы видны сразу. Для новичка программа может выглядеть менее дружелюбно, чем современные приложения с пошаговым мастером.
Второй минус — важные функции находятся в Premium-режиме. Precise algorithm, Automark files, folder groups, Spectrum Analysis, Sonogram Analysis, сохранение результатов и OpenCL acceleration особенно полезны как раз в серьезных сценариях. Если коллекция небольшая, можно обойтись базовыми возможностями. Если архив большой, Premium становится намного более практичным вариантом.
Третий минус — результаты требуют понимания. Similarity находит похожие файлы, но не всегда может решить за пользователя, что является ненужным дублем. Например, studio version и live version могут быть похожи, но их нельзя считать одинаковыми. Поэтому программа требует аккуратности: нужно смотреть Duration, Rating, теги и иногда слушать файлы.
Четвертый минус — поиск изображений не является главным направлением программы. Он есть, но Similarity прежде всего воспринимается как duplicate music finder и аудиоанализатор. Для больших фотоархивов лучше использовать специализированные инструменты, а Similarity применять к изображениям как дополнительную функцию.
Сравнение с аналогами
Similarity логично сравнивать не с абстрактными программами для чистки компьютера, а с конкретными инструментами, которые тоже ищут дубликаты музыки, похожие файлы или универсальные дубли.
| Программа | Основная специализация | Сильные стороны | В чем Similarity интереснее |
|---|---|---|---|
| Similarity | Похожие аудиофайлы, музыкальные дубли, анализ качества | Acoustic fingerprint, Rating, Analysis, Spectrum, folder groups | Глубокий аудиоанализ и выбор лучшей копии |
| Duplicate Cleaner Pro | Универсальный поиск дублей, музыка, фото, видео | Audio Mode, поиск по тегам и аудиоданным, работа с разными типами файлов | Similarity лучше раскрывается именно в музыкальной коллекции |
| dupeGuru | Open-source duplicate finder для файлов, музыки и изображений | Fuzzy matching, кроссплатформенность, простота | Similarity дает больше аудиоспецифичных параметров качества |
| Audio Comparer | Поиск дублей музыки по звучанию | Сравнение по звуку, разные форматы, визуальные группы | Similarity дополнительно предлагает Analysis, Rating, Spectrum |
| Duplicate Audio Finder | Audio fingerprinting и удаление аудиодублей | Поиск независимо от формата, битрейта и громкости | Similarity сильнее как инструмент анализа качества коллекции |
| AllDup | Универсальный поиск дублей любых файлов | Много критериев, похожие картинки, похожая музыка | Similarity более специализирована для аудиоархивов |
Duplicate Cleaner Pro
Duplicate Cleaner Pro — более универсальная программа. Она умеет искать дубликаты документов, изображений, музыки, видео и других файлов. Для музыки в ней есть Audio Mode: поиск по аудиотегам и по похожему музыкальному содержимому. Это хороший вариант, если пользователю нужна одна программа для разных типов дублей.
Similarity выглядит более узким, но более музыкальным инструментом. В ней сильнее выражены функции анализа качества: Rating, Analysis, Spectrum Analysis, Sonogram Analysis, Max Freq., Clipping. Если задача — не просто найти дубли, а привести в порядок именно аудиоколлекцию, Similarity дает более подходящую рабочую среду.
dupeGuru
dupeGuru — кроссплатформенный open-source инструмент для поиска дублей. Он умеет сравнивать имена и содержимое, использует fuzzy matching, имеет режимы для разных типов файлов, включая музыку и изображения. Его преимущество — простота, открытость и доступность на разных системах.
Similarity выигрывает в аудиодетализации. В dupeGuru удобно найти похожие файлы, но Similarity лучше подходит для выбора лучшей музыкальной копии. Она показывает профиль качества, анализирует частоты, клиппинг, битрейт, sample rate и дает инструменты вроде Automark files с приоритетами Rating, Bitrate, Format, Folder, Duration.
Audio Comparer
Audio Comparer также ориентирован на поиск дублей музыки по звучанию. Его идея близка к Similarity: программа анализирует фактическое аудио, а не только имя файла или теги, и может находить копии в разных форматах.
Разница в акцентах. Audio Comparer хорош как инструмент поиска похожих песен. Similarity, кроме поиска, дает более развитую систему оценки качества. Для пользователя, который хочет не просто удалить дубли, а понять, какой файл звучит технически лучше, Similarity выглядит функциональнее.
Duplicate Audio Finder
Duplicate Audio Finder делает акцент на audio fingerprinting: он сравнивает звучание и способен находить похожие аудиофайлы независимо от формата, размера, битрейта, частоты дискретизации и громкости. Также в нем есть операции удаления, перемещения и копирования, а также встроенный аудиоплеер.
Similarity сопоставима по идее поиска похожего аудио, но отличается набором аналитических инструментов. Ее вкладка Analysis, Rating, спектрограмма и sonogram делают программу удобной для тех, кто хочет чистить коллекцию с учетом качества, а не только похожести.
AllDup
AllDup — универсальный duplicate finder. Он ищет дубликаты по содержимому, свойствам файла и специальным признакам, включая похожие изображения и музыкальные треки. Это хороший выбор, когда нужно обработать весь диск: документы, архивы, фото, видео, музыку.
Similarity не пытается быть настолько универсальной. Ее сильная сторона — музыка. Если главная задача — убрать одинаковые файлы всех типов, AllDup может быть удобнее. Если задача — навести порядок в музыкальной коллекции, найти одинаковые песни с разными названиями и выбрать более качественную копию, Similarity подходит лучше.
Частые ошибки при работе с Similarity
Удаление только по названию группы
Нельзя считать, что вся группа в Results: Audio состоит из лишних файлов. В группе должен остаться хотя бы один файл, а иногда нужно оставить несколько версий. Similarity группирует похожие композиции, но пользователь должен решить, какие из них действительно дубли.
Доверие только тегам
Теги часто ошибаются. Если ориентироваться только на % tags, можно удалить разные версии композиции или пропустить одинаковые файлы с плохими метаданными. Для музыки надежнее смотреть % content, % precise, Duration и Analysis.
Игнорирование Duration
Разница в длительности — важный сигнал. Если один файл длится 3:31, а другой 4:19, это может быть не дубль, а другая версия. Такие файлы нужно слушать и проверять вручную.
Удаление без анализа качества
Если в группе есть несколько дублей, лучше сначала выполнить Analyze all. Без Rating и параметров Analysis можно случайно оставить низкокачественный файл и удалить лучший.
Слишком низкие thresholds
Низкие пороги совпадения дают больше результатов, но среди них больше спорных групп. Для большой коллекции лучше начинать со строгих значений и постепенно расширять поиск.
Автоматическая разметка без проверки
Automark files экономит время, но не заменяет контроль. После нажатия Mark нужно просмотреть отмеченные файлы. Только затем можно использовать Delete marked.
Сканирование всего диска
Если выбрать весь диск, Similarity будет обрабатывать лишние папки. Это дольше и грязнее по результатам. Лучше выбирать конкретные музыкальные каталоги.
Советы по настройке Similarity
Для небольшой коллекции можно использовать стандартный подход: включить Tags, Content, при необходимости Precise, выбрать папку и запустить Play. После сканирования — открыть Results: Audio, запустить Analyze all, отсортировать по Rating и вручную отметить лишние файлы.
Для коллекции с плохими тегами лучше отключить Tags. Если теги неполные, одинаковые или ошибочные, они скорее мешают. В таком случае надежнее сравнивать аудиосодержимое.
Для больших архивов стоит:
-
использовать строгие пороги;
-
включать Precise;
-
отключать слабые или лишние алгоритмы, если они создают много ложных групп;
-
использовать folder groups для сравнения старого и нового набора;
-
не очищать кеш без необходимости;
-
сначала удалять очевидные дубли;
-
спорные группы оставлять на ручную проверку.
Для выбора лучшей копии в группе полезный порядок приоритетов такой:
-
Убедиться, что это действительно одна и та же композиция.
-
Сравнить Duration.
-
Запустить Analyze all.
-
Смотреть Rating.
-
Проверить Bitrate и Sample rate.
-
Посмотреть Clipping и Max Freq..
-
При сомнениях открыть Spectrum Analysis.
-
Сравнить теги и папки.
-
Оставить файл с лучшим качеством и правильным расположением.
Итоговая оценка Similarity
Similarity by GAR Software — специализированная программа для тех, кто хочет привести в порядок музыкальную коллекцию и не ограничиваться примитивным поиском одинаковых файлов. Она хорошо подходит для поиска дубликатов MP3, FLAC, WMA, OGG, AAC и других аудиоформатов, умеет сравнивать треки по тегам, содержимому и acoustic fingerprint, показывает группы совпадений и помогает выбрать лучшую копию через анализ качества.
Главное достоинство Similarity — сочетание поиска похожих аудиофайлов и аудиоанализа. Программа не просто сообщает, что два файла похожи. Она дает Rating, Bitrate, Sample rate, Clipping, Max Freq., Spectrum и другие параметры, которые помогают понять, какой файл стоит оставить. Для большой музыкальной библиотеки это гораздо важнее, чем обычная кнопка удалить дубликаты.
Similarity особенно хороша в сценариях, где нужно:
-
найти одинаковые песни с разными названиями;
-
сравнить MP3 и FLAC-копии;
-
убрать низкокачественные версии;
-
проверить новые треки перед добавлением в архив;
-
разобрать старую папку Downloads;
-
сохранить лучшую копию в каждой группе;
-
работать с папками, группами и массовой разметкой.
Программа требует аккуратности и ручной проверки, но именно это делает ее надежной для музыкальных архивов. Для универсальной чистки всех типов файлов можно выбрать AllDup, Duplicate Cleaner Pro или dupeGuru. Для серьезной работы с аудиодубликатами Similarity остается сильным вариантом благодаря precise-сравнению, анализу качества, спектру, tag editor, folder groups и Automark files.
FAQ
Similarity бесплатная?
Базовая функциональность Similarity доступна бесплатно и не ограничена по времени. В бесплатном режиме можно искать дубликаты, удалять или перемещать найденные файлы, редактировать теги и выполнять массовые операции. Расширенные функции, включая precise algorithm, Automark files, folder groups, Spectrum Analysis, Sonogram Analysis, сохранение результатов и OpenCL acceleration, относятся к Premium-режиму.
Можно ли найти одинаковые MP3 с разными названиями?
Да. Similarity не ограничивается именем файла. Программа сравнивает музыкальные теги и аудиосодержимое, а в Premium-режиме использует precise algorithm на базе acoustic fingerprint. Поэтому она подходит для поиска одинаковых песен с разными названиями, разными тегами и разными битрейтами.
Поддерживает ли Similarity FLAC?
Да. Similarity работает с FLAC и другими популярными аудиоформатами: MP3, AAC, M4A, WMA, OGG, WAV, APE, WV, MPC, OPUS, TTA и другими. Также поддерживаются разные типы тегов, включая ID3v1, ID3v2, APEv2, WMA и Vorbis.
Можно ли удалить файлы автоматически?
Similarity позволяет автоматически отмечать файлы через Automark files, но сама логика безопаснее: сначала программа помечает кандидатов, а пользователь затем применяет действие. Для удаления используется Delete marked. Это правильный подход, потому что музыкальные дубли часто требуют ручной проверки.
Есть ли анализ качества аудио?
Да. Во вкладке Analysis Similarity показывает Rating, Sample rate, Bitrate, Channels, Duration, Clipping, Silence, Mean(Abs.), Step, Max(abs.), Max Freq., Spectrum, Clicks. Эти параметры помогают выбрать лучшую копию композиции и найти низкокачественные файлы.
Подходит ли Similarity для изображений?
Да, в Similarity есть поиск похожих изображений и вкладка Results: Images. Но основная сила программы — работа с аудио: поиск музыкальных дублей, acoustic fingerprint, анализ качества, Rating, Spectrum и Tag editor.
Чем Similarity отличается от обычного duplicate finder?
Обычный duplicate finder часто ищет файлы по имени, размеру, дате или хешу. Similarity сравнивает музыку по тегам и звучанию, показывает проценты совпадения, группирует похожие композиции, анализирует качество и помогает выбрать лучшую копию. Поэтому она лучше подходит для музыкальных коллекций, где один и тот же трек может существовать в разных форматах и с разными метаданными.
Стоит ли использовать Premium?
Premium нужен, если коллекция большая или требуется максимально точное сравнение. Самые полезные функции Premium — Precise algorithm, Automark files, folder groups, Spectrum Analysis, Sonogram Analysis, сохранение результатов и продолжение сканирования после перезапуска. Для маленькой папки с музыкой можно начать с бесплатных возможностей, но для серьезной чистки аудиоархива Premium заметно удобнее.