
PDF не всегда содержит настоящий текст. Иногда это обычный цифровой документ, где слова выделяются мышью, копируются и находятся через поиск. Но очень часто файл выглядит как нормальная страница, а внутри находится только изображение: скан договора, фото учебника, акт, накладная, архивная справка, страница книги, распечатка с печатью или скриншот. В таком документе нельзя нормально выделить строку, скопировать абзац, найти фамилию через Ctrl+F и быстро перенести данные в Word или Excel.
Для таких файлов используется OCR — оптическое распознавание символов. Программа анализирует страницу как изображение, находит буквы, цифры, таблицы, колонки, заголовки и создает текстовый слой. После этого PDF становится доступным для поиска, копирования, редактирования или экспорта в DOCX, XLSX, TXT и другие форматы.
В этом руководстве собраны способы для Windows, macOS, онлайн-сервисов и мобильных устройств. В каждом блоке есть одинаковая логика: для чего подходит программа, как выполнить распознавание, какие задачи она закрывает, где сильна, где ограничена и какой результат получится на выходе.
Когда распознавание текста в PDF действительно нужно
Перед запуском OCR стоит понять, какой именно PDF открыт. Визуально два файла могут выглядеть одинаково: белая страница, строки текста, таблицы, подписи. Разница становится заметна только при работе.
Текстовый PDF ведет себя как обычный документ. В нем можно выделить слово, скопировать фрагмент, найти номер договора через поиск, открыть свойства текста в редакторе и внести правку. Сканированный PDF ведет себя как картинка. Мышь выделяет не буквы, а область страницы. Поиск ничего не находит, хотя нужное слово видно глазами. Команда копирования переносит пустоту, мусорные символы или вообще недоступна.
OCR нужен в таких случаях:
-
PDF состоит из отсканированных страниц;
-
документ пришел как фото, вложенное в PDF;
-
текст видно, но он не выделяется;
-
поиск по файлу не находит слова;
-
нужно перенести данные из скана в Word;
-
нужно вытащить таблицу из PDF в Excel;
-
нужно сделать архив документов доступным для поиска;
-
нужно получить текст из учебника, инструкции, договора, счета или справки;
-
нужно сохранить внешний вид страницы, но добавить невидимый текстовый слой;
-
нужно распознать русский и английский текст в одном документе.
OCR не требуется, когда текст уже выделяется и копируется корректно. В такой ситуации достаточно обычного PDF-редактора или функции экспорта. Распознавание поверх уже нормального текстового слоя часто только увеличивает размер файла и добавляет ошибки.
Чем отличается распознавание от обычного копирования
Обычное копирование берет уже существующий текстовый слой. OCR создает этот слой заново. Поэтому результат зависит не только от программы, но и от качества исходника.
На точность влияют:
-
разрешение скана;
-
четкость букв;
-
контраст между текстом и фоном;
-
перекос страницы;
-
тени от книги или папки;
-
пятна, печати, штампы и рукописные пометки;
-
мелкий шрифт;
-
декоративные гарнитуры;
-
таблицы с тонкими линиями;
-
колонки;
-
смешение русского и английского языков;
-
сжатие PDF после сканирования.
Лучший материал для распознавания — ровный скан в 300 dpi с нормальным контрастом, без сильных теней и размытия. Хуже всего распознаются фотографии под углом, старые ксерокопии, документы с серым фоном, сканы с сильным JPEG-сжатием и страницы с рукописным текстом.
Как подготовить PDF к распознаванию
Перед обработкой стоит сделать короткую проверку.
-
Откройте PDF.
-
Попробуйте выделить одно слово мышью.
-
Нажмите Ctrl+F в Windows или Cmd+F в macOS.
-
Введите слово, которое точно есть на странице.
-
Посмотрите, находит ли программа это слово.
-
Убедитесь, что документ не защищен паролем.
-
Проверьте, не повернуты ли страницы боком.
-
Оцените читаемость: буквы должны быть различимы без увеличения до экстремального масштаба.
Для сложных сканов сначала полезно исправить изображение:
-
повернуть страницы в правильную ориентацию;
-
обрезать черные поля;
-
выровнять перекос;
-
поднять контраст;
-
убрать лишний фон;
-
удалить пустые страницы;
-
разделить развороты книги на отдельные страницы;
-
выбрать язык до запуска OCR.
Для официальных документов, договоров, счетов и справок после распознавания обязательно проверяются фамилии, даты, суммы, номера, реквизиты, адреса и артикулы. OCR хорошо ускоряет работу, но не заменяет вычитку там, где ошибка в одной цифре меняет смысл документа.
Быстрый выбор способа
| Задача | Лучший вариант | Почему |
|---|---|---|
| Распознать PDF на Windows без сложной настройки | PDF Commander | Русский интерфейс, понятная кнопка распознавания, работа со сканами и фото |
| Сделать сложный скан максимально аккуратным | ABBYY FineReader | Сильный OCR-редактор, зоны распознавания, проверка спорных символов |
| Работать в профессиональной PDF-среде | Adobe Acrobat Pro | Распознавание, редактирование PDF, исправление результата, подготовка searchable PDF |
| Нужен насыщенный редактор для Windows | PDF-XChange Editor | OCR Pages, выбор языков, поисковый текстовый слой, расширенный OCR в Plus |
| Нужно сканировать бумагу и сразу делать searchable PDF | NAPS2 | Сканирование, профили, OCR, сохранение в PDF |
| Нужно быстро распознать онлайн | PDF24 Tools или iLovePDF | Работают в браузере, создают PDF с поиском |
| Нужно вытащить текст через облако | Google Drive и Google Docs | Удобно для простых PDF и изображений |
| Нужно распознать фрагмент картинки в заметках | OneNote | Команда копирования текста с изображения |
| Нужно распознать документ с телефона | Adobe Scan, Microsoft Lens, CamScanner | Съемка, выравнивание, сохранение в PDF |
| Нужен открытый движок для автоматизации | Tesseract и gImageReader | Подходит для технических сценариев и пакетной обработки |
Как распознать текст в PDF на Windows
PDF Commander
PDF Commander удобно ставить первым способом для Windows, потому что программа не требует разбираться в профессиональных PDF-терминах. В интерфейсе есть отдельный сценарий для распознавания текста, а рядом находятся инструменты, которые обычно нужны после OCR: редактирование PDF, добавление текста, вставка изображения, объединение файлов, сканирование, конвертация, подпись, штампы и защита.
Программа подходит для сканов договоров, учебников, отчетов, справок, таблиц, архивных документов и фотографий страниц. В рабочем сценарии пользователь открывает файл, переходит во вкладку распознавания, выбирает режим OCR, отмечает язык документа и запускает обработку. После распознавания можно извлечь текст, добавить невидимый слой, заменить изображение текстом или наложить текст поверх изображения. Для обычной офисной работы самый полезный вариант — невидимый текстовый слой: внешний вид страницы остается прежним, но появляется поиск и копирование.
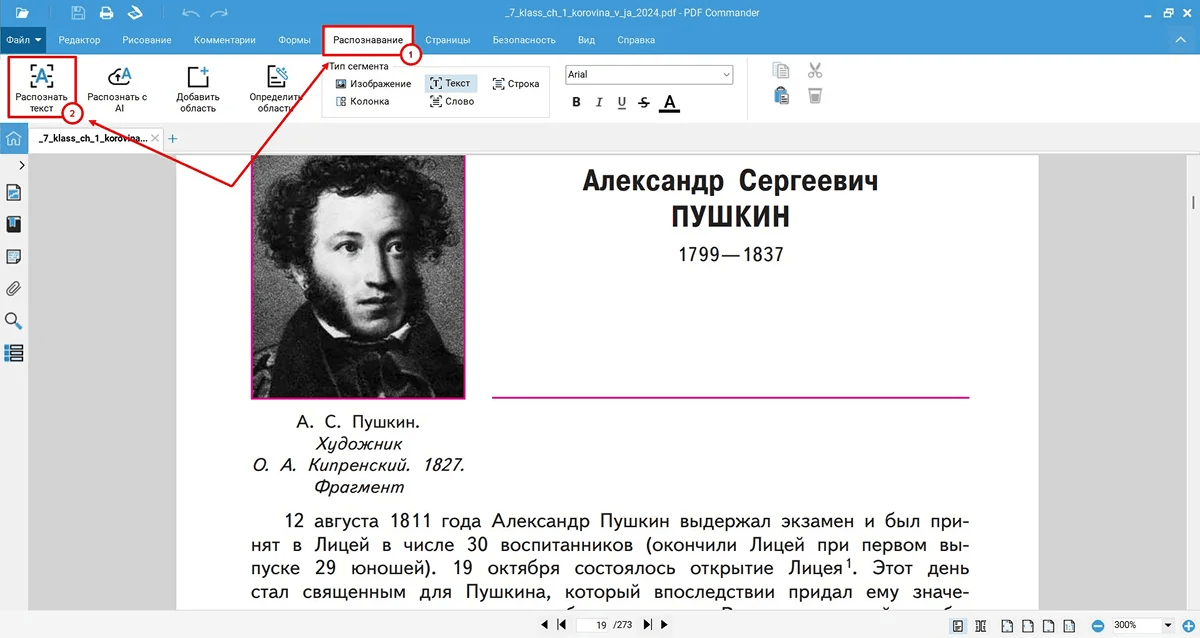
PDF Commander хорошо подходит для русскоязычных документов, потому что интерфейс и названия кнопок понятны без перевода. Для сканов на русском и английском выбираются соответствующие языки. Для отдельных страниц можно обработать текущий лист, все страницы или диапазон. Это удобно, когда в большом PDF нужно распознать только одну главу, приложение к договору или несколько страниц с таблицами.
Что можно сделать после распознавания:
-
скопировать текст из скана;
-
сохранить PDF с текстовым слоем;
-
отредактировать распознанный фрагмент;
-
добавить подпись или штамп;
-
объединить несколько сканов в один PDF;
-
повернуть и выровнять страницы;
-
закрыть файл паролем;
-
экспортировать документ в другой формат.
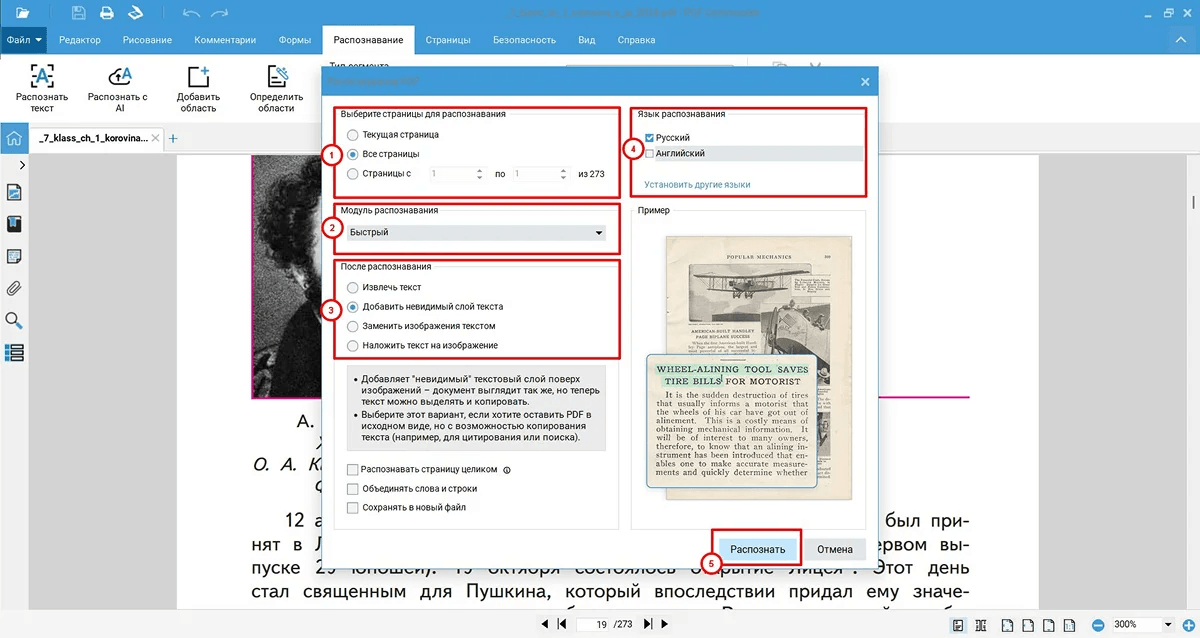
Пошаговая инструкция:
-
Запустите PDF Commander.
-
Нажмите Открыть PDF.
-
Выберите сканированный PDF, фотографию страницы или документ, где текст не выделяется.
-
Перейдите во вкладку Распознавание.
-
Нажмите Распознать текст.
-
Укажите страницы: текущая страница, все страницы или нужный диапазон.
-
Выберите режим распознавания.
-
Отметьте язык документа: русский, английский или оба языка.
-
Выберите результат после распознавания.
-
Нажмите Распознать.
-
Проверьте, выделяется ли текст.
-
Сохраните документ через Файл → Сохранить или Сохранить как.
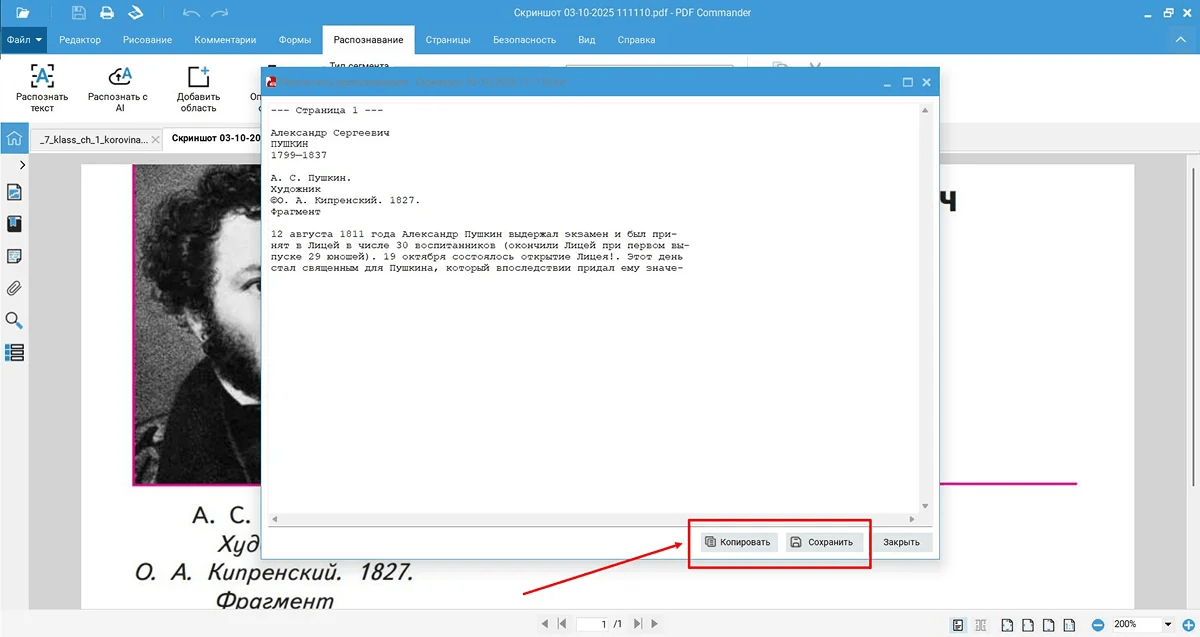
Плюсы:
-
русскоязычный интерфейс;
-
понятная кнопка Распознать текст;
-
подходит для сканов, фото страниц и обычных PDF;
-
можно обработать отдельную страницу или весь документ;
-
есть режим добавления невидимого текстового слоя;
-
после OCR доступны редактирование, подписи, штампы, защита и конвертация;
-
программа работает локально на компьютере;
-
удобно использовать для повседневного документооборота.
Минусы:
-
для сильно поврежденных сканов результат нужно внимательно проверять;
-
рукописный текст требует особенно аккуратного исходника;
-
профессиональная пакетная обработка больших архивов удобнее в специализированных OCR-системах;
-
качество таблиц зависит от четкости линий и структуры исходной страницы.
Лучший сценарий для PDF Commander — офисный PDF на русском языке: договор, акт, справка, скан учебного материала, заявление, счет или многостраничный документ, где нужно быстро получить текст, сохранить внешний вид и сразу продолжить работу в редакторе.
ABBYY FineReader
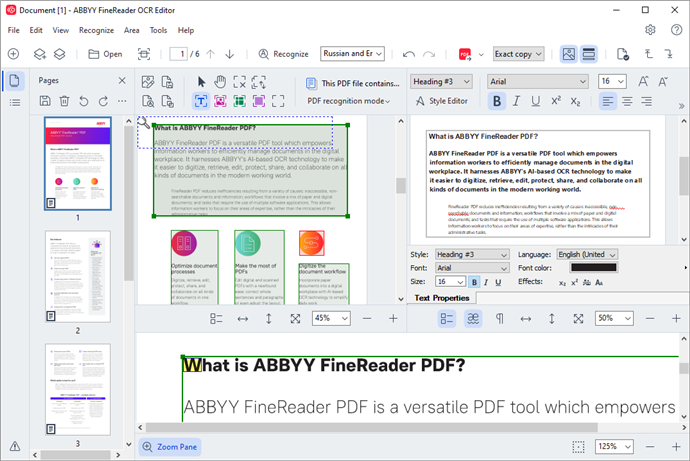
ABBYY FineReader — один из самых сильных вариантов для сложного OCR. Его главное отличие от простых распознавателей в том, что программа не просто извлекает текст, а дает полноценный контроль над документом: области распознавания, языки, таблицы, изображения, порядок блоков, проверка спорных символов, экспорт в офисные форматы и создание searchable PDF.
FineReader особенно хорошо раскрывается на сканах, где важно сохранить структуру: договоры с приложениями, таблицы, прайс-листы, отчеты, инструкции, методички, архивные книги, документы с колонками, печатями и несколькими языками. В OCR Editor страница делится на зоны. Пользователь видит исходное изображение, распознанный текст и может вручную поправить то, что автоматическая разметка определила неверно.
Ключевые задачи:
-
распознать сканированный PDF;
-
преобразовать PDF в Word;
-
перенести таблицу из PDF в Excel;
-
создать PDF с возможностью поиска;
-
проверить ошибки распознавания;
-
восстановить структуру документа;
-
обработать многостраничный файл;
-
сравнить версии документа;
-
подготовить архивный PDF.
Пошаговая инструкция:
-
Откройте ABBYY FineReader.
-
Выберите задачу Открыть PDF или отправьте файл в OCR Editor.
-
Укажите язык документа.
-
Проверьте автоматическую разметку страницы.
-
Для текста используйте текстовые зоны, для таблиц — табличные зоны, для иллюстраций — зоны изображений.
-
Нажмите Recognize.
-
Проверьте результат в текстовой панели.
-
Запустите проверку подозрительных символов.
-
Исправьте ошибки в фамилиях, суммах, датах и номерах.
-
Сохраните результат в DOCX, XLSX, searchable PDF, TXT или другой формат.
Плюсы:
-
сильный OCR для сложных сканов;
-
отдельный OCR Editor;
-
ручная настройка зон распознавания;
-
хорошее сохранение структуры страницы;
-
удобная работа с таблицами;
-
экспорт в Word, Excel, PDF и текстовые форматы;
-
проверка спорных символов;
-
подходит для документов с несколькими языками;
-
удобен для архивов, юридических и бухгалтерских задач.
Минусы:
-
программа тяжелее простых PDF-редакторов;
-
для простого одностраничного скана набор функций избыточен;
-
сложные документы требуют ручной проверки;
-
интерфейс насыщен инструментами и требует привыкания;
-
для максимальной точности нужно контролировать зоны и результат.
FineReader стоит выбирать, когда важна не просто скорость, а качество. Он особенно полезен там, где после OCR документ должен выглядеть как рабочий DOCX или XLSX, а не как набор случайно перенесенных строк.
Adobe Acrobat Pro
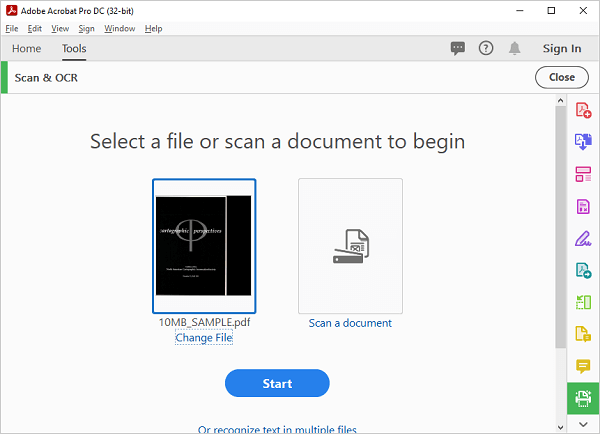
Adobe Acrobat Pro подходит тем, кто работает с PDF как с основным рабочим форматом: создает документы, редактирует страницы, проверяет файлы перед отправкой, подписывает, защищает, комментирует и делает сканы доступными для поиска. OCR здесь встроен в общий блок работы со сканами и PDF.
Главный сценарий — открыть отсканированный PDF и применить Recognize Text. После этого Acrobat создает текстовый слой, благодаря которому документ ищется, выделяется и копируется. Для профессиональной работы важно, что после распознавания можно использовать исправление подозрительных слов, редактировать PDF, применять redaction, добавлять комментарии, объединять документы и сохранять результат в стандартном PDF-потоке.
Acrobat удобен для рабочих документов, которые дальше остаются именно PDF. Когда нужно не столько выгрузить текст в Word, сколько получить аккуратный searchable PDF, этот вариант особенно уместен.
Пошаговая инструкция:
-
Откройте PDF в Adobe Acrobat Pro.
-
Перейдите в раздел Scan & OCR.
-
Выберите Recognize Text.
-
Укажите In This File для текущего документа.
-
Выберите страницы.
-
Укажите язык распознавания.
-
Запустите Recognize Text.
-
После обработки проверьте выделение текста.
-
Используйте Correct Recognized Text для исправления ошибок.
-
Сохраните PDF.
Что удобно делать после OCR:
-
искать слова и номера по документу;
-
выделять и копировать текст;
-
исправлять распознанные фрагменты;
-
комментировать PDF;
-
удалять чувствительные данные через redaction;
-
объединять распознанный документ с другими PDF;
-
подготавливать файл к отправке или архиву.
Плюсы:
-
профессиональная PDF-среда;
-
встроенный OCR для сканированных документов;
-
создание searchable PDF;
-
исправление ошибок распознавания;
-
сильные инструменты редактирования и защиты PDF;
-
хорошая связка с комментариями, подписями и подготовкой документов;
-
подходит для корпоративной работы.
Минусы:
-
интерфейс рассчитан на пользователей, которые регулярно работают с PDF;
-
для простой разовой задачи программа выглядит тяжелой;
-
подписочная модель не всем подходит;
-
для глубокого OCR с ручной разметкой областей FineReader часто удобнее;
-
онлайн-альтернативы быстрее для простых неконфиденциальных файлов.
Adobe Acrobat Pro лучше всего использовать, когда PDF должен остаться PDF: его нужно распознать, проверить, защитить, подписать и передать дальше без конвертации в отдельный офисный документ.
Wondershare PDFelement
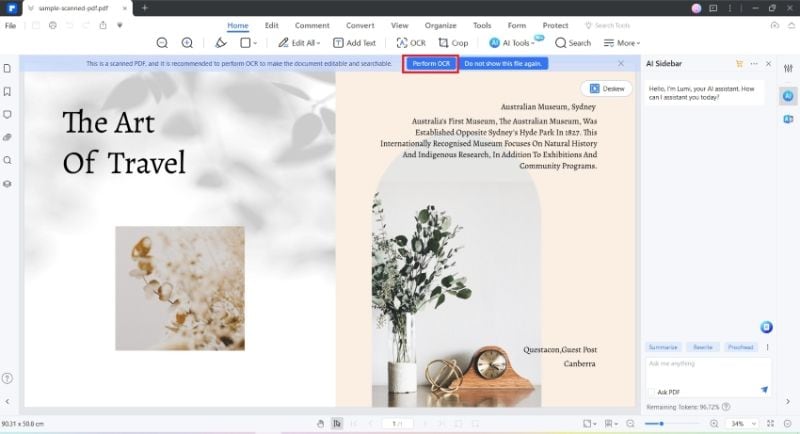
Wondershare PDFelement занимает промежуточное место между простыми PDF-утилитами и профессиональными редакторами. В нем есть OCR для сканированных PDF, редактирование текста, конвертация, работа со страницами, комментарии, формы, защита и экспорт. Для пользователя это удобный вариант, когда нужен не только извлеченный текст, но и дальнейшая правка документа.
OCR в PDFelement полезен в двух сценариях. Первый — сделать сканированный PDF доступным для поиска и копирования. Второй — превратить изображение текста в редактируемый PDF, чтобы исправлять фрагменты прямо на странице. Перед распознаванием выбирается язык, диапазон страниц и режим результата. После обработки можно редактировать текстовые блоки, экспортировать файл в Word или сохранить PDF.
Программа подходит для договоров, резюме, инструкций, учебных сканов, таблиц, счетов и деловых документов средней сложности. Для сложных архивов с большим количеством ошибок FineReader дает больше ручного контроля, но для повседневного PDF-workflow PDFelement достаточно удобен.
Пошаговая инструкция:
-
Откройте PDF в PDFelement.
-
Дождитесь уведомления о сканированном документе или перейдите к OCR вручную.
-
Выберите режим распознавания.
-
Укажите язык документа.
-
Задайте страницы для обработки.
-
Запустите OCR.
-
Проверьте, выделяется ли текст.
-
Перейдите к редактированию или экспорту.
-
Сохраните итоговый PDF.
Плюсы:
-
OCR встроен в PDF-редактор;
-
можно редактировать распознанный текст;
-
есть экспорт в офисные форматы;
-
доступны инструменты страниц, комментариев и защиты;
-
интерфейс проще, чем у некоторых профессиональных решений;
-
подходит для регулярной офисной работы.
Минусы:
-
для сложных таблиц и старых сканов нужна ручная проверка;
-
часть возможностей зависит от редакции;
-
при больших документах обработка занимает заметное время;
-
глубокий контроль зон распознавания уступает специализированным OCR-программам.
PDFelement уместен там, где нужно распознать документ и сразу внести правки в PDF: заменить дату, поправить реквизиты, добавить комментарий, сохранить файл или отправить его в Word.
PDF-XChange Editor
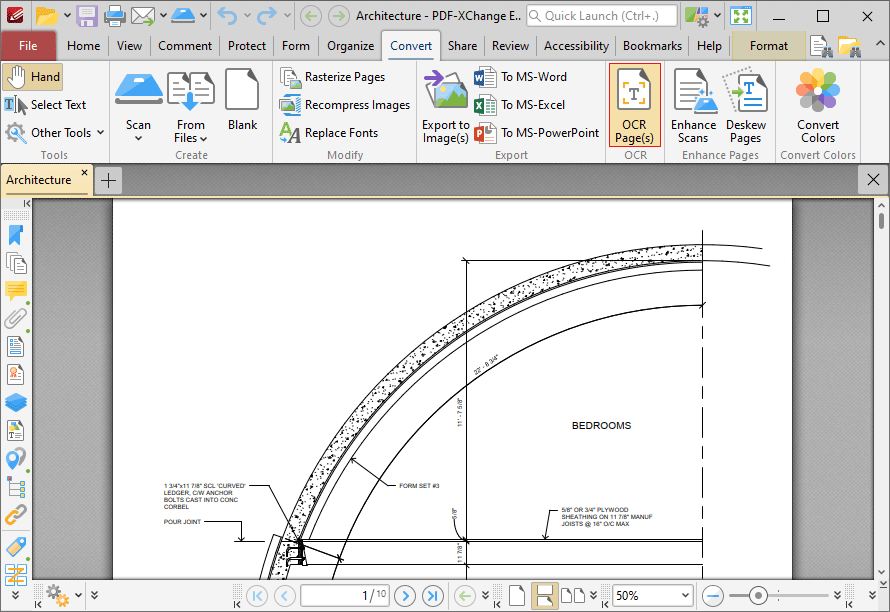
PDF-XChange Editor — мощный PDF-редактор для Windows, где OCR встроен в общий набор инструментов конвертации и обработки документов. Он подходит тем, кто хочет работать с PDF подробно: редактировать текст и объекты, управлять страницами, добавлять комментарии, защищать файлы, создавать формы и делать сканы доступными для поиска.
Для распознавания используется команда OCR Pages. Она находится на вкладке Convert. После запуска открывается диалог с выбором страниц, языка, точности, типа результата и дополнительных параметров. Для сканов важны опции определения перекоса, исправления неправильного поворота, игнорирования уже существующего текста, комментариев и полей формы. Благодаря этому OCR можно настроить под реальный документ, а не запускать одной слепой кнопкой.
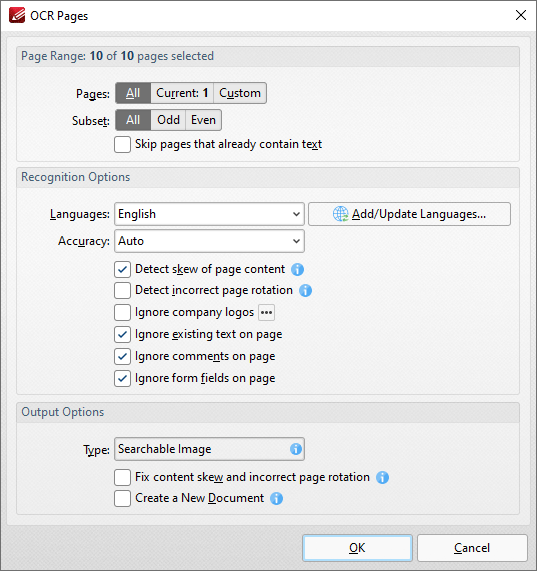
PDF-XChange Editor создает поисковый слой поверх изображения страницы. В расширенной редакции доступен Enhanced OCR, который лучше подходит для распознавания таблиц, стилей текста и более аккуратного результата. Для обычного searchable PDF хватает базового OCR. Для редактируемого вывода и сложных документов сильнее раскрывается версия Plus.
Пошаговая инструкция:
-
Откройте PDF в PDF-XChange Editor.
-
Перейдите на вкладку Convert.
-
Нажмите OCR Pages.
-
Выберите диапазон страниц.
-
Укажите язык распознавания.
-
Настройте Accuracy.
-
Отметьте Detect skew of page content для перекошенных сканов.
-
Выберите тип результата Searchable Image.
-
Нажмите OK.
-
Проверьте поиск по тексту через Ctrl+F.
-
Сохраните документ.
Плюсы:
-
сильный настольный PDF-редактор для Windows;
-
OCR Pages находится прямо на вкладке Convert;
-
есть выбор страниц, языка и точности;
-
можно включить исправление перекоса и поворота;
-
подходит для создания searchable PDF;
-
расширенный OCR работает с таблицами и стилями текста;
-
много инструментов для дальнейшей PDF-обработки.
Минусы:
-
интерфейс насыщен и требует привыкания;
-
часть продвинутых возможностей доступна в платных редакциях;
-
новичку проще начать с PDF Commander;
-
для глубокого OCR-контроля FineReader остается более специализированным решением.
PDF-XChange Editor лучше выбирать тогда, когда OCR — только одна часть работы. Например, нужно распознать скан, потом переставить страницы, добавить комментарии, защитить файл, сделать закладки и сохранить итоговый PDF.
NAPS2
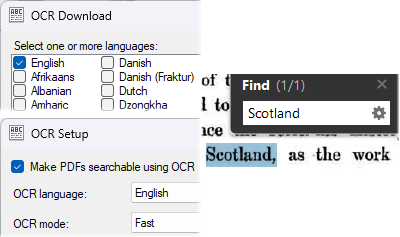
NAPS2 отличается от обычных PDF-редакторов тем, что в первую очередь предназначен для сканирования. Это удобная программа для ситуаций, когда бумажные документы нужно сразу превратить в аккуратный PDF: отсканировать, повернуть, обрезать, собрать страницы, включить OCR и сохранить searchable PDF.
OCR в NAPS2 не превращает программу в тяжелый PDF-редактор, но делает ее отличным инструментом для оцифровки. На панели есть кнопка OCR, через которую загружаются языки и включается параметр Make PDFs searchable using OCR. После этого сохраненные PDF получают текстовый слой для поиска. Для архива договоров, бухгалтерии, учебных материалов и личных документов это очень удобно: файлы остаются визуально такими же, но начинают находиться по словам, датам и номерам.
NAPS2 хорошо работает в связке со сканером. Можно настроить профили под разные типы документов: черно-белый текст, цветные удостоверения, серые договоры, многостраничные пачки через автоподатчик. После сканирования страницы можно переставить, повернуть, кадрировать и сохранить.
Пошаговая инструкция:
-
Откройте NAPS2.
-
Настройте профиль сканирования через Profiles.
-
Укажите сканер, источник подачи, DPI и цветовой режим.
-
Нажмите Scan или импортируйте готовый PDF.
-
Нажмите OCR.
-
Загрузите нужный язык.
-
Включите Make PDFs searchable using OCR.
-
Выберите язык распознавания.
-
Сохраните файл через Save PDF.
-
Проверьте поиск по документу.
Плюсы:
-
отличный инструмент для сканирования документов;
-
есть профили сканера;
-
поддерживается OCR для searchable PDF;
-
можно работать с автоподатчиком;
-
есть поворот, кадрирование и порядок страниц;
-
подходит для бумажных архивов;
-
не перегружен лишними PDF-функциями;
-
удобен для регулярной оцифровки.
Минусы:
-
это не полноценный PDF-редактор;
-
редактирование распознанного текста ограничено;
-
для сложного экспорта в Word и Excel нужны другие программы;
-
качество OCR зависит от выбранных языков и качества скана;
-
первое включение OCR требует загрузки языковых данных.
NAPS2 стоит использовать, когда основной процесс начинается со сканера. Для уже готового PDF, который нужно серьезно редактировать, лучше взять PDF Commander, FineReader, Acrobat или PDF-XChange Editor. Для поточной оцифровки бумажных документов NAPS2 очень практичен.
Readiris Pro
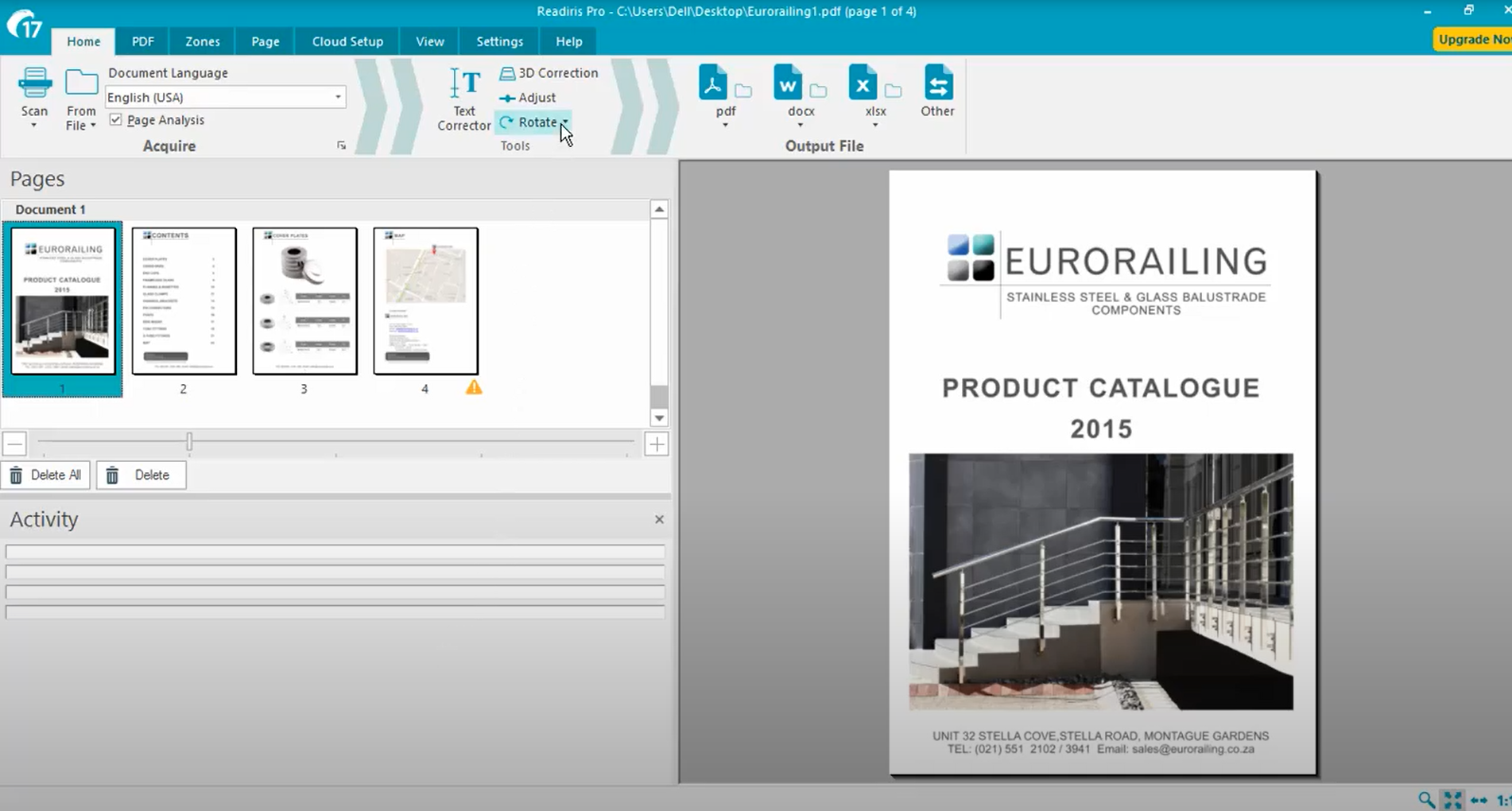
Readiris Pro — специализированная OCR-программа для сканов, изображений и PDF. Она рассчитана не только на извлечение текста, но и на восстановление структуры страницы. В рабочем окне важны три зоны: импорт, выбор языка и выходной формат. Программа анализирует страницу, выделяет текст, изображения и таблицы, затем сохраняет результат в Word, Excel, PDF, TXT и другие форматы.
Readiris удобен для тех, кто постоянно переводит бумажные документы в цифровой вид. Он подходит для счетов, актов, инструкций, книг, таблиц, архивных сканов и фотографий страниц. В отличие от простых онлайн-сервисов, здесь можно контролировать макет, корректировать изображение и готовить документ к экспорту.
Особенно полезен режим searchable PDF, где сохраняется исходный вид страницы и добавляется текстовый слой. Такой формат подходит для электронного архива: документ выглядит как оригинал, но ищется по словам и номерам.
Пошаговая инструкция:
-
Запустите Readiris Pro.
-
Нажмите From File или Scan.
-
Откройте PDF, изображение или получите страницу со сканера.
-
Выберите Document Language.
-
Проверьте зоны распознавания.
-
Для таблиц убедитесь, что область определена как таблица.
-
Выберите выходной формат: DOCX, XLSX, PDF Image-Text, TXT.
-
Запустите обработку.
-
Проверьте результат.
-
Сохраните файл.
Плюсы:
-
программа ориентирована именно на OCR;
-
поддерживает разные типы документов;
-
умеет сохранять структуру страницы;
-
подходит для Word, Excel и searchable PDF;
-
есть работа с зонами;
-
удобна для сканера и готовых файлов;
-
хороша для регулярной оцифровки.
Минусы:
-
интерфейс выглядит более техническим, чем у простых PDF-редакторов;
-
для редактирования PDF как документа удобнее PDF Commander или Acrobat;
-
сложные страницы требуют проверки зон;
-
для разового распознавания онлайн-сервис быстрее.
Readiris Pro хорош там, где нужен управляемый OCR-процесс: открыть скан, проверить зоны, выбрать правильный формат, сохранить результат и использовать его в работе.
CuneiForm
CuneiForm — более старый и простой инструмент для распознавания печатного текста. Его стоит рассматривать как легкое решение для базовых OCR-задач, когда нужно получить текст из изображения или скана без тяжелого PDF-комбайна. Программа больше подходит для простых документов, чем для современных сложных PDF с таблицами, формами, многоуровневой версткой и большим количеством графики.
CuneiForm полезен в случаях, где исходник простой: черный печатный текст на светлом фоне, ровная страница, без сложных колонок и нестандартного оформления. Для старых архивных документов или неидеальных копий результат нуждается в вычитке. Для сложной работы с PDF удобнее использовать программы, где OCR связан с редактором и экспортом.
Пошаговая инструкция:
-
Подготовьте изображение или скан.
-
Откройте файл в CuneiForm.
-
Укажите язык документа.
-
Запустите распознавание.
-
Просмотрите полученный текст.
-
Исправьте ошибки.
-
Сохраните результат в текстовый или поддерживаемый редактором формат.
-
При необходимости перенесите текст в Word или другой редактор.
Плюсы:
-
подходит для простого печатного текста;
-
не перегружен современными PDF-функциями;
-
может использоваться как легкий OCR-инструмент;
-
удобен для базового извлечения текста;
-
полезен на старых компьютерах и в простых сценариях.
Минусы:
-
не подходит для сложной PDF-верстки;
-
не является полноценным PDF-редактором;
-
хуже справляется с таблицами, колонками и плохими сканами;
-
интерфейс и рабочий процесс уступают современным OCR-программам;
-
после распознавания почти всегда нужна вычитка.
CuneiForm стоит рассматривать не как универсальный способ, а как простой OCR-вариант для печатного текста. Для ответственных документов лучше выбирать PDF Commander, FineReader, Acrobat, PDF-XChange Editor или Readiris.
Scanitto Pro
Scanitto Pro относится к программам для сканирования документов. Ее удобно использовать, когда исходник пока находится на бумаге: договор, заявление, паспортная копия, акт, счет, учебная страница или архивный лист. Основная логика здесь такая: получить изображение со сканера, обработать страницу, сохранить в нужный формат и использовать OCR для извлечения текста.
Scanitto Pro подходит пользователям, которым не нужен большой PDF-редактор, но нужно удобное рабочее место для сканирования. Такой подход особенно хорош для домашнего архива, небольшого офиса, бухгалтерии и административных задач. Перед OCR можно настроить качество сканирования, цветовой режим и параметры выходного файла.
Пошаговая инструкция:
-
Подключите сканер.
-
Запустите Scanitto Pro.
-
Выберите устройство сканирования.
-
Укажите режим: цветной, оттенки серого или черно-белый.
-
Задайте разрешение.
-
Отсканируйте страницу.
-
Проверьте качество изображения.
-
Запустите распознавание.
-
Сохраните результат в PDF или текстовый формат.
-
Проверьте распознанные данные.
Плюсы:
-
удобна для работы со сканером;
-
подходит для бумажных документов;
-
позволяет быстро получить PDF из листов;
-
рабочий процесс проще, чем в тяжелых PDF-редакторах;
-
полезна для домашней и офисной оцифровки;
-
можно настроить качество сканирования до распознавания.
Минусы:
-
не заменяет полноценный PDF-редактор;
-
OCR-функции уступают специализированным системам уровня FineReader;
-
для сложных таблиц и многоязычных документов нужна проверка;
-
работа привязана к качеству сканера и исходной бумаги.
Scanitto Pro подходит для прямого пути от бумаги к цифровому файлу. Когда документ уже существует как PDF и его нужно активно редактировать, удобнее использовать PDF Commander или другой PDF-редактор.
PDF24 Creator
PDF24 Creator и PDF24 Tools закрывают два разных сценария. Настольный PDF24 Creator устанавливается на Windows и подходит для локальной работы с PDF. Онлайн-инструмент PDF24 OCR работает в браузере и создает searchable PDF без установки программы.
Для распознавания в браузере пользователь загружает PDF, выбирает язык, указывает дополнительные настройки и запускает Start OCR. Сервис создает PDF с текстовым слоем. В настройках доступны PDF или PDF/A, очистка страниц, удаление артефактов, выравнивание перекоса, поворот страниц, принудительное OCR и объединение файлов. Это полезно, когда нужно быстро сделать скан доступным для поиска.
PDF24 хорош для документов без высокой конфиденциальности: учебные материалы, инструкции, публичные PDF, личные заметки, сканы без персональных данных. Для договоров, паспортов, медицинских документов, кадровых файлов и бухгалтерии безопаснее использовать локальные программы.
Пошаговая инструкция для онлайн OCR:
-
Откройте инструмент PDF OCR в PDF24 Tools.
-
Нажмите Choose files.
-
Загрузите PDF.
-
Выберите язык документа.
-
Укажите Output type: PDF или PDF/A.
-
Включите Deskew pages для перекошенных сканов.
-
Включите Clean pages для шумных страниц.
-
Нажмите Start OCR.
-
Скачайте готовый searchable PDF.
-
Проверьте поиск по документу.
Плюсы:
-
работает в браузере;
-
не требует установки;
-
создает PDF с возможностью поиска;
-
есть настройки очистки, поворота и выравнивания;
-
можно сохранить PDF/A;
-
подходит для быстрых задач;
-
доступен на разных операционных системах.
Минусы:
-
файл загружается на сервер;
-
не лучший вариант для конфиденциальных документов;
-
редактирование распознанного текста ограничено;
-
качество сложных таблиц требует проверки;
-
обработка больших файлов занимает время.
PDF24 удобно использовать как быстрый онлайн-способ: загрузил PDF, выбрал язык, получил searchable PDF. Для системной работы с документами лучше настольные программы.
Как распознать текст в PDF на macOS
Adobe Acrobat Pro для macOS
На macOS Adobe Acrobat Pro работает по той же логике, что и в Windows: открыть PDF, перейти в Scan & OCR, запустить распознавание, выбрать язык и сохранить searchable PDF. Для пользователей Mac это удобный вариант, когда нужно остаться внутри профессиональной PDF-среды и не разносить задачи по разным приложениям.
Acrobat полезен для договоров, отчетов, презентационных PDF, сканов, документов с комментариями и файлов, которые дальше нужно подписывать, защищать или отправлять коллегам. После OCR можно искать по документу, копировать текст, редактировать распознанные фрагменты и использовать инструменты подготовки PDF.
Пошаговая инструкция:
-
Откройте PDF в Acrobat Pro на Mac.
-
Перейдите в Scan & OCR.
-
Нажмите Recognize Text.
-
Выберите текущий файл.
-
Укажите страницы.
-
Задайте язык распознавания.
-
Запустите обработку.
-
Проверьте результат через поиск.
-
Исправьте ошибки распознавания.
-
Сохраните документ.
Плюсы:
-
полноценная PDF-среда на macOS;
-
OCR встроен в профессиональный рабочий процесс;
-
удобно делать searchable PDF;
-
есть редактирование, комментарии, защита и подписи;
-
подходит для корпоративного документооборота.
Минусы:
-
подписочная модель;
-
для разового OCR программа слишком тяжелая;
-
сложные сканы нужно проверять вручную;
-
для глубокой разметки зон FineReader удобнее.
Acrobat на Mac стоит выбирать, когда PDF нужно не просто распознать, а довести до готового рабочего состояния: проверить, подписать, защитить, отправить и сохранить.
ABBYY FineReader для macOS
На macOS ABBYY FineReader остается одним из лучших решений для сложного распознавания. Он подходит для пользователей, которые регулярно работают со сканами, PDF без текстового слоя, таблицами, документами на нескольких языках и архивными файлами.
Главная ценность FineReader на Mac — качество результата и контроль. Программа распознает документ, сохраняет структуру, позволяет проверять спорные места и экспортировать итог в Word, Excel или PDF с поиском. Для учебных материалов, юридических документов, бухгалтерских таблиц и старых архивов это один из самых надежных вариантов.
Пошаговая инструкция:
-
Запустите FineReader.
-
Откройте PDF или изображение.
-
Выберите язык документа.
-
Запустите OCR.
-
Проверьте зоны распознавания.
-
Исправьте ошибки.
-
Сохраните результат как DOCX, XLSX или searchable PDF.
Плюсы:
-
качественное распознавание текста;
-
хороший экспорт в Word и Excel;
-
подходит для таблиц и сложных страниц;
-
можно проверять результат до сохранения;
-
удобно использовать для архивов и документов с высокой ценностью.
Минусы:
-
избыточен для простых файлов;
-
требует внимательности на сложных сканах;
-
не всегда нужен пользователю, которому достаточно быстро получить текст;
-
профессиональные возможности требуют времени на освоение.
FineReader на macOS особенно уместен, когда документ после OCR должен быть пригоден для редактирования, а не только для поиска.
Preview
Preview не является полноценной OCR-программой уровня FineReader или Acrobat, но в рабочем процессе распознавания она все равно полезна. Через Preview удобно открыть PDF, проверить ориентацию страниц, посмотреть качество, сделать базовую разметку, экспортировать страницу, повернуть лист или подготовить файл перед передачей в OCR-инструмент.
На современных версиях macOS текст на изображениях часто можно выделять прямо в системном просмотре благодаря встроенным возможностям распознавания текста в изображениях. Это удобно для быстрых фрагментов: скопировать телефон, адрес, короткую цитату или подпись на скриншоте. Для полноценного многостраничного OCR, создания searchable PDF и экспорта таблиц нужны специализированные программы.
Пошаговый рабочий сценарий:
-
Откройте PDF в Preview.
-
Проверьте, выделяется ли текст.
-
Поверните страницы в правильную ориентацию.
-
Удалите лишние страницы.
-
Экспортируйте документ при необходимости.
-
Передайте файл в Acrobat, FineReader или онлайн OCR.
-
После распознавания снова откройте PDF и проверьте поиск.
Плюсы:
-
встроен в macOS;
-
быстро открывает PDF и изображения;
-
удобен для просмотра и подготовки;
-
можно повернуть и проверить страницы;
-
подходит для быстрых фрагментов текста на изображениях;
-
не требует отдельной установки.
Минусы:
-
не заменяет полноценный OCR-редактор;
-
не лучший вариант для многостраничных сканов;
-
нет развитой разметки зон;
-
экспорт таблиц и сложного макета нужно делать в других программах.
Preview стоит воспринимать как подготовительный и проверочный инструмент. Он помогает оценить PDF и привести его в порядок перед настоящим OCR.
Как сделать OCR в PDF онлайн
Google Drive и Google Docs
Google Drive и Google Docs позволяют быстро вытащить текст из PDF или изображения без установки программ. Сценарий простой: файл загружается в Drive, затем открывается через Google Docs. В созданном документе сверху обычно остается изображение страницы, а ниже появляется распознанный текст.
Этот способ удобен для простых документов: фотографий страниц, сканов без сложной верстки, одностраничных PDF, учебных фрагментов, заметок и материалов без конфиденциальных данных. Для таблиц, колонок, сложных форм и длинных PDF результат нужно проверять особенно внимательно. Форматирование может заметно отличаться от оригинала.
Пошаговая инструкция:
-
Откройте Google Drive.
-
Загрузите PDF или изображение.
-
Нажмите правой кнопкой по файлу.
-
Выберите Открыть с помощью → Google Документы.
-
Дождитесь создания документа.
-
Проверьте распознанный текст.
-
Удалите лишнее изображение сверху, когда нужен только текст.
-
Скачайте результат как DOCX или TXT через Файл → Скачать.
Плюсы:
-
не нужно устанавливать программу;
-
удобно для простых файлов;
-
работает в браузере;
-
результат сразу открывается как редактируемый документ;
-
подходит для быстрого извлечения текста;
-
можно сохранить в DOCX.
Минусы:
-
файл загружается в облако;
-
не подходит для конфиденциальных документов;
-
форматирование сохраняется ограниченно;
-
таблицы и колонки требуют ручной правки;
-
крупные и сложные PDF обрабатываются хуже;
-
результат не создает автоматически полноценный searchable PDF поверх исходника.
Google Drive хорош как быстрый способ получить текст. Для юридически важных файлов, паспортов, договоров и бухгалтерских документов лучше использовать локальное приложение.
OneNote
OneNote удобен не как полноценный PDF-редактор, а как быстрый способ вытащить текст из картинки, скриншота или вставленной распечатки. В заметку можно добавить изображение или файл, затем использовать команду копирования текста с картинки.
Этот способ подходит для коротких фрагментов: цитата из учебника, текст со скриншота, кусок инструкции, распечатанная страница, номер из документа. OneNote не лучший вариант для аккуратного многостраничного PDF с сохранением макета, но для заметок и быстрого копирования он очень удобен.
Пошаговая инструкция:
-
Откройте OneNote.
-
Создайте новую страницу.
-
Вставьте изображение или распечатку PDF.
-
Щелкните по картинке правой кнопкой мыши.
-
Выберите команду копирования текста с рисунка.
-
Вставьте текст в заметку, Word или другой редактор.
-
Проверьте ошибки и переносы строк.
Плюсы:
-
удобен для быстрых фрагментов;
-
хорошо вписывается в работу с заметками;
-
не требует отдельной OCR-программы;
-
подходит для скриншотов и картинок;
-
результат можно сразу вставить в заметку;
-
простой рабочий процесс.
Минусы:
-
не предназначен для полноценной обработки PDF;
-
не сохраняет исходный макет как OCR-редактор;
-
таблицы распознаются ограниченно;
-
многостраничные документы удобнее обрабатывать в других программах;
-
результат требует проверки.
OneNote стоит использовать, когда нужен текст здесь и сейчас: скопировать абзац с картинки, вытащить фразу из скриншота, сохранить текстовую заметку по учебному материалу.
PDF24 Tools

PDF24 Tools — один из самых удобных онлайн-способов создать searchable PDF. Инструмент работает в браузере: пользователь загружает PDF, выбирает язык, включает дополнительные параметры и скачивает готовый файл. Важное отличие от простых текстовых экстракторов: результатом становится именно PDF с текстовым слоем, а не только отдельный текст.
На странице OCR доступны настройки языка, PDF/PDF-A, удаления фона, поворота страниц, выравнивания перекоса, очистки страниц, принудительного распознавания и объединения файлов. Для плохих сканов особенно полезны Deskew pages и Clean pages. Для архивов — PDF/A.
Пошаговая инструкция:
-
Откройте PDF24 OCR в браузере.
-
Перетащите PDF в область загрузки.
-
Выберите язык.
-
Укажите тип результата PDF или PDF/A.
-
Включите очистку и выравнивание при необходимости.
-
Нажмите Start OCR.
-
Скачайте итоговый файл.
-
Проверьте поиск по тексту.
Плюсы:
-
бесплатный онлайн-инструмент;
-
не требует регистрации для базового сценария;
-
создает searchable PDF;
-
есть настройки очистки и выравнивания;
-
работает на разных платформах;
-
подходит для простых и средних документов.
Минусы:
-
документ передается на сервер;
-
не подходит для строго конфиденциальных файлов;
-
сложные таблицы требуют проверки;
-
редактирование текста после OCR ограничено;
-
большие документы обрабатываются дольше.
PDF24 Tools удобен для быстрых неконфиденциальных PDF, которые нужно сделать доступными для поиска.
iLovePDF
iLovePDF — популярный онлайн-набор инструментов для PDF, в котором есть отдельная функция OCR PDF. Она превращает невыделяемый PDF в документ, где текст можно искать и выделять. Пользователь загружает файл, выбирает языки документа и запускает обработку.
Этот способ хорошо подходит для простых сканов, учебных материалов, инструкций, брошюр и документов, где не требуется локальная обработка. Правильный выбор языка повышает качество результата. Для русско-английских документов нужно отмечать оба языка.
Пошаговая инструкция:
-
Откройте OCR PDF в iLovePDF.
-
Нажмите Select PDF file.
-
Загрузите документ.
-
В блоке Document languages выберите язык или несколько языков.
-
Запустите OCR.
-
Дождитесь обработки.
-
Скачайте PDF.
-
Проверьте выделение и поиск.
Плюсы:
-
удобный интерфейс;
-
быстрое создание searchable PDF;
-
можно выбрать языки документа;
-
работает в браузере;
-
подходит для простых сканов;
-
не требует установки настольной программы.
Минусы:
-
файл загружается в облако;
-
бесплатный режим имеет ограничения;
-
конфиденциальные документы лучше обрабатывать локально;
-
сложные таблицы и колонки требуют проверки;
-
результат зависит от качества скана и выбранных языков.
iLovePDF удобен для быстрого браузерного OCR, когда важна скорость и не требуется глубокое редактирование результата.
Smallpdf
Smallpdf подходит для пользователей, которым нужен простой онлайн-интерфейс и быстрый результат. Сервис ориентирован на массовые PDF-задачи: сжатие, объединение, конвертация, редактирование и распознавание в рамках доступных инструментов.
Для OCR Smallpdf полезен в ситуациях, где нужно быстро получить текстовый слой или конвертировать сканированный PDF в редактируемый формат. После загрузки файла сервис проводит обработку и дает скачать результат. Сложные документы с таблицами и большим количеством колонок нужно проверять вручную.
Пошаговая инструкция:
-
Откройте Smallpdf.
-
Выберите инструмент для OCR или конвертации сканированного PDF.
-
Загрузите файл.
-
Укажите нужный результат.
-
Запустите обработку.
-
Скачайте готовый документ.
-
Проверьте текст и форматирование.
Плюсы:
-
понятный онлайн-интерфейс;
-
много PDF-инструментов в одном месте;
-
подходит для быстрых задач;
-
не требует установки;
-
удобен для простых документов.
Минусы:
-
файл обрабатывается в облаке;
-
бесплатный режим ограничен;
-
точность сложных сканов нужно проверять;
-
не подходит для конфиденциальных документов;
-
глубокого контроля OCR меньше, чем в настольных программах.
Smallpdf лучше использовать как быстрый онлайн-инструмент, а не как основной OCR-центр для важных архивов.
PDF Candy
PDF Candy — онлайн-сервис для работы с PDF, где OCR используется для превращения сканов в текстовые или доступные для поиска документы. Его удобно применять для учебных страниц, простых договоров, инструкций и небольших PDF, которые нужно быстро обработать в браузере.
Рабочий процесс похож на другие онлайн-инструменты: загрузка файла, выбор настроек, запуск обработки и скачивание результата. Для PDF с таблицами важно после распознавания проверить порядок строк и ячеек. Для документов с персональными данными лучше выбрать локальную программу.
Пошаговая инструкция:
-
Откройте PDF Candy.
-
Выберите OCR PDF или инструмент распознавания.
-
Загрузите файл.
-
Укажите язык документа.
-
Запустите обработку.
-
Скачайте результат.
-
Проверьте текст.
Плюсы:
-
работает онлайн;
-
подходит для быстрых задач;
-
есть набор сопутствующих PDF-инструментов;
-
не требует установки;
-
удобен для простых сканов.
Минусы:
-
облачная обработка не подходит для приватных документов;
-
сложные страницы требуют проверки;
-
бесплатный режим ограничен;
-
редактирование после OCR удобнее в настольных программах.
PDF Candy стоит использовать для разового онлайн-распознавания, когда документ не содержит чувствительных данных.
Online OCR
Online OCR — простой сервис для извлечения текста из PDF и изображений. Он удобен, когда не нужно сохранять исходный вид страницы, а нужен сам текст или документ в редактируемом формате. Обычно пользователь загружает файл, выбирает язык, выбирает выходной формат и скачивает результат.
Сервис особенно удобен для небольших PDF, сканов страниц, учебных фрагментов и картинок с печатным текстом. Для многостраничных документов, конфиденциальных данных и сложных таблиц лучше использовать локальные OCR-программы.
Пошаговая инструкция:
-
Откройте Online OCR.
-
Загрузите PDF или изображение.
-
Выберите язык.
-
Укажите формат вывода: DOCX, XLSX или TXT.
-
Запустите распознавание.
-
Скачайте результат.
-
Проверьте ошибки и переносы строк.
Плюсы:
-
простой рабочий процесс;
-
подходит для быстрого извлечения текста;
-
есть выбор языка;
-
можно получить Word, Excel или TXT;
-
не требует установки.
Минусы:
-
файл передается в онлайн-сервис;
-
есть ограничения по размеру и количеству страниц;
-
сложная верстка переносится неидеально;
-
таблицы нуждаются в проверке;
-
не подходит для закрытых документов.
Online OCR удобен как быстрый конвертер: загрузить, выбрать язык, получить текст. Для серьезной PDF-обработки он уступает настольным программам.
Как сделать распознавание текста в PDF на Android и iOS
Adobe Scan
Adobe Scan — мобильное приложение для съемки бумажных документов камерой телефона. Оно автоматически определяет границы страницы, выравнивает изображение, улучшает читаемость и сохраняет результат в PDF. OCR используется для того, чтобы текст внутри скана можно было искать и копировать в экосистеме Adobe.
Приложение удобно для чеков, договоров, заметок, страниц учебников, визиток, справок и бумажных материалов, которые нужно быстро перенести в цифровой вид. Главный плюс телефона — скорость: документ можно распознать сразу после съемки, не используя отдельный сканер.
Пошаговая инструкция:
-
Откройте Adobe Scan.
-
Наведите камеру на документ.
-
Дождитесь определения границ.
-
Сделайте снимок.
-
Проверьте обрезку.
-
Примените улучшение изображения.
-
Сохраните PDF.
-
Откройте файл и проверьте распознанный текст.
Плюсы:
-
удобно сканировать с телефона;
-
автоматически находит границы страницы;
-
улучшает изображение;
-
сохраняет PDF;
-
подходит для быстрых документов;
-
хорошо работает в связке с Adobe Acrobat.
Минусы:
-
качество зависит от камеры и освещения;
-
для длинных документов телефон менее удобен, чем сканер;
-
конфиденциальные файлы завязаны на облачный сценарий;
-
сложные таблицы нужно проверять;
-
для глубокой PDF-правки нужен настольный редактор.
Adobe Scan хорош для мобильного захвата документов. Для окончательной проверки и редактирования распознанный PDF удобнее открыть на компьютере.
Microsoft Lens

Microsoft Lens подходит для съемки документов, досок, визиток и распечаток. Приложение выравнивает изображение, обрезает страницу и сохраняет результат в PDF, Word, PowerPoint, OneNote или OneDrive. Для OCR особенно удобен экспорт в Word и связка с OneNote.
Lens хорошо подходит студентам, преподавателям, офисным пользователям и тем, кто хранит документы в Microsoft 365. Сфотографированную страницу можно быстро превратить в редактируемый документ или отправить в заметки.
Пошаговая инструкция:
-
Откройте Microsoft Lens.
-
Выберите режим Document.
-
Сфотографируйте страницу.
-
Проверьте границы.
-
Подтвердите снимок.
-
Выберите формат сохранения.
-
Для текста используйте Word или OneNote.
-
Проверьте распознанный результат.
Плюсы:
-
хорошо подходит для документов и досок;
-
есть автоматическое выравнивание;
-
удобная интеграция с Word, OneNote и OneDrive;
-
можно быстро получить редактируемый текст;
-
подходит для учебы и работы.
Минусы:
-
результат зависит от освещения и четкости снимка;
-
большие документы удобнее сканировать на сканере;
-
сложные таблицы требуют ручной проверки;
-
для полного PDF-редактирования нужен отдельный редактор.
Microsoft Lens удобно использовать в мобильном рабочем процессе Microsoft: снял страницу, отправил в Word или OneNote, отредактировал текст.
CamScanner
CamScanner — мобильное приложение для сканирования документов камерой. Оно помогает быстро получить PDF из бумажных листов, улучшить контраст, выровнять страницу, объединить несколько снимков и использовать OCR для извлечения текста. Приложение часто выбирают для мобильной работы с документами: чеков, актов, договоров, заметок, учебных страниц и визиток.
CamScanner силен именно как карманный сканер. Документ можно сфотографировать, обрезать, улучшить и сохранить в PDF без компьютера. OCR полезен для поиска и копирования текста, но важные документы все равно требуют проверки.
Пошаговая инструкция:
-
Откройте CamScanner.
-
Нажмите кнопку сканирования.
-
Сфотографируйте страницу.
-
Проверьте автоматическую обрезку.
-
Выберите фильтр улучшения.
-
Добавьте остальные страницы.
-
Запустите распознавание.
-
Сохраните PDF или скопируйте текст.
Плюсы:
-
удобное мобильное сканирование;
-
автоматическая обрезка страниц;
-
улучшение читаемости;
-
объединение нескольких страниц;
-
OCR для копирования текста;
-
подходит для документов в дороге.
Минусы:
-
качество зависит от камеры;
-
бесплатный режим имеет ограничения;
-
для приватных документов нужно внимательно оценивать облачную обработку;
-
сложные таблицы распознаются неидеально;
-
настольные OCR-программы дают больше контроля.
CamScanner удобен для быстрого сканирования, когда рядом нет компьютера и сканера.
Google Lens

Google Lens удобен для распознавания текста с картинки, экрана, вывески, страницы книги или бумажного документа. Он не является PDF-редактором, но отлично решает задачу быстрого извлечения текста с изображения. Пользователь наводит камеру, выбирает текст и копирует его.
Этот способ подходит для коротких фрагментов: абзац из книги, номер, адрес, заметка, текст с плаката, фрагмент инструкции. Для многостраничного PDF и сохранения структуры нужен другой инструмент.
Пошаговая инструкция:
-
Откройте Google Lens.
-
Наведите камеру на текст или выберите изображение.
-
Перейдите в режим Text.
-
Выделите нужный фрагмент.
-
Нажмите Copy text.
-
Вставьте результат в заметку, документ или сообщение.
-
Проверьте ошибки.
Плюсы:
-
очень быстрый способ для фрагментов;
-
работает с камерой и готовыми изображениями;
-
удобно копировать отдельные строки;
-
подходит для переводов и поиска;
-
не требует подготовки PDF.
Минусы:
-
не создает полноценный searchable PDF;
-
не подходит для длинных документов;
-
форматирование почти не сохраняется;
-
таблицы и сложные страницы неудобны;
-
важные данные нужно проверять вручную.
Google Lens — лучший вариант для мгновенного извлечения небольшого текста, а не для полноценной OCR-обработки PDF.
Linux и открытые инструменты
Tesseract
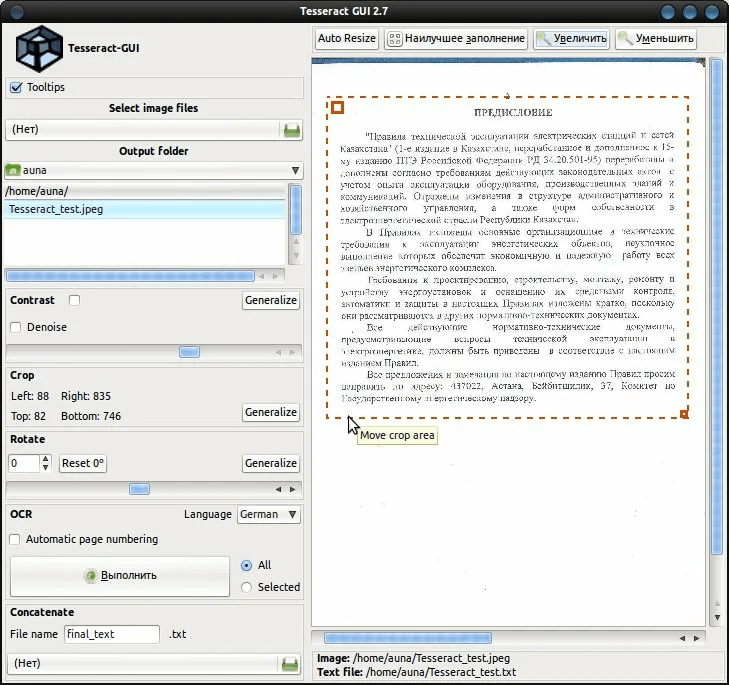
Tesseract — открытый OCR-движок, который часто используют в технических сценариях: автоматизация, пакетная обработка, скрипты, серверная обработка изображений, интеграция в собственные инструменты. Это не привычный PDF-редактор с кнопками, а движок распознавания, который работает через командную строку или через графические оболочки.
Tesseract подходит для пользователей, которым нужен контроль и автоматизация. Он распознает изображения, использует языковые модели и может быть встроен в цепочку обработки: подготовить изображение, выполнить OCR, собрать PDF, сохранить текст, обработать папку файлов.
Типовой сценарий:
-
Установить Tesseract.
-
Установить языковые данные.
-
Подготовить изображение или страницы PDF.
-
Запустить распознавание через команду.
-
Получить TXT или PDF с текстовым слоем.
-
Проверить результат.
-
При необходимости повторить с другой предварительной обработкой.
Плюсы:
-
открытый OCR-движок;
-
подходит для автоматизации;
-
поддерживает большое количество языков;
-
работает в скриптах;
-
можно обрабатывать папки файлов;
-
хорош для технических пользователей.
Минусы:
-
нет простого PDF-интерфейса по умолчанию;
-
требуется настройка;
-
для PDF часто нужны дополнительные утилиты;
-
качество сильно зависит от подготовки изображения;
-
новичку проще начать с графических программ.
Tesseract стоит использовать, когда задача выходит за рамки одного документа: нужна пакетная обработка, автоматизация или интеграция OCR в собственный рабочий процесс.
gImageReader
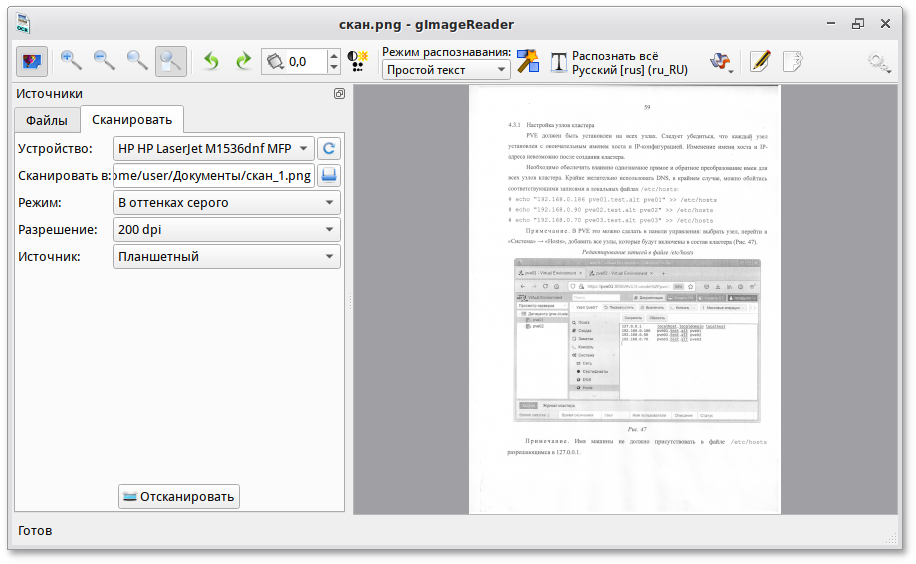
gImageReader — графическая оболочка для Tesseract. Она делает работу с открытым OCR проще: можно загрузить изображение или PDF, выбрать область, указать язык, запустить распознавание и получить текст в окне программы. Это удобный вариант для Linux-пользователей, которые хотят использовать Tesseract без постоянной работы в командной строке.
gImageReader полезен для сканов, отдельных страниц, учебных материалов, простых PDF и изображений. Он не заменяет коммерческие PDF-редакторы, но дает понятный интерфейс для распознавания и проверки текста.
Пошаговая инструкция:
-
Установите gImageReader и Tesseract.
-
Добавьте языковые пакеты.
-
Откройте PDF или изображение.
-
Выберите язык.
-
Укажите область распознавания.
-
Запустите OCR.
-
Проверьте текст в правой панели.
-
Сохраните результат.
Плюсы:
-
удобнее чистого Tesseract;
-
есть графический интерфейс;
-
можно выбирать области;
-
подходит для Linux;
-
работает с языковыми пакетами Tesseract;
-
хорош для простых OCR-задач.
Минусы:
-
не является полноценным PDF-редактором;
-
требует установки Tesseract;
-
сложное форматирование сохраняется ограниченно;
-
таблицы нужно проверять;
-
для корпоративного PDF-процесса возможностей меньше, чем у FineReader или Acrobat.
gImageReader — хороший выбор для Linux, когда нужен понятный интерфейс к открытому OCR-движку.
Как распознать официальный документ
Официальные документы требуют самого аккуратного подхода. В договорах, актах, счетах, справках и заявлениях критичны цифры, даты, фамилии, адреса, ИНН, номера счетов, суммы и подписи. Ошибка OCR в обычном абзаце неприятна, а ошибка в реквизитах может привести к неправильной оплате или юридической путанице.
Лучший порядок работы:
-
Использовать локальную программу.
-
Проверить, что PDF не защищен паролем.
-
Убедиться, что страница ровная и четкая.
-
Выбрать правильный язык.
-
Выполнить OCR.
-
Проверить все критичные данные.
-
Сохранить оригинал отдельно.
-
Сохранить распознанную копию под новым именем.
Для таких задач лучше подходят PDF Commander, ABBYY FineReader, Adobe Acrobat Pro и PDF-XChange Editor. Онлайн-сервисы оставьте для документов без персональных и коммерческих данных.
Как распознать учебник, книгу или методичку
Учебники и книги сложнее обычных документов. В них бывают колонки, иллюстрации, подписи к рисункам, номера страниц, сноски, таблицы, формулы и декоративные заголовки. Для таких материалов особенно важна подготовка.
Перед OCR:
-
разделите развороты на отдельные страницы;
-
уберите тени у корешка книги;
-
выровняйте страницы;
-
проверьте контраст;
-
выберите язык;
-
для больших файлов обработайте сначала несколько тестовых страниц;
-
сохраните исходник отдельно.
Для книг удобны ABBYY FineReader и Readiris Pro, потому что они лучше работают со структурой. Для простого поиска по отсканированному учебнику можно использовать PDF Commander, PDF-XChange Editor или PDF24 Tools.
Как распознать таблицу в PDF
Таблицы — одна из самых сложных задач для OCR. Программа должна не только прочитать символы, но и понять строки, столбцы, границы ячеек и порядок данных. Когда таблица простая и четкая, экспорт в Excel работает хорошо. Когда линии размыты, ячейки объединены, есть печати или скан перекошен, результат требует ручной проверки.
Правильный порядок:
-
Подготовьте страницу: поверните, выровняйте, улучшите контраст.
-
Выберите программу с поддержкой табличного OCR.
-
Укажите язык.
-
Выберите экспорт в XLSX, когда нужна работа с числами.
-
После распознавания проверьте шапку, строки, суммы и итоговые значения.
-
Сравните несколько контрольных строк с оригиналом.
Для таблиц лучше использовать ABBYY FineReader, Readiris Pro, Adobe Acrobat Pro, PDF-XChange Editor с расширенным OCR или PDF Commander для более простых задач.
Как сделать PDF доступным для поиска
Searchable PDF — это файл, который выглядит как скан, но внутри имеет текстовый слой. Его можно открыть как обычный PDF, при этом Ctrl+F находит слова, текст выделяется и копируется. Такой формат особенно удобен для архивов: внешний вид документа сохраняется, а поиск работает.
Подходит для:
-
договоров;
-
актов;
-
счетов;
-
учебников;
-
инструкций;
-
архивных справок;
-
судебных материалов;
-
кадровых документов;
-
технической документации.
Как сделать searchable PDF:
-
Откройте сканированный PDF.
-
Запустите OCR.
-
Выберите язык.
-
В качестве результата выберите невидимый текстовый слой или searchable PDF.
-
Сохраните файл под новым именем.
-
Проверьте поиск по нескольким словам.
-
Сравните распознанные фрагменты с оригиналом.
Для этой задачи подходят почти все инструменты из статьи. Самые удобные варианты: PDF Commander, Adobe Acrobat Pro, ABBYY FineReader, PDF-XChange Editor, NAPS2, PDF24 Tools и iLovePDF.
Частые ошибки при распознавании PDF
Выбран неправильный язык
Русский текст, распознанный как английский, превращается в набор похожих символов. Английские слова в русскоязычном режиме тоже искажаются. Для смешанных документов выбирайте оба языка.
Страница повернута боком
OCR хуже работает с неправильной ориентацией. Перед запуском поверните страницы в нормальное положение.
Скан слишком темный или слишком светлый
При слабом контрасте буквы сливаются с фоном или распадаются на фрагменты. Используйте улучшение изображения, повышение контраста и очистку фона.
Документ сфотографирован под углом
Перспективное искажение ломает строки. Для фото со смартфона используйте мобильные сканеры с выравниванием границ.
Таблица распознана как обычный текст
Для таблиц выбирайте экспорт в XLSX и программы, где можно контролировать области распознавания.
Текст копируется с лишними переносами
Это нормальная проблема после OCR. В Word или текстовом редакторе удалите лишние разрывы строк, проверьте абзацы и заголовки.
Поиск работает, но выделение неточное
Текстовый слой может немного не совпадать с изображением страницы. Это встречается на перекошенных или плохо подготовленных сканах. Повторите OCR после выравнивания.
Файл стал слишком тяжелым
OCR, сохранение исходных изображений и PDF/A могут увеличить размер. После проверки используйте сжатие PDF, но не пережимайте документ до потери читаемости.
Плюсы OCR
-
Можно копировать текст из сканов.
-
В PDF появляется поиск.
-
Бумажные документы становятся цифровыми.
-
Архивы документов легче находить по словам и номерам.
-
PDF можно конвертировать в Word, Excel или TXT.
-
Учебные материалы удобнее цитировать и перерабатывать.
-
Таблицы можно переносить в электронные таблицы.
-
Сканы можно использовать в документообороте.
-
Уменьшается ручная перепечатка.
-
Один и тот же документ можно сохранить как searchable PDF и как редактируемый файл.
Минусы OCR
-
Точность зависит от качества исходника.
-
Плохие сканы требуют предварительной обработки.
-
Рукописный текст распознается хуже печатного.
-
Таблицы и колонки часто требуют ручной проверки.
-
Онлайн-сервисы не подходят для конфиденциальных документов.
-
Длинные файлы обрабатываются медленнее.
-
Ошибки в цифрах и фамилиях нужно проверять вручную.
-
Форматирование не всегда сохраняется идеально.
-
После распознавания бывают лишние переносы строк.
-
Для сложных документов лучше использовать профессиональные программы.
Что выбрать в итоге
Для Windows первым вариантом стоит брать PDF Commander. Он хорошо подходит для русскоязычных PDF, сканов, учебных материалов, фото страниц и офисных документов. В нем удобно распознать текст, добавить невидимый слой, отредактировать PDF, поставить подпись и сохранить результат без перехода в другие программы.
Для сложных документов, таблиц, архивов и профессионального OCR лучше подходит ABBYY FineReader. Его стоит выбирать, когда важна структура, проверка ошибок и качественный экспорт в Word или Excel.
Для профессиональной PDF-среды удобен Adobe Acrobat Pro. Он хорошо подходит для searchable PDF, редактирования, комментариев, защиты и подготовки документов к передаче.
Для насыщенного Windows-редактора с большим количеством настроек хорош PDF-XChange Editor. Его OCR Pages удобен для создания поискового слоя, а расширенный OCR полезен для более сложных документов.
Для сканирования бумажных документов лучше использовать NAPS2, Scanitto Pro или мобильные приложения. Для быстрого браузерного OCR подходят PDF24 Tools, iLovePDF, Smallpdf, PDF Candy и Online OCR.
Главное правило простое: конфиденциальные документы распознавайте локально, сложные таблицы проверяйте вручную, а для обычных сканов выбирайте инструмент по платформе и нужному результату. Когда нужен быстрый searchable PDF, достаточно PDF Commander или онлайн OCR. Когда нужен аккуратный редактируемый документ, лучше использовать FineReader, Acrobat, PDF-XChange Editor или Readiris Pro.
Чтобы оставить комментарий, авторизуйтесь или зарегистрируйтесь.