
PDF удобен для отправки договоров, инструкций, сканов, учебных материалов, отчётов и презентаций, но с копированием текста в нём часто возникают проблемы. Один файл спокойно даёт выделить абзац мышью и перенести его в Word, а другой выглядит как обычная страница с текстом, но курсор не цепляется ни за одну букву. В третьем документе копирование работает, но после вставки появляются иероглифы, пропадают пробелы, ломаются таблицы или каждая строка превращается в отдельный абзац.
Главная причина в устройстве PDF. Внутри файла находится не только видимая страница, но и набор объектов: текстовые блоки, изображения, шрифты, маски, слои, ограничения доступа, служебные данные. Когда текстовый слой сохранён правильно, выделение работает сразу. Когда вместо текста лежит скан или картинка, обычное копирование не помогает: документ нужно распознать через OCR. Когда автор запретил копирование, программа показывает страницу, но блокирует перенос текста в буфер обмена. Когда использован проблемный шрифт или сложная кодировка, символы выделяются, но вставляются неправильно.
Ниже — подробный разбор способов для Windows, macOS, онлайн-сервисов и телефона. В каждом варианте есть инструкция, список задач, плюсы, минусы и практический вывод.
Почему текст из PDF не копируется
Перед выбором программы важно понять, что именно мешает копированию. Одинаково выглядящие PDF-файлы внутри устроены по-разному.
PDF сделан из скана или фотографии
Самая частая ситуация: страница выглядит как текст, но на самом деле это изображение. Такое бывает после сканирования договора, паспорта, книги, инструкции, старой методички, накладной или архивного документа. На экране видны буквы, но программа видит только картинку.
Признаки сканированного PDF:
-
при попытке выделить слово выделяется вся страница или прямоугольная область;
-
курсор не превращается в текстовый указатель;
-
поиск по документу не находит слова, которые визуально есть на странице;
-
при увеличении масштаба буквы становятся пиксельными;
-
файл содержит тени, перекосы, шум бумаги, следы сканера.
Для такого документа нужно распознавание текста в PDF. OCR анализирует изображение, находит буквы, формирует текстовый слой и позволяет копировать фразы как из обычного документа.
В PDF есть запрет на копирование
Автор документа поставил ограничения на операции с файлом. Такой PDF открывается для просмотра, но не разрешает копирование, редактирование, печать или извлечение страниц. Это встречается в учебных материалах, коммерческих отчётах, закрытых документах, защищённых книгах, банковских файлах.
Признаки ограниченного PDF:
-
команда Copy неактивна;
-
сочетание Ctrl+C или Cmd+C не переносит текст;
-
в свойствах файла указано, что копирование содержимого запрещено;
-
программа просит пароль для изменения разрешений;
-
документ открывается только для чтения.
При наличии пароля владельца ограничение снимается штатными средствами редактора. Для чужих документов без разрешения корректный вариант — запросить исходник, получить пароль или попросить версию с разрешённым копированием.
Текст есть, но используется нестандартная кодировка
Некоторые PDF создаются из старых издательских систем, CAD-программ, специализированных бухгалтерских приложений или генераторов отчётов. Визуально буквы выглядят нормально, но при копировании превращаются в набор символов. Проблема связана со шрифтом, таблицей соответствия символов и внутренней кодировкой.
Типичные признаки:
-
вместо русских букв вставляются латинские символы;
-
появляются квадраты, вопросительные знаки, иероглифы;
-
буквы копируются в неправильном порядке;
-
поиск по документу работает плохо;
-
одно и то же слово на странице вставляется по-разному.
В такой ситуации помогает не обычное копирование, а OCR поверх страницы. Программа заново распознаёт видимые буквы и создаёт нормальный текстовый слой.
Текст разбит на колонки, таблицы или отдельные фрагменты
PDF сохраняет внешний вид страницы, а не логическую структуру документа. Внутри файла один абзац часто состоит из десятков мелких текстовых объектов. Поэтому после копирования появляются лишние переносы строк, столбцы смешиваются, таблица превращается в кашу, а заголовки вставляются в середину абзаца.
Это особенно заметно в:
-
журналах и буклетах с несколькими колонками;
-
прайс-листах;
-
таблицах;
-
научных статьях;
-
презентациях;
-
финансовых отчётах;
-
документах с подписями, печатями и сносками.
Для таблиц лучше использовать экспорт в Word или Excel, а для многостраничных материалов — распознавание с сохранением структуры.
Быстрая диагностика PDF перед копированием
Перед запуском тяжёлых редакторов сделайте короткую проверку. Она экономит время и помогает выбрать правильный способ.
| Что происходит | Тип PDF | Лучшее решение |
|---|---|---|
| Слово выделяется мышью | Текстовый PDF | Копирование в просмотрщике или редакторе |
| Выделяется вся страница | Скан или картинка | OCR |
| Ctrl+C не работает | Ограничение доступа | Проверка разрешений, пароль владельца |
| После вставки иероглифы | Проблемная кодировка | OCR с выбором языка |
| Таблица вставляется строками | Сложная структура | Экспорт в Word или Excel |
| Поиск не находит видимые слова | Нет текстового слоя | OCR |
| Текст копируется без пробелов | Ошибка шрифта или структуры | OCR или конвертация |
Простой порядок действий:
-
Откройте PDF.
-
Попробуйте выделить одно слово.
-
Нажмите Ctrl+F и найдите слово, которое точно есть на странице.
-
Откройте свойства документа и проверьте ограничения.
-
При отсутствии выделения запускайте OCR.
-
При проблемах с таблицами экспортируйте документ в Word или Excel.
-
После копирования очистите переносы строк и проверьте смысловые ошибки.
Как скопировать текст из PDF, если не получается на Windows
PDF Commander
PDF Commander удобно поставить первым способом для Windows: программа ориентирована на работу с PDF-документами на русском языке, открывает файлы, даёт редактировать страницы, работать с текстом, изображениями, подписями, защитой, конвертацией и подготовкой документа к дальнейшей обработке. Для задачи, где не копируется текст из PDF, важны два сценария: обычное выделение текста и перевод проблемного файла в редактируемый формат.
PDF Commander подходит для офисных PDF, договоров, актов, инструкций, учебных материалов, файлов с картинками и документов, которые нужно не только прочитать, но и подготовить к дальнейшей правке.
Что получится сделать
В PDF Commander удобно выполнять такие задачи:
-
открыть PDF и проверить, выделяется ли текст;
-
скопировать отдельный абзац или фрагмент;
-
отредактировать текстовый блок в PDF;
-
извлечь нужные страницы;
-
сохранить документ после изменений;
-
преобразовать PDF в другой формат для дальнейшей работы;
-
подготовить файл к распознаванию и ручной корректировке;
-
удалить лишние страницы перед обработкой;
-
добавить комментарии, подписи и изображения.
Как скопировать текст в PDF Commander
-
Откройте PDF Commander.
-
Нажмите Файл → Открыть PDF.
-
Выберите документ на компьютере.
-
Перейдите на страницу с нужным фрагментом.
-
Выберите инструмент для работы с текстом.
-
Проведите мышью по абзацу.
-
Нажмите Ctrl+C.
-
Откройте Word, Блокнот, Google Docs или другое приложение.
-
Нажмите Ctrl+V.
-
Проверьте пробелы, переносы строк и знаки препинания.
Когда текст выделяется нормально, этого достаточно. При вставке в Word лучше включить отображение непечатаемых символов: так быстрее видно лишние переносы строк и двойные пробелы.
Что делать, когда текст не выделяется
Когда PDF Commander открывает страницу, но буквы не выделяются, перед вами скан или картинка. В этом случае обычное копирование не работает, потому что внутри файла нет полноценного текстового слоя. Для такого документа используйте распознавание или конвертацию через инструмент, который создаёт редактируемый текст.
Практический порядок:
-
Откройте PDF.
-
Увеличьте масштаб страницы до 150–200%.
-
Убедитесь, что буквы не выделяются отдельно.
-
Удалите лишние страницы, которые не нужны для копирования.
-
Сохраните рабочую копию файла.
-
Выполните распознавание в OCR-программе или конвертируйте документ в Word.
-
Откройте результат и скопируйте уже распознанный текст.
Такой порядок особенно удобен, когда нужно извлечь не весь документ, а 2–3 страницы из большого файла.
Как улучшить результат перед распознаванием
Перед OCR подготовьте PDF:
-
поверните страницы в правильное положение;
-
удалите пустые страницы;
-
оставьте только нужный диапазон;
-
проверьте, что текст не закрыт печатями и рукописными пометками;
-
увеличьте читаемость скана, когда в документе есть серый фон;
-
сохраните копию, чтобы исходный файл остался без изменений.
OCR лучше работает с ровным, контрастным изображением. Перекошенные страницы, смазанные буквы и серый фон ухудшают распознавание русского текста в PDF.
Плюсы PDF Commander
-
Русскоязычный интерфейс.
-
Удобен для базовой правки PDF на Windows.
-
Подходит для подготовки страниц перед распознаванием.
-
Позволяет быстро открыть, просмотреть и изменить документ.
-
Полезен для договоров, инструкций, актов и учебных материалов.
-
Не перегружен сложными профессиональными панелями.
-
Хорошо подходит начинающим пользователям.
Минусы PDF Commander
-
Для сложного OCR больших архивов удобнее специализированные распознаватели.
-
При сложных таблицах после конвертации требуется ручная проверка.
-
Для защищённых файлов нужен пароль владельца.
-
Сканы плохого качества требуют предварительной обработки.
-
Для пакетного распознавания сотен страниц лучше использовать отдельный OCR-комплекс.
Когда выбирать PDF Commander
PDF Commander выбирают, когда нужно быстро открыть PDF на Windows, проверить возможность копирования, подготовить страницы, внести правки и получить рабочий документ без сложной настройки. Это хороший стартовый вариант для пользователя, который разбирается, почему PDF не даёт выделить текст, и хочет привести файл в нормальный вид.
ABBYY FineReader
ABBYY FineReader — один из самых сильных вариантов для сканированных PDF, архивных документов, книг, договоров, таблиц, многостраничных отчётов и материалов на русском языке. Его основная задача — распознать текст в PDF, восстановить структуру страницы и сохранить результат в удобном формате.
FineReader особенно полезен, когда PDF выглядит как обычный документ, но не даёт выделить ни одного слова. Программа анализирует изображение страницы, определяет текстовые области, таблицы, картинки, колонтитулы, номера страниц и создаёт редактируемый текст.
Что получится сделать
В FineReader удобно:
-
распознать отсканированный PDF;
-
выбрать русский, английский и другие языки;
-
сохранить результат в DOCX, XLSX, TXT, searchable PDF;
-
копировать фрагменты после распознавания;
-
проверять сомнительно распознанные символы;
-
сохранять таблицы в Excel;
-
обрабатывать многостраничные документы;
-
исправлять области распознавания вручную;
-
превращать скан PDF в Word.
Как распознать PDF в ABBYY FineReader
-
Запустите ABBYY FineReader.
-
Нажмите Открыть.
-
Выберите PDF-файл.
-
Укажите языки документа: русский, английский или нужную комбинацию.
-
Дождитесь анализа страниц.
-
Проверьте области: текст, таблицы, изображения.
-
Нажмите Распознать.
-
После обработки откройте текстовую панель.
-
Выделите нужный фрагмент.
-
Нажмите Ctrl+C.
-
Вставьте текст в Word или другой редактор.
При работе с документом на русском языке обязательно выбирайте русский язык распознавания. Так уменьшается количество ошибок в окончаниях, буквах ё/е, цифрах, сокращениях и фамилиях.
Как сохранить распознанный документ
После OCR доступны разные варианты сохранения:
-
DOCX — для дальнейшего редактирования в Word;
-
XLSX — для таблиц;
-
TXT — для чистого текста без оформления;
-
PDF с возможностью поиска — для архива и копирования;
-
PDF/A — для долговременного хранения;
-
RTF — для совместимости со старыми редакторами.
Для копирования больших фрагментов удобнее сохранить DOCX. Для архива лучше создать PDF с текстовым слоем: внешний вид страницы сохранится, а текст станет доступен для поиска и выделения.
Как исправить ошибки OCR
После распознавания проверьте:
-
фамилии, адреса, номера договоров;
-
цифры в суммах;
-
даты;
-
таблицы;
-
сокращения;
-
печати и подписи рядом с текстом;
-
строки на сгибах страницы;
-
мелкий шрифт;
-
подстрочные и надстрочные символы.
OCR не заменяет финальную вычитку. Для юридических, финансовых и технических документов проверка обязательна.
Плюсы ABBYY FineReader
-
Сильное распознавание русского текста.
-
Хорошая работа со сканами, таблицами и многостраничными PDF.
-
Экспорт в Word, Excel, TXT и searchable PDF.
-
Удобная проверка сомнительных символов.
-
Подходит для архивов, книг, договоров и отчётов.
-
Позволяет корректировать области распознавания вручную.
-
Хорошо сохраняет структуру страницы.
Минусы ABBYY FineReader
-
Платная программа.
-
Для разовой задачи установка выглядит избыточной.
-
Большие документы требуют времени на обработку.
-
Плохие сканы всё равно требуют ручной правки.
-
Интерфейс богаче, чем нужно для простого копирования одного абзаца.
Когда выбирать ABBYY FineReader
FineReader выбирают, когда нужно скопировать текст из отсканированного PDF, сохранить структуру, обработать русский документ и получить качественный результат. Это один из лучших вариантов для случаев, когда текст не выделяется вообще или копируется иероглифами.
Adobe Acrobat Pro
Adobe Acrobat Pro подходит для профессиональной работы с PDF: редактирования, OCR, проверки ограничений, экспорта в Word, защиты, подписей, комментариев и подготовки документов к отправке. Для задачи копирования текста Acrobat полезен тем, что показывает права доступа и умеет создавать текстовый слой поверх скана.
Что получится сделать
В Acrobat Pro удобно:
-
скопировать текст из обычного PDF;
-
проверить, разрешено ли копирование;
-
распознать скан через OCR;
-
экспортировать PDF в Word;
-
сделать PDF доступным для поиска;
-
снять ограничения при наличии пароля владельца;
-
сравнить исходный и обработанный документ;
-
исправить текст прямо в PDF;
-
работать с многостраничными файлами.
Как скопировать текст из обычного PDF
-
Откройте PDF в Adobe Acrobat Pro.
-
Выберите инструмент выделения.
-
Наведите курсор на нужный абзац.
-
Выделите текст.
-
Нажмите Ctrl+C.
-
Вставьте фрагмент в Word, Excel, Блокнот или редактор сайта.
-
Проверьте переносы строк.
Для точного копирования небольшого фрагмента выделяйте текст по строкам, а не целую область страницы. Это уменьшает риск захватить колонтитулы, номера страниц и соседнюю колонку.
Как распознать текст через OCR
-
Откройте документ.
-
Перейдите в раздел All tools.
-
Выберите Scan & OCR.
-
Нажмите Recognize Text.
-
Выберите вариант In This File.
-
Укажите страницы для обработки.
-
Проверьте язык распознавания.
-
Запустите OCR.
-
После завершения попробуйте выделить текст мышью.
-
Скопируйте нужный фрагмент.
После OCR Acrobat добавляет текстовый слой. Внешний вид страницы остаётся прежним, а текст становится доступен для поиска и копирования.
Как экспортировать PDF в Word
-
Откройте файл.
-
Выберите Export PDF.
-
Укажите формат Microsoft Word.
-
Выберите Word Document.
-
Запустите экспорт.
-
Откройте DOCX.
-
Скопируйте нужный текст из Word.
Экспорт в Word удобен для больших фрагментов, когда требуется не просто взять одну цитату, а переработать весь документ.
Как проверить ограничения
-
Откройте PDF.
-
Перейдите в свойства документа.
-
Откройте вкладку безопасности.
-
Проверьте операции, которые разрешены: печать, копирование, редактирование.
-
При наличии пароля владельца измените разрешения.
-
Сохраните копию файла.
Для чужих документов без разрешения корректнее запросить файл без ограничений. Это особенно важно для книг, платных методичек, внутренней документации и коммерческих отчётов.
Плюсы Adobe Acrobat Pro
-
Профессиональная работа с PDF.
-
Есть OCR для сканированных документов.
-
Удобная проверка прав доступа.
-
Хороший экспорт в Word.
-
Подходит для корпоративного документооборота.
-
Работает с подписями, формами, комментариями и защитой.
-
Позволяет редактировать PDF после распознавания.
Минусы Adobe Acrobat Pro
-
Платная подписка.
-
Интерфейс перегружен для простой задачи.
-
На слабых компьютерах большие PDF обрабатываются медленно.
-
Для защищённых файлов нужен пароль владельца.
-
После экспорта сложных таблиц нужна ручная правка.
Когда выбирать Adobe Acrobat Pro
Acrobat Pro выбирают, когда нужно не только скопировать текст, но и проверить защиту, распознать скан, экспортировать PDF в Word, подготовить документ к отправке или сохранить файл с нормальным текстовым слоем.
Adobe Acrobat Reader
Adobe Acrobat Reader — бесплатный просмотрщик PDF. Он подходит для чтения, поиска, выделения, копирования доступного текста, комментариев и базовой работы с файлами. Reader не заменяет полноценный редактор, но для обычного текстового PDF его достаточно.
Что получится сделать
В Reader удобно:
-
открыть PDF;
-
выделить текст мышью;
-
скопировать фрагмент;
-
искать слова по документу;
-
добавлять комментарии;
-
проверять, работает ли текстовый слой;
-
понять, что документ является сканом;
-
увидеть ограничения на копирование.
Как скопировать текст в Adobe Acrobat Reader
-
Откройте PDF в Adobe Acrobat Reader.
-
Выберите инструмент выделения.
-
Проведите мышью по нужному абзацу.
-
Нажмите Ctrl+C.
-
Вставьте текст в другой документ.
-
Проверьте результат.
Когда документ состоит из двух колонок, выделяйте только одну колонку. При выделении всей страницы программа часто смешивает блоки в неправильном порядке.
Что делать, когда копирование недоступно
Порядок проверки:
-
Нажмите Ctrl+F и попробуйте найти слово со страницы.
-
Попробуйте выделить одну букву или одно слово.
-
Откройте свойства документа.
-
Проверьте ограничения.
-
При отсутствии текстового слоя передайте файл в OCR-программу.
-
При наличии запрета на копирование используйте файл с разрешением или пароль владельца.
Reader хорошо показывает сам факт проблемы, но не всегда решает её. Для сканов нужен Acrobat Pro, FineReader, PDF-XChange Editor, PDFelement или другой инструмент с OCR.
Плюсы Adobe Acrobat Reader
-
Бесплатный просмотрщик.
-
Подходит для простого копирования.
-
Есть поиск по документу.
-
Удобен для проверки текстового слоя.
-
Распространён в офисной среде.
-
Хорошо открывает сложные PDF.
-
Поддерживает комментарии и выделения.
Минусы Adobe Acrobat Reader
-
Не выполняет полноценное редактирование PDF.
-
OCR доступен не как базовая функция Reader.
-
Защищённые документы остаются ограниченными.
-
Сложные таблицы копируются с ошибками.
-
Для массовой обработки нужен другой инструмент.
Когда выбирать Adobe Acrobat Reader
Reader выбирают, когда PDF уже содержит нормальный текстовый слой. Это быстрый вариант для чтения, поиска и копирования небольших фрагментов без установки профессионального редактора.
PDFelement
PDFelement объединяет функции редактора PDF, OCR, конвертера, инструмента для форм, комментариев и защиты. Для копирования текста из проблемного PDF он полезен тем, что позволяет распознавать сканы, редактировать текстовый слой и экспортировать документ в Word.
Что получится сделать
В PDFelement удобно:
-
копировать текст из обычного PDF;
-
запускать OCR для сканированных страниц;
-
редактировать распознанный текст;
-
конвертировать PDF в Word, Excel и TXT;
-
работать с формами;
-
добавлять комментарии;
-
объединять и разделять файлы;
-
проверять структуру страниц;
-
сохранять PDF после изменений.
Как скопировать обычный текст
-
Откройте PDF в PDFelement.
-
Перейдите в режим выделения.
-
Выберите нужный фрагмент.
-
Нажмите Ctrl+C.
-
Вставьте текст в редактор.
-
Проверьте форматирование.
Для аккуратного результата не выделяйте сразу весь разворот. Лучше копировать по смысловым блокам: заголовок, абзац, список, таблица.
Как распознать сканированный PDF
-
Откройте файл.
-
Нажмите OCR.
-
Выберите язык документа.
-
Укажите диапазон страниц.
-
Выберите режим создания редактируемого или доступного для поиска текста.
-
Запустите распознавание.
-
После завершения выделите нужный текст.
-
Скопируйте фрагмент.
При плохом скане проверьте результат вручную. Особое внимание уделите цифрам, адресам, артикулу товара, номерам документов и фамилиям.
Как экспортировать PDF в Word
-
Откройте PDF.
-
Перейдите к конвертации.
-
Выберите формат Word.
-
Укажите страницы.
-
Сохраните DOCX.
-
Откройте файл в Word.
-
Скопируйте или отредактируйте текст.
Экспорт удобен, когда нужно забрать большой объём текста и сохранить хотя бы часть оформления.
Плюсы PDFelement
-
Есть OCR и редактирование PDF.
-
Подходит для сканов и обычных документов.
-
Удобный экспорт в Word.
-
Интерфейс проще, чем у многих профессиональных решений.
-
Есть работа с формами и комментариями.
-
Подходит для офисного документооборота.
-
Позволяет исправлять текст после распознавания.
Минусы PDFelement
-
Полные функции доступны в платной версии.
-
OCR требует проверки после обработки.
-
Сложные таблицы после экспорта требуют ручной правки.
-
Интерфейс меняется между версиями.
-
Для разового копирования одного фрагмента программа избыточна.
Когда выбирать PDFelement
PDFelement выбирают, когда требуется не только извлечь текст из PDF, но и отредактировать документ, сохранить в Word, распознать сканы и продолжить работу с файлом в одном интерфейсе.
PDF-XChange Editor
PDF-XChange Editor — сильный редактор для Windows с инструментами просмотра, редактирования, комментариев, OCR и работы со страницами. Он хорошо подходит пользователям, которым нужен точный контроль над PDF без тяжёлой экосистемы.
Что получится сделать
В PDF-XChange Editor удобно:
-
копировать текст из обычного PDF;
-
запускать OCR для выбранных страниц;
-
распознавать отдельную область;
-
создавать невидимый текстовый слой;
-
сохранять searchable PDF;
-
добавлять комментарии и пометки;
-
работать с закладками;
-
извлекать страницы;
-
проверять результат поиска после OCR.
Как скопировать текст
-
Откройте PDF.
-
Выберите инструмент выделения текста.
-
Выделите нужный фрагмент.
-
Нажмите Ctrl+C.
-
Вставьте текст в редактор.
-
Проверьте порядок строк.
В PDF с колонками копируйте текст частями. Это снижает количество ошибок при вставке.
Как запустить OCR
-
Откройте документ.
-
Перейдите на вкладку Convert.
-
Нажмите OCR Pages.
-
Укажите страницы.
-
Выберите язык распознавания.
-
Укажите вариант создания текстового слоя.
-
Запустите обработку.
-
Сохраните документ.
-
Проверьте поиск по словам.
-
Скопируйте нужный текст.
PDF-XChange Editor также удобен для распознавания отдельной области страницы. Это помогает, когда нужно скопировать не весь лист, а одну таблицу, подпись, реквизиты или фрагмент инструкции.
Как распознать отдельную область
-
Откройте страницу.
-
Выберите инструмент OCR для области.
-
Обведите прямоугольником нужный фрагмент.
-
Укажите язык.
-
Запустите распознавание.
-
Скопируйте результат.
Этот способ экономит время на больших файлах и уменьшает количество мусора в итоговом тексте.
Плюсы PDF-XChange Editor
-
Есть OCR страниц и областей.
-
Удобен для точечной работы с PDF.
-
Хорошо подходит для технических документов.
-
Много инструментов разметки и комментариев.
-
Позволяет сохранять searchable PDF.
-
Быстрее многих тяжёлых редакторов.
-
Подходит для опытных пользователей Windows.
Минусы PDF-XChange Editor
-
Интерфейс насыщен панелями и настройками.
-
Новичку требуется время на привыкание.
-
Часть функций доступна в платной редакции.
-
После OCR нужен контроль ошибок.
-
Сложные таблицы не всегда идеально переносятся.
Когда выбирать PDF-XChange Editor
PDF-XChange Editor выбирают, когда нужен точный OCR, выделение отдельных областей, работа с комментариями и быстрое создание PDF с текстовым слоем.
Foxit PDF Editor
Foxit PDF Editor подходит для офисной работы с PDF: редактирования, OCR, комментариев, форм, экспорта и защиты. Для копирования текста из сканированных документов в нём важен инструмент распознавания.
Что получится сделать
Foxit PDF Editor позволяет:
-
копировать текст из обычных PDF;
-
распознавать сканированные страницы;
-
создавать searchable PDF;
-
выбирать язык OCR;
-
редактировать распознанный текст;
-
экспортировать PDF в Word;
-
работать с комментариями;
-
проверять подозрительные символы после распознавания;
-
обрабатывать документы с изображениями.
Как скопировать текст
-
Откройте PDF в Foxit PDF Editor.
-
Выберите инструмент выделения текста.
-
Выделите нужный блок.
-
Нажмите Ctrl+C.
-
Вставьте текст в редактор.
-
Проверьте переносы строк.
Для документов с несколькими колонками выделяйте текст по одной колонке. При необходимости используйте экспорт в Word.
Как запустить OCR
-
Откройте сканированный PDF.
-
Перейдите на вкладку Convert.
-
Выберите Recognize Text.
-
Укажите Current File.
-
Выберите страницы.
-
Укажите язык.
-
Выберите режим текстового слоя.
-
Нажмите Start.
-
Дождитесь завершения.
-
Проверьте выделение текста.
После OCR текст становится доступным для поиска и копирования. Для важных документов используйте проверку подозрительных символов.
Плюсы Foxit PDF Editor
-
Есть OCR.
-
Подходит для офисного PDF-документооборота.
-
Удобный экспорт в Word.
-
Есть работа с формами и комментариями.
-
Поддерживает создание searchable PDF.
-
Хорошо работает с многостраничными документами.
-
Есть инструменты проверки результата OCR.
Минусы Foxit PDF Editor
-
Полная версия платная.
-
Интерфейс насыщен офисными вкладками.
-
Для простой разовой задачи функций слишком много.
-
OCR требует проверки после распознавания.
-
Сложная вёрстка после экспорта требует ручной корректировки.
Когда выбирать Foxit PDF Editor
Foxit PDF Editor выбирают для регулярной офисной работы с PDF, когда нужно копировать текст, распознавать сканы, редактировать документы и сохранять результат в Word.
Nitro PDF Pro
Nitro PDF Pro — редактор PDF с OCR, экспортом, правкой текста, комментариями, формами и защитой. Он хорошо подходит для пользователей, которые часто переводят PDF в Word, обрабатывают сканы и собирают документы из разных источников.
Что получится сделать
В Nitro PDF Pro удобно:
-
копировать текст из PDF;
-
распознавать сканированные документы;
-
создавать searchable PDF;
-
создавать редактируемый текстовый слой;
-
экспортировать PDF в Word и Excel;
-
работать с формами;
-
комментировать файлы;
-
объединять документы;
-
повышать пригодность PDF для поиска.
Как скопировать текст
-
Откройте PDF в Nitro PDF Pro.
-
Выберите инструмент выделения.
-
Выделите фрагмент.
-
Нажмите Ctrl+C.
-
Вставьте текст в Word или Блокнот.
-
Проверьте результат.
При копировании из отчётов и таблиц лучше использовать экспорт, а не ручное выделение.
Как выполнить OCR
-
Откройте PDF.
-
Перейдите на вкладку Review.
-
Найдите панель Documents.
-
Нажмите OCR.
-
Выберите режим Searchable или Searchable and Editable.
-
Откройте параметры обработки.
-
Укажите страницы и язык.
-
Запустите OCR.
-
Сохраните обработанный файл.
-
Скопируйте текст.
Режим searchable подходит для поиска и копирования. Режим editable нужен, когда текст предстоит править прямо в документе.
Плюсы Nitro PDF Pro
-
Есть OCR для сканов.
-
Хороший экспорт в Word и Excel.
-
Подходит для документов с таблицами.
-
Удобен для офисной работы.
-
Есть редактирование текста и страниц.
-
Поддерживает формы и комментарии.
-
Позволяет создавать searchable PDF.
Минусы Nitro PDF Pro
-
Платный продукт.
-
Для разового копирования выглядит тяжеловесно.
-
OCR требует проверки.
-
Интерфейс ориентирован на офисных пользователей.
-
Сложные макеты требуют ручной доводки после экспорта.
Когда выбирать Nitro PDF Pro
Nitro PDF Pro выбирают, когда PDF регулярно переводится в Word или Excel, а документы часто приходят в виде сканов, отчётов и таблиц.
Microsoft Word
Microsoft Word подходит для быстрого превращения PDF в редактируемый DOCX. Это не полноценный PDF-редактор, но для текстовых документов, писем, договоров и простых инструкций способ работает очень быстро.
Что получится сделать
В Word удобно:
-
открыть PDF как редактируемый документ;
-
скопировать текст из DOCX;
-
сохранить результат в Word;
-
убрать лишние переносы;
-
исправить абзацы;
-
переработать текст;
-
извлечь часть содержимого;
-
очистить форматирование.
Как открыть PDF в Word
-
Запустите Microsoft Word.
-
Нажмите Файл → Открыть.
-
Выберите PDF.
-
Подтвердите преобразование.
-
Дождитесь открытия документа.
-
Найдите нужный фрагмент.
-
Скопируйте текст обычным способом.
-
Сохраните файл в DOCX.
Word лучше справляется с PDF, где много обычного текста и мало сложной графики. В документах с таблицами, несколькими колонками, сносками и нестандартными шрифтами вёрстка часто меняется.
Как очистить текст после открытия в Word
После конвертации:
-
Включите отображение непечатаемых символов.
-
Удалите лишние разрывы строк.
-
Проверьте заголовки.
-
Исправьте списки.
-
Сверьте таблицы с оригиналом.
-
Проверьте номера страниц и сноски.
-
Сохраните чистую версию.
Для простого извлечения текста используйте Вставить только текст. Это убирает часть лишнего форматирования.
Плюсы Microsoft Word
-
Уже установлен у многих пользователей.
-
Быстро открывает простые PDF.
-
Удобен для дальнейшей правки текста.
-
Хорошо подходит для договоров и писем.
-
Легко убрать лишние переносы.
-
Можно сохранить результат в DOCX.
-
Не нужен отдельный PDF-редактор для простой задачи.
Минусы Microsoft Word
-
Сложная вёрстка меняется.
-
Таблицы часто требуют ручной правки.
-
Сканы без OCR не превращаются в качественный текст.
-
Большие PDF открываются медленно.
-
Исходный вид страницы не всегда сохраняется.
Когда выбирать Microsoft Word
Word выбирают, когда нужно быстро получить редактируемый текст из простого PDF. Для сканов, таблиц и юридически точных копий лучше использовать OCR-редактор.
PowerToys Text Extractor
PowerToys Text Extractor помогает скопировать текст с области экрана. Этот способ полезен, когда PDF не даёт выделить текст, а нужен небольшой фрагмент: номер договора, адрес, цитата, пункт инструкции, подпись под картинкой.
Инструмент работает по принципу распознавания текста с изображения на экране. Вы открываете страницу, выделяете область, а распознанный текст попадает в буфер обмена.
Что получится сделать
С помощью экранного распознавания удобно:
-
взять текст с изображения;
-
скопировать фрагмент из скана;
-
распознать одну область PDF;
-
получить текст из защищённого интерфейса без изменения файла;
-
быстро перенести короткую надпись;
-
забрать текст из презентации или скриншота.
Как использовать экранное распознавание
-
Установите Microsoft PowerToys.
-
Включите Text Extractor.
-
Откройте PDF на нужной странице.
-
Увеличьте масштаб, чтобы буквы были крупными.
-
Запустите сочетание для Text Extractor.
-
Обведите нужный фрагмент.
-
Дождитесь копирования текста в буфер обмена.
-
Вставьте результат в редактор.
-
Проверьте ошибки.
Для лучшего результата увеличивайте масштаб страницы и выбирайте только нужную область без лишних линий, печатей и соседних колонок.
Плюсы PowerToys Text Extractor
-
Быстро работает с отдельными фрагментами.
-
Не требует конвертировать весь PDF.
-
Подходит для текста на изображении.
-
Удобен для коротких задач.
-
Работает с областью экрана.
-
Полезен для сканов, скриншотов и интерфейсов.
Минусы PowerToys Text Extractor
-
Не подходит для больших документов.
-
Требует ручной проверки.
-
Таблицы распознаются хуже, чем в OCR-редакторах.
-
Качество зависит от масштаба и чёткости текста.
-
Не сохраняет структуру PDF.
Когда выбирать PowerToys Text Extractor
Этот способ выбирают, когда нужно быстро забрать небольшой фрагмент, а полноценное распознавание всего документа не требуется.
Как скопировать текст из PDF, если он не копируется на macOS
Просмотр
Просмотр — стандартное приложение macOS для PDF и изображений. Оно открывает документы без установки дополнительных программ и подходит для базового копирования текста, разметки, поворота страниц, экспорта и просмотра свойств.
Что получится сделать
В Просмотре удобно:
-
открыть PDF;
-
выделить доступный текст;
-
скопировать фрагмент;
-
искать слова;
-
проверять, является ли страница сканом;
-
поворачивать страницы;
-
делать разметку;
-
использовать системные возможности macOS для текста на изображениях.
Как скопировать текст в Просмотре
-
Откройте PDF двойным щелчком.
-
Перейдите в Инструменты.
-
Выберите Выбор текста.
-
Выделите нужный фрагмент.
-
Нажмите Cmd+C.
-
Вставьте текст в Pages, Word, Заметки или другой редактор.
Когда текст не выделяется, переключитесь на выбор текста вручную через меню инструментов. При работе с многостраничными файлами используйте поиск: он сразу показывает, есть ли в документе текстовый слой.
Как проверить защиту PDF на Mac
-
Откройте документ в Просмотре.
-
Перейдите в Инструменты.
-
Откройте инспектор.
-
Проверьте сведения о шифровании и разрешениях.
-
При наличии пароля откройте документ с нужными правами.
-
Сохраните рабочую копию.
Когда нужен OCR
Просмотр копирует текст только тогда, когда он реально есть в PDF или доступен через системное распознавание. Для многостраничных сканов, таблиц и архивных документов лучше использовать ABBYY FineReader, Adobe Acrobat Pro или другой OCR-инструмент.
Плюсы Просмотра
-
Уже встроен в macOS.
-
Быстро открывает PDF.
-
Подходит для обычного копирования.
-
Есть поиск по документу.
-
Удобен для просмотра и лёгкой разметки.
-
Не требует установки.
-
Хорошо подходит для проверки типа PDF.
Минусы Просмотра
-
Не является полноценным OCR-комплексом для больших архивов.
-
Сложные сканы требуют отдельного распознавания.
-
Таблицы копируются ограниченно.
-
Защищённые документы требуют разрешений.
-
Редактирование PDF ограничено.
Когда выбирать Просмотр
Просмотр выбирают для быстрого копирования текста на Mac, когда PDF уже содержит текстовый слой. Для сканов лучше сразу переходить к OCR.
ABBYY FineReader для macOS
FineReader на Mac решает ту же задачу, что и версия для Windows: распознаёт сканированные PDF, создаёт текстовый слой, сохраняет результат в DOCX, TXT, XLSX или searchable PDF.
Что получится сделать
На macOS FineReader удобен для:
-
сканированных договоров;
-
учебных пособий;
-
архивных материалов;
-
многостраничных PDF;
-
документов на русском языке;
-
таблиц;
-
PDF-книг;
-
конвертации в Word.
Как распознать PDF на Mac
-
Запустите FineReader.
-
Откройте PDF.
-
Выберите язык документа.
-
Проверьте области распознавания.
-
Запустите OCR.
-
Сохраните результат в Word или PDF с текстовым слоем.
-
Откройте результат.
-
Скопируйте нужный текст.
Для документов с таблицами выбирайте экспорт в Excel или Word. Для архива выбирайте searchable PDF.
Плюсы ABBYY FineReader для macOS
-
Хорошее распознавание русского текста.
-
Подходит для сканов и архивов.
-
Сохраняет результат в удобных форматах.
-
Помогает восстановить таблицы.
-
Подходит для многостраничных документов.
-
Удобен для создания PDF с поиском.
Минусы ABBYY FineReader для macOS
-
Платная программа.
-
Для короткого фрагмента проще использовать встроенные средства.
-
OCR больших документов занимает время.
-
Плохие сканы требуют ручной проверки.
-
Результат таблиц нужно сверять с оригиналом.
Когда выбирать ABBYY FineReader на Mac
FineReader выбирают, когда на Mac нужно качественно распознать скан, скопировать большой объём текста или подготовить документ для дальнейшей работы в Word.
Adobe Acrobat Pro для macOS
Adobe Acrobat Pro на Mac подходит для OCR, экспорта, проверки защиты, редактирования и работы с корпоративными PDF.
Что получится сделать
В Acrobat Pro на macOS удобно:
-
выделять и копировать текст;
-
распознавать сканы;
-
экспортировать PDF в Word;
-
проверять ограничения;
-
редактировать текст;
-
сохранять searchable PDF;
-
работать с формами и подписями.
Как распознать PDF
-
Откройте файл.
-
Перейдите в All tools.
-
Выберите Scan & OCR.
-
Нажмите Recognize Text.
-
Укажите файл и страницы.
-
Выберите язык.
-
Запустите OCR.
-
Сохраните результат.
-
Скопируйте текст.
Плюсы Adobe Acrobat Pro на Mac
-
Профессиональный набор PDF-инструментов.
-
Есть OCR.
-
Удобный экспорт в Word.
-
Подходит для защищённых документов при наличии пароля.
-
Есть редактирование и комментарии.
-
Хорошо вписывается в офисную работу.
Минусы Adobe Acrobat Pro на Mac
-
Платная подписка.
-
Для простого копирования одного абзаца избыточен.
-
Сложные таблицы требуют проверки.
-
Большие сканы обрабатываются не мгновенно.
-
Интерфейс перегружен для новичка.
Когда выбирать Adobe Acrobat Pro на Mac
Acrobat Pro выбирают, когда PDF нужно не только распознать, но и проверить, отредактировать, экспортировать, подписать или отправить дальше в рабочем процессе.
Что делать, когда не получается скопировать текст из PDF онлайн
Онлайн-сервисы удобны для разовой обработки: загрузили PDF, выбрали OCR или конвертацию, скачали результат. Главный вопрос — конфиденциальность. Договоры, паспортные данные, банковские документы, коммерческие отчёты и внутренние материалы компании лучше обрабатывать локально на компьютере.
Google Drive и Google Docs
Google Drive и Google Docs подходят для простого распознавания и конвертации PDF в редактируемый документ. Способ удобен, когда нет отдельной OCR-программы, а файл не содержит конфиденциальных данных.
Что получится сделать
Через Google Drive удобно:
-
загрузить PDF;
-
открыть файл в Google Docs;
-
получить редактируемый текст;
-
скопировать нужный фрагмент;
-
сохранить документ в DOCX;
-
быстро обработать скан;
-
перенести текст в облачный документ.
Как скопировать текст через Google Drive
-
Откройте Google Drive.
-
Загрузите PDF.
-
Нажмите правой кнопкой по файлу.
-
Выберите Открыть с помощью.
-
Выберите Google Документы.
-
Дождитесь преобразования.
-
Найдите нужный фрагмент.
-
Скопируйте текст.
-
Проверьте абзацы, таблицы и списки.
Google Docs хорошо подходит для обычного текста. Списки, таблицы, колонки, сноски и сложная вёрстка часто требуют ручной правки.
Плюсы Google Drive и Google Docs
-
Не нужно ставить программу.
-
Удобно для разовой задачи.
-
Работает в браузере.
-
Подходит для простых сканов.
-
Можно сразу редактировать текст.
-
Легко скачать результат в DOCX.
-
Хороший вариант для учебных материалов без секретных данных.
Минусы Google Drive и Google Docs
-
Не подходит для конфиденциальных файлов.
-
Сложные таблицы и колонки распознаются хуже.
-
Оформление меняется.
-
Большие файлы открываются медленнее.
-
Качество зависит от изображения и структуры PDF.
Когда выбирать Google Drive
Google Drive выбирают, когда нужно быстро извлечь текст из PDF онлайн и файл не содержит персональных или коммерческих данных.
Smallpdf
Smallpdf — онлайн-набор инструментов для PDF: конвертация, сжатие, объединение, разделение, подпись, редактирование и OCR-функции. Для копирования текста он удобен через преобразование PDF в Word или создание доступного для поиска документа.
Что получится сделать
В Smallpdf удобно:
-
преобразовать PDF в Word;
-
обработать скан через OCR;
-
скачать редактируемый документ;
-
скопировать текст из результата;
-
быстро обработать файл без установки программы;
-
использовать браузер на Windows, Mac или Linux.
Как извлечь текст через Smallpdf
-
Откройте инструмент PDF в Word или OCR.
-
Загрузите PDF.
-
Выберите преобразование в редактируемый формат.
-
Дождитесь обработки.
-
Скачайте DOCX.
-
Откройте файл.
-
Скопируйте нужный текст.
-
Проверьте ошибки и оформление.
Для сканов выбирайте режим с распознаванием. Простая конвертация без OCR не создаёт полноценный текст из картинки.
Плюсы Smallpdf
-
Работает в браузере.
-
Подходит для разовых задач.
-
Есть конвертация PDF в Word.
-
Есть инструменты для OCR.
-
Не требует установки.
-
Удобен на разных системах.
-
Быстро помогает с простыми документами.
Минусы Smallpdf
-
Конфиденциальные документы лучше обрабатывать локально.
-
Бесплатный режим имеет ограничения.
-
Качество таблиц зависит от исходного файла.
-
Большие PDF обрабатываются дольше.
-
После OCR нужна проверка текста.
Когда выбирать Smallpdf
Smallpdf выбирают, когда нужен быстрый онлайн-способ извлечь текст из PDF, а документ не содержит чувствительной информации.
iLovePDF
iLovePDF — онлайн-сервис для конвертации, объединения, разделения, сжатия и распознавания PDF. Для задачи копирования текста он полезен через OCR и преобразование PDF в Word.
Что получится сделать
В iLovePDF удобно:
-
загрузить PDF;
-
выполнить OCR;
-
преобразовать файл в Word;
-
скачать результат;
-
скопировать распознанный текст;
-
обработать документ в браузере;
-
использовать сервис с разных устройств.
Как распознать PDF
-
Откройте инструмент OCR или PDF to Word.
-
Загрузите PDF.
-
Выберите язык документа.
-
Запустите обработку.
-
Скачайте результат.
-
Откройте файл в Word или другом редакторе.
-
Скопируйте нужный текст.
-
Проверьте ошибки распознавания.
Для русского текста выбирайте русский язык. При смешанном документе добавляйте второй язык, например английский.
Плюсы iLovePDF
-
Работает онлайн.
-
Есть OCR для PDF.
-
Удобная конвертация в Word.
-
Подходит для быстрой обработки.
-
Не требует установки.
-
Есть много дополнительных PDF-инструментов.
-
Подходит для простых сканов.
Минусы iLovePDF
-
Конфиденциальные документы безопаснее обрабатывать локально.
-
Бесплатный режим ограничен.
-
Таблицы и сложная вёрстка требуют проверки.
-
Качество зависит от скана.
-
Большие документы обрабатываются дольше.
Когда выбирать iLovePDF
iLovePDF выбирают для быстрой онлайн-конвертации PDF в редактируемый документ и распознавания простых сканов.
Sejda PDF Editor
Sejda PDF Editor — онлайн-инструмент для редактирования и обработки PDF. Для копирования текста из сложного файла полезны OCR, экспорт и редактирование страницы.
Что получится сделать
В Sejda удобно:
-
открыть PDF в браузере;
-
распознать скан через OCR;
-
получить searchable PDF;
-
сохранить текстовый результат;
-
отредактировать отдельные элементы;
-
скачать обработанный документ;
-
работать без установки программы.
Как извлечь текст через Sejda
-
Откройте OCR-инструмент Sejda.
-
Загрузите PDF.
-
Выберите язык документа.
-
Укажите формат результата.
-
Запустите обработку.
-
Скачайте файл.
-
Откройте результат.
-
Скопируйте текст.
Для длинных документов заранее разделите PDF на нужные страницы. Это ускоряет обработку и упрощает проверку.
Плюсы Sejda PDF Editor
-
Работает в браузере.
-
Есть OCR.
-
Подходит для редактирования отдельных PDF.
-
Удобен для небольших документов.
-
Не требует установки.
-
Можно получить searchable PDF или текстовый результат.
-
Подходит для разовой обработки.
Минусы Sejda PDF Editor
-
Есть ограничения бесплатного использования.
-
Конфиденциальные документы лучше не загружать в онлайн-сервис.
-
Сложная структура требует проверки.
-
OCR зависит от качества изображения.
-
Для больших архивов удобнее настольная программа.
Когда выбирать Sejda
Sejda выбирают, когда нужно быстро распознать небольшой PDF онлайн, скачать результат и скопировать из него текст.
Что делать, если не копируется текст из PDF на Android и iOS
На телефоне PDF часто открывается из мессенджера, почты, облака или сканера. Главная сложность — маленький экран. Для короткой цитаты мобильного способа достаточно, а для большого документа удобнее отправить файл на компьютер.
iPhone и iPad: Файлы, Фото и Live Text
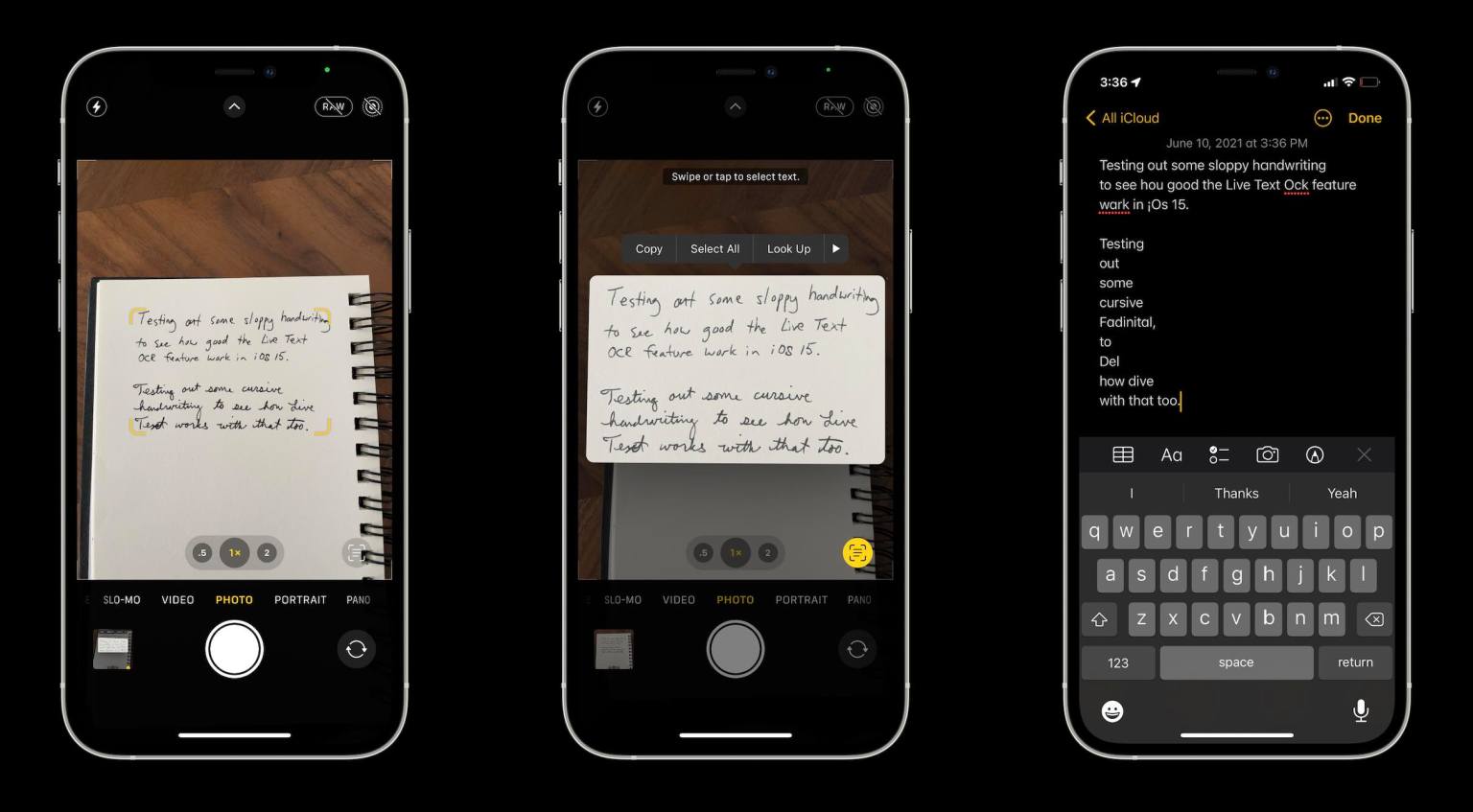
На iPhone и iPad текст из PDF копируется через встроенный просмотр, приложение Файлы, предпросмотр в Почте, Фото и системное распознавание текста на изображениях. Способ удобен для коротких фрагментов: адресов, номеров, цитат, пунктов договора, реквизитов.
Что получится сделать
На iPhone и iPad удобно:
-
открыть PDF из Файлов;
-
выделить текст в обычном PDF;
-
скопировать фрагмент;
-
распознать текст на изображении;
-
перенести текст в Заметки;
-
отправить фрагмент в мессенджер;
-
скопировать номер, адрес или пункт инструкции.
Как скопировать текст из обычного PDF
-
Откройте PDF в Файлах.
-
Увеличьте нужную страницу.
-
Нажмите и удерживайте слово.
-
Расширьте выделение маркерами.
-
Нажмите Скопировать.
-
Вставьте текст в Заметки, Pages, Word или сообщение.
Как скопировать текст со скана
-
Откройте страницу или скриншот.
-
Увеличьте область с текстом.
-
Используйте системное выделение текста на изображении.
-
Выберите нужный фрагмент.
-
Нажмите Скопировать.
-
Проверьте результат в заметке.
Для длинных документов сделайте обработку на компьютере. На телефоне сложнее контролировать таблицы, колонки и ошибки распознавания.
Плюсы iPhone и iPad
-
Не нужна отдельная программа для коротких фрагментов.
-
Удобно копировать адреса, номера и цитаты.
-
Работает с PDF и изображениями.
-
Результат легко отправить в заметки или сообщение.
-
Подходит для документов из почты и мессенджеров.
-
Быстро помогает в дороге.
Минусы iPhone и iPad
-
Неудобно обрабатывать большие PDF.
-
Таблицы копируются плохо.
-
Качество зависит от размера текста на экране.
-
Для многостраничного OCR лучше компьютер.
-
Ошибки распознавания нужно проверять вручную.
Когда выбирать iPhone или iPad
Мобильный способ выбирают для коротких фрагментов. Для полноценного скана на десятки страниц лучше использовать настольный OCR.
Android: Google Lens и Google Drive
На Android удобно использовать Google Lens, Google Drive, Google Docs и PDF-просмотрщики. Lens хорошо распознаёт текст с изображения, а Google Docs помогает преобразовать PDF в редактируемый документ.
Что получится сделать
На Android удобно:
-
открыть PDF из почты или мессенджера;
-
скопировать текст из обычного PDF;
-
сделать скриншот страницы;
-
распознать текст через Google Lens;
-
загрузить PDF в Google Drive;
-
открыть файл через Google Docs;
-
отправить результат в заметки или документ.
Как скопировать текст через Google Lens
-
Откройте PDF на нужной странице.
-
Увеличьте текст.
-
Сделайте скриншот.
-
Откройте скриншот в Google Lens.
-
Выберите режим Текст.
-
Выделите нужный фрагмент.
-
Нажмите Копировать текст.
-
Вставьте результат в заметку или документ.
Как обработать PDF через Google Drive
-
Загрузите PDF на Google Drive.
-
Откройте его через Google Docs.
-
Дождитесь преобразования.
-
Скопируйте нужный текст.
-
Проверьте абзацы и таблицы.
Плюсы Android-способа
-
Удобен для коротких фрагментов.
-
Google Lens быстро распознаёт текст с изображения.
-
Google Drive работает в браузере и приложении.
-
Результат легко отправить в документ.
-
Не требуется настольный компьютер.
-
Подходит для срочных задач.
Минусы Android-способа
-
Большие документы обрабатывать неудобно.
-
Таблицы и колонки часто ломаются.
-
Для конфиденциальных файлов онлайн-обработка нежелательна.
-
Результат OCR нужно проверять.
-
Маленький экран мешает точному выделению.
Когда выбирать Android
Android подходит для быстрого копирования короткого фрагмента из PDF или скана. Для больших документов удобнее компьютерная программа.
Xodo PDF Reader

Xodo PDF Reader подходит для чтения PDF, аннотаций, выделений, комментариев и базовой работы с документами на телефоне, планшете и компьютере. Для копирования текста он полезен при работе с обычными PDF, где текстовый слой уже есть.
Что получится сделать
В Xodo удобно:
-
открыть PDF;
-
выделить текст;
-
скопировать фрагмент;
-
добавить комментарий;
-
подчеркнуть важное место;
-
работать с документом на телефоне;
-
читать длинные PDF;
-
синхронизировать рабочие материалы.
Как скопировать текст в Xodo
-
Откройте PDF в Xodo.
-
Перейдите на нужную страницу.
-
Нажмите и удерживайте слово.
-
Расширьте выделение.
-
Нажмите Copy.
-
Вставьте текст в заметку, письмо или документ.
Когда текст не выделяется, перед вами скан. Для такого файла используйте OCR через Google Lens, Google Drive или настольный распознаватель.
Плюсы Xodo PDF Reader
-
Удобен для чтения PDF на телефоне.
-
Поддерживает выделения и комментарии.
-
Подходит для обычного копирования текста.
-
Работает с документами большого объёма.
-
Удобен для учёбы и рабочих материалов.
-
Позволяет быстро отметить нужные места.
Минусы Xodo PDF Reader
-
Сканированный PDF требует отдельного OCR.
-
На маленьком экране сложно выделять большие фрагменты.
-
Таблицы копировать неудобно.
-
Защищённые документы остаются ограниченными.
-
Для сложной обработки лучше компьютер.
Когда выбирать Xodo
Xodo выбирают для чтения, пометок и копирования текста из PDF на мобильном устройстве. Для сканов используйте распознавание.
Что делать, когда текст копируется иероглифами
Иероглифы, квадраты, вопросительные знаки и бессмысленные символы появляются из-за внутренней кодировки PDF. Видимые буквы на странице связаны с нестандартными шрифтами, а таблица соответствия символов работает неправильно.
Правильный порядок:
-
Не копируйте текст повторно из того же слоя.
-
Откройте файл в OCR-программе.
-
Выберите язык документа.
-
Распознайте страницу заново.
-
Скопируйте текст из нового слоя.
-
Сверьте результат с оригиналом.
Для русских документов обязательно проверьте буквы ё, й, з, э, цифры 0/О, 1/л/I, сокращения, фамилии и адреса.
Что делать, когда копируются лишние переносы строк
PDF часто хранит строки как отдельные блоки. Поэтому после вставки в Word каждый визуальный перенос превращается в новый абзац.
Как очистить текст:
-
Вставьте текст в Word.
-
Включите непечатаемые символы.
-
Откройте замену через Ctrl+H.
-
Замените лишние разрывы строк на пробел.
-
Сохраните настоящие абзацы вручную.
-
Удалите двойные пробелы.
-
Проверьте списки и заголовки.
Для длинных текстов удобнее сначала вставить материал в простой текстовый редактор, очистить переносы, затем перенести в Word.
Как скопировать таблицу из PDF
Таблицы — один из самых сложных случаев. В PDF таблица выглядит цельной, но внутри она часто состоит из линий, отдельных чисел, текстовых блоков и невидимых координат. Обычное копирование часто ломает строки и столбцы.
Лучший порядок:
-
Проверьте, выделяется ли текст в таблице.
-
Попробуйте экспорт в Excel.
-
При скане выполните OCR с распознаванием таблиц.
-
Сверьте заголовки столбцов.
-
Проверьте числа, десятичные разделители и даты.
-
Удалите лишние пустые строки.
-
Сравните итог с оригинальным PDF.
Для финансовых таблиц нельзя ограничиваться автоматическим результатом. Проверяйте суммы, проценты, артикулы, ИНН, банковские реквизиты и номера договоров.
Как скопировать текст из PDF-картинки
PDF-картинка — это файл, где каждая страница представляет собой изображение. В нём нет текстового слоя. Обычное выделение не работает, потому что программа не видит букв.
Используйте OCR:
-
Откройте PDF в FineReader, Acrobat Pro, PDF-XChange Editor, Foxit, Nitro или PDFelement.
-
Выберите язык документа.
-
Запустите распознавание.
-
Сохраните searchable PDF или DOCX.
-
Откройте результат.
-
Скопируйте текст.
-
Проверьте ошибки.
Качество OCR повышается, когда страница ровная, текст контрастный, разрешение достаточное, фон не серый, а буквы не смазаны.
Как скопировать текст из защищённого PDF
Защита PDF бывает разной. Один документ просит пароль на открытие. Другой открывается, но запрещает копирование. Третий разрешает печать, но не даёт редактировать страницы.
Корректный порядок:
-
Откройте свойства документа.
-
Проверьте разрешения.
-
При наличии пароля владельца измените настройки безопасности.
-
Сохраните копию без ограничений.
-
Скопируйте текст обычным способом.
-
При отсутствии разрешения запросите исходный файл или доступ.
Для рабочих, платных, учебных и коммерческих документов соблюдайте права автора и условия доступа. Не используйте обход ограничений для материалов, которые не принадлежат вам и не выданы вам для обработки.
Как выбрать лучший способ
| Ситуация | Лучший вариант |
|---|---|
| PDF обычный, текст выделяется | Adobe Reader, Просмотр, PDF Commander |
| PDF сканированный | ABBYY FineReader, Acrobat Pro, PDF-XChange Editor |
| Нужно сохранить структуру | FineReader, Acrobat Pro, PDFelement |
| Нужен Word-файл | Microsoft Word, Acrobat Pro, PDFelement, Smallpdf |
| Нужна таблица | FineReader, Nitro PDF Pro, Excel-экспорт |
| Нужно быстро онлайн | Google Drive, Smallpdf, iLovePDF |
| Документ конфиденциальный | Локальная программа на компьютере |
| Нужно скопировать одну строку с экрана | PowerToys Text Extractor, Google Lens |
| Работа на Mac | Просмотр, Acrobat Pro, FineReader |
| Работа на телефоне | Live Text, Google Lens, Xodo |
Частые ошибки
Пытаться копировать скан как обычный текст
Когда PDF состоит из картинок, выделение мышью не сработает. Нужен OCR.
Распознавать русский документ без выбора русского языка
OCR без правильного языка чаще ошибается в окончаниях, фамилиях, сокращениях и буквах.
Загружать конфиденциальный PDF в онлайн-сервис
Документы с персональными данными, договорами, отчётами и внутренней информацией лучше обрабатывать локально.
Копировать сразу всю страницу с колонками
Вставка часто смешивает левую и правую колонку. Копируйте по блокам.
Не проверять результат OCR
Даже хороший распознаватель ошибается на плохих сканах, печатях, мелком шрифте и таблицах.
Считать Word полноценным OCR-редактором
Word удобен для простых PDF, но сложные сканы и таблицы лучше обрабатывать специализированными программами.
FAQ
Почему в PDF нельзя выделить текст мышью?
Текст не выделяется, когда страница является изображением, документ защищён от копирования или в файле повреждён текстовый слой. Для скана нужно OCR. Для защищённого документа нужен доступ с разрешением на копирование.
Как понять, что PDF сделан из скана?
Откройте поиск по документу и найдите слово со страницы. Когда поиск ничего не находит, а мышь не выделяет отдельные буквы, документ состоит из изображений.
Чем отличается OCR от конвертации в Word?
OCR распознаёт буквы на изображении и создаёт текстовый слой. Конвертация в Word переносит содержимое PDF в DOCX. Для сканов сначала нужен OCR, затем уже сохранение в Word.
Как скопировать текст из защищённого PDF?
Проверьте разрешения в свойствах документа. При наличии пароля владельца измените ограничения и сохраните копию. При отсутствии прав запросите версию документа с разрешённым копированием.
Почему после копирования появляются иероглифы?
Внутри PDF используется проблемная кодировка или нестандартный шрифт. Лучшее решение — распознать страницу через OCR и копировать текст из нового слоя.
Как убрать лишние переносы строк после копирования?
Вставьте текст в Word, откройте замену через Ctrl+H, уберите лишние разрывы строк и двойные пробелы. После этого вручную восстановите настоящие абзацы.
Как скопировать таблицу из PDF?
Используйте экспорт в Excel или OCR с распознаванием таблиц. После обработки обязательно проверьте строки, столбцы, суммы и даты.
Как скопировать текст из PDF на Mac?
Откройте файл в Просмотре, включите выбор текста и нажмите Cmd+C. Для скана используйте FineReader или Acrobat Pro.
Как скопировать текст из PDF на телефоне?
На iPhone используйте Файлы, Фото и системное распознавание текста. На Android используйте Google Lens или Google Drive. Для большого документа удобнее компьютер.
Как сохранить PDF, чтобы текст потом копировался?
После OCR сохраните файл как searchable PDF. Внешний вид страниц сохранится, а текст станет доступен для поиска, выделения и копирования.
Итоговая рекомендация
Для Windows начните с PDF Commander: откройте файл, проверьте выделение текста, подготовьте страницы и сохраните рабочую копию. Для сканов и большого объёма текста используйте ABBYY FineReader, Adobe Acrobat Pro, PDF-XChange Editor, Foxit PDF Editor или PDFelement. На Mac сначала проверьте файл в Просмотре, а для сканов переходите к OCR. Онлайн-сервисы вроде Smallpdf, iLovePDF и Sejda PDF Editor оставьте для неконфиденциальных файлов.
Универсальный порядок простой: проверьте выделение, определите тип PDF, выполните OCR для скана, экспортируйте сложный документ в Word или Excel, очистите текст от лишних переносов и обязательно сверьте результат с оригиналом.
Чтобы оставить комментарий, авторизуйтесь или зарегистрируйтесь.